此项目旨在为番剧提供一个快速高效提取角色音频的解决方案。
WEBUI下载链接: Anime-Audio-Dataset-Maker-WEBUI Release
-
第一个方法 整合包一键下载使用方法: 链接: https://pan.baidu.com/s/1T9GbDo6enrV__G0j7pXbwQ?pwd=s556 提取码: s556 下载后使用 整合包使用这个.bat 即可
-
安装使用 首先先安装pytorch, 这个需要根据系统的cuda版本来进行安装 以我的Cuda11.8为例
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118在这里pytorch 选择你对应的版本并运行相对应的命令即可~
- 然后安装该仓库需要的依赖
pip3 install -r requirement.txt-
下载webui Anime-Audio-Dataset-Maker-WEBUI Release 下载最新版本的webui解压至该项目根目录下
-
运行launch.bat
项目会运行在7896端口
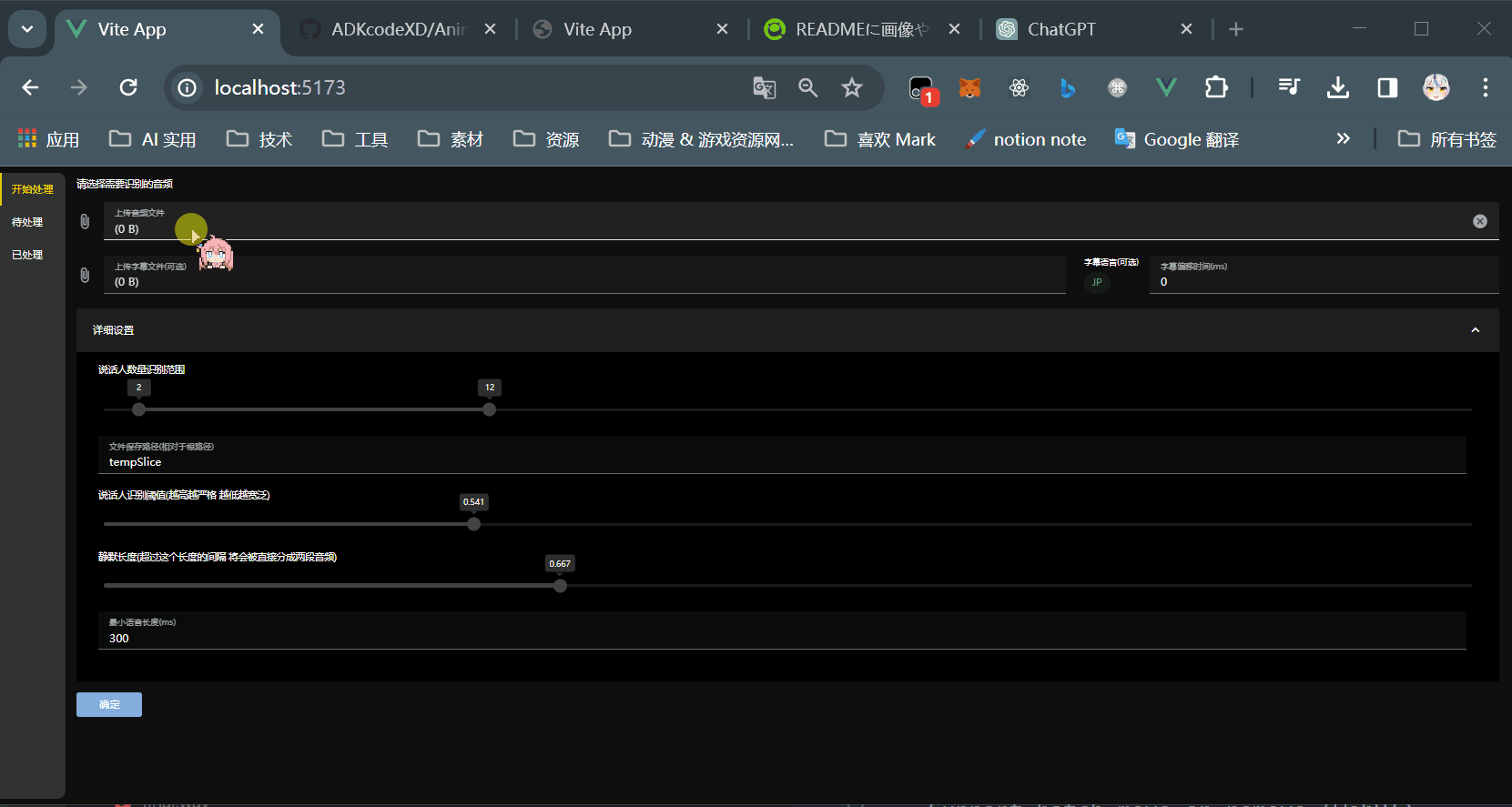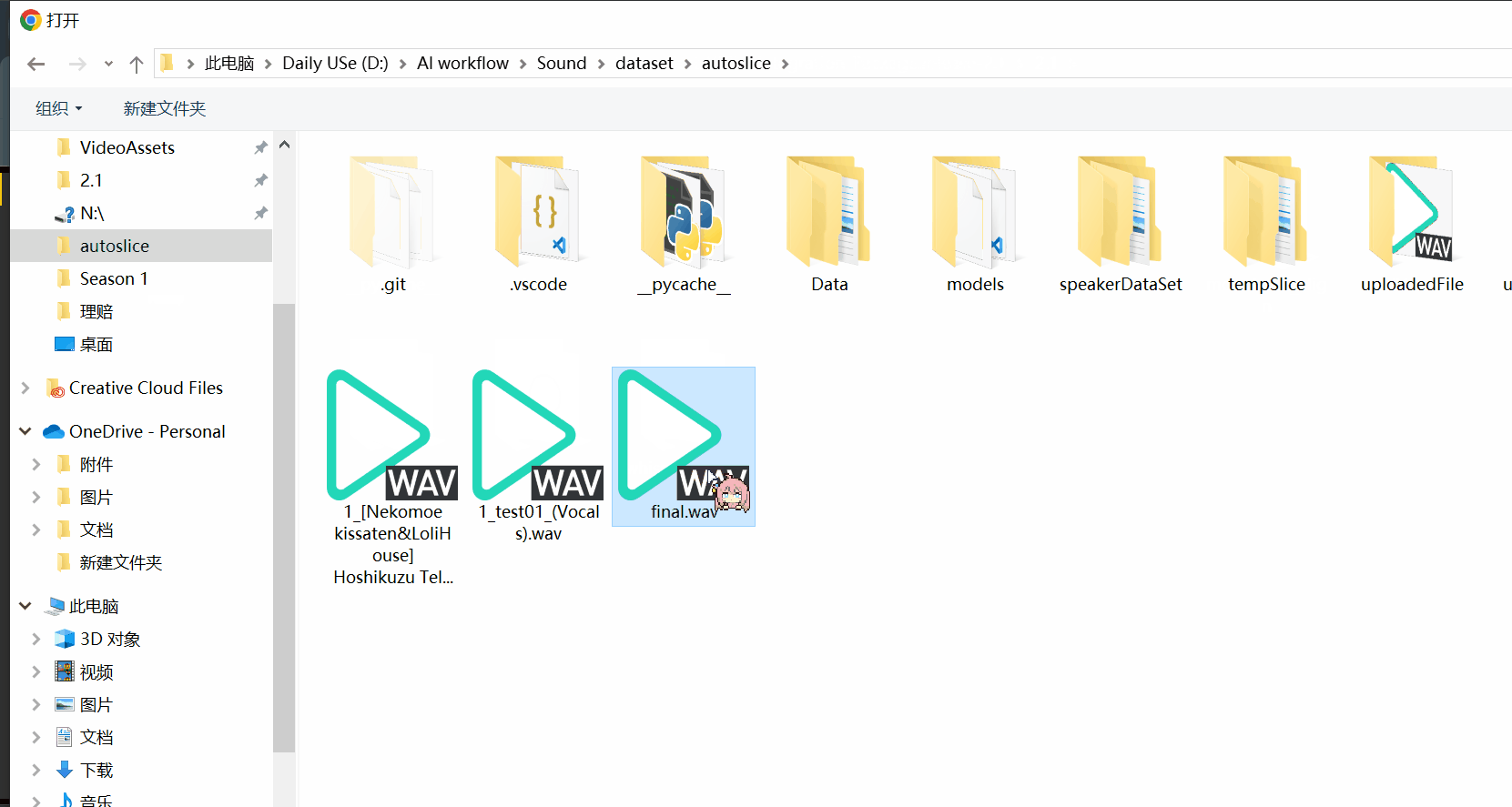