| title | date | updated | tags | categories |
|---|---|---|---|---|
面试知识点汇总 |
2019-09-04 02:27:46 -0700 |
2019-09-04 02:27:46 -0700 |
面经 |
Java |
持续更新到2020校招结束
封装,继承,多态
Java是一门面向对象的语言,如果只有八种基本类型byte, short,int, long, float, double, char, bool,在计算上是简单的,但是在面向对象的操作上是麻烦的,比如向集合类添加元素就只能添加包装类型而不能添加基本类型。反之,包装类型是对象,存放在堆上,占用空间大,而基本类型存放在栈中。
在自动装箱的时候,高频区域的数值存在缓存,会直接使用已有的对象。各个包装类型的缓存范围如下
| 包装类型 | 缓存范围 |
|---|---|
| Byte | -128~127 |
| Short | -128~127 |
| Character | 0~127 |
| Long | -128~127 |
| Integer | -128~127 |
看以下代码:
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
System.out.println(a==b);
System.out.println(a.equals(b));
Integer c= 200;
Integer d = 200;
System.out.println(c==d);
System.out.println(c.equals(d));
}
输出:
true
true
false
true
==比较的是对象地址,equals比较的是值。可以发现,在缓存范围内,对象a和b的地址是相同的。
- 包装类型和包装类型比较,
==比较的是对象的地址,equals比较的是值; - 包装类型和基本类型比较,无论是
==还是equals,比较的都是值,先将包装类型拆箱再同基本类型比较。
String定义的字符串,不可修改;StringBuffer和StringBuilder定义的字符串,可以修改,但是StringBuffer是线程安全的。
解释:
上述三者底层都是通过定义了一个字节数组byte[] value来实现的,不同的是,对于String类型,数组被final修饰,不可修改,而StringBuffer和StringBuilder没有这个修饰。
StringBuffer和StringBuilder内容都可以修改,但是StringBuffer是线程安全的,因为它的append()方法被synchronized关键字修饰。
String s = new String("taochq");定义了几个对象?
检查字符串常量池是否有“taochq”这个变量,有则返回其引用,此时定义了一个对象,没有则先创建后返回,定义了两个对象。
- 如何理解
String的intern方法
检查当前字符串常量是否在常量池中,不在的话放入常量池并返回引用,在的话直接返回引用。它更多的是用于将那些只有在运行时才能确定的字符串放入常量池。
String s = "a"+"b"定义了几个对象
一个,编译器进行了优化,就是"ab"。
- String s= new String("tao")+"chq"定义了几个对象
如果常量池中没有"tao"和"chq"的话,三个。
jdk7以后,字符串常量池放在了堆中。
对于基本数据类型,==比较的是值
对于医用数据类型,==比较的是内存中的存放地址
equals()方法是Object类中的方法,其最初的实现是
public boolean equals(Object obj) {
return (this == obj);
}
所以其最初比较的也是引用的地址,但是后来有些继承类比如String,有了自己的实现,用来比较内容了。
这两个方法都是定义在万类之祖------Object类中的方法,所以每个类都继承到了并且可以重写。
上文中已经讲到了equals()方法,其最开始也是比较两个对象的地址的,但是String等对象重写了,用来比较内容。
hashcode()最初的实现是用c++实现的,它返回每个对象的内存地址。
一般来讲,这两个方法没有太大的关系,我们自己实现的一些类可能会需要重写equals()方法,对于重写equals()方法,有以下要求:
1. 对称性:如果x.equals(y)返回是"true",那么y.equals(x)也应该返回是"true"。
2. 反射性:x.equals(x)必须返回是"true"。
3. 类推性:如果x.equals(y)返回是"true",而且y.equals(z)返回是"true",那么z.equals(x)也应该返回是"true"。
4. 一致性:如果x.equals(y)返回是"true",只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是"true"。
5. 非空性,x.equals(null),永远返回是"false";x.equals(和x不同类型的对象)永远返回是"false"。
那么hashcode()用在哪里呢?一个最广泛的用途就是哈希表,比如HashMap,HashSet和HashTable,在哈希表中,哈希值用来当作索引。
为什么说**在HashMap中重写equals()也要重写hashcode()**呢?
