- 加载语料库,语料库来源于2部分:
- wiki百科,使用wiki_extractor进行抽取,中文繁体转换为中文简体,具体操作
- 新闻语料库,使用18年新华社新闻库,存放在MySQL数据库中。
- 加载模型(ltp分词、词性标注、依存句法分析)(这些在哈工大的ltp语言模型中都有的,只要安装好就可以用)
- cws.model对应分词模型
- parser.model对应依存句法分析模型
- pos.model对应词性标注模型
- pisrl.model对应语义角色分析模型
- 根据上述模型和语料库(按行处理)得到依存句法关系parserlist。
- 这部分处理主要是为了找出所有的SBV主谓结构的句子,为后来的验证模型做准备。
- 使用gensim工具加载预训练好的词向量模型word2vec.model
- gensim.Word2Vec
- 通过word2vec.most_similar('说', topn=10) 得到一个以跟‘说’意思相近的词和相近的概率组成的元组,10个元组组成的列表。
- 本文采用10次迭代gensim相似词结果计算,并且每次迭代的计算结果先进行词性分析,如果为verb再加入到下次迭代计算中,这样获得与“说”类似的词更为精准。
- 仅仅是上面10个与‘说’意义相近的词是不够的,写个函数来获取更多相近的词。首先把第五步的‘词’取出来,把其后面的概率舍弃。取出来之后,按那10个词组成的列表利用word2vec模型分别找出与这10个词相近的词,这样广度优先搜索,那么他的深度就是10。这样就得到了一组以‘说’这个意思的词语组成的一个列表,绝对是大于10个的,比如说这些近义词可以是这些['眼中', '称', '说', '指出', '坦言', '明说', '写道', '看来', '地说', '所说', '透露',‘普遍认为', '告诉', '眼里', '直言', '强调', '文说', '说道', '武说', '表示', '提到', '正说', '介绍', '相信', '认为', '问', '报道']等。
- 增加激活词,可以参考哈工大同义词词林的方法进行增加。
- 接下来可以手动加入一些新闻中可能出现的和‘说’意思相近的一些词,但是上面我们并没有找到的,比如‘报道’。
- 手动添加激活词虽然略显笨拙,但是像“强调”、“说明”诸类词会被停用词剔除,但这些词在新闻中确实是经常容易出现的,因此,手动添加激活词有时候也是必要的。
- 获取与‘说’意思相近的词之后,相当于已有谓语动词,接下来要找谓语前面的主语和后面的宾语了。由前面我们获取的句法依存关系,找出依存关系是主谓关系(SBV)的,并且SBV的谓语动词应该是前面获取的‘说’的近义词。那么接着应该找出动词的位置,主语和宾语的位置自然就找出来,就能表示了。那么怎么找位置?SBV词所在的索引就是主语。
- 但是找主语要注意必须指代消解,消除代词,找到实际的名词,指代消解常用的方法参考
- 获得主语和谓语‘说’的序号之后,我们就要取得‘说的内容’也就是SBV的宾语。那么怎么寻找说的内容呢?首先我们看‘说’后面是否有双引号内容,如果有,取到它,是根据双引号的位置来取得。如果没有或者双引号的内容并不在第一个句子,那么‘说’这个词后面的句子就是‘说的内容’。然后检查第二个句子是否也是‘说的内容’,通过句子的相似性来判断,如果相似度大于某个阈值,我们就认为相似,也就认为这第二句话也是‘说的内容’。至此我们得到了宾语的内容。
- 在这一步中,主要考虑应当是同一说话人的句子之间有无联系,当输入说话人的段落时,首先进行分句,然后ltp处理之后,每个单句之间的相似度采用Tfidf进行判别。
- 使用Tfidf进行文档的相似度判断,具体采用工具scikit learning
- 思考设置合理的权重,向输入文本的用户推荐8W+ 新华社新闻稿中相似度最接近用户输入的Top5文章
- 合理使用正负面评价和情感分析的语料库,针对同一事件不同人的看法进行聚类分析
- OS环境:华为云主机CentOS7.6
- 软件环境:
- Python3.5.1
- jieba、pyltp3.4.0、gensim、
- flask、Bootstrap、html
- 语料库:wiki中文版和8W新闻稿-已经合成merge_corpus
- 1 flask文件夹下,指定app:
export FLASK_APP=myproject.py
- 2 flask文件夹下,运行:
nohup firefox &
- 3 flask文件夹下,运行:
flask run
- 4 firefox浏览器运行<127.0.0.1:5000>
.
