-
硬件IIC
IIC:模拟IIC 协议,好多人都说STM32的硬件IIC模块用不了,主要是因为STM32 的硬件 IIC 模块有个天生的 BUG,就是不能被中断,也就是IIC要处于中断的最高级,ST在自己后来的 DataSheet 中已经证实了这一点。
-
hex、bin文件区别
hex文件包含地址信息。在用ISP方式烧写程序时,我们都有这样的经验:1)选择单片机型号;2)选择串口号;3)设置波特率(或者默认);4)选择下载的文件;5)点击下载按钮下载。如下图所示。经过这几步后,程序下载工作就完成了,在以上的步骤中我们并没有选择要把程序下载到单片机的哪块内存中,即不需要设置地址。因为HEX文件内部的信息已经包括了地址。而烧写BIN文件的时候,用户是一定需要指定地址信息的。
-
内核空间、用户空间
对 32 位操作系统而言,它的寻址空间(虚拟地址空间,或叫线性地址空间)为 4G(2的32次方)。也就是说一个进程的最大地址空间为 4G。操作系统的核心是内核(kernel),它独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证内核的安全,现在的操作系统一般都强制用户进程不能直接操作内核。具体的实现方式基本都是由操作系统将虚拟地址空间划分为两部分,一部分为内核空间,另一部分为用户空间。针对 Linux 操作系统而言,最高的 1G 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF)由内核使用,称为内核空间。而较低的 3G 字节(从虚拟地址 0x00000000 到 0xBFFFFFFF)由各个进程使用,称为用户空间。
-
IIC
IIC标准速率为100Kbit/s,快速模式400Kbit/s
-
嵌入式(系统)理解?
嵌入式系统有别于通用计算机(PC),嵌入式系统强调以应用为中心,以计算机技术为基础,软硬件可配置(需要什么功能就应该添加什么硬件以及实现相关软件驱动、应用,比如电饭煲温度调控),对功能、可靠性、成本、体积、功耗有严格约束的专用计算机(只适用于某种特定场景的应用,相较于PC体积更小、功耗较小,对实时性、可靠性要求更高)。(实时性:wxworks导弹发射)
一般的嵌入式系统没有用到操作系统,只是由一个单个程序实现整个控制逻辑(通俗讲就是在主函数的一个while循环里面轮询地执行整个功能),比如51单片机。当然当这个嵌入式处理器具有中断功能时,比如STM32,便可实现以中断触发的前后台处理模式,避免了轮询模式对CPU资源造成的浪费(每次对每个外设都要询问一便,有时候有些外设时不工作的;有些外设速度快,已经准备好被系统读取,但是由于轮询一定要先询问完前面的外设才能轮到这个外设,降低了实时响应性),能够协调各种外设间的速度差异,提高系统的工作效率。当然有些情形下嵌入式系统用到了操作系统会让整个系统更加合适一些。就我个人项目开发经历而言,移植了操作系统后开发难度降低了很多,整个工程的结构看着也很清晰、很舒适。比如我又两个任务,一个需要一秒执行依次,一个需要三秒执行一次。如果没有操作系统,那么我一般就会用到两个定时器,一个定时器中断一秒触发一次、另一个三秒,并将这两个任务要做的事情分别放到两个中断处理函数里面就行。但是有操作系统就不一样了,首先不需要自己实现延时函数(delay.c),比如ucosii就有提供OSTimeDly()等一系列api,我们只要配置好系统时钟中断就可以了。其次,要实现两个任务,只要调用OSTaskCreate()建立两个任务,然后再两个任务函数里面的while()循环里面一个delay1秒、一个3秒就行。如果还要增加一个任务,只要再OSTaskCreate就行,不用再使用额外的定时器。虽然在任务调度、上下文切换的时候操作系统会消耗一点CPU资源,但是优秀的实时调度算法可以很好地克服这些缺点,比如ucosii的优先级位图法。
所以我现在做的四轴项目正是在体验、深入了解嵌入式系统这么一个过程。
-
OSTaskCreate做的事情
首先创建任务时会指定一个优先级,ucosii一般有64个优先级,一开始程序会检查该优先级是否已经被其他任务占用,如果占用则直接退出创建任务。
若没有其他任务占用,然后就会进行任务堆栈初始化以及任务TCB初始化。操作系统在初始化时会创建64个空的任务TCB结构体,TCB结构体包括栈顶指针、延时数、状态、优先级等变量,TCB初始化时会对他们赋值。
TCB初始化完成后,再判断操作系统是否正在运行,如果在运行则直接进行任务调度,从就绪队列中找到最高优先级任务执行。如果操作系统没在运行,则退出OSTaskCreate,完成任务的创建。
-
优先级位图法
当需要从就绪队列找出最高优先级任务时则用到了优先级位图法。因为如果采用遍历就绪队列中所有TCB的话时间复杂度时O(n),这是个不确定的量,依赖于当前就绪队列任务数。为了做到实时性,采用牺牲空间换取时间的方法实现了时间复杂度O(1)。OSRdyGrp、OSRdyTbl[]表示哪些优先级的任务就绪
-
使任务进入就绪队列:
OSRdyGrp |= ptcb->OSTCBBitY; OSRdyTbl[ptcb->OSTCBY] |= ptcb->OSTCBBitX;
-
从就绪队列中找出最高优先级:
y = OSUnMapTbl[OSRdyGrp]; OSPrioHighRdy = (y<<3) + OSUnMapTbl[OSRdyTbl[y]];
-
-
Linux基本操作?
文件查找、删除、复制、移动、修改;gcc命令;
-
git基本操作?
