#Harnessing disagreement in event text classification using CrowdTruth annotation
Gathering new expert annotated data for any machine learning task is a costly and timely approach. Using crowd-sourcing for gathering human interpretation on text, video and audio is a cost and time efficient alternative. There are many crowd-sourcing platforms available, for instance CrowdFlower or Amazon Mechanical Turk. However while experts have specific domain knowledge and incentive to annotate following a strict set of rules, this does not apply to the human annotators or Workers on the crowd-sourcing platforms. In "CrowdTruth methodology, a novel approach for gathering annotated data from the crowd", the authors state that human interpretation is subjective and thus having multiple people performing the same task on a crowd-sourcing platform will lead to multiple interpretations of this task. A common way of dealing with this problem is by using Majority Voting, take the annotation that has highest frequency and disregard all other annotations. However this removes the disagreement which is a signal, not noise. In this paper we introduce a novel way to incorporate the disagreement in the annotators as a way to weigh the features for textual data. We propose multiple novel algorithms to create the crowd-based distribution weights and discuss the pros and cons of each one. We test our weighted features with a modified Multinominal Naive Bayes algorithm. We show that using crowd based distribution weights we are able to perform as well and better than expert-labeled data while learning on only 10% of the training data. Furthermore our approach also has a much faster learning rate.
