Java Web Application Server 2023
이 프로젝트는 우아한 테크코스 박재성님의 허가를 받아 https://github.com/woowacourse/jwp-was 를 참고하여 작성되었습니다.
- 자바 프로그램을 실행하면 JVM 프로세스 실행 → JVM 프로세스 안에서 GC 를 포함한 여러개의 스레드 실행
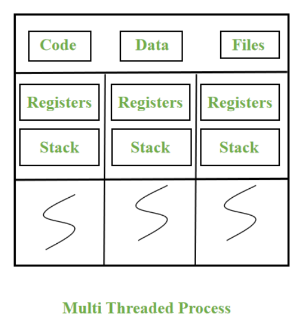
- 각 스레드마다 Java Stack, PC Register, Native Method Stack 이 존재
- 자바는 동일한 메모리를 읽지만 각각 작업을 수행하는 스레드들, 즉 멀티 스레드를 통해 동시에 여러 작업을 수행
- JVM 의 메모리 사용 방식

- 프로세스는 많은 시간과 자원이 드는 비싼 친구!
- JVM 은 벤더마다 다르지만 최소 32MB 이상의 메모리가 필요
- 스레드는 1MB 이내의 메모리를 점유하므로 스레드를 경량 프로세스라고 칭함
스레드는 User Level Threads(ULT)와 Kernel Level Threads(KLT) 2가지 유형이 있음
- ULT : 사용자 라이브러리를 통해 사용자가 만든 스레드로, 스레드가 생성된 프로세스이 주소 공간에서 해당 프로세스에 의해 실행되고 관리됨
- KLT : 커널에 의해 생성되고 OS 에 의해 직접 관리됨. ULT 보다 생성 및 관리 속도가 느림
두 유형의 차이는 누가 스레드를 제어하느냐의 관점임
ULT 는 스레드가 생성된 프로세스 자체에 의해 제어되고, KLT 는 프로세스 내의 사용자 스레드에 대해 알지 못하고 OS 에 의해 직접 관리됨
- ULT 실행 시나리오
- 스레드를 실행하기 위해서는 커널의 CPU 스케줄러가 스레드를 CPU에 스케쥴링해야함
- 하지만 CPU 스케쥴러는 커널의 일부이기 때문에 ULT 에 대해 알지 못함
- 그래서 ULT 는 KLT 에 매핑되어 실행하게됌
- ULT ↔ KLT 매핑 방법
- Many to One Model, 다대일 모델
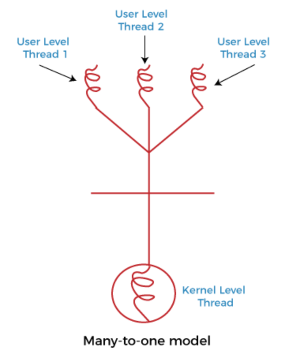
- 다대일 모델은 여러 ULT 를 하나의 KLT 에 매핑함. 스레드는 사용자 공간의 스레드 라이브러리에 의해 관리됨
- 한 스레드가 Blocking 되면 전체 프로세스가 Block됨
- 한번에 하나의 스레드만 커널에 접근할 수 있기 때문에 멀티 코어 시스템에서 병렬 실행 불가능 But 동기화 및 리소스 공유가 쉬워서 실행시간이 단축됨
- Java 의 초기 버전 스레드 모델인 Green Thread 가 이 모델을 채택했지만 대부분의 컴퓨팅 시스템이 멀티 코어로 바뀌면서 해당 모델은 사용되지 않음
- One to One Model, 일대일 모델
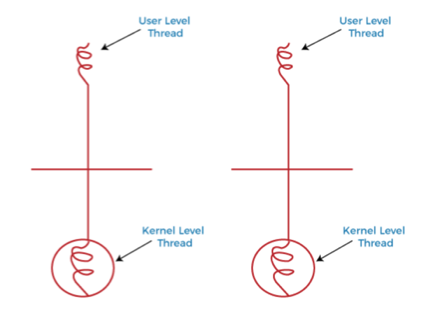
- 일대일 모델은 각 ULT 를 각각의 하나의 KLT 에 매핑
- 한 스레드가 Blocking 되더라도 다른 스레드가 실행될 수 있기 때문에 병렬 실행에 용이
- But ULT 를 위해 KLT 를 만들어야하는 큰 단점 존재, 많은 KLT 는 시스템에 부하를 가하기 때문에 OS 는 스레드 수의 증가를 제한함
- Many to Many Model, 다대다 모델
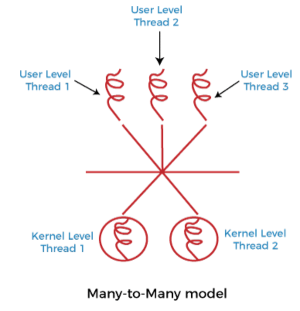
- 해당 모델은 여러개의 ULT 보다 작은 혹은 같은 수의 KLT 로 매핑
- KLT 의 수는 시스템의 코어 수에 따라 다름. 코어의 갯수가 많을 수록 많은 KLT 를 할당받음