-
基本操作
建立git仓库:git init
复制远程: git clone ssh://user@domain.com/repo.git
添加远程仓库: git remote add origin xxxxx.git
添加文件到缓存区: git add [files]
提交commit: git commit -m "xxx"
提交到远程仓库: git push origin master
拉取远程仓库文件: git pull
-
分支管理
添加分支: git checkout -b [newbranch]
删除分支: git branch -d [branch]
切换分支: git checkout [branch]
合并分支: git merge [branch]
-
版本回退:
回退到指定版本: git reset --hard [commitid]
-
-
C语言掌握程度?
指针大小:32机器上四个字节,64位机器上八个字节
-
arm汇编作用?
直接操作处理器的寄存器,任务上下文切换需要对处理器的寄存器进行保存和恢复,所以要用到汇编
-
Altium Designer掌握程度?
能设计元器件封装并绘制原理图、PCB板
-
逻辑分析仪怎么用?
分析一段时间的方波时序
-
CAN总线?
CAN 总线是一个广播类型的总线,所以任何在总线上的节点都可以监听总线上传输的数据。也就是说总线上的传输不是点到点的,而是一点对多点的传输,这里多点的意思是总线上所有的节点。
-
X86、arm处理器体系结构?
-
Java、C++特性?
-
makefile?
makefile就像一个Shell脚本一样
-
CPSR寄存器
7:0: 控制位,其中[4:0]位为模式位(用户、快中断、中断、管理、中止、未定义、系统),[7]位为IRQ中断标志,[6]FIQ中断标志,[5]工作状态位:thumb、ARM状态
27:8:保留
31:28:由高到低分别为N(负数位)、Z(零位)、C(借位位)、O(溢出位)
-
B、BL、BLX
B:直接跳转
BL:跳转前将PC保存在LR
BX:跳转时切换状态,最低位为1切换成thumb状态,最低为为0切换成ARM状态(ARM寻址的地址总是2的倍数,如GPIOA的DATA寄存器地址为0x40004000,GPIOA的ODR寄存器地址为0x4000450C,它们的最低位都为0)
-
thumb、ARM、thumb-2
-
ARM状态:arm处理器工作于32位指令的状态,所有指令均为32位
-
thumb状态:arm执行16位指令的状态,即16位状态
-
thumb-2状态:这个状态是ARM7版本的ARM处理器所具有的新的状态,新的thumb-2内核技术兼有16位及32位指令,实现了更高的性能,更有效的功耗及更少地占用内存。总的来说,感觉这个状态除了兼有arm和thumb的优点外,还在这两种状态上有所提升,优化。
-
-
ucosii 任务调度、上下文切换?
任务调度时机:任务创建时、操作系统开始时、任务进入等待队列中、时钟中断结束有任务进入就绪队列。
上下文切换:保存当前任务现场(PC、R0-R12、LR、CPSR),切换到新任务,恢复新任务堆栈现场
-
NOR flash、NAND flash
NOR flash:较长时间抹写,但是提供完整寻址与数据总线。
NAND flash:较快抹写速度,但是只能以块的形式进行读写。
-
cortex-m3m4启动过程
-
初始化堆栈指针SP=_initial_sp : STM32的中断向量表规定第一行必须是SP地址,第二行是复位中断入口地址,上电后,CPU首先就会读这两个值,分别存为SP和PC寄存器。上述流程第一行_initial_sp就是SP地址。
-
初始化PC指针,令其=Reset_Handler
-
初始化中断向量表
-
配置系统时钟
-
调用C库函数_main(_main是IDE自带的mcu初始化程序,包括堆栈、ram等初始化并自动跳转到main)
-
-
STM32时钟树、中断机制?
时钟树配置:HSI、HSE、PLL(HSI、HSE、(/M *N /P))-> SYSCLK
中断机制:启动文件里面已经建立了中断向量表,向量表里面分别存储了对应中断处理函数的地址
-
PCB电气设计规范?
-
互补滤波算法?
陀螺仪积分误差和时间成正比,加速度测出来的角度变化也是随时间成正比,用后者补偿前者。
-
PID?
