Deep skill chaining has been developed on top of the popular simple_rl library for maximal readability and reproducability.
In addition to the installation requirements for simple_rl, DSC simply requires a MuJoCo install (which unfortunately requires a license). The conda env yaml file contains all the software dependencies that can be installed using anaconda.
The main file from which experiments can be run is simple_rl/agents/func_approx/dsc/SkillChainingAgentClass.py.
A simple framework for experimenting with Reinforcement Learning in Python.
There are loads of other great libraries out there for RL. The aim of this one is twofold:
- Simplicity.
- Reproducibility of results.
A brief tutorial for a slightly earlier version is available here. As of version 0.77, the library should work with both Python 2 and Python 3. Please let me know if you find that is not the case!
simple_rl requires numpy and matplotlib. Some MDPs have visuals, too, which requires pygame. Also includes support for hooking into any of the Open AI Gym environments. I recently added a basic test script, contained in the tests directory.
The easiest way to install is with pip. Just run:
pip install simple_rl
Alternatively, you can download simple_rl here.
Some examples showcasing basic functionality are included in the examples directory.
To run a simple experiment, import the run_agents_on_mdp(agent_list, mdp) method from simple_rl.run_experiments and call it with some agents for a given MDP. For example:
# Imports
from simple_rl.run_experiments import run_agents_on_mdp
from simple_rl.tasks import GridWorldMDP
from simple_rl.agents import QLearningAgent
# Run Experiment
mdp = GridWorldMDP()
agent = QLearningAgent(mdp.get_actions())
run_agents_on_mdp([agent], mdp)
Running the above code will run unleash Q-learning on a simple GridWorld. When it finishes it will store the results in cur_dir/results/* and open the following plot:
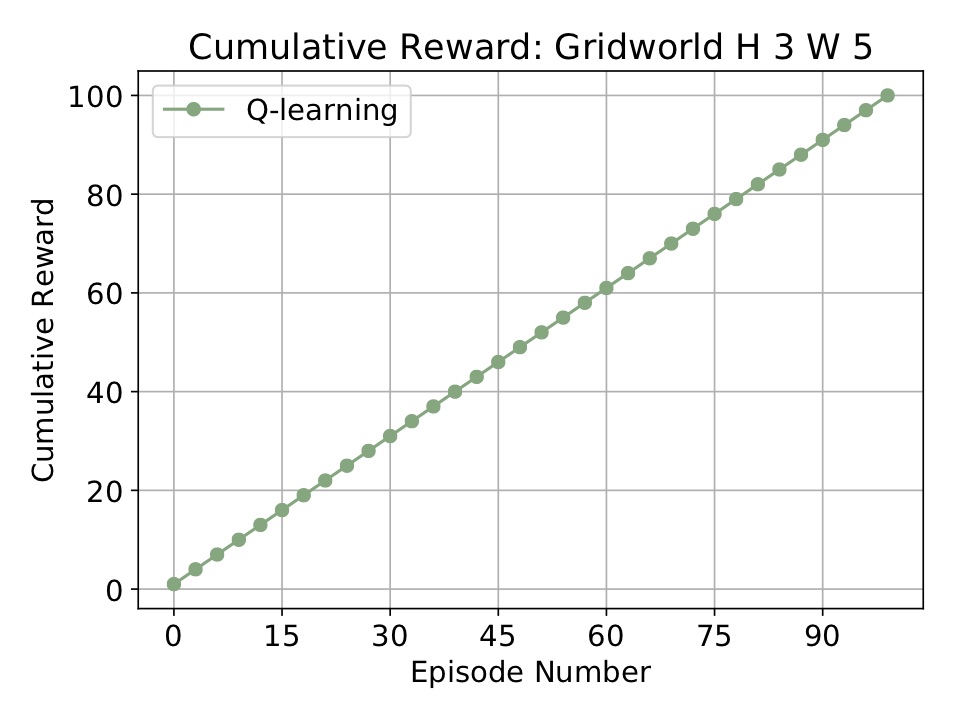
For a slightly more complicated example, take a look at the code of simple_example.py. Here we run three few agents on the grid world from the Russell-Norvig AI textbook:
from simple_rl.agents import QLearningAgent, RandomAgent, RMaxAgent
from simple_rl.tasks import GridWorldMDP
from simple_rl.run_experiments import run_agents_on_mdp
# Setup MDP.
mdp = GridWorldMDP(width=4, height=3, init_loc=(1, 1), goal_locs=[(4, 3)], lava_locs=[(4, 2)], gamma=0.95, walls=[(2, 2)])