- 이전 두 모델의 단점을 절충한 방법으로 개발자는 필요한 만큼 ULT 를 생성하고 그에 상응하는 KLT 가 병렬로 수행됨. 가장 높은 정확도의 동시성 처리를 제공하는 모델로, 하나의 스레드가 Blocking 되었을 때 커널은 다른 스레드의 수행을 스케쥴링할 수 있음
- 일대일 모델로도 동작할 수 있음. 매우 좋아보이지만 실제로 구현하기 어렵고 시스템에서 코어 수가 증가하면서 커널 스레드를 제한하는 중요성이 줄어 대부분의 OS 에서 일대일 모델 차용중
- Many to One Model, 다대일 모델



초기에는 Green Thread 를 사용하다가 Native Thread 모델로 변경
Java의 스레드 모델은 Native Thread로, Java의 유저 스레드를 만들면 Java Native Interface(JNI)를 통해 커널 영역을 호출하여 OS가 커널 스레드를 생성하고 매핑하여 작업을 수행하는 형태
| Green Thread | Native Thread | |
|---|---|---|
| Multi Threading Model | 다대일 모델 | 다대다 모델 |
| 구현 및 관리 | 애플리케이션 수준에서 구현되고 사용자 공간에서 관리 | OS 수준에서 구현되고 커널 공간에서 관리 |
| 장점 | 동기화 및 자원 공유가 용이하여 실행 시간이 단축됨 | 높은 정확도의 동시성 처리, 멀티코어 시스템의 활용할 수 있음 |
| 단점 | 멀티 코어 시스템의 이점을 살릴 수 없음 | 스레드 동기화 및 자원 공유가 복잡 → 실행 시간 증가 |
- Java 1.0 - 1.1
- 초기 버전에서는 스레딩에 대한 기본 클래스들이 제공되지 않았음
- 개발자는
Thread클래스를 직접 확장하거나Runnable인터페이스를 구현하여 스레드를 생성
- Java 1.2 - 1.4 (Java 2)
- Java 2에서는
java.lang.Thread클래스 및java.lang.Runnable인터페이스가 도입 Thread클래스의 메서드 중 일부가 synchronized로 선언되어 멀티스레딩에서 더 쉽게 사용synchronized키워드를 사용하여 스레드 간 동기화 지원.
- Java 2에서는
- Java 5 (Java 1.5) - 동시성 API의 도입
java.util.concurrent패키지 도입으로 스레드 풀, 락, 동시 컬렉션 등을 포함한 새로운 동시성 API가 도입Executor프레임워크,Future및Callable인터페이스,Lock및ReentrantLock등이 추가volatile키워드의 사용이 변경되어 스레드 간 가시성이 향상되었습니다.
- Java 6
java.util.concurrent패키지에 몇 가지 새로운 클래스 및 개선 사항이 추가되었습니다.- **
StampedLock**이 추가되어 낙관적인 읽기와 쓰기 잠금을 지원했습니다.
- Java 7
- **
ForkJoinPool**이 도입되어 병렬 처리를 지원하는데 사용됩니다. ThreadLocalRandom클래스 도입으로 스레드 간 랜덤 넘버 생성이 향상되었습니다.
- **
- Java 8
- 람다 표현식이 도입되어 함수형 프로그래밍이 가능해졌습니다.
java.util.stream패키지 추가로 병렬 스트림을 통한 간단한 병렬 처리를 제공.
- Java 9
FlowAPI 도입으로 리액티브 프로그래밍 및 비동기 프로그래밍을 위한 스트림 기능이 향상되었습니다.
- Java 11
- **
java.util.concurrent**에 **CompletableFuture**에 새로운 메서드 추가. Thread.onSpinWait()메서드 도입.
