My name is Nathan Fritter and I am obsessed with data. I have a B.S. in Applied Statistics from UCSB and was an active member of the Data Science club @ UCSB. This is one of various projects I have completed to vairous degrees; Feel free to take a look at any and all other projects and make suggestions.
This project is based on the Kaggle competition here
Tweets from various accounts on Twitter (all with an accompanying personality type) were gathered together; each account has a personality type, along with the last 50 tweets for each user.
At first, my goal was to tokenize the data (turn into individual words or parts) remove ALL the noise (stop words, hyperlinks, hashtags, etc.), and use the tokenized inputs try and predict the personality type of the user.
However, I realized that I was leaving alot to be desired with respect to exploratory analysis. Instead of simply just getting word and type frequency, I realized I could be looking for so much more (hashtag/mention/retweet/url frequency, n-gram occurences, etc.). Thus I have revamped the project to include alot more on the exploratory analysis side.
I also have learned alot about data cleanup, manipulation, storing data in different ways, and more that I hope becomes clear in my code.
I utilized three different Machine Learning models known for success in Natural Language Processing (NLP):
- Multinomial Naive Bayes
- Linear Support Vector Machine
- Neural Network
The project is split up into different sections tht you may look at individually:
- Data Extraction/Cleanup
- Exploratory Analysis
- Naive Bayes
- Linear Support Vector Machine
- Neural Network
Currently the only version I have this for is Python; versions in R and pyspark are currently in the works.
NOTE: data_extraction_cleanup.py and helper_functions.py are used to abstract functions for the other scripts for readability (i.e. using a function called tokenize_data from helper_functions.py to tokenize data, creating different versions of data for the other scripts to import, etc.).
Since the other scripts use these scripts heavily, if you would like to make changes to this project give them a look.
The Myers Briggs Personality Type is based on psychological theory about how people perceive their world and make accompanying judgements about these perceptions.
It is a simplistic view that is prone to overgeneralizing, but one that can have surprising effectiveness at predicting people's behaviors in general when taking into account the limitations of the theory. There are four categories:
-
Extroverted/Introverted (E/I):
- Rather than the mainstream view that this distinction means talkative versus antisocial, this difference stems from where one gets their energy:
- Extroverts gain energy from being around other people: talking, conversing, being noticed, etc.
- They can be alone, but will get tired without contact
- Introverts gain energy from being alone and clearing their thoughts
- Being alone and allowed to let their thoughts flow is very energizing (coming from personal experience).
- Opposite to extroverts, introverts have the capability to socialize quite effectively; but after a while, even five minutes can do wonders.
- Extroverts gain energy from being around other people: talking, conversing, being noticed, etc.
- Rather than the mainstream view that this distinction means talkative versus antisocial, this difference stems from where one gets their energy:
-
Intuitive/Sensory (N/S):
- Here, the differences lie in how the individual perceives their world. The two domains here are either through the five senses (immediate environment) or within their mind.
- Intuitives (N) are better at perceiving the world through their mind and imagining abstract possibilities in the world.
- Sensories (S) are better at perceiving the world through the five senses.
- Here, the differences lie in how the individual perceives their world. The two domains here are either through the five senses (immediate environment) or within their mind.
