This repository provides a set of Jupyter Notebooks that augment and analyze COVID-19 time series data.
While working on this scenario, we identified that building a pipeline would help organize the notebooks and simplify running the full workflow to process and analyze new data. For this, we leveraged Elyra's ability to build notebook pipelines to orchestrate the running of the full scenario on a Kubeflow Pipeline runtime.

WARNING: Do not run these notebooks from your system Python environment.
Use the following steps to create a consistent Python environment for running the notebooks in this repository:
- Install Anaconda or Miniconda
- Navigate to your local copy of this repository.
- Run the script
env.shto create an Anaconda environment in the directory./env:Note: This script takes a while to run.$ bash env.sh - Activate the new environment and start JupyterLab:
$ conda activate ./env $ jupyter lab --debug
Elyra's Notebook pipeline visual editor currently supports running these pipelines in a Kubeflow Pipeline runtime. If required, these are the steps to install a local deployment of KFP.
After installing your Kubeflow Pipeline runtime, use the command below (with proper updates) to configure the new KFP runtime with Elyra.
elyra-metadata install runtimes --replace=true \
--schema_name=kfp \
--name=kfp-local \
--display_name="Kubeflow Pipeline (local)" \
--api_endpoint=http://[host]:[api port]/pipeline \
--cos_endpoint=http://[host]:[cos port] \
--cos_username=[cos username] \
--cos_password=[cos password] \