- **
- 그 이후 눈여겨볼만한 Thread 변경
Virtual Thread: 경량 스레드 모델-
기존 스레드 모델의 문제점
- 요청량이 급격하게 증가하는 서버 환경에서는 갈수록 더 많은 스레드 수를 요구하게 되었음. 스레드의 사이즈가 프로세스에 비해 작다고 해도, 스레드 1개당 1MB 사이즈라고 가정하면, 4GB 메모리 환경에서도 많아야 4,000개의 스레드를 가질 수 있음. 이처럼 메모리가 제한된 환경에서는 생성할 수 있는 스레드 수에 한계가 있었고, 스레드가 많아지면서 컨텍스트 스위칭 비용도 기하급수적으로 늘어나게됌
-
더 많은 요청 처리량과 컨텍스트 스위칭 비용을 줄여야 했는데, 이를 위해 나타난 스레드 모델이 경량 스레드 모델인
-
Virtual Thread
-
while ((connection = listenSocket.accept()) != null) {
Thread thread = new Thread(new RequestHandler(connection));
thread.start();
}- 다음과 같은 Thread 운영 방식을 서버에 도입할 경우 동시에 여러 사용자가 접속할 때에 스레드를 계속해서 생성 → 자바 스레드 모델의 경우, thread 를 OS의 자원으로 사용하기 때문에 OS 자원이 빨리 소진되어 서버가 다운될 위험이 있음
- 또한 Thread 가 실행한 task 의 결과를 반환하고 싶은 경우, 기존 Java Thread 로는 불가능한 부분이 존재
이를 해결하기 위한 Concurrent 패키지
-
Thread Pool 이란- 탄생 배경
- 데이터베이스 및 웹 서버와 같은 서버 프로그램은 여러 클라이언트의 요청을 반복적으로 실행하며 많은 수의 작은 작업들을 처리하는 데 중점을 둠. 서버 응용 프로그램을 이러한 요청을 처리하는 방식은 요청이 도착할 때마다 새 스레드를 만들고 새로 만든 스레드에서 받은 요청을 처리하는 것. BUT 모든 요청에 대해 새 스레드를 생성하는 서버는 실제 요청을 처리하는 것보다 스레드 생성 및 소멸에 더 많은 시간을 소비하고 더 많은 시스템 리소스를 소비. 활성(active) 스레드는 시스템 리소스를 소비하기 때문에 동시에 너무 많은 스레드를 생성하는 JVM은 시스템에 OOM을 유발할 수 있음. 이것은 생성되는 쓰레드의 수를 제한할 필요성을 느끼게함.
- 운영 방식
- 쓰레드 풀은 미리 일정 개수의 쓰레드를 생성하여 관리하는 기법
