由于毕设需要使用clickhouse,
但是spring data jpa不支持clickhouse,(拒绝mybatis的xml)
只能自己写一个风格类似的先凑合用了。(以后有空再写个jpa规范版)
- clone本仓库
- 在本地执行 mvn clean install
- 添加依赖
<dependency>
<groupId>asalty.fish</groupId>
<artifactId>clickhouse-jpa</artifactId>
<version>1.0.4-release</version>
</dependency>
<dependency>
<groupId>com.github.housepower</groupId>
<artifactId>clickhouse-native-jdbc</artifactId>
<version>2.6.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.zaxxer/HikariCP -->
<!-- https://mvnrepository.com/artifact/com.zaxxer/HikariCP -->
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>4.0.3</version>
</dependency>- 填写配置文件
spring:
jpa:
clickhouse:
# clickhouse引擎
driver-class-name: com.github.housepower.jdbc.ClickHouseDriver
# clickhouse的url
url: jdbc:clickhouse://localhost
# clickhouse的端口
port: 19000
# clickhouse的数据库
database: tutorial
# clickhouse的用户名
username: default
# clickhouse的密码
password:
# 是否开启自动创建表\更新表
table-update: true
# 连接池配置
hikari:
# 连接池的最大连接数
maximumPoolSize: 60
# 空闲超时
idleTimeout: 1000000
# 连接超时时间
connectionTimeout: 5000- 新建一个实体类(若开启自动建表,会在容器启动时自动创建该实体对应的表)
@Data
@ClickHouseEntity
@ClickHouseTable(name = "create_table_test_entity", engine = ClickHouseEngine.MergeTree)
public class CreateTableTestEntity {
@ClickHouseColumn(isPrimaryKey = true)
public Long id;
@ClickHouseColumn(comment = "观看id")
public Long WatchID;
public Boolean JavaEnable;
@ClickHouseColumn(comment = "标题")
public String Title;
public String GoodEvent;
public Integer UserAgentMajor;
@ClickHouseColumn(name = "URLDomain")
public String testUserDefinedColumn;
public LocalDateTime CreateTime;
public LocalDate CreateDay;
public CreateTableTestEntity() {
}
}- 新建一个dao(需要在注解中指定实体,方法内的逻辑随意填写)
@ClickHouseRepository(entity = CreateTableTestEntity.class)
public class CreateTableTestEntityDao {
public List<CreateTableTestEntity> findAllByWatchID(Long watchID) {
return null;
}
public Boolean create(CreateTableTestEntity entity) {
return null;
}
@ClickHouseNativeQuery("select count(*) from create_table_test_entity")
public Long countAll() {
return null;
}
public Long countWatchIDByWatchID(Long watchID) {
return null;
}
public Long countWatchIDByWatchIDAndTitle(Long watchID, String title) {
return null;
}
}- 将dao注入到spring容器中使用
- 开启自动建表后生成的表:
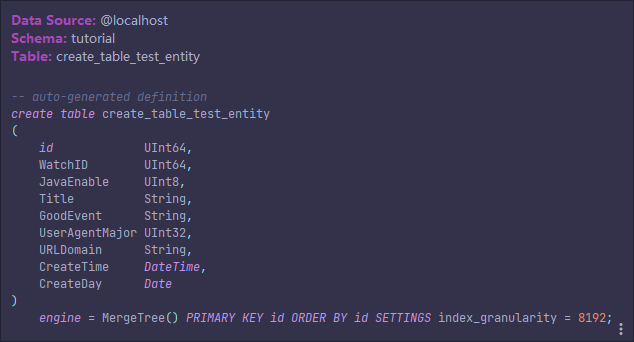

用于标记实体类
用于标记表名,默认为类名,可以指定表引擎,暂时只支持MergeTree
用于标记dao,需要在注解中指定dao对应的实体类
用于提供列的额外信息:列名(默认为字段名),是否为主键,注释内容(注释暂不支持写入表)。
用于标记原生sql查询,需要在注解中指定sql语句
- 没写防注入的逻辑(clickhouse-jdbc就不支持,自己写太累了)
- 自动生成的查询方法暂时只支持list返回值
- 自动生成的查询方法暂时只支持And和Or查询
- 自动生成的查询方法没有做大小写和列转换,所以需要保证方法名中的列名和实体类中的列名一致
- 自动生成的插入方法暂时只支持单个对象插入
- 没写更新和删除(好像也用不到)
- 暂时支持的列类型只有:
javaTypeToClickhouseMap.put(Long.class.getSimpleName(), "UInt64");
javaTypeToClickhouseMap.put(Integer.class.getSimpleName(), "UInt32");
javaTypeToClickhouseMap.put(Boolean.class.getSimpleName(), "UInt8");
javaTypeToClickhouseMap.put(String.class.getSimpleName(), "String");
javaTypeToClickhouseMap.put(LocalDateTime.class.getSimpleName(), "DateTime");
javaTypeToClickhouseMap.put(LocalDate.class.getSimpleName(), "Date");
javaTypeToClickhouseMap.put(Double.class.getSimpleName(), "Float64");- 修复每个线程不能单独拥有一个数据库连接的问题
- 提供生成的原生SQL的缓存(使用ConcurrentHashMap,日后考虑换caffeine)
- 修复了由于clickhouse读取出来的localdatetime格式为yyyyMMddTHHSS+时区导致的格式转换错误
- 修复了插入语句未缓存成功的问题
- 提供了批量插入代理
- 修复一个批量写入的sql拼接问题
benchmark代码链接:
https://github.com/A-Salty-Fish/IotBigData/tree/main/src/main/java/asalty/fish/iotbigdata/benchmark
benchmark结果(12线程,5s)(1图为开启SQL缓存,2图为关闭SQL缓存):

 可以看出,经过优化,框架的插入执行速率接近原生SQL执行。(我觉得如果把框架的日志去了可能还能更快一点)
可以看出,经过优化,框架的插入执行速率接近原生SQL执行。(我觉得如果把框架的日志去了可能还能更快一点)
benchmark结果:
 可以看出,单次写入还是比mysql慢了不少(20%)的,后面可以优化一下批量写入。
可以看出,单次写入还是比mysql慢了不少(20%)的,后面可以优化一下批量写入。
- 每次一次性写入10条时:
 可以看出,clickhouse此时已经反超mysql 40%
可以看出,clickhouse此时已经反超mysql 40% - 每次一次性写入50条时
 差距已经拉大到了130%
差距已经拉大到了130% - 每次一次性写入100条时
 差距拉大到了360%
差距拉大到了360% - 每次一次性写入200条时
 差距达到了惊人的380%
差距达到了惊人的380%




所以请尽量使用批量写入功能(batchCreate方法)
 可以看出,一次性插入200左右的数据时,总吞吐量最高
可以看出,一次性插入200左右的数据时,总吞吐量最高
Clickhouse数据行数为:10405961
Mysql数据行数为:9999993
执行的位运算操作均为:(参数为随机生成)
select max(watchid) from test_mysql_table where ((watchid ^ :watchId) >> :bit) = 0 均使用NativeQuery功能
均使用NativeQuery功能
可以看出clickhouse比mysql快了接近26倍
Clickhouse数据行数为:10405961
Mysql数据行数为:9999993
执行的between操作均为:(参数为随机生成)
select avg(watchid) from test_mysql_table where user_agent_major between :left and :right 均使用NativeQuery功能
均使用NativeQuery功能
可以看出clickhouse比mysql快了接近60倍