VICReg: Variance Invariance Covariance Regularization for Self supervised Learning is authored by Adrien Bardes along with Jean Ponce & Yann LeCun and was published at ICLR 2022. VICReg falls under the category of Non-contrastive methods applied to joint embedding architectures for Self-Supervised Learning (SSL). Despite it's simplicity, it performs on par with other SSL methods and supervised baselines on downstream tasks such as image classification & object detection.
Keywords: Self-supevised Learning, Representation Learning
Self Supervised Learning (SSL) is one of the hottest topic in AI/ML at the moment. SSL is a method for learning representations from unlabeled data. While Self-supervised learning has made a huge success in Natural Language Processing (Eg: BERT, GPT), SSL has shown significant progress in Computer vision only in the recent years (Eg: DINO).
There are 2 popular methods for SSL applied to Vision, Contrastive Learning and Non-Contrastive Learning methods. Joint embedding architecture (JEA) is a core part behind these 2 methods. In simple terms, JEA consists of two networks which are trained to produce similar embeddings for different views of the same image. Siamese network is a popular instance of JEA, where the two networks share the same weights.
In Contrastive learning, JEA is trained to maximize the similarity between different views of the same image (positves) and to minimize the similarity between views of the different images (negatives). The challenge with contrastive learning is, it requires a large batch size to work well which is very costly. Whereas in Non-contrastive learning, JEA is just trained to maximize the similarity between positives and no negatives are used. But the main challenge with Non-contrastive learning is to prevent a collapse in which the two networks ignore the inputs and produce identical & constant vectors. Several methods (Eg: Barlow twins, W-MSE, VICReg) have been proposed to prevent collapse in the context of non-contrastive learning, among which VICReg is insanely simple and yet effective method.
As you can see in the below illustration, two different views (X,X') of the batch of images (I) are generated using transformations (T), which are then passed to the joint embedding architecture to produce the embeddings (Z,Z'). Loss is calculated between the embeddings Z and Z' which needs to be minimized.
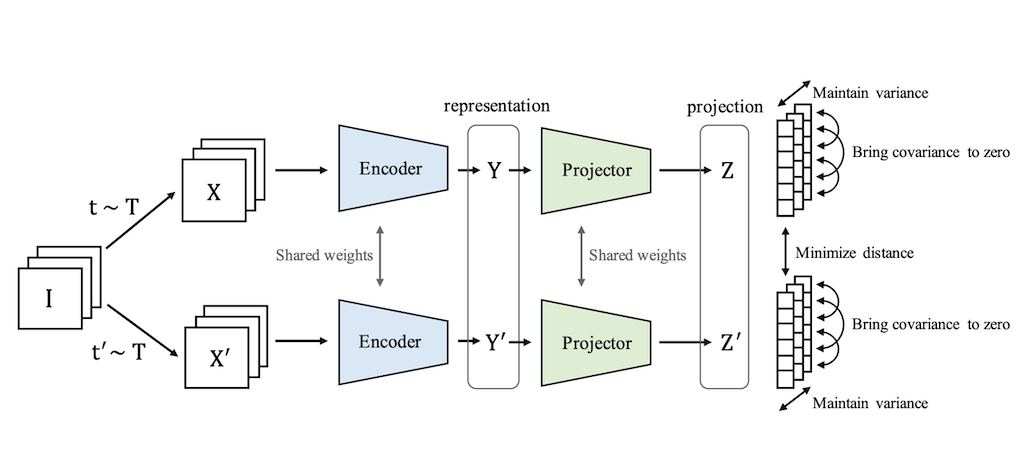
Illustration of VICReg method
The main component of the VICReg method is the Loss which needs to be minimized. The loss is a linear combination of 3 separate losses,
- Invariance loss: mean square distance between Z & Z'.
- Variance loss: a hinge loss to maintain the standard deviation (over a batch) of each variable of the embedding above a given threshold.
- Covariance loss: attracts the covariances (over a batch) between every pair of (centered) embedding variables towards zero.
Use of loss: Invariance loss helps in increasing the similarity between the embeddings (Z,Z'). Variance loss forces the embeddings of samples within a batch to be different, which effectively prevents the collapse. Covariance loss decorrelates the variables of each embedding or in other words, increases the information content of the embedding.
- Adrien Bardes, Jean Ponce, Yann LeCun. VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning. ICLR 2022. (link)
- Official codebase for VICReg (link)
- Yann LeCun. A Path Towards Autonomous Machine Intelligence. (link)
- SimCLR Jax/Flax Tutorial (link)
- My blog on Self-supervised Learning (link)
@inproceedings{bardes2022vicreg,
author = {Adrien Bardes and Jean Ponce and Yann LeCun},
title = {VICReg: Variance-Invariance-Covariance Regularization For Self-Supervised Learning},
booktitle = {ICLR},
year = {2022},
}