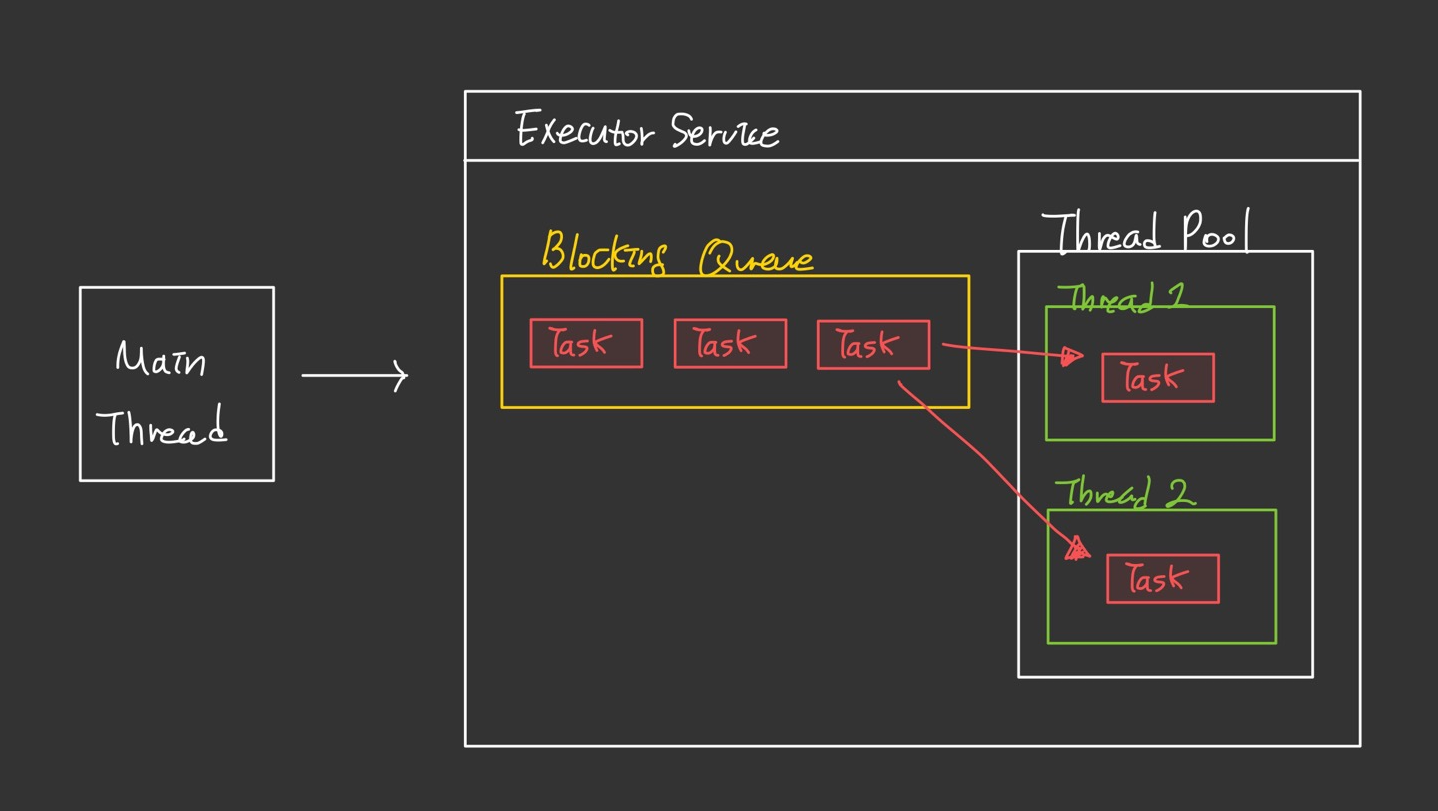
- 미리 생성된 쓰레드들은 작업을 할당받기 위해 대기 상태에 있게 되는데, 작업이 발생하면 대기 중인 쓰레드 중 하나를 선택하여 작업을 수행. 작업이 완료되면 해당 스레드는 다시 대기 상태로 돌아가고, 새로운 작업을 할당받을 준비.
- 쓰레드 풀을 사용하면 스레드 생성 및 삭제에 따른 오버헤드를 줄일 수 있으며, 특정 시점에 동시에 처리할 수 있는 작업의 개수를 제한할 수 있음.
- 쓰레드 풀은 미리 일정 개수의 쓰레드를 생성하여 관리하는 기법
- 탄생 배경
-
How to Use??

웹 애플리케이션에 쓰레드 풀을 도입하기 좋은 이유 - 쓰레드풀은 동일하고 서로 독립적인 다수의 작업을 실행 할 때 가장 효과적이다.실행 시간이 오래 걸리는 작업과 금방 끝나는 작업을 섞어서 실행하도록 하면 풀의 크기가 굉장히 크지 않은 한 작업 실행을 방해하는 것과 비슷한 상황이 발생한다. 또한 크기게 제한되어 있는 쓰레드 풀에 다른 작업의 내용에 의존성을 갖고 있는 작업을 등록하면 데드락이 발생할 가능성이 높다. 다행스럽게도 일반적인 네트웍 기반의 서버 어플리케이션 (웹서버,메일서버,파일서버등)은 작업이 서로 동일하면서 독립적이어야 한다는 조건을 대부분 만족한다. - Java concurrency in practice 책 발췌
- 변경점
var executor = Executors.newFixedThreadPool(30);
while ((connection = listenSocket.accept()) != null) {
// STEP-1 [요구 사항 3] Concurrent 패키지를 사용하도록 변경.
executor.execute(new RequestHandler(connection));
}- 다른 작업의 결과를 동시에 기다리는 작업을 대기열에 넣으면 안됨. 이로 인해 위에서 설명한 교착 상태가 발생할 수 있음
- 스레드 풀은 마지막에 명시적으로 종료시켜야함. 이 작업을 하지 않으면 프로그램이 계속 실행되고 끝나지 않습니다. 풀에서 shutdown()을 호출하여 Excutor를 종료. 종료 후 이 Excutor에 다른 작업을 보내려고 하면 RejectedExecutionException이 발생
- JVM에서 실행할 수 있는 최대 스레드 수를 제한하여 JVM의 메모리 부족 가능성을 줄이는 것이 좋음.