“工具人”,根据姿态状况自动进行调节以达到用户设定值。
-
DMA
DMA提供了一个关于数据的高数传输通道,这个通道不占用CPU的资源。换句话说,通过DMA通道,你在传输大规模数据的时候CPU同时也能够去干其他事。
-
问面试官问题
只能工作3个月吗?学院要求有6个月的实习期。房补餐补。
-
int getchar()
我们用getchar()来读字符,但是EOF是整形的,为了能够当EOF出现时能够正确接收到,一般使用int类型的变量来接收getchar的返回值
-
链接器
链接器同时会引入标准C函数库中任何被该程序所用到的函数,而且他可以搜索程序员自己的程序库,将其中需要使用的函数也链接到程序中。
-
三字母词(trigraphs)
出现三字母词时编译会出现warnning
-
枚举类型声明
typedef enum { OK = 1, ERROR = 0 } Status; 未指明值时默认第一个为0,比前面大一
-
指针声明
int* a,b,c;//只有a是指针
-
const
int a[10]; int * const a; a=malloc(10*sizeof(int));
两者是一致的,都不能改变指针的值(即指向),但是可以改变指针指向的内存中的值。
-
链接属性
链接器链接各文件引用的函数形成可执行文件。external表明不同文件中表示一个实体,internal表明不同实体。
-
static关键字
当它用于函数定义或者代码块之外的变量声明时。static关键字用于修改标识符的链接属性,从external改为internal,但标识符的存储类型和作用域不受影响。用这种方式声明的函数或变量只能在声明他们的源文件中访问。
当用于代码块内声明变量时,自动类型变为静态类型,但变量的链接属性和作用域不受影响。这种变量在程序执行之前创建,直到整个程序结束。
-
作用域、链接属性和存储类型总结
变量类型 声明的位置 是否存在于堆栈 作用域 如果声明为static 全局 所有代码块之外 否 从声明处到文件尾 不允许从其他源文件访问 局部 代码块起始处 是 整个代码块 变量不存储于堆栈中,它的值在程序整个执行期一直保持 形式参数 函数头部 是 整个函数 不允许 -
变量作用域
static char b = 2; void y(void) { } int a = 1; void x(void) { int c = 3; static float d = 4; }
y函数不能使用a变量。
-
悬空else
else语句从属于最靠近他的不完整的if语句
-
switch
case只定义入口点,如果没有break的话就会一直执行
-
=
连等表达式最好左值都是同类型,否则会出现数据截断的问题
-
结合方向
单目运算符结合方向从左到右
-
逗号运算符
整个表达式最终值为最后一个表达式的值。
while(x<10) b+=x, x+=1;
-
1[a]
1[a]和a[1]意义完全一样,因为会翻译成*(a+1)
-
数组与指针
char message[]="hello"; char *message="hello";
两者不一样。前者为初始化列表,而后面的则表示一个字符串常量。
-
结构体变量对齐问题
-
位段
减少结构体变量浪费的空间。
-
联合
联合的所有成员引用的是内存中的相同位置。
-
链表
- 插入节点
#include <stdio.h> #include <stdlib.h> typedef union { int i; float f; char c; } Value; typedef struct NODE { struct NODE* next; Value value; } Node; typedef enum { TRUE = 1, FALSE = 0 } Status; //插入新节点到末尾 Status InsertNode(Node** ppHead, Value value) { Node *currNode, *preNode; currNode = *ppHead; preNode = NULL; //遍历到末尾 while (currNode != NULL) { preNode = currNode; currNode = currNode->next; } //申请新节点 Node* newNode = (Node*)malloc(sizeof(Node)); newNode->value = value; newNode->next = NULL; //插入新节点 if (preNode == NULL) *ppHead = newNode; else preNode->next = newNode; return TRUE; } //反转链表:要想改变指针指向只有传指针的指针 void ReverseNodeList(Node** ppHead) { //边界判断 if (*ppHead == NULL || (*ppHead)->next == NULL) return; //将链表分为两部分,[1]和[2-n] Node* curNode = *ppHead; *ppHead = (*ppHead)->next; curNode->next = NULL; //将[2-n]逆转 ReverseNodeList(ppHead); //将[1]放到逆转后的[2-n]的后面 Node* nextNode = *ppHead; while (nextNode->next != NULL) nextNode = nextNode->next; nextNode->next = curNode; return; } //合并链表 Node* MergeNodeList(Node* pHead1, Node* pHead2) { //边界判断 if (pHead1 == NULL) return pHead2; else if (pHead2 == NULL) return pHead1; //将两链表中较小值取出放入新链表,并将剩下两个链表进行合并后接入新链表后面 Node* mergeNode = NULL; if (pHead1->value.i < pHead2->value.i) { mergeNode = pHead1; mergeNode->next = MergeNodeList(pHead1->next, pHead2); } else { mergeNode = pHead2; mergeNode->next = MergeNodeList(pHead1, pHead2->next); } return mergeNode; } void PrintNodeList(Node* pHead) { Node* currNode = pHead; while (currNode != NULL) printf("%d\n", currNode->value.i), currNode = currNode->next; } int main(void) { int a[5] = { 1, 3, 5, 7, 9 }; Node* head = NULL; for (int i = 0; i < 5; i++) InsertNode(&head, *(Value*)(void*)&a[i]); int b[5] = { 2, 4, 6, 8, 10 }; Node* head2 = NULL; for (int i = 0; i < 5; i++) InsertNode(&head2, *(Value*)(void*)&b[i]); Node* mergeNode = MergeNodeList(head, head2); PrintNodeList(mergeNode); return 0; }
-
二叉树
#include<queue> //按层遍历 void func(BTNode *pRoot){ //边界判断 if(pRoot==nullptr) return; queue<BTNode*> q; q.push(pRoot); while(q.size()){ BTNode *currNode=q.front(); q.pop(); printf("%d ",currNode->val); if(currNode->left!=nullptr) q.push(currNode->left); if(currNode->right!=nullptr) q.push(currNode->right); } }
-
所有指针大小一样吗?
