

Constructing cryptocurrency indices based on Reddit texts with NLP to measure uncertainty for downstream time series analysis and predictive forecasting. The goal is to evaluate if the unforecastable component / stochastic process can be measured from textual data as a means of capturing crypto market sentiment and other latent stochastic processes to inform price returns or directional price returns forecasting of cryptocurrencies.
The diagram details a simplified and abstracted overview of some of the ETL processes and index construction flows.

Trained Hedge Detection BERTweet model weights can be found on Hugging Face Hub with a live Hosted Inference API to play around with :)
- Baseline Keyword Based Index
(Lucey et al. 2021) - Expanded Keyword Based Index with Latent Dirichlet Allocation recovered Topics
- Hedge Based Uncertainty Index with BERTweet & Wiki Weasel 2.0
Some simple steps to setting up the repository for ETL, Modelling, etc.
brew install make # OSX
make install # Runs Brew and Poetry Installs
make build # Builds Elasticsearch, Kibana & Postgres images from compose file
poetry shell # Activate venvAll Data extraction, NLP modelling & inferences as well as Index construction pipelines can be called via the CLI interface. Please refer to the documentation below for details:
- Reddit data extraction via Pushshift
-
Extracts all subreddit comments and submissions data for a given list of
subredditsover a period specified bystart_dateandend_date. Note that data is extracted in batches byYear-Monthto handle PushshiftAPI's (PMAW) connection drops / rate limits. -
Data is inserted into and analyzed by
Elasticsearchunder thereddit-cryptoindex by default and serialised locally indata/raw_data_dump/redditas.pklfiles.Usage: cli.py extract-reddit-cry-data [OPTIONS] Extracts data from given subreddits for the specified date range. Options: --subreddits TEXT Subreddits to pull data from [default: ethereum, ethtrader, EtherMining, Bitcoin, BitcoinMarkets, btc, CryptoCurrency, CryptoCurrencyTrading] --start-date [%Y-%m-%d|%Y-%m-%dT%H:%M:%S|%Y-%m-%d %H:%M:%S] Start date [default: 2014-01-01 00:00:00] --end-date [%Y-%m-%d|%Y-%m-%dT%H:%M:%S|%Y-%m-%d %H:%M:%S] End date [default: 2021-12-31 00:00:00] --mem-safe / --no-mem-safe Toggle memory safety. If True, caches extracted data periodically [default: mem- safe] --safe-exit / --no-safe-exit Toggle safe exiting. If True, extraction will pick up where it left off if interrupted [default: no-safe-exit]
- Yahoo! Finance data extraction
- Extracts all Yahoo! Finance Market Data for a given list of
tickersover a period specified bystart_dateandend_date. - Data is inserted into a specified
target-tablein a postgres database.Usage: cli.py extract-yfin-data [OPTIONS] Extracts ticker data from Yahoo Finance Options: --tickers TEXT List of Asset Tickers [default: BTC-USD, ETH-USD, USDT-USD, XRP-USD, BNB-USD, ADA-USD, DOT-USD, LUNA-USD, GC=F, ^GSPC] --start-date TEXT Start date to begin extraction [default: 2014-01-01] --end-date TEXT End date to extract up till [default: 2021-12-31] --interval TEXT Granularity of data [default: 1wk] --target-table TEXT Postgres table to insert data to [default: asset_prices]
- Text Processing / Analysis of Raw Reddit Data
- Uses the ES' Reindex API to move and process existing raw data under