├── app
│ ├── forms.py
│ ├── forms.py.bak
│ ├── init.py
│ ├── review_content.py
│ ├── routes.py
│ ├── static
│ │ └── images
│ │ ├── \345\257\271\350\257\235\346\203\205\347\273\252\350\257\206\345\210\253.PNG
│ │ ├── \346\203\205\346\204\237\345\200\276\345\220\221\345\210\206\346\236\220.PNG
│ │ ├── \346\226\207\347\253\240\345\210\206\347\261\273.PNG
│ │ ├── \346\226\207\347\253\240\346\240\207\347\255\276\347\256\241\347\220\206.PNG
│ │ ├── \346\226\260\351\227\273\346\221\230\350\246\201.PNG
│ │ ├── \350\207\252\344\270\273\347\272\240\351\224\231.PNG
│ │ └── \350\257\204\350\256\272\350\247\202\347\202\271\346\217\220\345\217\226.PNG
│ └── templates
│ ├── base.html
│ ├── form.html
│ ├── index.html
│ └── review_extraction.html
├── config.py
├── cws.model
├── md5.txt
├── merge_corpus
├── merge_corpus.model
├── merge_corpus.model.trainables.syn1neg.npy
├── merge_corpus.model.wv.vectors.npy
├── myproject.py
├── ner.model
├── parser.model
├── pisrl.model
├── pos.model
├── review_content.py
└── stopwords.txt
Home Page

review content extraction

- Flask部分
#从app模块中即从__init__.py中导入创建的app应用
from app import app
from flask_bootstrap import Bootstrap
from flask import render_template, redirect
from app.forms import NameForm
#from app.numpy import
#建立路由,通过路由可以执行其覆盖的方法,可以多个路由指向同一个方法。
import pandas
from app import review_content
from app import news_extract
@app.route('/') # 指向/
@app.route('/index') # 指向/index.html
def index():
return render_template("index.html")
@app.route('/Review_Extraction',methods=['GET','POST'])
def Review_Extraction ():
name = None
form = NameForm()
if form.validate_on_submit(): # 当提交的内容不为空时
name = form.name.data
old_width = pandas.get_option('display.max_colwidth')
pandas.set_option('display.max_colwidth', -1)
df = review_content.review_fc(name)
df = news_extract.main(name)
form.name.data = ''
columns = ['Person','SBV','speech_content','sentence']
return render_template('review_extraction.html', title='Zh_Cola',form=form,tables=[df.to_html(classes='data',escape=True,index=True,sparsify=False,border=1,index_names=False,header=True,columns=columns)], titles=df.columns.values)
pandas.set_option('display.max_colwidth', old_width)
else:
return render_template('review_extraction.html', title='Zh_Cola',form=form)
@app.route('/News_push')
def News_push():
return "更新中~~~"
bootstrap = Bootstrap(app)- review_content()函数部分
#!/usr/bin/ python
# -*- coding: utf-8 -*-
import sys, os
from zhon.hanzi import punctuation
from zhon.hanzi import non_stops
from zhon.hanzi import stops
import logging
zhon_char = punctuation + non_stops + stops