# Setup Agents.
ql_agent = QLearningAgent(actions=mdp.get_actions())
rmax_agent = RMaxAgent(actions=mdp.get_actions())
rand_agent = RandomAgent(actions=mdp.get_actions())
# Run experiment and make plot.
run_agents_on_mdp([ql_agent, rmax_agent, rand_agent], mdp, instances=5, episodes=50, steps=10)
The above code will generate the following plot:
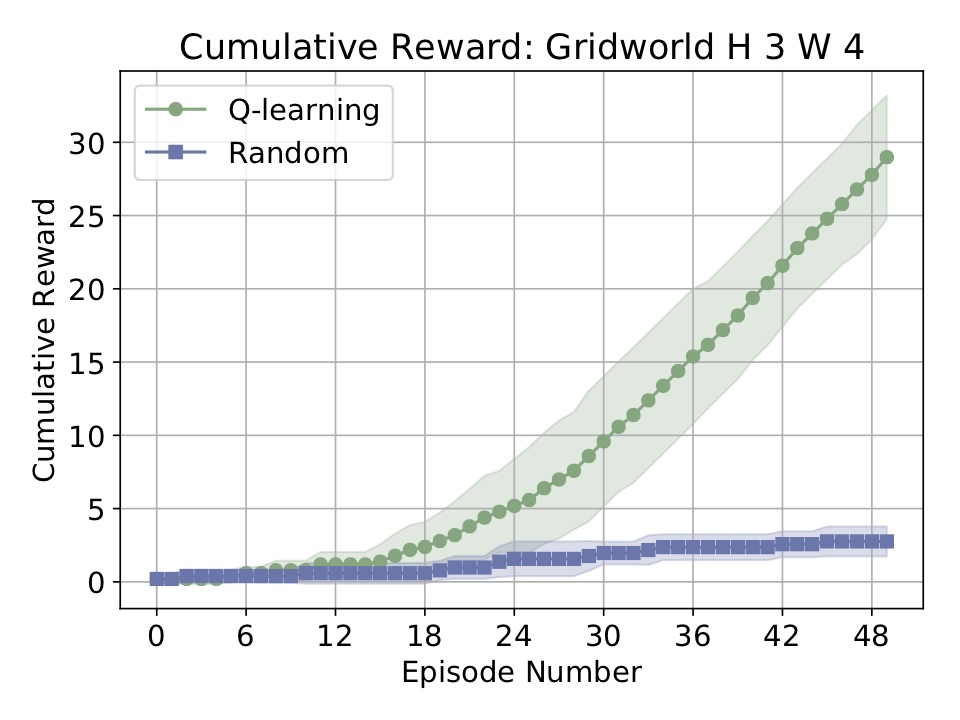
-
(agents): Code for some basic agents (a random actor, Q-learning, [R-Max], Q-learning with a Linear Approximator, and so on).
-
(experiments): Code for an Experiment class to track parameters and reproduce results.
-
(mdp): Code for a basic MDP and MDPState class, and an MDPDistribution class (for lifelong learning). Also contains OO-MDP implementation [Diuk et al. 2008].
-
(planning): Implementations for planning algorithms, includes ValueIteration and MCTS [Couloum 2006], the latter being still in development.
-
(tasks): Implementations for a few standard MDPs (grid world, N-chain, Taxi [Dietterich 2000], and the OpenAI Gym).
-
(utils): Code for charting and other utilities.
If you'd like to contribute: that's great! Take a look at some of the needed improvements below: I'd love for folks to work on those pieces. Please see the contribution guidelines. Email me with any questions.
Make an MDP subclass, which needs:
-
A static variable, ACTIONS, which is a list of strings denoting each action.
-
Implement a reward and transition function and pass them to MDP constructor (along with ACTIONS).
-
I also suggest overwriting the "__str__" method of the class, and adding a "__init__.py" file to the directory.
-
Create a State subclass for your MDP (if necessary). I suggest overwriting the "__hash__", "__eq__", and "__str__" for the class to play along well with the agents.
Make an Agent subclass, which requires:
-
A method, act(self, state, reward), that returns an action.
-
A method, reset(), that puts the agent back to its tabula rasa state.
I'm hoping to add the following features:
- Planning: Finish MCTS [Coloum 2006], implement RTDP [Barto et al. 1995]
- Deep RL: Write a DQN [Mnih et al. 2015] in PyTorch, possibly others (some kind of policy gradient).
- Efficiency: Convert most defaultdict/dict uses to numpy.
- Docs: Tutorials, contribution policy, and thorough documentation.
- Visuals: Unify MDP visualization.
- Misc: Additional testing, reproducibility checks (store more in params file, rerun experiment from params file).
Cheers,
-Dave