若只需要找到Frequent Itemsets,輸入以下指令到命令提示字元:
$ java -jar FPGrowth.jar [dataset file path] [minimum support]
若同時需要找到Association Rule,則須加上[minimum confidence]參數:
$ java -jar FPGrowth.jar [dataset file path] [minimum support] [minimum confidence]
若需要將找到的結果輸出到一個文字檔中,則須加上> [output file]:
$ java -jar FPGrowth.jar ... > [output file]
下圖為範例示意截圖

在FPGrowth實作的過程中,最讓我煩惱的是排序的問題。對每一筆transaction中的物件進行排序聽起來很簡單,但他排序的方式卻是要參照一個固定的順序,也就是說,會需要先在這個"固定的順序"中找到物件的位置,才能將這個物件和其他物件進行比較。若是用這個想法進行實作,那麼每一筆transaction的排序會需要$O(N \times NlogN)$的時間,這裡$N$是transaction中的最大物件數量。
在這個問題上,我最後使用的方式是創造了一個Entry類別,並自訂義它的排序方式:
if A.count < B.count:
則 A < B
else if A.count < B.count:
則 A > B
else:
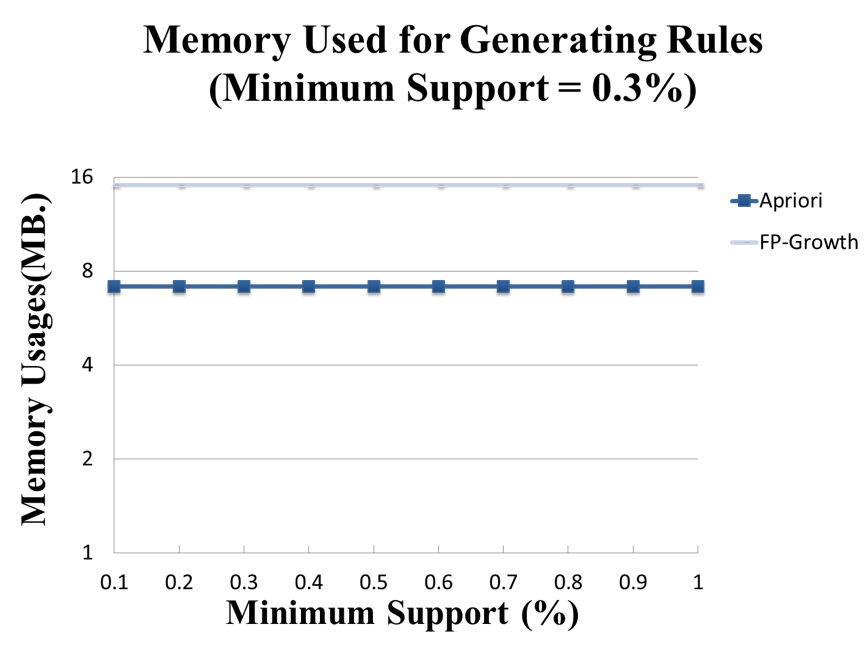
則比較 A 和 B 的 物件名稱字串另外,在進行實驗時,我發現FPGrowth在Runtime的記憶體使用上非常巨大,尤其是在探勘樹的階段,由於Java的Garbage Collection十分耗時,因此只要程式一直讓記憶體徘徊在Memory Full的邊緣,程序就需要不斷調動Garbage Collection而使得執行時間爆炸性增加。這個問題我仍未找到解決方法,目前想到的方向是找到辦法在Java程式中釋放指定物件的記憶體,又或者是要改變探勘樹這個過程目前的遞迴結構。
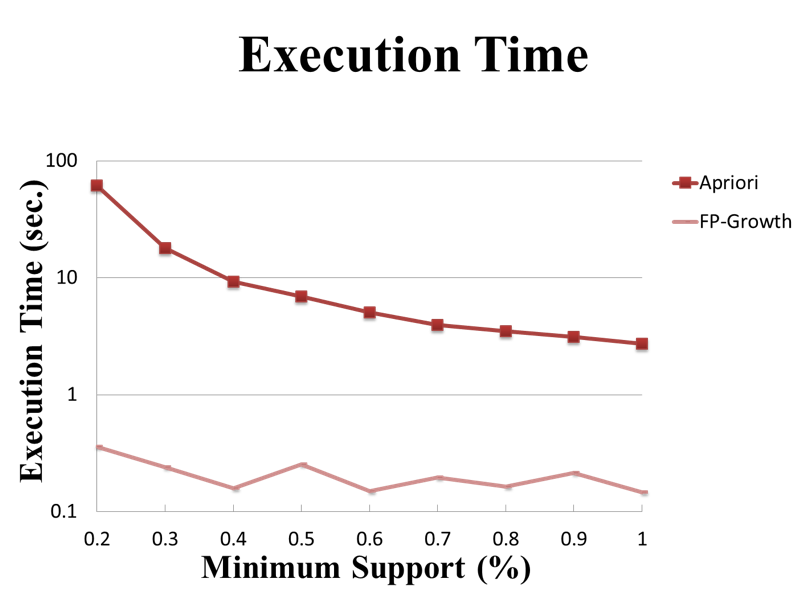
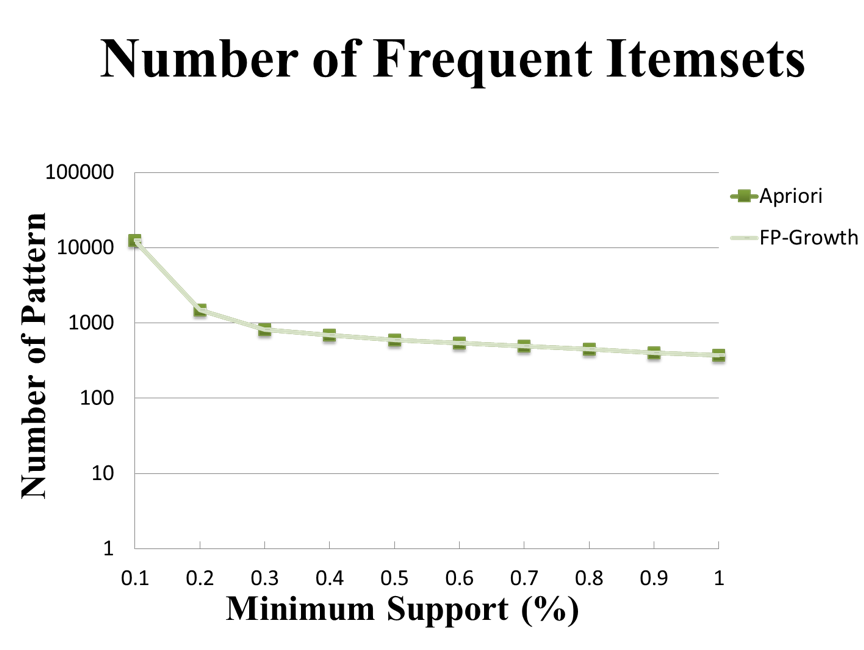
這裡的實驗結果會和Apriori實作的表現進行比較。