import pyltp
import gc
import re
# 从single_sents读句子也可以
def sentence_read():
# 0
#Input = open("./single_sents", "r", encoding="utf-8")
# 1 利用sentencesplitter再分一遍句子
with open("./article_corpus", 'r', encoding="utf-8") as fo:
pass
# 中文文本分句,返回值为字符串组成的列表
def cut_sent(para):
para = re.sub('([。!?\?])([^”’])', r"\1\n\2", para) # 单字符断句符
para = re.sub('(\.{6})([^”’])', r"\1\n\2", para) # 英文省略号
para = re.sub('(\…{2})([^”’])', r"\1\n\2", para) # 中文省略号
para = re.sub('([。!?\?][”’])([^,。!?\?])', r'\1\n\2', para)
# 如果双引号前有终止符,那么双引号才是句子的终点,把分句符\n放到双引号后,注意前面的几句都小心保留了双引号
para = para.rstrip() # 段尾如果有多余的\n就去掉它
# 很多规则中会考虑分号;,但是这里我把它忽略不计,破折号、英文双引号等同样忽略,需要的再做些简单调整即可。
return para.split("\n")
# ltp_process,只分析SBV类型的句子。输出SBV主语、谓语“说”和说话内容
def ltp_process(sentence):
stop_words = get_stops_words() # 提取停用词,为SBV词【如“是”等停用词】在SBV词中删除。
# 分词
segmentor = pyltp.Segmentor()
segmentor.load("./cws.model")
words = segmentor.segment(sentence)
print("\t".join(words))
segmentor.release()
# 词性
postagger = pyltp.Postagger()
postagger.load("./pos.model")
postags = postagger.postag(words)
# list-of-string parameter is support in 0.1.5
# postags = postagger.postag(["**","进出口","银行","与","**银行","加强","合作"])
print("\t".join(postags))
postagger.release()
# 依存句法分析
parser = pyltp.Parser()
parser.load("./parser.model")
arcs = parser.parse(words, postags)
parser.release()
# 角色分析,暂时没用上
# 拿到前面来是有用意的,在进行判断了当前的SBV的子节点与"说"有关后,需要抽取这个词,简而言之,是SBV,又对应A0,则这个词一定是主语。
labeller = pyltp.SementicRoleLabeller()
labeller.load("./pisrl.model")
roles = labeller.label(words, postags, arcs)
print("\t".join("%d:%s" % (arc.head, arc.relation) for arc in arcs))
SBV_set = list()
Subject_label_set = list()
Word_of_speech_content = list()
Index_of_Subjet = 0
for arc in arcs:
#SBV_index = get_repeat(arc.head, "SBV")
k = Index_of_Subjet
if arc.relation == "SBV" and words[arc.head - 1] not in stop_words: # 这个地方难道真的不够严谨,不能只判断是不是SBV,因为一旦判断有SBV了,那么必然这个词就是A0
SBV_set.append(words[arc.head - 1]) # arc.head是从1开始计数,存储SBV指向的谓语动词
Subject_label_set.append(words[Index_of_Subjet]) # 如果有SBV,那么这个词对应的位置肯定是主语
Word_of_speech_content.append(words[arc.head:]) # 拿出来的相当于SBV主语词以后的部分。
Index_of_Subjet += 1
else:
Index_of_Subjet += 1
continue # 如果为空列表,该句子没有分析的必要性
return SBV_set, Subject_label_set, Word_of_speech_content # 返回的是一个列表,第一个值是SBV的子节点词(HED),第二个是当前SBV的主语。一定要注意,是不是都是[]
import pandas as pd
from collections import defaultdict
def pd_DataFram():
'''
DataFram 结构是这样的
列索引
0
分句结果 SVB 说话人 说话内容
行索引 0 句子0 句子0的SVB结果[SVB词的索引列表] [per1, per2, per3,...] [speech1, speech2, speech3]
1 句子1 句子1的SVB结果[SVB次的索引列表] [per1, per2, per3,...] [speech1, speech2, speech3]
2 . ...
3 .