-
Thinking/Feeling (T/F):
- This domain deals with how the individual judges the information they have perceived: Either the individual makes judgments in a Thinking (T) way or a Feeling (F) way
- Thinkers make conclusions about their world through logic and reasoning
- Feelers make conclusions about their world through emotion and gut feeling
- This domain deals with how the individual judges the information they have perceived: Either the individual makes judgments in a Thinking (T) way or a Feeling (F) way
-
Judgmental/Perceiving (J/P):
- Lastly (and a little more complicated), this domain basically states whether the perceiving trait or the judging trait is the dominant trait of the individual
- Judgers (J) have their judging trait be their dominant overall trait
- Perceivers (P) have their perceiving trait be their dominant overall trait
- Lastly (and a little more complicated), this domain basically states whether the perceiving trait or the judging trait is the dominant trait of the individual
Here is more in depth detail on the theory (Kaggle site has info as well)/
-
Clone the repo onto your machine (instructions here if you are not familiar)
-
OPTIONAL: Download the package
virtualenv- I prefer using virtual environments to run code since there will be no package conflicts with anything in
requirements.txt - Here we will use
pip3 install virtualenv(python3 compatible) - Feel free to use another package manager such as
brew
- I prefer using virtual environments to run code since there will be no package conflicts with anything in
-
Run the following commands in your terminal (compatible with Linux and Mac):
I. Creating a virtual environment called YOUR-VIRTUAL-ENV:
$ virtualenv YOUR-VIRTUAL-ENV
Replace YOUR-VIRTUAL-ENV with what you'd like to name your environment
II. Turn on the virtual environment and place you inside:
$ source YOUR-VIRTUAL-ENV/bin/activate
III. Install necessary packages from requirements.txt
$ pip3 install -r requirements.txt
IV. Create necessary files for exploratory analysis and model building:
$ python3 scripts/data_extraction_cleanup.py
This will create the following files:
+ mbti_tokenized.csv (Tokenized data with stopwords)
+ mbti_cleaned.csv (Tokenized data without stopwords)
IMPORTANT: To make sure these scripts run properly, run the code from the main directory after cloning (i.e. do not change directories before running scripts). I have added code that grabs the current working directory and makes sure it ends with myersBriggsNLPAnalysis; if it does not, the scripts will not run.
Example for running scripts:
$ python3 scripts/any-script.py
- Run any of the other scripts and watch the magic!
Here I will delve into the various different insights I have mined through this data
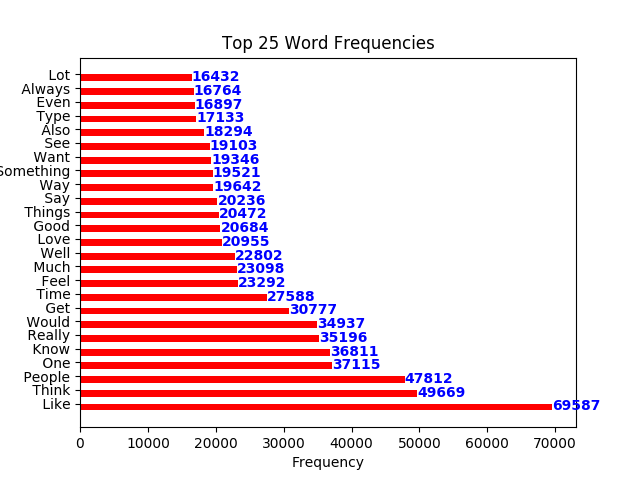

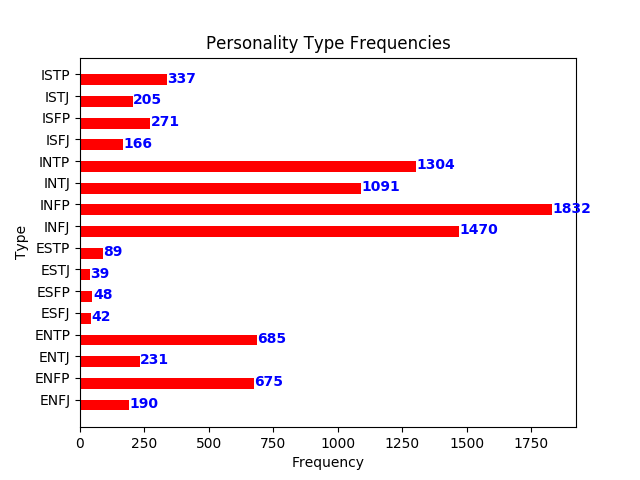
The variance in the frequency of personality types may be an issue down the line; "INFP", "INFJ", "INTP", and "INTJ" show up the most, and disproportionally so.
Because of this, there will likely be something called "class imbalance": this is where some classes are represented much more highly than others.
Also, complexity does not always make models better. The fact that there are sixteen different classes would impact any model's performance.
As a next step, I will alter the types to look at specific type combination differences, which may include:
- E vs I, N vs S, T vs F, J vs P
- NT vs NF vs SF vs ST
- NJ vs NP vs SJ vs SP
Whichever method I choose should reduce error and increase accuracy due to increased simplicity of the model (however any simplification will lead to information lost, so there is a trade-off).