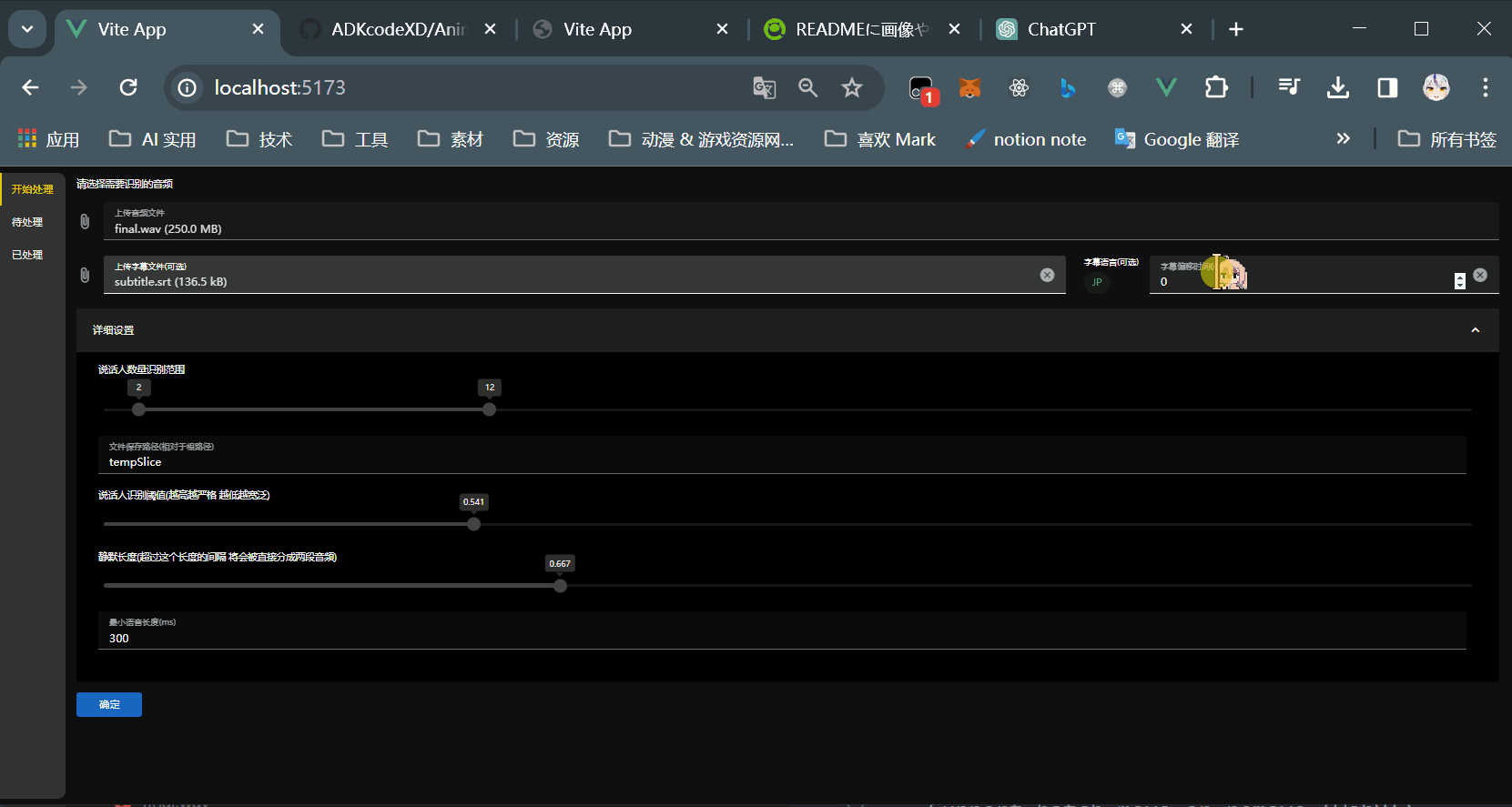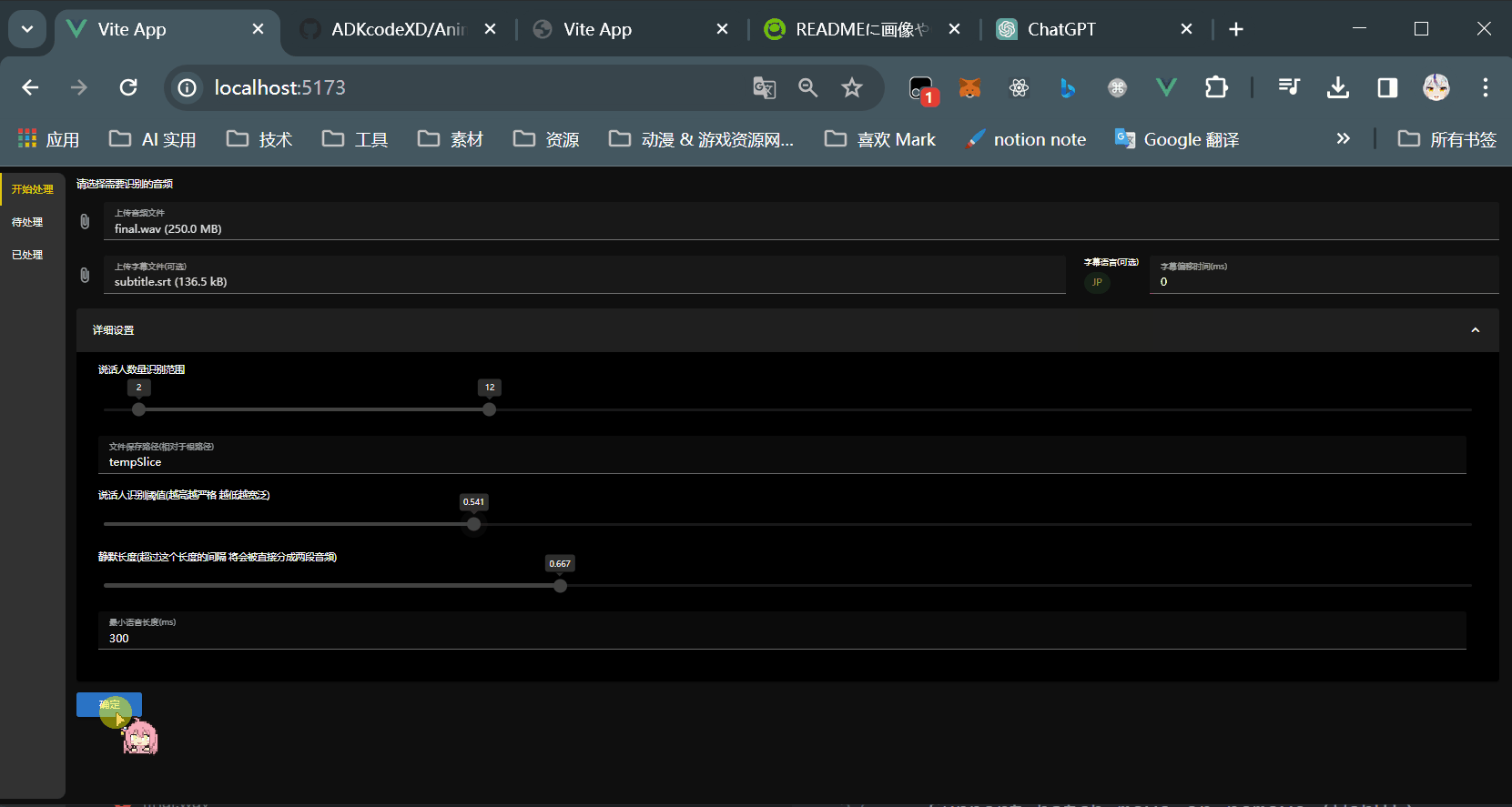
- 通过pyannote.audio对原音频进行说话人的识别和切割
- 通过字幕时间线对原音频进行切割
- 通过匹配检测最佳匹配的说话人
- 分类到各个说话人的文件夹中
- 开始预处理音频

...
- Support automaticly split long audio by each speaker
- Support sub upload and slice by sub timeline.
- Support edit the sub text and export it by bert-vits config
- Support split ever single audio (WebUI)
- Support merge audio with interval (WebUI)
- Support management folders or files (WebUI)
- Support use Arrow key to handle data (WebUI)
- Support batch rename (WebUI)
- Support batch move or remove (WebUI)