Different Recommendation Systems
1. Simple Recommender (Knowledge-Based Recommender)
-
Here is the link for the dataset used for this recommender.
-
This will be a simple function that will perform the following tasks:
- Ask the user for the genres of movies he/she is looking for .
- Ask the user for the duration.
- Ask the user for the timeline of the movies recommended.
- Using the information collected, recommend movies to the user that have a high weighted rating (according to the IMDB formula) and that satisfy the preceding conditions.
-
Building the simple recommender is fairly straightforward. The steps are as follows:
-
Choosing the metric (or score) to rate the movies on .
-
Deciding the prerequisites for the movie to be featured on the chart.
-
Calculate the score for every movie that satisfies the conditions.
-
Output the list of movies in decreasing order of their scores.
-
-
Here IMDB's weighted rating formula is used as the metric. Mathematically, it can be represented as follows:
-
weighted_rating(WR) =
-
v is the number of votes garnered by the movie.
-
m is the minimum number of votes required for the movie to be in the chart (the prerequisite).
-
R is the mean rating of the movie.
-
C is the mean rating of all the movies in the dataset.
-
The Prerequisites
-
The IMDB weighted formula also has a variable m , which it requires to compute its score.
-
Just like the metric, the choice of the value of m is arbitrary. In other words, there is no right value for m.
-
It is a good idea to experiment with different values of m and then choose the one that you (and your audience) think gives the best recommendations.
-
For this recommender, we will use the number of votes garnered by the 80th percentile movie as our value for m.
-
-

2. Plot Description-Based Recommender(Content Based)
-
This model compares the descriptions and taglines of different movies, and provides recommendations that have the most similar plot descriptions.
-
The first step toward building this system is to represent the bodies of text (henceforth referred to as documents) as mathematical quantities. There are two ways of representation of text:
-
CountVectorizer is used to a collection of text documents to vectors of token counts essentially producing sparse representations for the documents over the vocabulary. The end result is a vector of features, which can then be passed to other algorithms.
-
**TF-IDFVectorizer ** takes the aforementioned point into consideration and assigns weights to each word according to the following formula. For every word i in document j, the following applies:
- In this formula, the following elements are:
- w is the weight of word i in document j
- df is the number of documents that contain the term i
- N is the total number of documents
- In this formula, the following elements are:
-
-
In this system we will be using TF-IDFVectorizer because some words occur much more frequently in plot descriptions than others. Another reason of using this vectorizer is that it speeds up the calculation of the cosine similarity score between a pair of i, j documents.
-
Presently, we will make use of the cosine similarity metric to build our models. The cosine score is extremely robust and easy to calculate (especially when used in conjunction with TF-IDFVectorizer).
The cosine score can take any value between -1 and 1. The higher the cosine score, the more similar the documents are to each other.
-
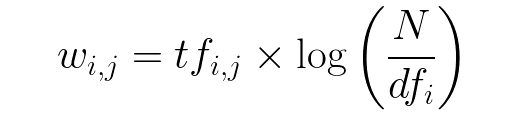
3. Collaborative Filters
- Just like the knowledge-based and content-based recommenders, collaborative filtering models are built on the context of movies. Since collaborative filtering demands data on user behavior, here the different dataset is used known as MovieLens.
- The MovieLens dataset is made publicly available by GroupLens Research, a computer science lab at the University of Minnesota. It is one of the most popular benchmark datasets used to test the potency of various collaborative filtering models and is usually available in most recommender libraries and packages.
- MovieLens gives us user ratings on a variety of movies and is available in various sizes. The full version consists of more than 26,000,000 ratings applied to 45,000 movies by 270,000 users. However, for the sake of fast computation, built recommender on the much smaller dataset, which contains 100,000 ratings applied by 1,000 users to 1,700 movies.
- For Model based recommender KNN algorithm is used to build clustering-based collaborative filter. Here instead of implementing KNN from base, an extremely popular and robust library called surprise is kept in play.
- Surprise is a scikit (or scientific kit) for building recommender systems in Python. You can think of it as scikit-learn's recommender systems counterpart. This is because it is extremely robust and easy to use. It gives us ready-to-use implementations of most of the popular collaborative filtering algorithms.
- To download surprise, like any other Python library, open up your Terminal and type the following command:
- For windows
- For Mac or Unbuntu
- For windows


