- 项目列表
- TF-IDF算法和词袋模型的朴素贝叶斯在聊天文本挖掘中的实践
- 基于Fashion-MNIST数据集的分类问题研究
- 基于KNN(KD-Tree)对鸢尾花分类的比较和参数调优
- 这里简单介绍聊天文本挖掘中的实践的项目,详细内容见报告
文本挖掘是一个对具有丰富语义的文本进行分析从而理解其所包含的内容和意义的过程,已经成为数据挖掘中一个日益流行而重要的研究领域。文本挖掘所研究的文本数据库,由来自各种数据源的大量文档组成,包括新闻文章,研究论文,聊天文本等。
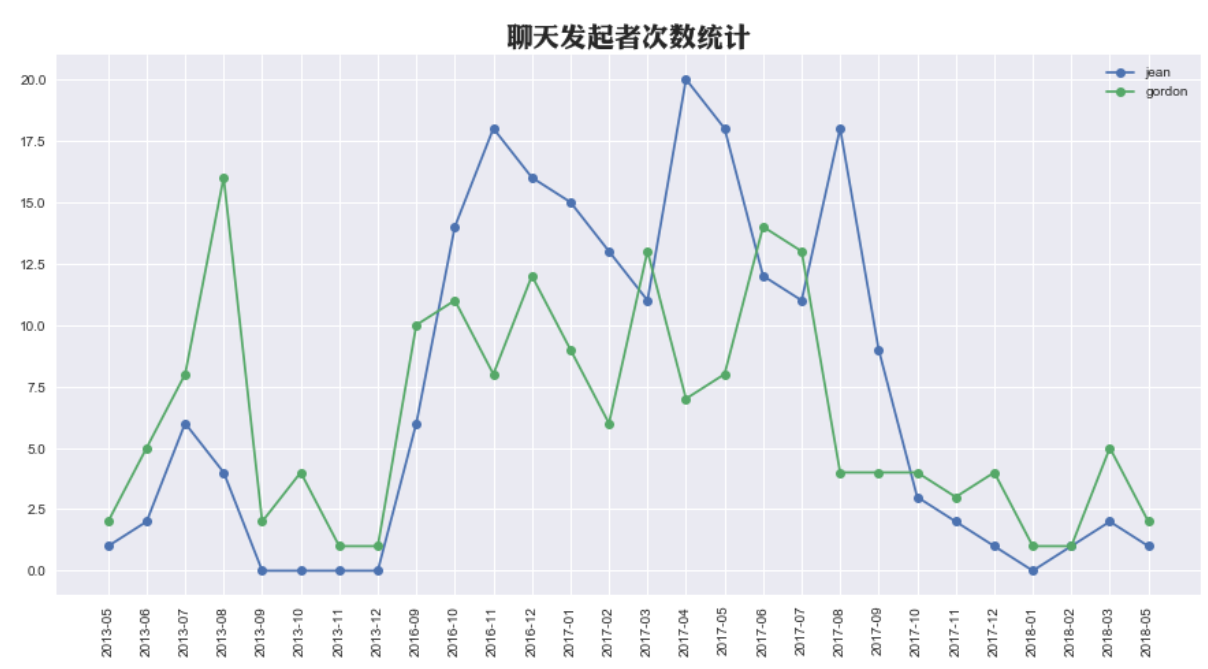
针对聊天文本的挖掘 问题的研究 ,目前来说还是一片空白。 本文利用作者与朋友的五年内数万条QQ消息记录作为数据集,利用 TF-IDF算法和基于词袋模型 的朴素贝叶斯算法进行文本挖掘, 以发现该数据集背后隐藏的相关 信息和模式。
在聊天文本中,人们常常关注双方聊天内容的关键词,即在一段时间内双方经常聊天的主题是什么。此时,可以使用TF-IDF算法进行关键词提取。
基于朴素贝叶斯算法对聊天文本进行训练,从而得到可以通过输入一段文本,预测其说话者是谁的模型
除了上述通过TF-IDF寻找聊天文本出现最多的关键词,以及用朴素贝叶斯算法预测说话者身份,我们同时挖掘了其他相关信息