考虑一下:
以HashMap为例,假设我们只重写了equals方法,认为只有键和值都相等时这两个entry才相等,我们在进行get或put操作时,都需要先根据key来确定存储位置,存储位置的确定需要hash方法和indexFor方法,hash方法中需要使用hashCode进行定位,如果没有重写hashCode方法,那它返回的是这个key的地址,即使两个key值相同,但是地址不同,你用一个新key的地址去hash,你是永远也找不到旧key的位置的。
底层由红黑树实现。映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator进行排序,具体取决于使用的构造方法。所以是个有序的key-value集合。
set, list, map
其中set, list都实现了Collection接口, 而map没有
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Collection是顶层接口,而Collections是一个工具类,里面提供了一些静态方法,比如排序啊,逆序啊等等,不能被实例化。
ArrayList底层由数组实现,查找快,但是删除和中间插入牵扯到其他元素的移动,速度慢;
LinkedList底层由链表实现,删除和插入方便,但是查找起来没有ArrayList快;
Vector线程安全,它的修改结构的方法由synchronized关键字修饰,并且它可以往里面插入不同类型的数据。它的扩容粒度和ArrayList也不一样,ArrayList扩容1.5倍,Vector扩容一倍或者增量扩容传入的参数。Vector是Java中的遗留容器。
它们都实现了Map接口,
HashTable的方法由synchronized修饰,是线程安全的,
HashTable键值不能为空,而HashMap可以。
它俩都是Java集合中的错误检测机制。
当多个线程对非fail safe的集合进行结构上的修改时,就有可能产生fail fast机制,这时候会抛出ConcurrentModificationException异常。事实上单线程环境下也有可能出现该异常,主要是由于modCount和expectedModCount不一致造成的。
fail safe对集合结构的修改是在集合的一个复制品上进行的,所以不会抛出上述错误。但是这种方式更耗内存,而且并不能保证读到的数据是原始数据。
开局一张图

ListIterator是List专有的迭代器,继承自Iterator, 前向后向都可以访问(向前访问也是基于当前位置的,所以当前位置如果是0的话,你懂的),并且还多了set, add等方法
Iterator除了List可以用,Set也可以用,只能后向访问,且只能remove,不能add,可以看出ListIterator更强大一些(毕竟也是继承下来的对吧),在list中,给两种迭代器都提供了方法。
为了计算快捷,引入2的次幂,在二倍扩容以及indexFor的使用取模的方式来取余上,求提高了运算速度,但是同时因为是按照2的次幂取余,会增加冲突,所以1.7版本中在hash函数中也增加了扰动算法来使得散列更加均匀。
Map中的hash方法
synchronized修饰,获取锁的线程释放锁只有两种情况:
-
获取锁的线程执行完了该代码块,然后线程释放对锁的占有;
-
线程执行发生异常,此时JVM会让线程自动释放锁。
如果这个获取锁的线程由于要等待IO或者其他原因(比如调用sleep方法)被阻塞了,但是又没有释放锁,其他线程便只能干巴巴地等待 ,不能相应中断
Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;Lock可以让等待锁的线程响应中断
使用synchronized关键字获取锁时,是成功获取还是进入等待队列我们是不能直观知道的,但是使用Lock接口的tryLock()方法,可以通过返回的布尔值知道是否成功获取锁。
| synchronized | Lock | |
|---|---|---|
| 发生异常 | JVM自动释放锁 | 使用unLock()手动释放锁 |
| 等待的线程相应中断 | 不能 | 能 |
| 知道线程是否获取锁 | 不能 | 能 |
| 语言内置 | 是 | 否 |
| 可重入 | 是 | 是 |
| 公平性 | 非公平锁 | 都可以 |
通俗的讲,进程表示一个任务,线程表示一个任务里的子任务。
具体的讲,进程是资源分配的基本单元,线程是执行的基本单元。同一个进程之间的多个线程共享资源。
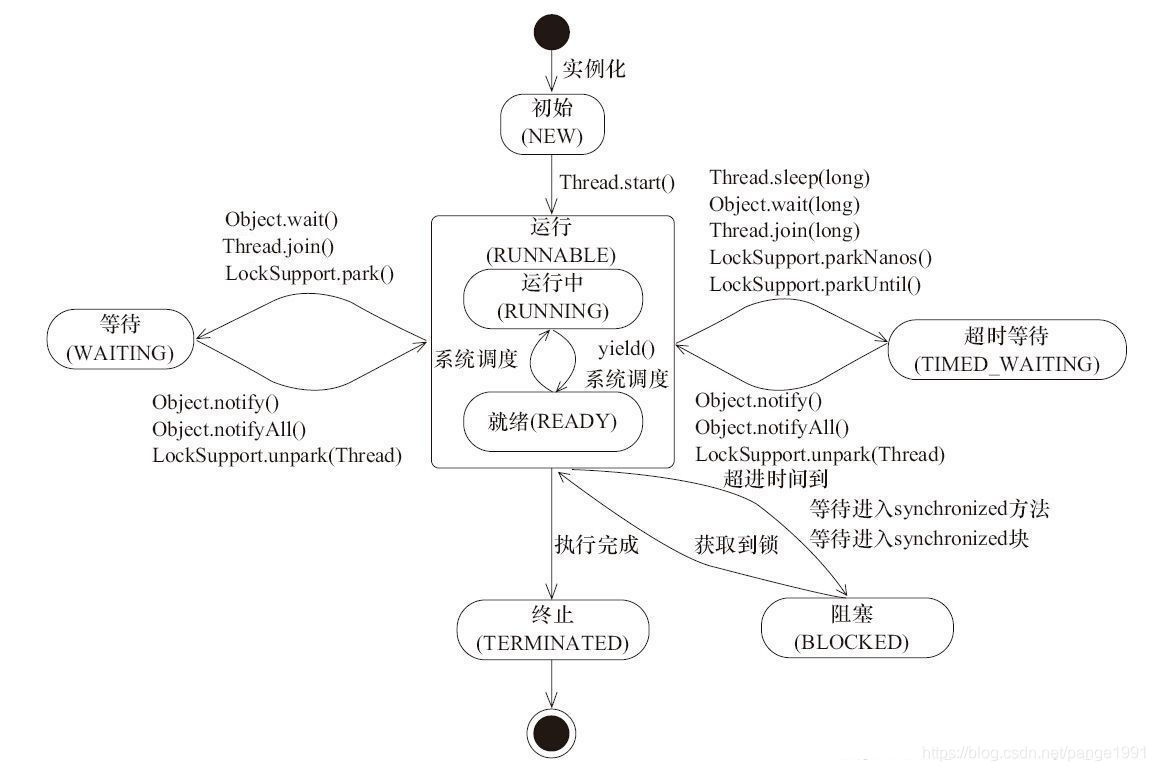
阻塞和等待的区别:
等待状态是需要其他线程唤醒的,阻塞状态强调的是在因为没有获取到锁而阻塞,两者的侧重点不同。一个侧重被唤醒,一个侧重获取锁。
多个线程访问共享变量时导致的数据不一致的情况。
启动一个线程应该用start(),而不是run().
-
调用
start()方法JVM会创建一个线程并去执行这个线程里的run()方法,而调用run()方法并不会创建新的线程。 -
start()不能被重复调用,run()可以被重复调用。
-
synchronized -
volatile -
Lock: AQS+Condition (核心在于通过CAS来操作state) ,Lock更像一种人工锁,其核心就是state变量 -
wait,notify -
ThreadLocal:每个线程内部做一份拷贝 -
阻塞队列:队列+可重入锁+Condition
-
原子变量: 自旋+CAS
-
信号量
相同点:
- 都是
Thread类的静态方法 - 都是让当前线程放弃CPU但不释放锁
不同点:
sleep可以抛出InterruptedException异常
因为这些方法会使得程序处于不确定状态下。以suspend()为例,它使线程暂停,但不会释放已经占有的线程资源(比如锁)。
它们都可以实现线程之间的相互等待。
CountDownLatch侧重于一个线程A等待其他线程都执行完某些或所有任务后,线程A才能继续执行,类似于thread.join()的作用。
CyclicBarrier侧重于让所有线程都执行到某个同步点然后统一继续向下执行。
不同的是CyclicBarrier可以重用。
多个线程在竞争资源或者彼此通信时造成的一种互相阻塞的现象。若无外力作用,它们都将无法推进下去。
- 互斥:一个资源每次只能被一个进程使用
- 请求保持:一个进程因为请求资源而阻塞时,对已经占有的资源没有释放
- 不可剥夺:进程已获得的资源,在未使用完之前,不能强行剥夺
- 循环等待:若干进程之间形成一种头尾相接的循环等待资源关系
从产生死锁的四个必要条件入手:
- 破坏互斥:这正是锁的定义所在,不能破坏
- 破坏请求保持:让进程一次性请求所有所需的资源
- 破坏不可剥夺:
- 让进程在请求其他资源失败时,先释放当前已经占有的资源
- 设置优先级,优先级高的进程可以抢占
- 破坏循环等待:让多个进程对资源的请求顺序相同
每个锁关联一个线程持有者和一个计数器。