'''
#句子成分分析结果
result_of_data = defaultdict(list)
return result_of_data
import gensim as gm
# verb_speak是一个包含SBV的列表,非一个词
def is_there_speak(Verb_and_Subject_result_of_ltp_process):
# 1 投入SBV的词进行检测,看下是不是位于词的列表中。
# 1.1 手动写的这些
manl_add_speak = ['讨论', '交流', '讲话', '说话', '吵架', '争吵', '勉励', '告诫', '戏言', '嗫嚅', '沟通', '切磋', '争论', '研究', '辩解', '坦言', '喧哗', '嚷嚷', '吵吵', '喊叫', '呼唤', '讥讽', '咒骂', '漫骂', '七嘴八舌', '滔滔不绝', '口若悬河', '侃侃而谈', '念念有词', '喋喋不休', '说话', '谈话', '讲话', '叙述', '陈述', '复述', '申述', '说明', '声明', '讲明', '谈论', '辩论', '议论', '讨论', '商谈', '哈谈', '商量', '畅谈', '商讨', '话语', '呓语', '梦话', '怪话', '黑话', '谣言', '谰言', '恶言', '狂言', '流言', '巧言', '忠言', '疾言', '傻话', '胡话', '俗话', '废话', '发言', '婉言', '危言', '谎言', '直言', '预言', '诺言', '诤言']
# 1.2 迭代10次加入的这些
gensim_speak_list =['说', '却说', '答道', '回答', '问起', '说出', '追问', '干什么', '质问', '不在乎', '没错', '请问', '问及', '问到', '感叹', '告诫', '说谎', '说完', '开玩笑', '讲出', '直言', '想想', '想到', '问说', '责骂', '讥笑', '问过', '转述', '闭嘴', '撒谎', '谈到', '有没有', '骂', '责怪', '取笑', '吹嘘', '听过', '不该', '询问', '坚称', '怒斥', '答', '该死', '忘掉', '说起', '反问', '问道', '忍不住', '苦笑', '没事', '道谢', '问', '对不起', '戏弄', '埋怨', '发脾气', '说道', '原谅', '责备', '大笑', '听罢', '放过', '不解', '没想', '训斥', '认错', '想来', '自嘲', '还好', '打趣', '嘲笑', '后悔', '讥讽', '发怒', '心疼', '发牢*', '数落', '点头', '认得', '醒悟', '装作', '要死', '流泪', '哭诉', '走开', '动怒', '不屑', '悔恨', '咒骂', '捉弄']
speak_list = manl_add_speak + gensim_speak_list
final_speak = list()
final_label = list()
final_speech_content = list()
#tmp_SBV_label_set = Verb_and_Subject_result_of_ltp_process
for speak, label, speech_content in Verb_and_Subject_result_of_ltp_process:
if speak in speak_list:
final_speak.append(speak)
final_label.append(label)
final_speech_content.append(speech_content)
else:
# # 2 如果不在列表中,采用gensim.most_similar()进行判断,相似性大于0.4,认为就是说的同义词
logging.basicConfig(format="%(asctime)s:%(levelname)s:%(message)s", level=logging.INFO)
mode = gm.models.Word2Vec.load("./merge_corpus.model")
if mode.wv.similarity('说', speak) > 0.4:
print(speak, mode.wv.similarity('说', speak))
final_speak.append(speak)
final_label.append(label)
final_speech_content.append(speech_content)
else:
continue