一样。他们存的都是地址,只是在间接调用时的解读方式不一样。但是进行+、-等运算时,步长是和指针的类型有关的。其次,在不同平台上也不一样,32位机器和64位机器上的不一样,但是同一平台上的一样。
-
函数指针
//查找节点 Node *SearchNode(Node *pHead,void const *pValue,int (*compare)(void const *,void const *)){ Node *currNode=pHead; while(currNode!=NULL){ if(compare(&currNode->value,pValue)) break; currNode=currNode->next; } return currNode; } //比较函数 int compare_int(void const *a,void const *b){ return *(int*)a==*(int*)b; } ... //调用 Node *temp=SearchNode(head,&value,compare_int);
-
字符串常量
字符串常量实际上是一个指针。所以
//表示指向y的指针。 "xyz"+1 //表示x *"xyz" //表示z "xyz"[2]
-
宏函数
//每个参数和总表达式外加括号 #define ADD(x,y) ((x)+(y)) //do-while(0)妙用 #define DELETE_POINTER(p) \ do \ { \ if(NULL != p) \ delete p; \ p = NULL; \ }while(0)
-
#include预处理和链接器链接
#include预处理是将函数声明进行包含,类似传值调用;而链接器是将函数实现进行链接,类似传址调用。
-
sizeof
sizeof是在预处理器完成工作以后而发挥作用的。所以
#if sizeof(int) == 2 typedef long int32; #else typedef int int32; #endif
是错的。
-
递归与迭代
如果递归算法在尾部出现,所以我们可以使用迭代更有效地实现这个算法。
-
泛型
毫不吃惊的是,用C语言实现泛型是相当困难的,因为它的设计远早于泛型这个概念被提出之时。泛型是面向对象编程语言处理得比较完美的问题之一。
-
内存不够
-
地址空间不隔离:所有程序直接访问物理内存,恶意程序很容易修改其他程序内存数据。希望其中一个任务失败也不会影响其他任务。
-
内存使用效率低:大量数据换入换出。
-
运行地址不确定:
解决:虚拟地址,映射
-
-
Linux多线程
fork:复制当前进程。fork返回新任务的速度非常快,因为fork并不复制原任务的任务空间,而是和原任务一起共享一个写时复制的内存空间。
Linux的fork操作是采取内存共享、写时复制的策略,就是说只有当父子进程一方对一块内存进行写操作时内核会就会复制原来的这块内存到一块新的物理内存上让另一个进程对应的值还是不变。那既然涉及到新的物理内存,为啥他们的地址还是不变?因为打印的地址时虚拟地址,就算虚拟地址一样不代表物理地址一样。因为操作系统MMU的存在。
-
fork
如果父进程在创建子进程之前有锁且对锁进行了操作。那么fork子进程后,自己成会继承父进程中所有锁及所得状态,但是fork之后父子各自对锁的操作时不可见的。即即使fork后父进程解锁了,但是子进程中的锁还是加锁状态,子进程是无法再进行加锁的。
fork不仅继承父进程中的栈堆还继承数据段和bss段内容。
-
同步和锁
-
二元信号量:只有两种状态:占用和非占用,适用只能被唯一一个线程独占访问的资源。但是一个线程占据一个锁可以被其他线程释放。
-
互斥量:于二元信号量很类似,只是一个线程占据一个锁只能由它自己释放。
-
信号量:一个初始值为N的信号量允许N个线程并发访问。
-
读写锁:可多读不可多写。
-
临界区:和互斥量相同性质,但是互斥量在不同进程中式可见的,临界区却只针对本进程。
-
-
ARM7 ARM9 ARM Cortex M3 M4 有什么区别?
一般情况下ARM7 Cortex-M3 Cortex-M4可以认为是一类,M3和M4都是针对微控制器(单片机)设计的,一般运行嵌入式操作系统或者不带操作系统。而ARM7更多时候也是作为单片机,比如一些蓝牙芯片是ARM7的。Cortex-M3和M4相比,M4有浮点数运算单元和SIMD指令(DSP)(可以加快一些数学运算的速度),都有功能较强的中断控制器。ARM7架构较老,运算性能和中断性能较差,基本上可以被Cortex-M3和M4完全替代。ARM9一般看到的是应用级处理器,运行Linux或者OpenWRT之类的操作系统。ARM9一般主频会比较高,所以处理速度比大部分微控制器快。ARM9开发相对更加复杂,不过可以用linux下的驱动模块。这些都是处理器的IP核,可以大致相当于CPU的架构。不同厂家用同一款IP核做出来的芯片可能差别很大。具体要看各个厂家的数据手册,整体上性能ARM9>Cortex-M4>Cortex-M3>ARM7。
-
ucosii中的临界区
-
如果是arm9处理器,里面有个cpsr寄存器,其中第8位为IRQ中断位,如果关闭它那么程序将不会响应所有将关闭所有可屏蔽中断的异常(IRQ中断),但不包括FIQ、NMI、硬件中断等。
OSCPUSaveSR MRS R0,CPSR ORR R1,R0,#0x80//IRQ位置1 MSR CPSR_c,R1 MOV PC,LR OSCPURestoreSR MSR CPSR_c,R0 MOV PC,LR
-
如果是cortex-m3、m4系列处理器,里面有一个中断屏蔽寄存器PRIMASK,置1后,将关闭所有可屏蔽中断的异常,只剩NMI和硬fault,默认值为0。