reddit-cryptoto thereddit-crypto-customindex using aCustom Analyzerto handlecryptocurrencyandsocial-mediaspecific terms and patterns. Seees/custom_analyzersfor details.Usage: cli.py es-reindex [OPTIONS] ES reindexing from a source index to a destination index Options: --source-index TEXT Source ES Index to pull data from [default: reddit- crypto] --dest-index TEXT Destination ES Index to insert data to [default: reddit-crypto-custom] --dest-mapping TEXT Destination index ES mapping
- LDA Topic Modelling
- Trains a LDA topic model using
Gensim's Multicore LDA implementation optimized with variational Bayes.Usage: cli.py nlp-toolkit train-multi-lda [OPTIONS] Train multiple iterations of LDA for various Num Topics (K) Options: --raw-data-dir TEXT Directory containing csv files with processed data (sans tokenization) [default: nlp/topic_models/data/processed_re ddit_train_test/train] --gram-level TEXT Unigram or Bigrams [default: unigram] --num-topic-range <INTEGER INTEGER>... Lower and upper bound of K to try out [default: 1, 10] --num-topic-step INTEGER Step size to increment K by within topic range [default: 1] --num-workers INTEGER Number of workers (CPU cores) to use for parallelization [default: 7] --chunksize INTEGER Size of training batches [default: 10000] --passes INTEGER Number of passes through the training corpus [default: 1] --alpha TEXT Alpha val for a priori topic - document distribution [default: symmetric] --eta FLOAT Eta value. See Gensim docs --random-state INTEGER Random seed [default: 42] --save-dir TEXT Where to save relevant dict, model data for each run [default: nlp/topic_models/models/lda] --trained-dict-save-fp TEXT Location of saved dictionary for corpus. Specify to use pre-constructed dict. --trained-bigram-save-fp TEXT Bigram Model Save directory --get-perplexity / --no-get-perplexity Whether to compute log perplexity on each model on a held out test set. [default: get-perplexity] --test-data-dir TEXT File path to test data dir to compute log perplexity on. [default: nlp/topic_models/d ata/processed_reddit_train_test/test]
- Top2Vec Topic Modelling
- Trains a Top2Vec topic model using joint word and document embeddings with the
Doc2Vecalgorithm (Default).Usage: cli.py nlp-toolkit train-t2v [OPTIONS] Trains Top2Vec on a given corpus Options: --data TEXT Corpus data [default: nlp/topic_models/data /processed_reddit_combined/crypto_processed_ reddit_combined_10.csv] --min-count INTEGER Minimum number of counts a word should have to be included [default: 50] --speed TEXT Learning speed. One of learn, fast-learn or deep-learn [default: learn] --num-workers INTEGER Number of CPU threads to train model [default: 7] --embedding-model TEXT Embedding model [default: doc2vec] --umap-low-mem / --no-umap-low-mem Whether to use low mem for UMAP [default: no-umap-low-mem] --hdb-min-cluster-size INTEGER HDBSCAN min cluster size [default: 100] --model-save-dir TEXT Model save directory [default: nlp/topic_models/models/top2vec]
- Finetune BERTweet Hedge Detector with Pop Based Training
- Finetunes a
Hugging Facemodel (VinAI's BERTweetbut can be changed) using SOTAPopulation Based Trainingwith Ray Tune and logs models trained and hyperparameter sweep withWeights & Biases.Usage: cli.py nlp-toolkit pbt-hedge-clf [OPTIONS] Finetunes Hugging Face classifier using SOTA population based training Options: --model-name TEXT Base huggingface hub transformer to finetune on. [default: vinai/bertweet-base] --train-data-dir TEXT Data directory containing csv train and test data for finetuning and eval in specified format. [default: nlp/hedge_classifier/data /szeged_uncertainty_corpus/cleaned_datasets/ train_test/wiki/csv] --model-save-dir TEXT Model save directory location. [default: nlp/hedge_classifier/models] --sample-data-size INTEGER Amount of train and test data to use as a subsample for testing. --num-cpus-per-trial INTEGER Number of CPUs to use per trial (Tesla A100) [default: 8] --num-gpus-per-trial INTEGER Number of GPUs to use per trial (Tesla A100) [default: 1] --smoke-test / --no-smoke-test Whether to run a smoke test. [default: no- smoke-test] --ray-address TEXT Ray address location. If None uses Local. --ray-num-trials INTEGER Number of times to Randomly Sample a point in the Params Grid [default: 8]
- Hedge Classifier Demo
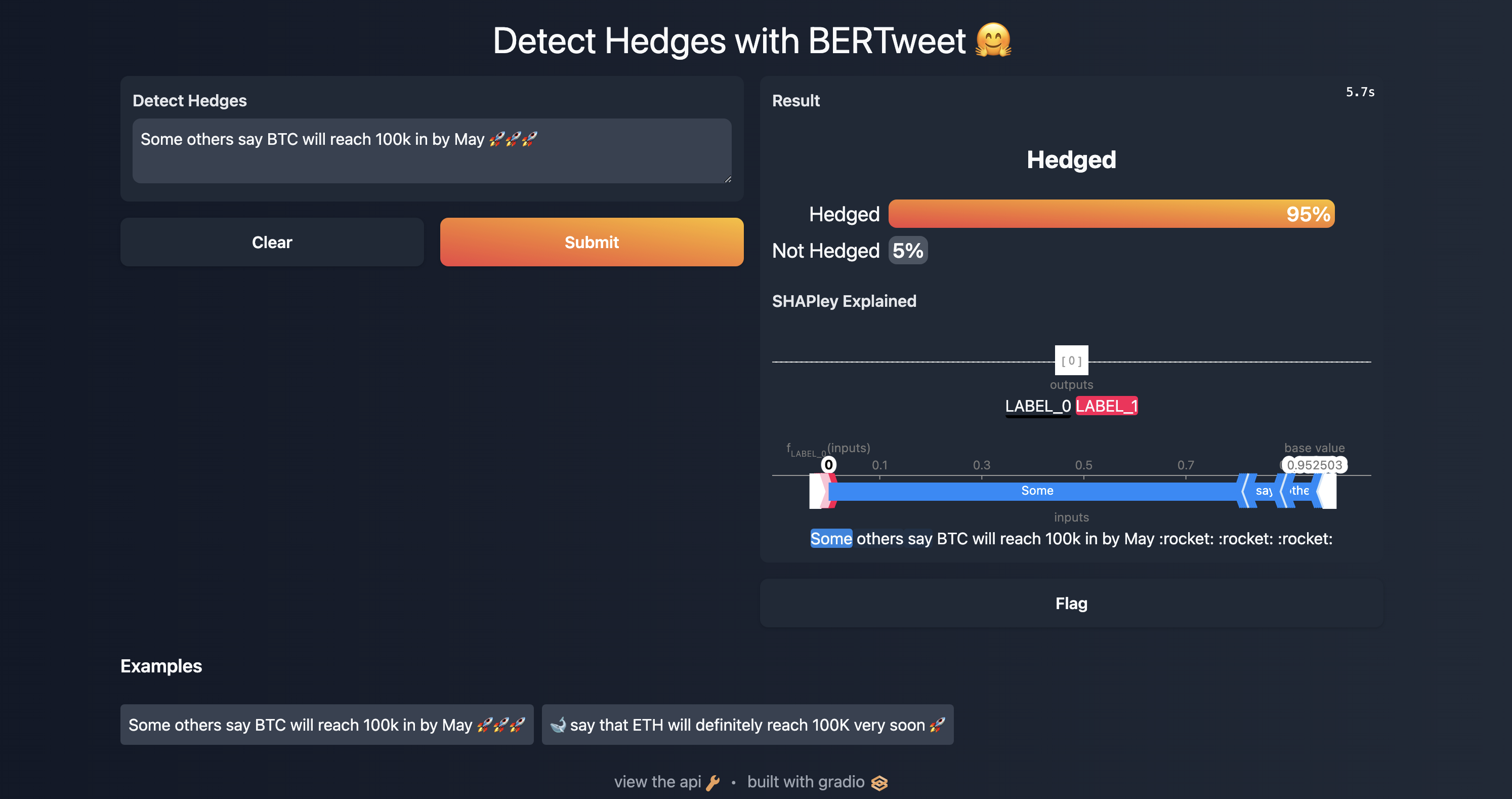

- Launches an App to
demoa given Hedge (Text) Classifier withGradio. SHAPleyvalues for Transformers are provided for error analysis / inspection.Usage: cli.py nlp-toolkit hedge-clf-demo [OPTIONS] Launches a Gradio app for hedge classification demo. Options: --hf-model-name TEXT Hugging Face Model to Load. Must be valid on Hugging Face Hub. [default: vinai/bertweet-base] --model-save-dir TEXT Pretrained model save dir / checkpoint to load from. [default: nlp/hedge_classifier/models/best_model] --theme TEXT Gradio theme to use. [default: dark-peach]
- Build Keyword Uncertainty Index
-
Uses
Lucey et al. (2021)'s methodology to construct a baseline cryptocurrency index using a simplepredefined keyword set. -
Resulting numeric index values are inserted into the
postgresandelasticsearch.Usage: cli.py build-ucry-index [OPTIONS] Construct crypto uncertainty index based on Lucey\'s methodology. Options: --es-source-index TEXT ES Index to pull text data from [default: reddit-crypto-custom] --start-date [%Y-%m-%d|%Y-%m-%dT%H:%M:%S|%Y-%m-%d %H:%M:%S] Start date [default: 2014-01-01 00:00:00] --end-date [%Y-%m-%d|%Y-%m-%dT%H:%M:%S|%Y-%m-%d %H:%M:%S] End date [default: 2021-12-31 00:00:00] --granularity TEXT Supports day, week, month, year etc. [default: week] --text-field TEXT Name of field to mine for index [default: full_text] --type TEXT Index type. One of price or policy [default: price] --prefix TEXT Index name. One of lucey, lda or top2vec [default: lucey]
- Build Hedge Uncertainty Index
-
Uses a trained
Hugging Facetext classifier to detect hedges in a given corpus and build an index. -
Resulting numeric index values are inserted into
postgres.Usage: cli.py build-hedge-index [OPTIONS] Construct hedge based crypto uncertainty index using HF transformer. Options: --data-source TEXT Source data to perform hedge classification on. [default: nlp/topic_models/data/processed_reddit] --start-date [%Y-%m-%d|%Y-%m-%dT%H:%M:%S|%Y-%m-%d %H:%M:%S] Start date [default: 2014-01-01 00:00:00] --end-date [%Y-%m-%d|%Y-%m-%dT%H:%M:%S|%Y-%m-%d %H:%M:%S] End date [default: 2021-12-31 00:00:00] --granularity TEXT Supports day, week, month, year etc. [default: week] --hf-model-name TEXT Valid Hugging Face Hub model name. [default: vinai/bertweet-base] --hf-model-ckpt TEXT Path to tuned Hugging Face model config and weights [default: nlp/hedge_classifier/models/best_model] --name TEXT Index name. [default: bertweet-hedge]
Elasticsearch&Kibana- For easy text analysis and lookup of dataPostgres- Storing of all other relational data (E.g. cryptocurrency indicies, macroeconomic indicators, etc.)
Make Commands
### Start Up Services ###
make run # After building docker images
### Health Check ###
make ps
make es-cluster-health
### Shutdown ###
make stop # Stops docker containers