--cos_bucket=covidNote: The cloud object storage above is a local minio object storage but other cloud-based object storage services could be configured and used in this scenario.
Elyra provides a visual editor for building Notebook-based AI pipelines, simplifying the conversion of multiple notebooks into batch jobs or workflows. By leveraging cloud-based resources to run their experiments faster, the data scientists, machine learning engineers, and AI developers are then more productive, allowing them to spend their time using their technical skills.
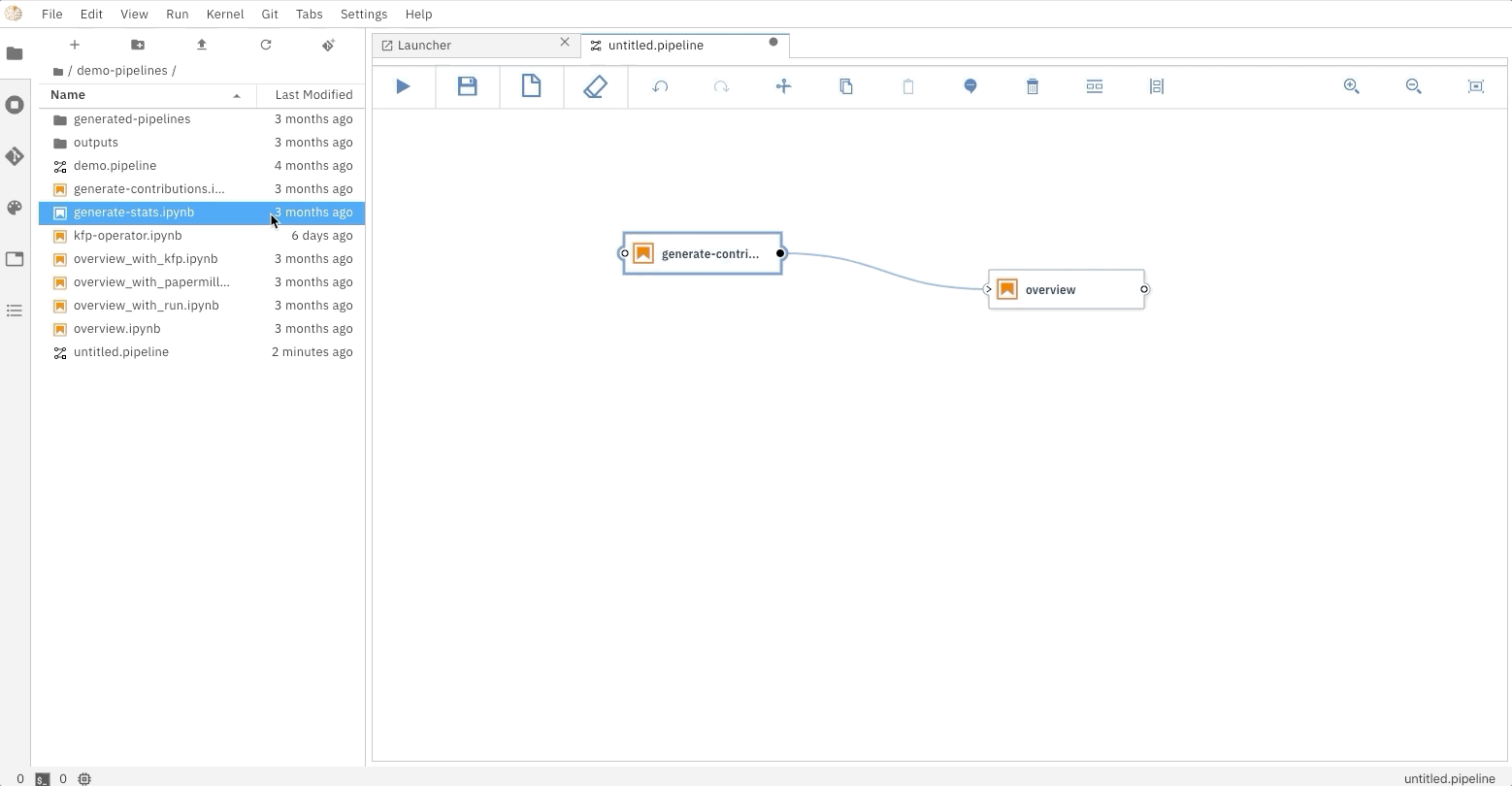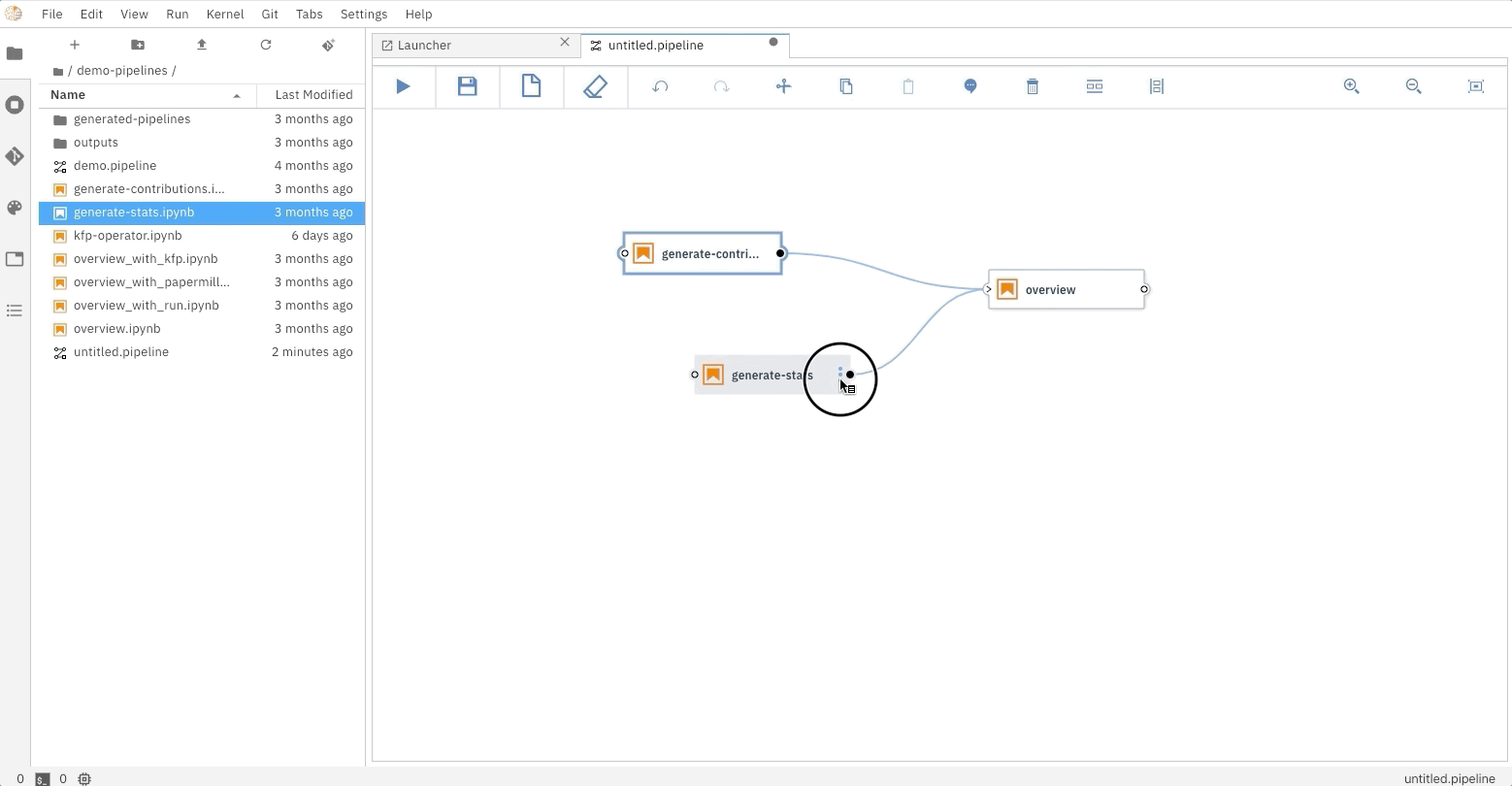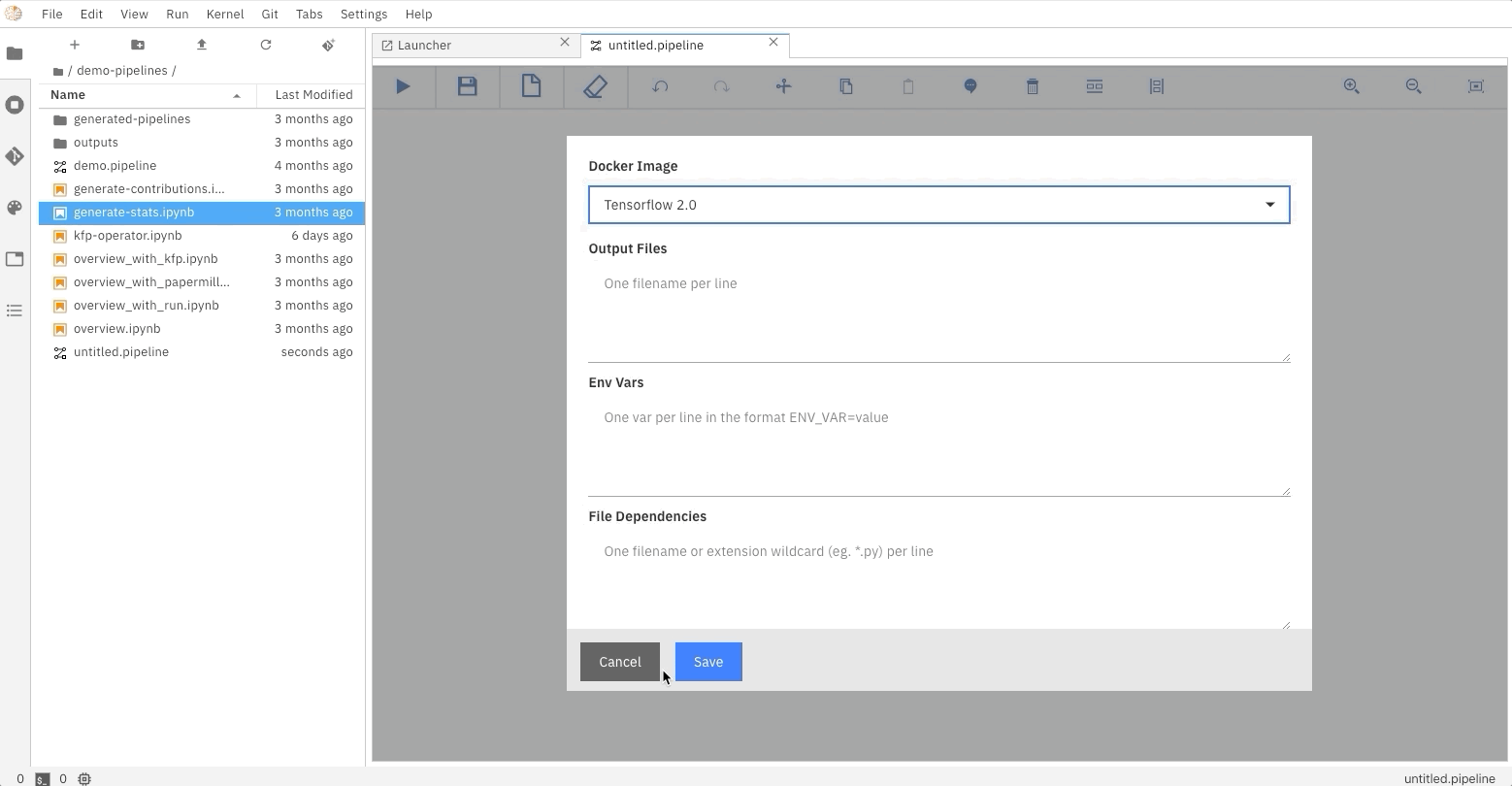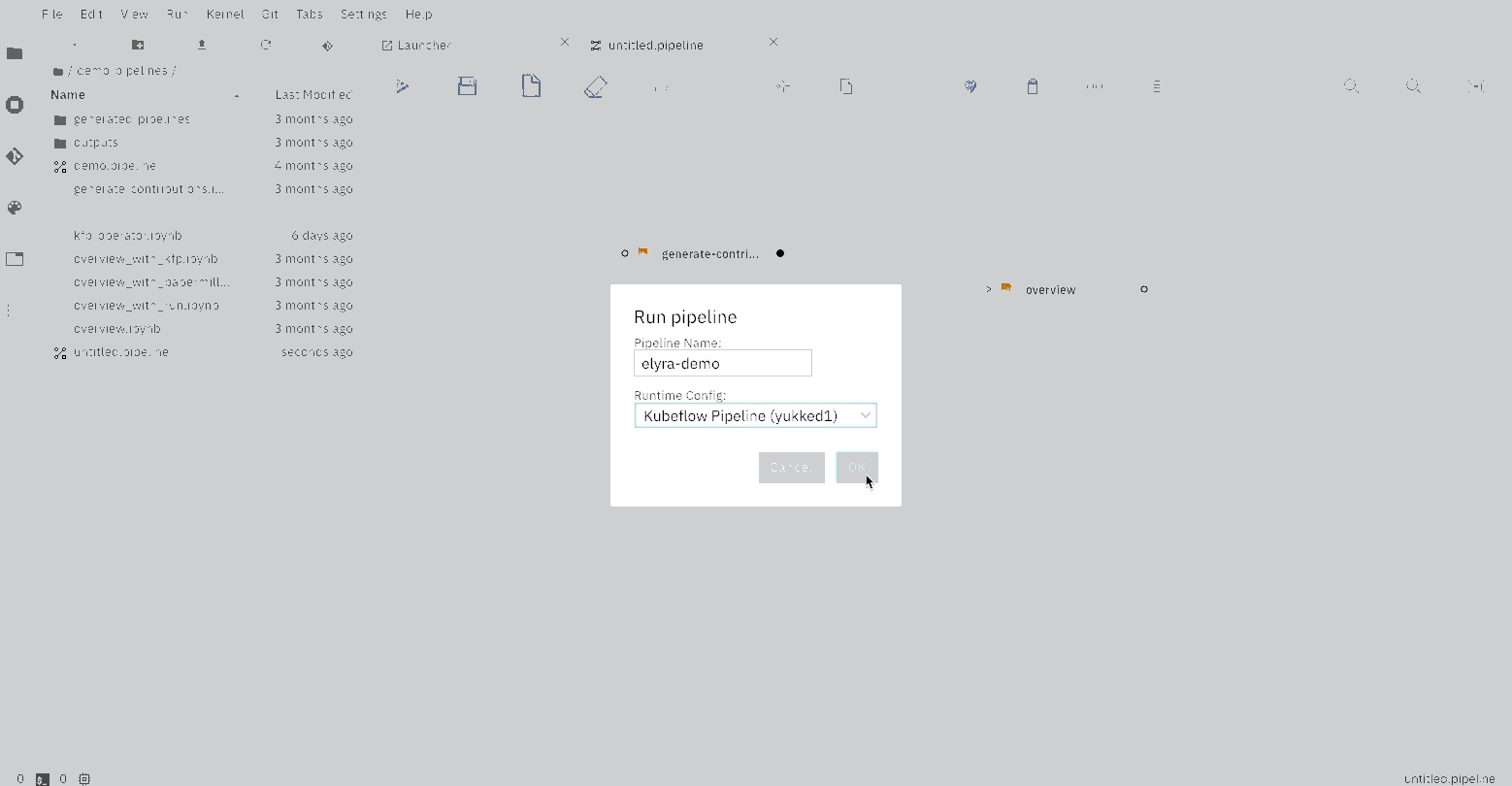
The Elyra pipeline us_data.pipeline, which is located in the pipeline directory, can be run by clicking
on the play button as seen on the image above. The submit dialog will request two inputs from the user: a name
for the pipeline and a runtime to use while executing the pipeline. The list of available runtimes comes from
the registered Kubeflow Pipelines runtimes documented above. After submission, Elyra will show a dialog with a direct
link to where the experiment is being executed on Kubeflow Piplines.
The user can access the pipelines, and respective experiment runs, via the api_endpoint of the Kubeflow Pipelines
runtime (e.g. http://[host]:[port]/pipeline)

The output from the executed experiments are then available in the associated object storage
and the executed notebooks are available as native ipynb notebooks and also in html format
to facilitate the visualization and sharing of the results.

Find more project details on Elyra's GitHub or watching the Elyra's demo.