OS_CPU_SR_Save MRS R0,PRIMASK CPSID I//关中断 BX LR OS_CPU_SR_Restore MSR PRIMASK,R0 BX LR
-
-
编译过程
-
词法分析:将程序内容按关键字、标识符、字面量、特殊符号进行扫描识别。
-
语法分析:由语法分析器生成的语法树就是以表达式为结点的树(赋值表达式、加法表达式、乘法表达式、括号表达式。。。)。这种树将各种词连接起来。
-
语义分析:语法分析能分析出各个表达式的成分,但是无法分析这些表达式是否有意义,比如一个浮点数和指针相加。语义分析就是分析静态语义,即在编译过程能确定的语义。
-
中间代码生成:进行一定优化,比如加法表达式中如果两个加数不是变量而是常数2和3那么将直接将这个加法表达式用常数5代替。优化后的代码形成三地址码等中间代码。
-
目标代码生成与优化:将中间代码优化并转换成与处理器相关的汇编代码
-
-
汇编过程
将汇编代码转换成机器可以执行的指令。
-
(静态)链接过程
将各个模块之间相互引用的部分都处理好。主要包括了地址和空间分配、符号决议、重定位等等。
-
程序指令分开存储原因:
-
指令时只读的,而数据时可读写的。分开来可以防止恶意指令修改指令内容。
-
对于现代CPU的Cache体系,一般分为数据缓存和指令缓存分离,所以对提高CPU的缓存命中率提高有好处。
-
共享内存。尤其对于有动态链接的系统而言,大量进程的指令都是一样的。这样节省了很多空间。
-
-
大小端模式
-
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
-
小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
-
-
自定义段
void f() { __attribute((section(".data"))) int temp = 3; }
这样就可以将temp变量放到data段。
-
C++符号修饰
编译器和链接器在连接过程中,通过符号修饰机制区分不同函数和变量:
int func(int); float func(float); class C { int func(int); class C2 { int func(int); }; }; namespace N { int func(int); class C { int func(int); }; }
函数签名 修饰后名称(符号名) int func(int) _Z4funci float func(float) _Z4funcf int C::func(int) _ZN1C4funcEi int C::C2::func(int) _ZN1C2C24funcEi int N::func(int) _ZN1N4funcEi int N::C::func(int) _ZN1N1C4funcEi 为了避免在C++程序中对其中C代码中的函数、变量进行符号修饰,常用
extern "C"对C代码进行标识已防止被符号修饰。 -
调试信息
在目标文件中一般都会由大量和debug有关的段,这些段在目标文件和可执行文件中占用了很大空间,往往比程序的代码和数据本身大好几倍,所以当我们开发完程序要发布的时候需要将这些调试信息去掉。在Linux中可以通过
strip命令来去掉ELF文件中的调试信息。 -
强符号弱符号
一、概述
在 C 语言中,函数和初始化的全局变量(包括显示初始化为 0)是强符号,未初始化的全局变量是弱符号。
对于它们,下列三条规则使用:
-
同名的强符号只能有一个,否则编译器报 "重复定义" 错误。
-
允许一个强符号和多个弱符号,但定义会选择强符号的。
-
当有多个弱符号相同时,链接器选择最先出现那个,也就是与链接顺序有关。
二、哪些符号是弱符号?
我们经常在编程中碰到一种情况叫符号重复定义。多个目标文件中含有相同名字全局符号的定义,那么这些目标文件链接的时候将会出现符号重复定义的错误。比如我们在目标文件 A 和目标文件 B 都定义了一个全局整形变量 global,并将它们都初始化,那么链接器将 A 和 B 进行链接时会报错:
1 b.o:(.data+0x0): multiple definition of `global' 2 a.o:(.data+0x0): first defined here
这种符号的定义可以被称为强符号(Strong Symbol)。有些符号的定义可以被称为弱符号(Weak Symbol)。对于 C 语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号 (C++ 并没有将未初始化的全局符号视为弱符号)。我们也可以通过 GCC 的
"__attribute__((weak))"来定义任何一个强符号为弱符号。注意,强符号和弱符号都是针对定义来说的,不是针对符号的引用。比如我们有下面这段程序:extern int ext; int weak1; int strong = 1; int __attribute__((weak)) weak2 = 2; void __attribute__((weak)) f(); int main() { f(); return 0; }
上面这段程序中,"weak" 和 "weak2" 是弱符号,"strong" 和 "main" 是强符号,而 "ext" 既非强符号也非弱符号,因为它是一个外部变量的引用。
若链接器链接时没有发现由外部强定义的f()那么f()的值为0。
-
-
交换
void swap(int *a,int *b){ *a ^= *b ^= *a ^= *b; }
-
全局构造和析构
全局对象的构造函数和析构函数在main函数之前之后运行,ELF文件中有两个段.init和.fini,Glibc会安排执行这两个段
-
NUL、NULL
一个‘L’的NUL用于结束一个ASCII字符串。两个‘L’的NULL用于表示什么也不指向(空指针)。
