Zheng Chen, Yulun Zhang, Jinjin Gu, Linghe Kong, Xiaokang Yang, and Fisher Yu, "Dual Aggregation Transformer for Image Super-Resolution", ICCV, 2023
[arXiv] [supplementary material] [visual results] [pretrained models]
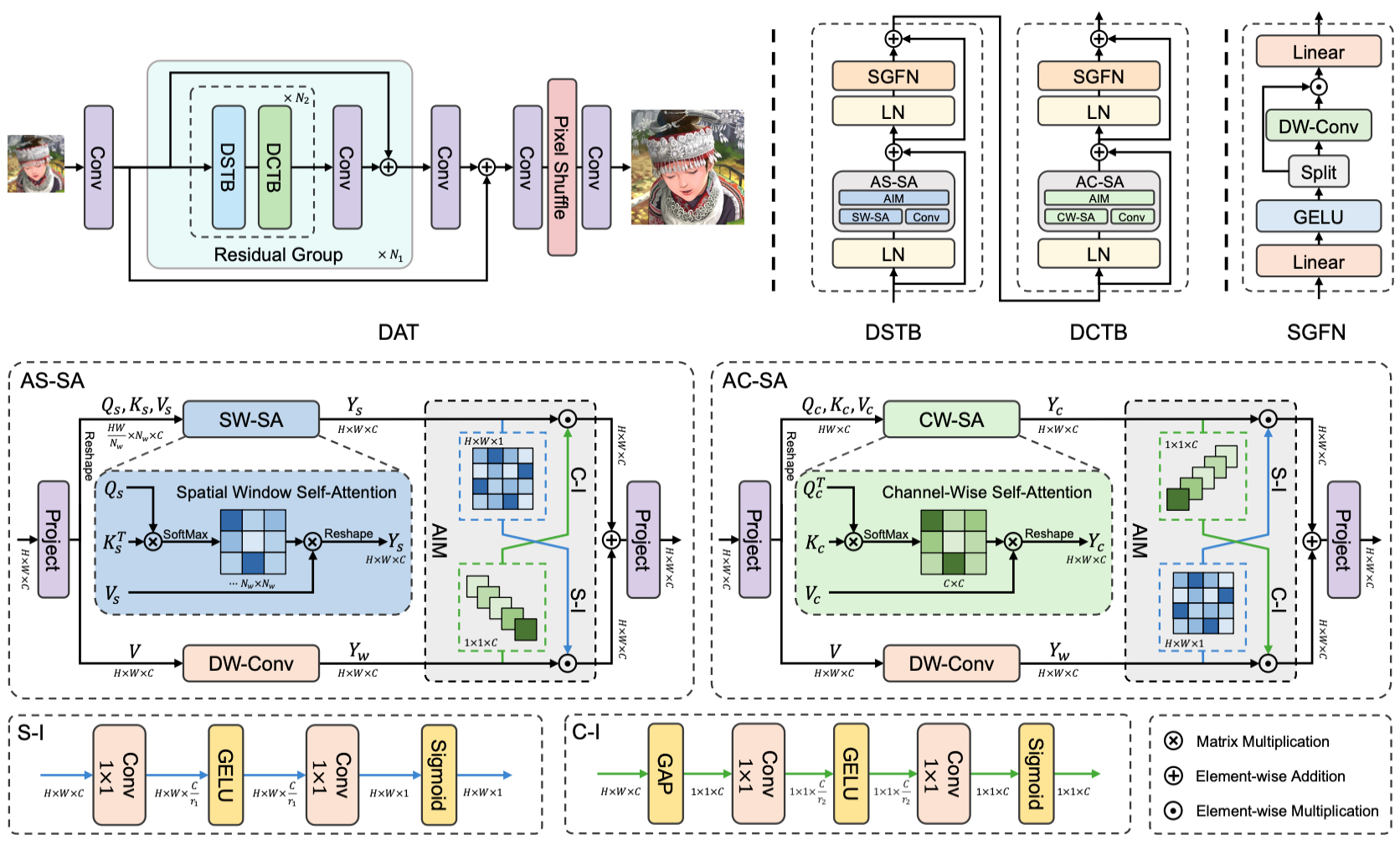
Abstract: Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods.