- 처리를 위해 새 스레드를 생성하는 반복문을 구현해야 하는 경우 ThreadPool이 최대 제한에 도달한 후 새 스레드를 생성하지 않기 때문에 ThreadPool을 사용하면 더 빠르게 처리하는 데 도움이 됨.
실제 세계처럼 더 밀접한 모델링 방식이 필요해서 등장한 방식이 객체 지향 프로그래밍(Object Oriented Programming)임. OOP 의 핵심은 객체와 클래스인데 이들은 실제 개체와 같은 데이터와 행동이라는 2가지 특징을 지니고 있음
- 데이터는 객체의 속성과 상태를 나타냄
- 행동은 스스로 변화하고 다른 물체와 소통할 수 있는 능력
객체는 클래스의 인스턴스임. 각각의 객체는 상태, 행동 그리고 식별자를 갖고 있음. 또한 객체들은 서로간의 호출을 통해 통신할 수 있으며 이를 message passing이라고 함
하나의 클래스를 통해 필요로하는 어플리케이션에 여러개의 객체를 생성. 각 객체의 식별은 일반적으로 JVM 에 의해 유지되며 Java 객체를 만들 때마다 JVM 은 객체에 대한 해시코드를 만들고 할당함. 이를 통해 JVM 은 모든 객체가 고유하게 식별되도록함
-
추상화(Abstraction)
추상화는 컨텍스트와 관련이 없는 정보를 숨기거나 관련된 정보만 알 수 있도록 하는 것. 일반적인 추상화는 데이터 추상화 와 제어 추상화로 볼 수 있음
// 데이터 추상화 public class Employee { private Department department; private Address address; private Education education; // 복잡한 데이터 형태를 생성하기 위해 여러 작은 데이터 타입을 사용하는 방법 }
//제어 추상화 public class EmployeeManager { public Address getPrefferedAddress(Employee e) { // 어떤 클래스의 메소를 사용하는 사용자에게 해당 메소드의 작동방식과 // 같은 로직을 숨기기 위함임. 만일 메소드 내 로직이 변경된다고 하더라도 // 실제 사용자는 변경된 내용이 어떤 것인지 알 필요 없이 이전과 동일하게 메소 // 사용할 수 있음. 따라서 로직이 변경되더라도 사용자에게 영향을 주지 않음 } }
-
캡슐화(Encapsulation)
캡슐화는 관련이 있는 변수와 함수를 하나의 클래스로 묶고 외부에서 쉽게 접근하지 못하도록 은닉하는 것. 객체의 직접적인 접근을 막고 외부에서 내부의 정보에 직접 접근하거나 변경할 수 없고 객체가 제공하는 필드와 메소드를 통해서만 접근이 가능. 캡슐화에는 정보은닉과 구현은닉을 모두 갖고 있음
정보은닉의 방법으로는 1. 접근제어자를 사용하여 외부에서 접근할 수 없도록 하며 2. 인터페이스를 통해 구현은닉을 달성하는 것. 구현은닉은 객체가 책임을 이행하는 방식을 수정할 수 있도록 개발자에게 자유를 제공. 이는 설계가 변경 될 때 유용하게 작용할 수 있습니다.