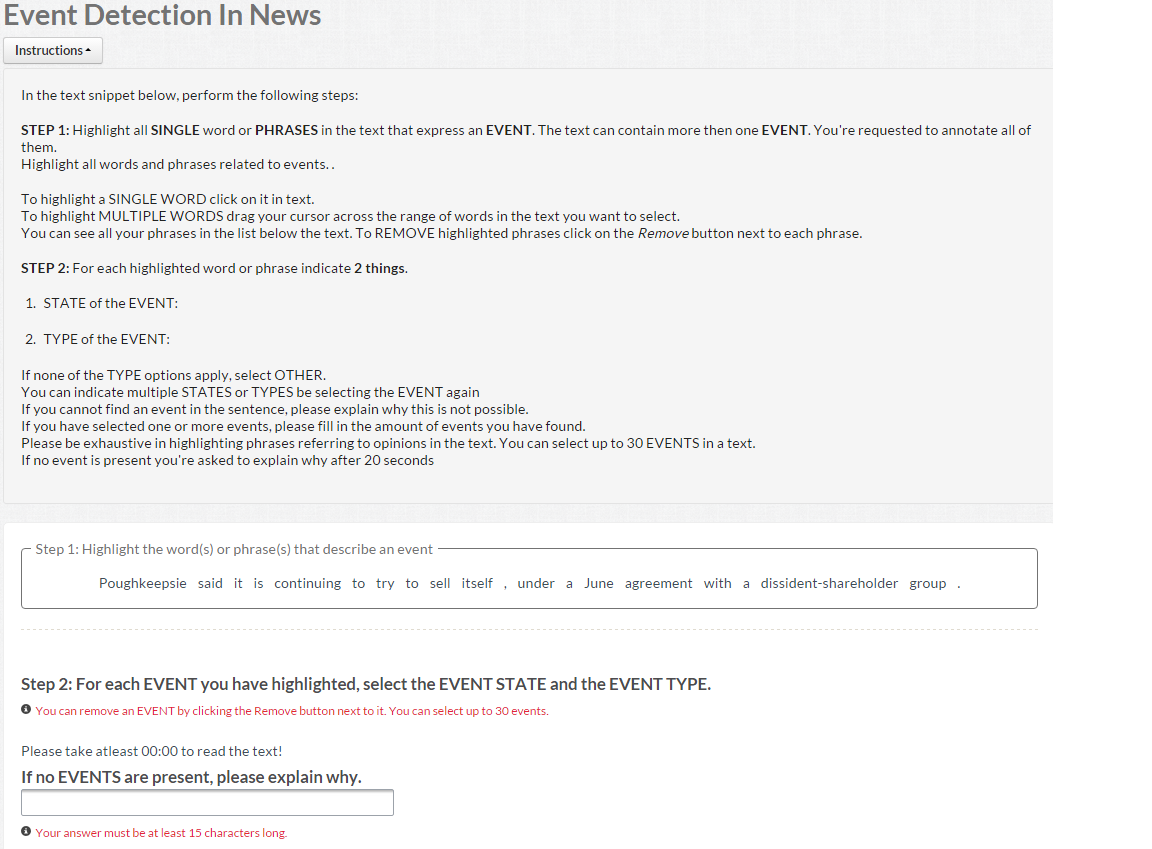
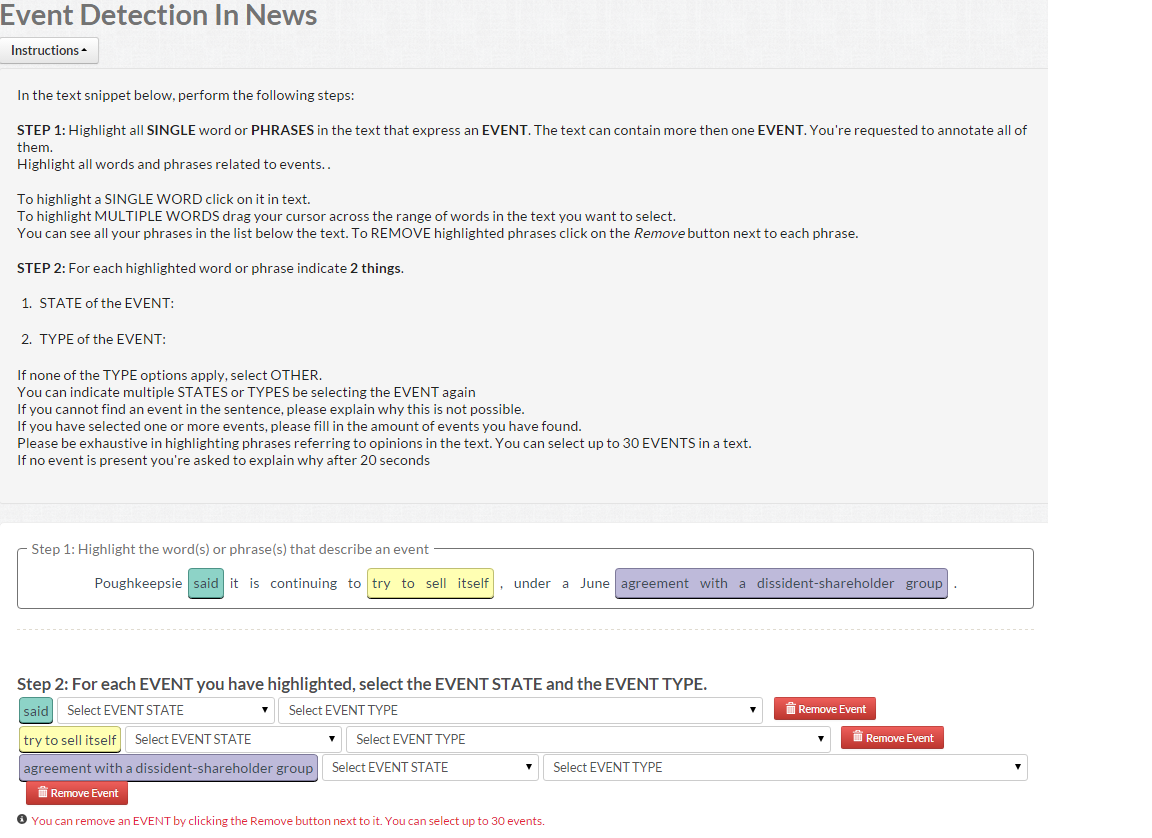
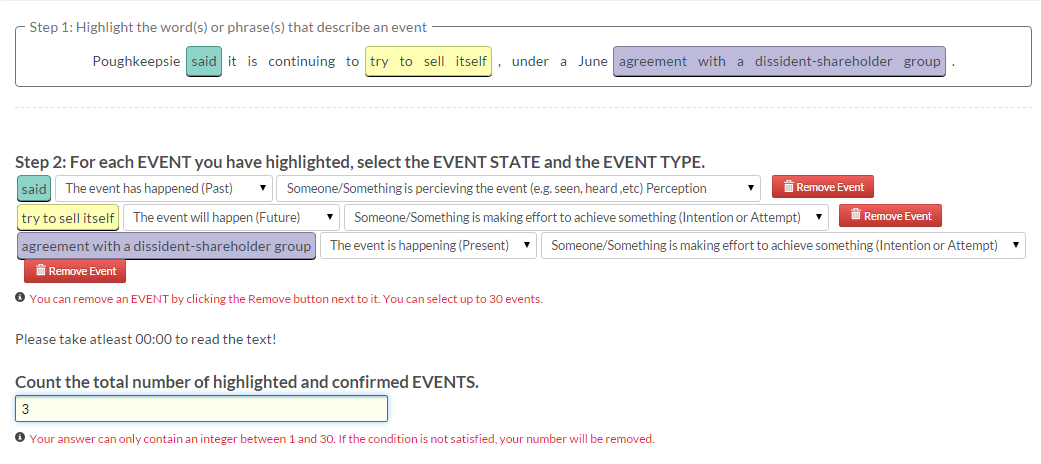
| Task | Workers/Unit | Payment/Unit |
|---|---|---|
| Task | 15 | $0.05 |
Text used in this research orginate from the tempeval2 where all sentences have been annotated with an event and event type by a panel of experts.
This repository contains all the data and code that was used to annotate the text as all features and labels used during training and testing of the classifiers. We distinguish two different folders 'Code' and 'Data'. The folder 'Code' contains all python files used to compute the Sentence-Clarity, Sentence-Event- Clarity, TFIDF scores and to create the features and classifiers. All required jars have been provided. The 'Data' folder contains the input and output files from all crowdsourcing tasks aswell as the output files produced by the python files from 'Code'.
The data and results produced by this research have been achieved by following the following steps:
- Gather annotations crowdsourcing task 1 using the input file [https://raw.githubusercontent.com/CrowdTruth/Events-in-Text/master/Data/CrowdTask/sample_only_sentences_0.csv), employing batches with a maximum size of 30 sentences.
- Run python code /Code/ to create combinedTrain folder
- Run python code Code/Prepoccesing to compute the features
- Run python code Code/Bayes on the outputfiles of the previous stepts to train and test the classifier