print(final_speak, final_label, final_speech_content)
return final_speak, final_label, final_speech_content
# 把停用词再删除
def get_stops_words():
with open("./stopwords.txt", "r") as fo:
stop_words = fo.read().split('\n')
return stop_words
def refine_speech_content():
# 01 如果只有引号能把所有内容包括,则把引号里的内容拿出来
# 02 如果没有引号,则按逗号进行拆分,并判断是不是一句话。
pass
# 主函数
def review_fc(para):
#0 输入一个句子或者一个段落
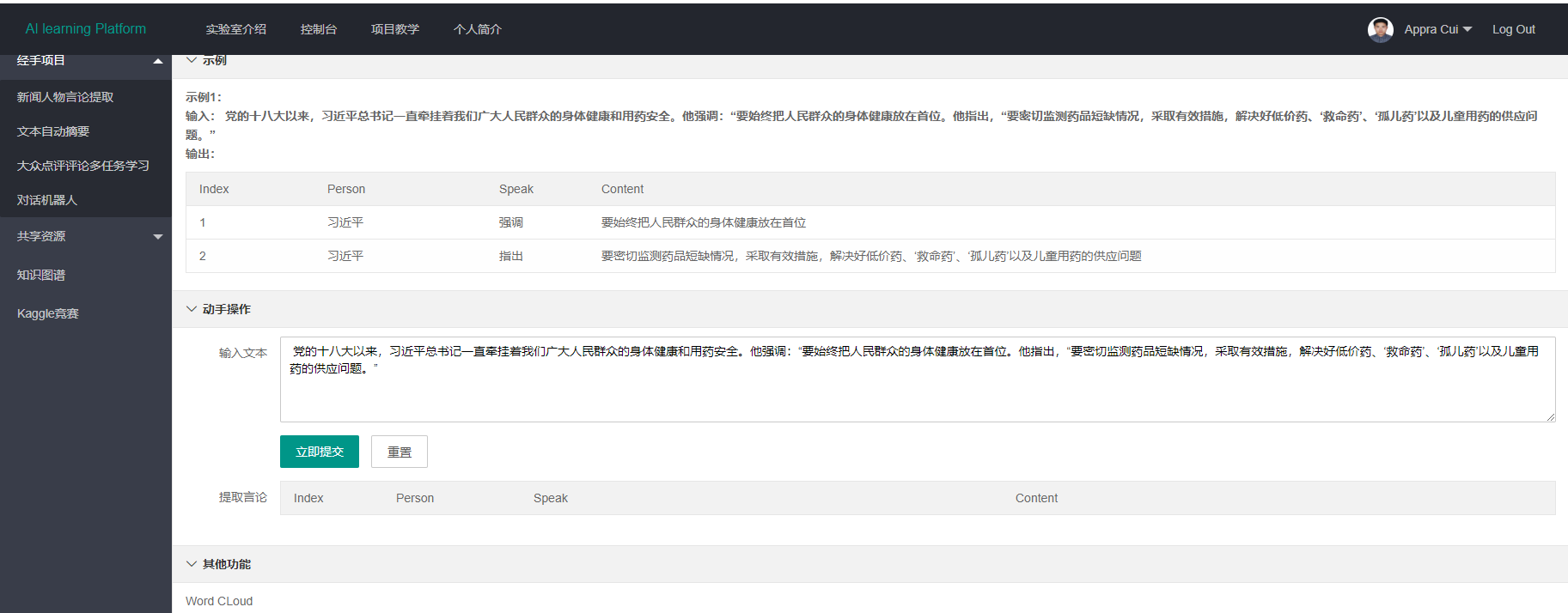
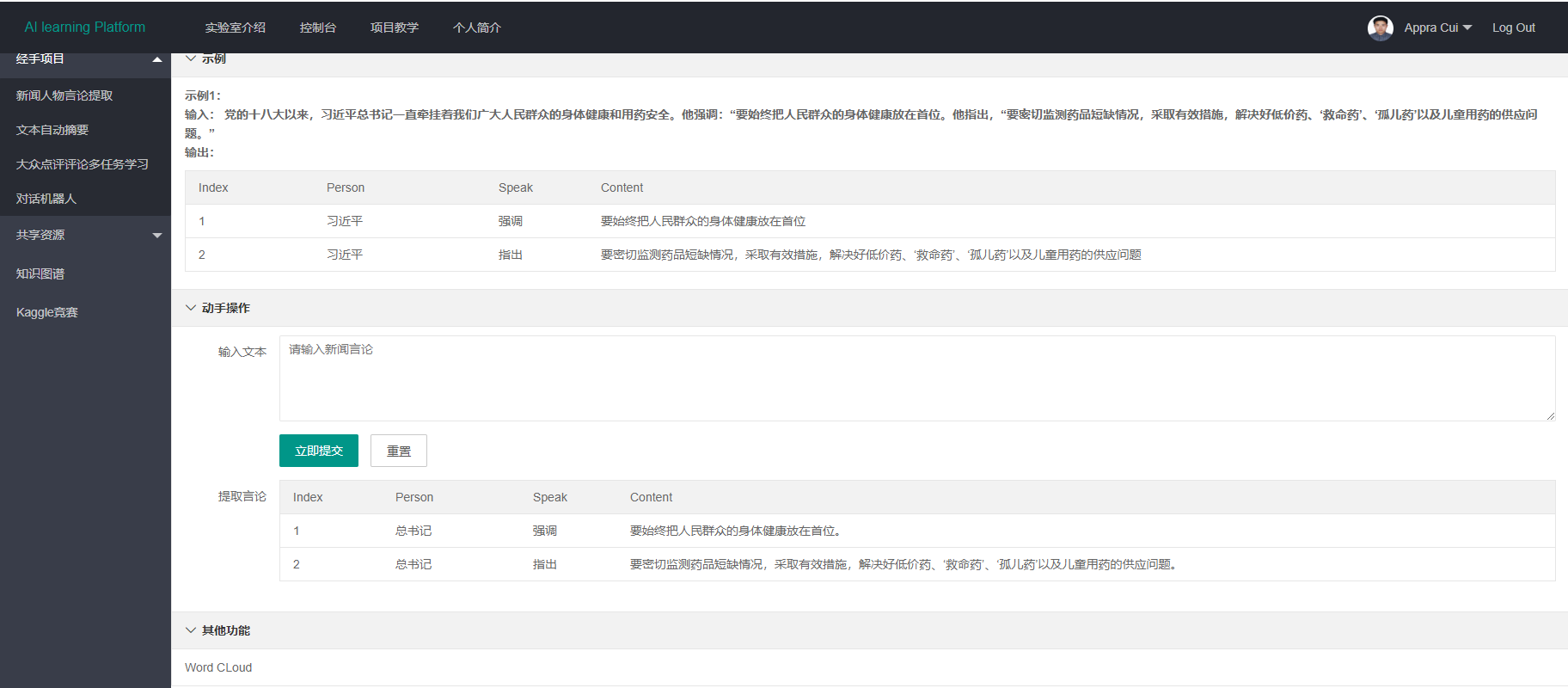
paragraph = "党的十八大以来,***总书记一直牵挂着广大人民群众的身体健康和用药安全,他强调:要始终把人民群众的身体健康放在首位。他指出,“要密切监测药品短缺情况,采取有效措施,解决好低价药、‘救命药’、‘孤儿药’以及儿童用药的供应问题。"
paragraph = para
result_of_data = pd_DataFram() # 空defaultdict
#0.1 判断句子是否可以分句
cut_result = cut_sent(paragraph)
result_of_data["sentence"] = cut_result
print(result_of_data["sentence"])
if cut_result:
for sent in cut_result: # 一个句子一个句子分析
#0.2 判断这个句子是不是含有SBV的成分
ltp_result = ltp_process(sent) # 返回的已经是words[“SVB”]和SBV对应的主语。
verb_of_ltp_result, label_of_ltp_result, Word_of_speech_content = ltp_result
if verb_of_ltp_result: #只要verb_of_ltp_result不为空,就进行判断说,否则该句子就没有说
(sp_list, label_list, speech_list) = is_there_speak(zip(verb_of_ltp_result, label_of_ltp_result, Word_of_speech_content))
if sp_list != None:
result_of_data["SBV"].append(sp_list)
result_of_data["Person"].append(label_list)
result_of_data["speech_content"].append([''.join(k) for k in speech_list if speech_list[0] != ',:'])
else:
result_of_data["sentence"].pop()
print("句子不含有动词说")
else:
result_of_data["sentence"].pop()
print("该句子不是SBV类型") # 不是SBV类型可以再加一部分判断,按照袁禾那种从动词verb出发,判断是不是说
#可以调袁禾的接口去做
result_all = pd.DataFrame(result_of_data)
return result_all
def main():
main_fuc()
if __name__ == "__main__":
print(main)- 两个html部分
- index.html
{% extends "bootstrap/base.html" %}
{% block title %}Zh_Cola Lab{% endblock %}
{% block navbar %}
<div class="navbar navbar-inverse" role="navigation">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle"
data-toggle="collapse" data-target=".navbar-collapse">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="/">Flasky</a>
</div>