| HR | LR | SwinIR | CAT | DAT (ours) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
- Python 3.8
- PyTorch 1.8.0
- NVIDIA GPU + CUDA
# Clone the github repo and go to the default directory 'DAT'.
git clone https://github.com/zhengchen1999/DAT.git
conda create -n DAT python=3.8
conda activate DAT
pip install -r requirements.txt
python setup.py developUsed training and testing sets can be downloaded as follows:
| Training Set | Testing Set | Visual Results |
|---|---|---|
| DIV2K (800 training images) + Flickr2K (2650 images) [complete training dataset DF2K] | Set5 + Set14 + BSD100 + Urban100 + Manga109 [complete testing dataset download] | here |
Download training and testing datasets and put them into the corresponding folders of datasets/ and restormer/datasets. See datasets for the detail of the directory structure.
| Method | Params | FLOPs (G) | Dataset | PSNR (dB) | SSIM | Model Zoo | Visual Results |
|---|---|---|---|---|---|---|---|
| DAT-S | 11.21M | 203.34 | Urban100 | 27.68 | 0.8300 | Google Drive | Google Drive |
| DAT | 14.80M | 275.75 | Urban100 | 27.87 | 0.8343 | Google Drive | Google Drive |
| DAT-2 | 11.21M | 216.93 | Urban100 | 27.86 | 0.8341 | Google Drive | Google Drive |
| DAT-light | 573K | 49.69 | Urban100 | 26.64 | 0.8033 | Google Drive | Google Drive |
The performance is reported on Urban100 (x4). DAT-S, DAT, DAT-2: output size of FLOPs is 3×512×512. DAT-light: output size of FLOPs is 3×1280×720.
-
Download training (DF2K, already processed) and testing (Set5, Set14, BSD100, Urban100, Manga109, already processed) datasets, place them in
datasets/. -
Run the following scripts. The training configuration is in
options/train/.# DAT-S, input=64x64, 4 GPUs python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_S_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_S_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_S_x4.yml --launcher pytorch # DAT, input=64x64, 4 GPUs python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_x4.yml --launcher pytorch # DAT-2, input=64x64, 4 GPUs python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_2_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_2_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_2_x4.yml --launcher pytorch # DAT-light, input=64x64, 4 GPUs python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_light_x2.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_light_x3.yml --launcher pytorch python -m torch.distributed.launch --nproc_per_node=4 --master_port=4321 basicsr/train.py -opt options/Train/train_DAT_light_x4.yml --launcher pytorch
-
The training experiment is in
experiments/.
-
Download the pre-trained models and place them in
experiments/pretrained_models/.We provide pre-trained models for image SR: DAT-S, DAT, DAT-2, and DAT-light (x2, x3, x4).
-
Download testing (Set5, Set14, BSD100, Urban100, Manga109) datasets, place them in
datasets/. -
Run the following scripts. The testing configuration is in
options/test/(e.g., test_DAT_x2.yml).Note 1: You can set
use_chop: True(default: False) in YML to chop the image for testing.# No self-ensemble # DAT-S, reproduces results in Table 2 of the main paper python basicsr/test.py -opt options/Test/test_DAT_S_x2.yml python basicsr/test.py -opt options/Test/test_DAT_S_x3.yml python basicsr/test.py -opt options/Test/test_DAT_S_x4.yml # DAT, reproduces results in Table 2 of the main paper python basicsr/test.py -opt options/Test/test_DAT_x2.yml python basicsr/test.py -opt options/Test/test_DAT_x3.yml python basicsr/test.py -opt options/Test/test_DAT_x4.yml # DAT-2, reproduces results in Table 1 of the supplementary material python basicsr/test.py -opt options/Test/test_DAT_2_x2.yml python basicsr/test.py -opt options/Test/test_DAT_2_x3.yml python basicsr/test.py -opt options/Test/test_DAT_2_x4.yml # DAT-light, reproduces results in Table 2 of the supplementary material python basicsr/test.py -opt options/Test/test_DAT_light_x2.yml python basicsr/test.py -opt options/Test/test_DAT_light_x3.yml python basicsr/test.py -opt options/Test/test_DAT_light_x4.yml
-
The output is in
results/.
-
Download the pre-trained models and place them in
experiments/pretrained_models/.We provide pre-trained models for image SR: DAT-S, DAT, and DAT-2 (x2, x3, x4).
-
Put your dataset (single LR images) in
datasets/single. Some test images are in this folder. -
Run the following scripts. The testing configuration is in
options/test/(e.g., test_single_x2.yml).Note 1: The default model is DAT. You can use other models like DAT-S by modifying the YML.
Note 2: You can set
use_chop: True(default: False) in YML to chop the image for testing.# Test on your dataset python basicsr/test.py -opt options/Test/test_single_x2.yml python basicsr/test.py -opt options/Test/test_single_x3.yml python basicsr/test.py -opt options/Test/test_single_x4.yml -
The output is in
results/.
We achieved state-of-the-art performance. Detailed results can be found in the paper. All visual results of DAT can be downloaded here.
Click to expan
- results in Table 2 of the main paper

- results in Table 1 of the supplementary material

- results in Table 2 of the supplementary material

- visual comparison (x4) in the main paper

- visual comparison (x4) in the supplementary material




If you find the code helpful in your research or work, please cite the following paper(s).
@inproceedings{chen2023dual,
title={Dual Aggregation Transformer for Image Super-Resolution},
author={Chen, Zheng and Zhang, Yulun and Gu, Jinjin and Kong, Linghe and Yang, Xiaokang and Yu, Fisher},
booktitle={ICCV},
year={2023}
}
This code is built on BasicSR.