-
typedef和#define
//例子一 #define peach int unsigned peach i;//没问题 ... typedef int peach; unsigned peach i;//错误 //例子二 #define pChar char* pChar a,b,c;//只有a是指针 ... typedef char* pChar; pChar a,b,c;//都是指针
-
C语言设计哲学
所有特性都不需要隐式的运行时支持
-
C++对C语言的改进
C++允许一个常量整数来定义数组的大小:
//c++中正确,c中错误 const int size=5; int a[size];
-
模式
编辑模式、命令模式、底线模式
-
命令
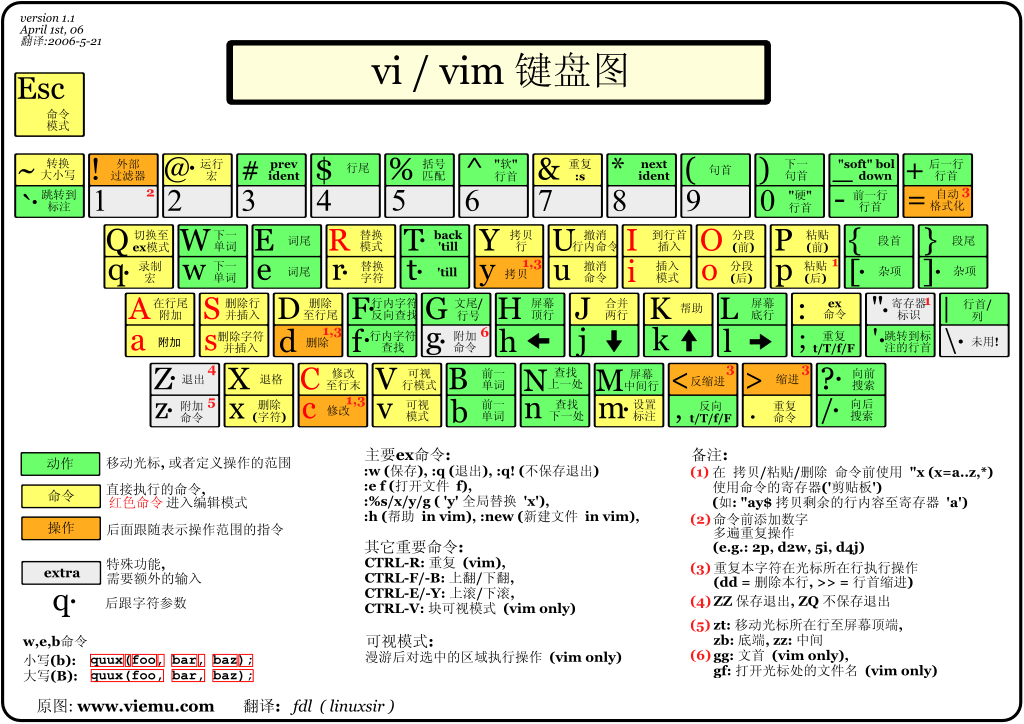
移动光标的方法 30↓ 向下移动 30 行 h 或 向左箭头键(←) 光标向左移动一个字符 j 或 向下箭头键(↓) 光标向下移动一个字符 k 或 向上箭头键(↑) 光标向上移动一个字符 l 或 向右箭头键(→) 光标向右移动一个字符 [Ctrl] + [d] 屏幕『向下』移动半页 [Ctrl] + [u] 屏幕『向上』移动半页 n[space] 向后面移动 20 个字符距离。 0 或功能键[Home] 这是数字『 0 』:移动到这一行的最前面字符处 (常用) $ 或功能键[End] 移动到这一行的最后面字符处(常用) G 移动到这个档案的最后一行(常用) nG n 为数字。移动到这个档案的第 n 行。 gg 移动到这个档案的第一行,相当于 1G 啊! (常用) n[Enter] n 为数字。光标向下移动 n 行(常用) 搜索替换 /word 向光标之下寻找一个名称为 word 的字符串。例如要在档案内搜寻 vbird 这个字符串,就输入 /vbird 即可! (常用) ?word 向光标之上寻找一个字符串名称为 word 的字符串。 n 这个 n 是英文按键。代表重复前一个搜寻的动作。举例来说, 如果刚刚我们执行 /vbird 去向下搜寻 vbird 这个字符串,则按下 n 后,会向下继续搜寻下一个名称为 vbird 的字符串。如果是执行 ?vbird 的话,那么按下 n 则会向上继续搜寻名称为 vbird 的字符串! N 这个 N 是英文按键。与 n 刚好相反,为『反向』进行前一个搜寻动作。 例如 /vbird 后,按下 N 则表示『向上』搜寻 vbird 。 :1,$s/word1/word2/gc 或 :%s/word1/word2/gc 从第一行到最后一行寻找 word1 字符串,并将该字符串取代为 word2 !且在取代前显示提示字符给用户确认 (confirm) 是否需要取代!(常用) 删除、复制与贴上 x, X 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) nx n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 dd 删除游标所在的那一整行(常用) ndd n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) yy 复制游标所在的那一行(常用) nyy n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) p, P p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) u 复原前一个动作。相当于撤回(常用) [Ctrl]+r 重做上一个动作。相当于反撤回(常用) . 不要怀疑!这就是小数点!意思是重复前一个动作的意思。 如果你想要重复删除、重复贴上等等动作,按下小数点『.』就好了! (常用) 指令行的储存、离开等指令 :w 将编辑的数据写入硬盘档案中(常用) :w! 若文件属性为『只读』时,强制写入该档案。不过,到底能不能写入, 还是跟你对该档案的档案权限有关啊! :q 离开 vi (常用) :q! 若曾修改过档案,又不想储存,使用 ! 为强制离开不储存档案。 :wq 储存后离开,若为 :wq! 则为强制储存后离开 (常用) :w [filename] 将编辑的数据储存成另一个档案(类似另存新档) :r [filename] 在编辑的数据中,读入另一个档案的数据。亦即将 『filename』 这个档案内容加到游标所在行后面 :n1,n2 w [filename] 将 n1 到 n2 的内容储存成 filename 这个档案。 :! command 暂时离开 vi 到指令行模式下执行 command 的显示结果!例如『:! ls /home』即可在 vi 当中察看 /home 底下以 ls 输出的档案信息! :set nu 显示行号,设定之后,会在每一行的前缀显示该行的行号 :set nonu 与 set nu 相反,为取消行号! 添加注释 (和搜索替换类似,注意转义影响) 在 10 - 20 行添加 // 注释 :10,20s#^#//#g 在 10 - 20 行删除 // 注释 :10,20s#^//##g 在 10 - 20 行添加 # 注释 :10,20s/^/#/g 在 10 - 20 行删除 # 注释 :10,20s/#//g

-
vector
vector就是一个动态数组,里面有一个指针指向一片连续的内存空间,当空间不够装下数据时,会自动申请另一片更大的空间(一般是增加当前容量的50%或100%),然后把原来的数据拷贝过去,接着释放原来的那片空间;当释放或者删除里面的数据时,其存储空间不释放,仅仅是清空了里面的数据。
