Official implementation from the following paper:
“Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation” Paper Link(Arxiv)

We propose SepReformer, a novel approach to speech separation using an asymmetric encoder-decoder network named SepReformer.
Demo Pages: Sample Results of speech separation by SepReformer
- python 3.10
- torch 2.1.2
- torchaudio 2.1.2
- pyyaml 6.0.1
- ptflops
- wandb
- mir_eval
- You can log the training process by wandb as well as tensorboard.
- Support dynamic mixing (DM) in training
- For training or evaluation, you need dataset and scp file
- Prepare dataset for speech separation (eg. WSJ0-2mix)
- create scp file using data/crate_scp/*.py
- If you want to train the network, you can simply trying by
-
set the scp file in ‘models/SepReformer_Base_WSJ0/configs.yaml’
-
run training as
python run.py --model SepReformer_Base_WSJ0 --engine-mode train
-
-
Simply evaluating a model without saving output as audio files
python run.py --model SepReformer_Base_WSJ0 --engine-mode test -
Evaluating with output wav files saved
python run.py --model SepReformer_Base_WSJ0 --engine-mode test_wav --out_wav_dir '/your/save/directoy[optional]'
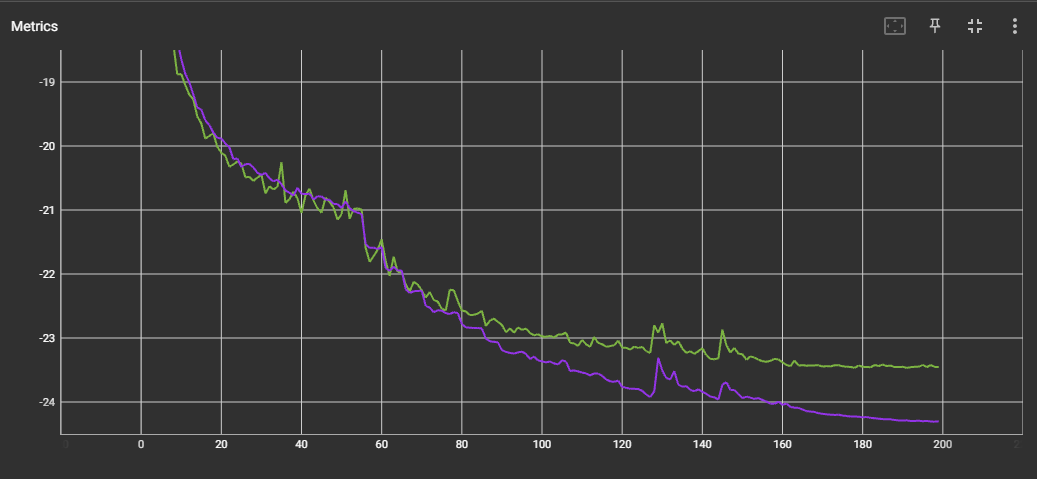
- For SepReformer-B with WSJ-2MIX, the training and validation curve is as follows:



If you find this repository helpful, please consider citing:
@misc{shin2024separate,
title={Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation},
author={Ui-Hyeop Shin and Sangyoun Lee and Taehan Kim and Hyung-Min Park},
year={2024},
eprint={2406.05983},
archivePrefix={arXiv},
}
- To add the pretrained model.