<div class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li><a href="/">Home</a></li>
<li><a href="/Review_Extraction">Review Extraction</a></li>
<li><a href="/">NEWs Push</a></li>
</ul>
</div>
</div>
</div>
{% endblock %}
{% block content %}
<style>
.h1{
margin:20px;
}
.div1{
margin:10px;
}
</style>
<div>
<h1 class=div1 style="margin:10" ><b>Welcome to our Lab!</b><br/></h1>
<h1 class=div1 style="color:#123456;margin:10"> Members </h1>
<p class=h1 style="font-size:20px;margin:20">袁 禾 王路宁 范倩文 崔少华 </p>
<h1 class=div1 style="color:#456123;margin:10"> Fuctions </h1>
<a class=h1 href='Review_Extraction' style="font-size:20px;margin:10"> Review Extraction <br/></a>
<a class=h1 href='/' style="font-size:20px"> News Push </a>
<h1 class=div1 style="color:#123456 "> what can N-L-P do ? </h1>
<img class=div1 src="{{ url_for('static', filename='images/对话情绪识别.PNG') }}" width="300" height="300" alt="test"/>
<img src="{{ url_for('static', filename='images/评论观点提取.PNG') }}" width="300" height="300" alt="test"/>
<img src="{{ url_for('static', filename='images/文章分类.PNG') }}" width="300" height="300" alt="test"/>
<img src="{{ url_for('static', filename='images/文章标签管理.PNG') }}" width="300" height="300" alt="test"/>
<img src="{{ url_for('static', filename='images/新闻摘要.PNG') }}" width="300" height="300" alt="test"/>
<img src="{{ url_for('static', filename='images/自主纠错.PNG') }}" width="300" height="300" alt="test"/>
</div>
{% endblock %}
- review_extraction.html
{% extends "bootstrap/base.html" %}
{% block title %}Zh_Cola_Lab{% endblock %}
{% block navbar %}
<div class="navbar navbar-inverse" role="navigation">
<div class="container">
<div class="navbar-header">
<button type="button" class="navbar-toggle"
data-toggle="collapse" data-target=".navbar-collapse">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="/">{{ title }}</a>
</div>
<div class="navbar-collapse collapse">
<ul class="nav navbar-nav">
<li><a href="/">Home</a></li>
<li><a href="/Review_Extraction">Review_Extraction</a></li>
<li><a href="/News_push">NEWs Push</a></li>
</ul>
</div>
</div>
</div>