#include<iostream> #include<vector> using namespace std; int main(void) { vector<int> a; cout << "addr a:"<<&a << endl; for (int i = 0; i < 10; i++) { a.push_back(i); } int *b = &a[0]; int *e = &a[7]; vector<int> c = vector<int>(b, e); vector<int> d = vector<int>(a.begin(), a.end()); cout << "addr c:" << &c << endl; cout << "addr d:" << &d << endl; return 0; }
vector构造函数vector(begin,end):复制[begin,end)区间内另一个数组的元素到vector中。所以对新vector的更改不会影响原vector的内容。
-
构造函数
Apple a=Apple();//显示调用构造函数 Apple b();//同上 Apple *c=new Apple(); Apple d;//隐式调用默认构造函数
构造函数还可以这样用:
Apple a; a= Apple();
此时a对象已经存在,第二条语句的意思是临时构建一个对象(附带初值),然后将这个临时变量赋给对象a,之后再删除临时对象(会调用临时对象的析构函数)。
在C++11中可以这样初始化:
Apple a={1,2}; //Apple a=Aplle(1,2); -
友元函数
友元函数的原型在类声明中,由于加了friend关键字,所以不能通过成员运算符来调用;虽然友元函数不是成员函数,但是和成员函数的访问权限相同。
<<操作符重载ostream & operator<<(ostream & os,const ClassType & t){ os<<t.value; return os; }
-
隐式复制构造函数
隐式复制构造函数是按值进行复制的。
对于Apple类:
Class Apple{ private: int i; char *str; public: ······ }若Apple的一个对象a已经初始化过,则
Apple b=a;
相当于
b.i=a.i; b.str=a.str;
当打印对象b的str时没问题,因为和a是指向同一块内存。但是当删除a时,连带字符串内容也删掉了。此时再访问b的str就会报错。
-
隐式赋值运算符
与隐式复制运算符类似
Apple b; b=a;
此时调用的是隐式赋值运算符而不是隐式复制构造函数。
-
静态类成员函数
只能使用静态成员变量不能使用其他成员变量,因为static类函数不属于任何对象。
-
派生类
派生类因为不能直接访问基类的私有成员数据,所以派生类构造函数的要点有:
-
首先创建基类对象。
-
派生类构造函数应该通过成员初始化列表将积累信息传递给基类构造函数。
-
派生类构造函数应该初始化派生类新增的数据成员。
-
-
派生类和基类关系
-
派生类可以使用积累的方法,前提是基类方法不是私有的。
-
基类指针(引用)可以在不进行显式转换的情况下指向(引用)派生类对象。然而基类指针(引用)只能使用基类方法。
Apple apple; Fruit *f1 = apple; Fruit &f2 = apple;
-
与上点相反却不行不能派生类指针(引用)指向(引用)基类。
-
-
多态
方法的行为取决于调用该方法的对象。有两种方法实现多态共有继承:
-
在派生类中重新定义基类的方法
-
使用虚方法
-
-
虚函数
如果没有使用关键字virtual,程序将根据引用类型或指针类型选择方法。如果定义了virtual,程序将根据引用或指针指向的对象的类型来选择方法。方法在基类中声明为虚类后,它会在派生类中自动成为虚方法。关键字只用于方法声明中,不用使用在方法定义上。
使用场景:用一个数组来保存所有基类和派生类对象,此时可以用一个指针数组。
析构函数都应该为虚函数。
友元不能是虚函数,因为友元不是成员函数。
-
域解算符
在多态中,派生类方法想要调用基类同名方法必须加以域解算符
void BrassPlus::ViewAcct(){ Brass::ViewAcct(); cout<<maxLoan<<endl; }
-
静态联编、动态联编
-
静态:重载方法的使用:符号修饰
-
动态:基类、派生类方法的使用:虚函数
-
-
protected
对外部而言,protect成员和private成员一样;对派生类而言,protect成员和public成员一样。
-
派生类基类
派生类不能继承基类的构造函数、析构函数、赋值运算符和友元。
-
类的内存模型
需要对齐。虚表指针位于类内存中的第一位,大小为8字节(64位机器)。
//sizeof(test)=4 class test { private: int a; public: // test(/* args */); // ~test(); // virtual void func(); };
//sizeof(test)=16 class test { private: int a; public: // test(/* args */); // ~test(); virtual void func(); };
//sizeof(test)=16 class test { private: int a; int b; public: // test(/* args */); // ~test(); virtual void func(); };
//sizeof(test)=16 class test { private: double a; public: // test(/* args */); // ~test(); virtual void func(); };
-
空类的Size为1,应为编译器自动添加了一个标记字节。(Size为0就太诡异了!)