Using the original, four letter types (16 classes) here are the model results:
| Model | Accuracy | Test Error Rate | Cross Validation Score | Hyperparameter Optimization | Optimized Accuracy |
|---|---|---|---|---|---|
| Multinomial Naive Bayes | 0.2169 | 0.7831 | Accuracy: 0.21 (+/- 0.00) | {'vect__ngram_range': (1, 1), 'tfidf__use_idf': False, 'clf__alpha': 1.0e-10, 'clf__fit_prior': False} | 0.3210 |
| Linear Support Vector Machine | 0.6615 | 0.3385 | Accuracy: 0.67 (+/- 0.03) | {'clf__alpha': 0.001, 'clf__eta0': 0.25, 'clf__l1_ratio': 0, 'clf__learning_rate': 'optimal', 'clf__penalty': 'l2', 'tfidf__use_idf': True, 'vect__ngram_range': (1, 1)} | 0.6716 |
| Multi Layer Perceptron | 0.5777 | 0.3423 | Accuracy: 0.66 (+/- 0.02) | Blank | Blank |
The accuracy and test error rate are based on one train test split with model fitting and default parameters(simplest method).
- The Optimized Accuracy is the accuracy of the model chosen with the best parameters after optimization, as well as the cross validation results.*
As we can see, the accuracy of these methods will be fairly limited due to the large number of classes (and the shortcomings of using tweets as data, where slang, hyperlinks and more contribute to making the data noisy).
Here are the success rates of each model predicting each personality type:
This is used tuned model results
| Personality Type | Multinomial Naive Bayes | Linear Support Vector Machine | Multi Layer Perceptron |
|---|---|---|---|
| ENFJ | 0.000000 | 0.129032 | 0.370968 |
| ENFP | 0.051887 | 0.561321 | 0.584906 |
| ENTJ | 0.000000 | 0.342466 | 0.561644 |
| ENTP | 0.027273 | 0.613636 | 0.586364 |
| ESFJ | 0.000000 | 0.100000 | 0.100000 |
| ESFP | 0.000000 | 0.000000 | 0.000000 |
| ESTJ | 0.000000 | 0.000000 | 0.000000 |
| ESTP | 0.000000 | 0.222222 | 0.296296 |
| INFJ | 0.475789 | 0.751579 | 0.698947 |
| INFP | 0.676898 | 0.886914 | 0.754443 |
| INTJ | 0.230088 | 0.657817 | 0.678466 |
| INTP | 0.396896 | 0.815965 | 0.778271 |
| ISFJ | 0.000000 | 0.415385 | 0.538462 |
| ISFP | 0.000000 | 0.225806 | 0.494624 |
| ISTJ | 0.000000 | 0.272727 | 0.480519 |
| ISTP | 0.000000 | 0.583333 | 0.703704 |
We can deduce a couple of things here:
- Naive Bayes is NOT a good choice for this data, as it consistently has trouble predicting the underrepresented classes
- The model only was able to give six different classes in its predictions
- All of the "INxx" types plus "ENFP" and "ENTP")
- These six types happened to be the top 6 types in frequency
- This is a case where the model's simplicity ends up hurting it; it is highly reliant on seeing many examples of a class to predict it accurately
- The model only was able to give six different classes in its predictions
- No matter what model, the four "INxx" personality types seem to be predicted pretty well. Within that, the "INFP" type is predicted very well
- This is consistent with the fact that those four have the most tweets, as well as "INFP" having the most overall
- The "ENxx" types have the second most, and they have reasonable performance (including actual predictions from Naive Bayes)
- Next are "ISxx" types, then "ESxx" types did the worst overall (also having the lowest amount of tweets)
- In fact, there seems to be a noticable relationship between the number of tweets (data points) per type and the model's predictive success with them
- There are some exceptions ("ENTJ", "ISFJ", and "ISTP"), but for the most part this is to be expected: The more data you have of a certain class, the better a model will be able to correctly predict it on new data
If you would like to contribute:
- Create a new branch to work on (instructions here)
- By default the branch you will receive after cloning is the "master" branch
- This is where the main changes are deployed, so it should not contain any of your code unless the changes have been agreed upon by all parties (which is the purpose of creating the new branch)
- This way you must submit a request to push changes to the main branch
- Submit changes as a pull request with any relevant information commented
- Reaching out in some way would also be great to help speed up the process
If you do contribute, I will add your name as a contributor! I am always iterating on this project, and any feedback would be greatly welcomed!