//정보 은닉 class InformationHiding { // 직접 접근 막기 private ArrayList items = new ArrayList(); public ArrayList getItems(){ // item에는 직접 접근x, 메서드를 통해 접근 return items; } }
//구현 은닉 interface ImplemenatationHiding { Integer sumAllItems(ArrayList items); } class InformationHiding implements ImplemenatationHiding { private ArrayList items = new ArrayList(); public ArrayList getItems(){ return items; } public Integer sumAllItems(ArrayList items) { //이 함수의 사용자는 내부 구현과 무관 } }
-
상속(Inheritance)
자바에서의 상속은 하나의 클래스가 부모클래스의 속성과 행동을 얻게 되는 방법. 상속은 코드의 재사용성과 유지보수를 위해 사용. 상속을 사용하기 위해서는 extends 키워드를 상속 받을 클래스에 명시하여 사용할 수 있음. sub클래스는 super클래스의 non-private 멤버들을 상속 받게되며 생성자는 멤버가 아니기 때문에 상속되지 않음. 하지만 sub클래스에서 super클래스의 생성자를 호출할 수 있음
-
다형성(Polymorphism)
다형성은 같은 자료형에 여러가지 객체를 대입하여 다양한 결과를 얻어내는 성질을 의미. 이를 통해 동일한 이름을 같은 여러 형태의 매소드를 만들 수 있음. 자바에서는 다형성을 다루는 근본적인 방법이 2가지 : compile time polymorphism 과 runtime polymorphism
compile time polymorphism은 컴파일러가 필요한 모든 정보를 가지고 있고 프로그램 컴파일 중에 호출할 방법을 알기 때문에 컴파일 시간에 적절한 메소드를 각각의 객체에 바인딩할 수 있음. 정적바인딩이나 early binding이라고도 불림. 자바에서는 메소드 오버로딩을 통해 사용됨. 메소드 오버로딩을 통해 메소드의 매개변수의 형태가 달라질 수 있음.
runtime polymorphism은 동적 바인딩이라고 불리며 메소드 오버라이딩과 연관있음. 일반적으로 런타임 다형성은 부모 클래스와 자식 클래스가 존재할때 사용되는데 부모자식 클래스에 존재하는 메소드를 실행시키게 되면 런타임과정에서 해당 인스턴스에 맞는 메소드를 호출하게 됨
class Animal { public void makeSound() { System.out.println("Some generic sound"); } } class Dog extends Animal { @Override public void makeSound() { System.out.println("Bark! Bark!"); } public void fetch() { System.out.println("Fetching the ball"); } } class Cat extends Animal { @Override public void makeSound() { System.out.println("Meow!"); } public void climb() { System.out.println("Climbing the tree"); } } public class RuntimePolymorphismExample { public static void main(String[] args) { Animal myDog = new Dog(); Animal myCat = new Cat(); // 런타임 다형성: 실제 객체의 타입에 따라 메서드가 동적으로 호출됨 myDog.makeSound(); // "Bark! Bark!" myCat.makeSound(); // "Meow!" // myDog와 myCat은 Animal 타입으로 선언되었기 때문에 Animal 클래스의 메서드에만 접근 가능 // myDog.fetch(); // 컴파일 오류: Animal 클래스에는 fetch() 메서드가 없음 // myCat.climb(); // 컴파일 오류: Animal 클래스에는 climb() 메서드가 없음 // 형변환을 통해 실제 객체의 타입에 따라 다양한 메서드에 접근 가능 if (myDog instanceof Dog) { ((Dog) myDog).fetch(); // "Fetching the ball" } if (myCat instanceof Cat) { ((Cat) myCat).climb(); // "Climbing the tree" } } }
결합도(Coupling)
결합도는 클래스간의 상호 의존 정도를 의미. 즉 얼마나 강하게 클래스들 사이에 연관이 되어있는지를 뜻함. 좋은 소프트웨어는 낮은 결합도(low coupling)를 갖고 있는 것. 즉 하나의 클래스는 특정 기능에 독립적이여야하며 EmailSender 라는 클래스의 경우 이메일을 전송하는 기능에만 집중
응집도(Cohesion)
응집도는 하나의 클래스가 기능에 집중하기 위한 모든 정보와 역할을 갖고 있어야 한다는 의미. 만일 어떤 기능이 작동하기 위해 여러 클래스가 필요다면 유지보수적인 측면에서 좋지 않고 재사용성을 낮춤. 좋은 소프트웨어는 높은 응집도(high cohesion)을 유지
Association
Association은 독립적인 라이프사이클을 갖고 있는 객체들의 관계를 의미. 클래스들간의 연관은 이루어지지만 한 클래스의 생성과 제거에 의해 다른 클래스가 영향 받지 않는 속성
Aggregation
Aggregation은 객체들 간의 관계에서 독립적인 라이프사이클은 존재하지만 관계의 소유권이 존재. 부모클래스와 자식클래스 사이에서 자식 클래스는 다른 부모 클래스에 속할 수 없음. 하지만 자식클래스 자체 라이프사이클은 독립적으로 존재
Composition
Composition은 객체간의 관계에서 독립적인 라이프사이클이 존재하지 않는 성질. 만약 부모 객체가 삭제된다면 모든 자식 객체들 또한 삭제
상속보단 Composition
composition을 구현하기 위해서는 다양한 인터페이스의 생성이 이루어짐. 상속은 어떤 클래스의 기능을 확장시키기 위한 목적으로 볼 수 있고 인터페이스는 해당 시스템이 작동하는데 필요한 필수적인 변수와 메소드들을 명시해줌. 인터페이스 구현을 통해 필수적인 기능외에 필요한 비지니스 로직들이 추가되고 사용자는 인터페이스에 존재하는 메소드를 통해 시스템을 작동 시킬 수 있기 때문입니다.