<div style="width:100%;text-align:center">
<form action="" method="post">
<!-- #用来实现在配置中激活的csrf保护-->
{{ form.hidden_tag() }}
<p>
{{ form.name.label }}<br>
{{ form.name(size=100) }}
</p>
<p>{{ form.submit() }}</p>
</form>
</div>
<div class="container">
<h1>The result of review_Extraction is<br/></h1>
<table border="0">
{% for table in tables %}
<table border="0">
{{titles[loop.index]}}
{{ table|safe }}
`- 更新:添加指代消歧
 指代消歧本身是一项复杂的过程,当前深度学习算法中也有Coref任务在持续进行,研究学者也开发了不少模型进行计算,比较有代表性的是阿里云的模型,大家可从网上找下相关论文看下。数据集也是公开的,本文暂使用的是基于规则来写,具体参考的算法是指代消歧的研究方法一文,项目中的关键代码展示在下方:
指代消歧本身是一项复杂的过程,当前深度学习算法中也有Coref任务在持续进行,研究学者也开发了不少模型进行计算,比较有代表性的是阿里云的模型,大家可从网上找下相关论文看下。数据集也是公开的,本文暂使用的是基于规则来写,具体参考的算法是指代消歧的研究方法一文,项目中的关键代码展示在下方:
# focus_point_set
class Si:
def __init__(self, words, postags, old_SI = {}):
self.words = words # 名词及索引
self.postags = postags # 主语、宾语、辅助名词及索引
self.params = {} # {'word':'score'}
self.old_SI = old_SI
def score(self):
# 根据名词和索引及主宾辅的索引情况进行归类并且赋值初始分数
weight_adment = []
for i,j in self.postags.items():
# i代表["SBV",'VOB'],j代表索引
# 加入一个权重的修正,将名词词组的得分提高,如score(***) = score(总书记)
if i=='SBV':
for k in j:
if k[0] in self.words.keys() and self.words[k[0]] == k[1]:
self.params[k[0]] = 5
weight_adment.append(k[1])
else:
pass
elif i=='VOB':
for m in j:
if m[0] in self.words.keys() and self.words[m[0]] == m[1]:
self.params[m[0]] = 2
else:
pass
else:
self.params[i] = 1# "SBV":(词,初始分数)
for word, index in self.words.items():
if word not in self.params.keys():
self.params[word] = 1
# 修正
#print(weight_adment)
for f, k in self.words.items():
if k in (np.array(weight_adment) + 1).tolist() or k in (np.array(weight_adment) - 1).tolist():
self.params[f] = 5
return self.params
def update(self):
# 先调用一次score,获得当前的params
params = self.score()
# 比较当前postags和之前的postags
if self.old_SI:
for i, j in self.old_SI.params.items():
if i not in list(params.keys()) and j>=1:
j -= 1 # 进行简化,衰减程度都变成1
self.old_SI.params[i] = j
if j <= 0:
self.old_SI.params[i] = 0
#print('update', self.old_SI.params)
return self.old_SI.params(1)指代消解的算法还需要再写入初级目标;
(2)Tfidf在判断文档相似性上还需要细心考虑一些权重。
(3)正负面评价分析目前需要参考硕博论文再定思路。