-
静态数据和静态函数,配置到对象之外。
-
非静态函数,配置到对象之外。
-
含有虚函数的对象,配置有一个指向类虚拟表(vtbl)的指针。
-
纯虚对象(接口对象),配置有一个指向类虚拟表的指针。
-
-
字典序排列
next_permutation算法
定义
升序:相邻两个位置ai < ai+1,ai 称作该升序的首位
步骤(二找、一交换、一翻转)
-
找到排列中最后(最右)一个升序的首位位置i,x = ai
-
找到排列中第i位右边最后一个比ai 大的位置j,y = aj
-
交换x,y
-
把第(i+ 1)位到最后的部分翻转
还是拿上面的21543举例,那么,应用next_permutation算法的过程如下:
-
x = 1;
-
y = 3
-
1和3交换,得23541
-
翻转541,得23145
23145即为所求的21543的下一个排列。
-
-
C结构体、C++结构体、C++类区别C
C结构体只有成员变量,是不同数据的聚合,C++结构体内存模型和类几乎一样,只是默认访问权限不一样
-
C++内联函数
函数调用在执行时,首先要在栈中为形参和局部变量分配存储空间,然后还要将实参的值复制给形参,接下来还要将函数的返回地址(该地址指明了函数执行结束后,程序应该回到哪里继续执行)放入栈中,最后才跳转到函数内部执行。这个过程是要耗费时间的。
另外,函数执行 return 语句返回时,需要从栈中回收形参和局部变量占用的存储空间,然后从栈中取出返回地址,再跳转到该地址继续执行,这个过程也要耗费时间。
如果函数内部执行代码很少,这些调用函数的开销就不能够忽略。
-
C++map哈希表内存模型、读取删除时间复杂度
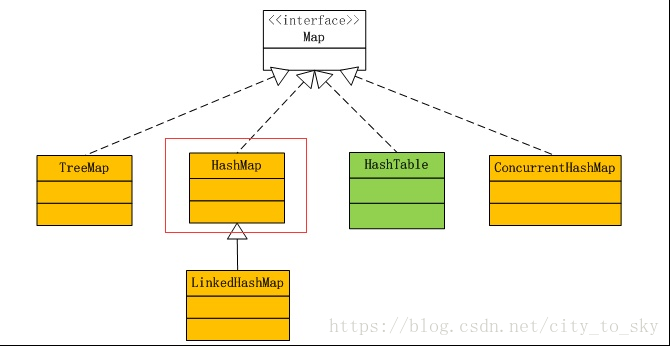
上面可以看到Map接口的几个实现方式。简要说明:
TreeMap是基于树(红黑树)的实现方式,即添加到一个有序列表,在O(log n)的复杂度内通过key值找到value,优点是空间要求低,但在时间上不如HashMap。C++中Map的实现就是基于这种方式
HashMap是基于HashCode的实现方式,在查找上要比TreeMap速度快,添加时也没有任何顺序,但空间复杂度高。C++ unordered_Map就是基于该种方式。
HashTable与HashMap类似,只是HashMap是线程不安全的,HashTable是线程安全的,现在很少使用
ConcurrentHashMap也是线程安全的,但性能比HashTable好很多,HashTable是锁整个Map对象,而ConcurrentHashMap是锁Map的部分结构
但由于可能会有多个key值对应同一个index,为了避免冲突,其实每个数组元素里存储的是链表结构。当添加函数检测到index对应的元素已经有值了以后,它就会将key值和value作为子节点添加到该index所在元素的尾部节点。如果检测到key值相同,则更新value.当链表的长度大于8后,会自动转为红黑树,方便查找.
-
C++智能指针
auto r = make_shared<int>(42);//r指向的int只有一个引用者 r=q;//给r赋值,令它指向另一个地址 //递增q指向的对象的引用计数 //递减r原来指向的对象的引用计数 //r原来指向的对象已没有引用者,会自动释放
当指向一个对象的最后一个shared_ptr被销毁时,shared_ptr类会自动销毁此对象,它是通过另一个特殊的成员函数-析构函数完成销毁工作的,类似于构造函数,每个类都有一个析构函数。析构函数控制对象销毁时做什么操作。析构函数一般用来释放对象所分配的资源。shared_ptr的析构函数会递减它所指向的对象的引用计数。如果引用计数变为0,shared_ptr的析构函数就会销毁对象,并释放它所占用的内存。
编译时需要加上
--std=c++11。 -
define和const变量区别
-
Linux孤儿进程
-
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
-
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait或waitpid获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。这种进程称之为僵死进程。
-
-
查看shell脚本运行进程情况
-
查看自己进程号:
echo $$ -
查看指定进程是否正在运行,不在运行则启动它:
#!/bin/bash #ps -ef 全进程全格式显示 #grep -w name 查找name进程 #grep -v name 排除name进程 #wc -l 统计行数 PROC_NAME=$1 #$1为命令行第一个参数,这里输入进程名 ProcNumber=`ps -ef |grep -w $PROC_NAME|grep -v grep|wc -l` if [ $ProcNumber -le 0 ];then echo "程序未运行" ./$PROC_NAME else echo "程序正在运行" fi
-
-
ps指令、top指令
ps命令–提供系统过去信息的一次性快照;top命令–这个命令就很有用了
-
进程后台、挂起
#ctrl+z:挂起,程序放到后台,程序没有结束。
#jobs:查看被挂起的程序工作号
恢复进程执行时,有两种选择:fg命令将挂起的作业放回到前台执行;用bg命令将挂起的作业放到后台执行
格式:fg 工作号;bg 工作号
进程:正在执行的一个程序
程序:是一种写好的代码或脚本
&:后台执行,不占用终端
如:xeyes &
-
select、poll、epoll
-
select:用户可以在一个线程内同时处理多个socket的IO请求.但是最大文件描述符数量有限制,最大1024。需要遍历整个描述符集合。
-
poll:和select差不多,但是没有文件描述符数量限制
-
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
-
-
三次握手四次挥手

-
volatile关键字
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:
short flag; void test() { do1(); while(flag==0); do2(); }
这段程序等待内存变量flag的值变为1(怀疑此处是0,有点疑问,)之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:
volatile short flag;
需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
-
求余数
int indexFor(int h, int length) { return h & (length-1); }
-
饿汉式、懒汉式
下面对单例模式的懒汉式与饿汉式进行简单介绍:
饿汉式:在程序启动或单件模式类被加载的时候,单件模式实例就已经被创建。
懒汉式:当程序第一次访问单件模式实例时才进行创建。
如何选择:如果单例模式实例在系统中经常会被用到,饿汉式是一个不错的选择。反之如果单例模式在系统中会很少用到或者几乎不会用到,那么懒汉式是一个不错的选择。