인터페이스 사용하여 구현하기
인터페이스를 사용하게 되면 코드의 유연성이 증가. 인터페이스는 super class와 같은 역할을 하기 때문에 인터페이스를 통해 레거시 코드를 변경하지 않고 메소드의 로직을 새롭게 생성 할 수 있음
변경 사항 캡슐화
향후 변경 가능성이 있는 코드를 캡슐화하여 사용자가 코드를 직접 변경하는 일을 줄일 수 있음. 접근제어자를 사용하여 캡슐화를 진행하고 캡슐화를 달성하기 위해서는 디자인 패턴 중 팩토리 디자인 패턴을 사용할 수 있음.
-
단일 책임 원칙(SRP, Single Responsibility Principle)
There should never be more than one reason for a class to change. In other words, every class should have only one responsibility.
한 클래스는 하나의 책임만 가져야한다는 원칙.
public class Developer { private final static boolean BACKEND = true; private final static boolean FRONTEND = false; private final boolean role; public void work() { if (this.role == BACKEND) { ... } else { ... } } }
- Developer 클래스의 work() 메서드는 백엔드와 프론트엔드 개발자의 행위를 모두 구현하려고 하기 때문에, 단일 책임 원칙을 위반
- 해결책 : 해당 클래스를 Developer 클래스를 상속하는 BackendDeveloper와 FrontendDeveloper 클래스로 분리한다면 분기문을 사용할 필요가 없으며, 단일책임 원칙을 지킬 수 있음. 다음과 같이 역할에 따라 클래스를 분리해 놓으면, 백엔드 개발자의 역할이 바뀐다고 해도 FrontendDeveloper 클래스에는 전혀 영향이 가지 않음. 이처럼 변경이 있을 때 파급 효과가 적다면 단일 책임 원칙을 잘 따른 것이라고 판단
-
개방-폐쇄 원칙(OCP, Open/Closed Principle)
Software entities ... should be open for extension, but closed for modification.
소프트웨어의 요소(클래스, 모듈, 함수 등)는 확장에는 열려있으나 변경에는 닫혀있어야 한다는 원칙
import java.util.List; public interface CalculatorOperation { void perform(); } public class Addition implements CalculatorOperation { private double left; private double right; private double result; // constructor, getters and setters @Override public void perform() { result = left + right; } } public class Subtraction implements CalculatorOperation { private double left; private double right; private double result; // constructor, getters and setters @Override public void perform() { result = left - right; } } public class Calculator { private List<CalculatorOperation> operations; public Calculator(List<CalculatorOperation> operations) { this.operations = operations; } public void calculate(CalculatorOperation operation) { if (operation == null) { throw new InvalidParameterException("Cannot perform operation"); } operation.perform(); } public void addOperation(CalculatorOperation operation) { operations.add(operation); } }
- CalculatorOperation 클래스가 존재하고 Addition, Division 등의 구체적인 연산을 구현한 클래스가 CalculatorOperation 인터페이스를 구현하는 방식으로 설계한다면, 추가적인 연산이 생겨 클래스를 확장하더라도 Calculator의 코드는 변경할 필요가 없음. 이와같이 다형성을 활용하면 새로운 기능이 추가될 때 기존에 사용하던 인터페이스를 구현한 새로운 클래스를 만들어주기만 하면 됨
public static void main(String[] args) { // 더하기와 빼기 연산을 포함한 Calculator 객체 생성 List<CalculatorOperation> operations = new ArrayList<>(); operations.add(new Addition(5, 3)); // 더하기 연산 operations.add(new Subtraction(10, 7)); // 빼기 연산 Calculator calculator = new Calculator(operations); // 각각의 연산 실행 for (CalculatorOperation operation : operations) { calculator.calculate(operation); } // 결과 출력 Addition additionResult = (Addition) operations.get(0); Subtraction subtractionResult = (Subtraction) operations.get(1); System.out.println("Result of addition: " + additionResult.getResult()); System.out.println("Result of subtraction: " + subtractionResult.getResult()); }
-
리스코프 치환 원칙(LSP, Liskov Subsitution principle)
Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.
프로그램 객체는 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다는 원칙
예를 들어 동물이라는 클래스를 상속하는 고양이와 강아지 클래스가 있다고 할 때 고양이 클래스의 인스턴스는 동물 객체 참조 변수에 대입하더라도 동물 클래스의 인스턴스 역할을 하는 데 문제가 없어야함
Animal cat1 = new Cat();
그러나 A 클래스가 B 클래스가 가진 역할을 수행할 수 없는데도, A 클래스가 B 클래스를 상속하도록 설계한다면 리스코프 치환 원칙을 위배한 것. 예를 들어 Father 클래스의 역할을 Daughter가 할 수 없는데도 Daughter 클래스가 Father 클래스를 상속하도록 설계한 건 객체지향의 상속을 잘못 적용하고 있으며, 리스코프 치환 원칙을 위배한 사례
Father jane = new Daughter();
쉽게 말해 하위 클래스는 상위 클래스의 한 종류라는 상속의 규칙을 잘 지키고 있고, 인터페이스를 구현하고 있는 구현 클래스가 인터페이스의 규약을 전부 지키고 있다면 리스코프 치환 원칙을 준수하고 있다고 판단
-
인터페이스 분리 원칙(ISP, Interface Segregation Principle)
Many client-specific interfaces are better than one general-purpose interface.
특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다는 원칙
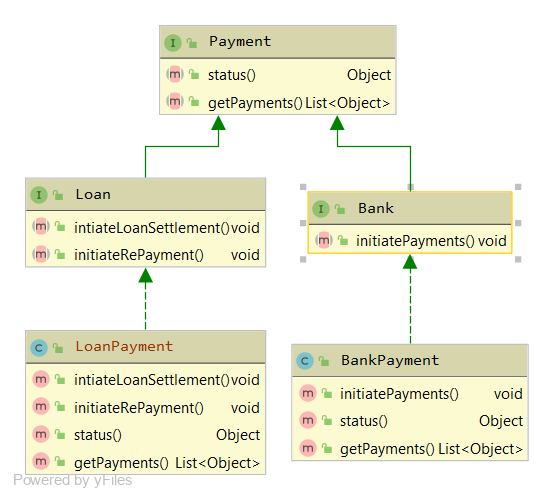 예를 들어 Payment 인터페이스를 Loan 인터페이스와 Bank 인터페이스로 분리한다면 Bank 인터페이스에 수정이 발생해도 Loan 클라이언트에게는 영향을 주지 않으며, Loan 클라이언트는 Bank 인터페이스가 아닌 Loan 인터페이스에 있는 메서드들과만 의존 관계를 맺음. 또한 구현 클래스는 한 개의 범용 인터페이스 사용으로 인한 비어있는 메서드들을 가질 필요가 없음. 이처럼 인터페이스 분리 원칙을 적용한다면 인터페이스가 명확해지고 대체 가능성이 높아진다는 장점이 있음
예를 들어 Payment 인터페이스를 Loan 인터페이스와 Bank 인터페이스로 분리한다면 Bank 인터페이스에 수정이 발생해도 Loan 클라이언트에게는 영향을 주지 않으며, Loan 클라이언트는 Bank 인터페이스가 아닌 Loan 인터페이스에 있는 메서드들과만 의존 관계를 맺음. 또한 구현 클래스는 한 개의 범용 인터페이스 사용으로 인한 비어있는 메서드들을 가질 필요가 없음. 이처럼 인터페이스 분리 원칙을 적용한다면 인터페이스가 명확해지고 대체 가능성이 높아진다는 장점이 있음 -
의존관계 역전 원칙(DIP, Dependency Inversion Principle)
Depend upon abstractions, not concretions.
추상화에 의존해야지 구체화에 의존하면 안 된다는 원칙
예를 들어 자동차와 타이어의 관계를 생각해보자. 타이어는 소모품이고, 계절에 따라 교체될 수 있음. 따라서 자동차와 타이어의 관계를 설정할 때 자동차가 스노우타이어라는 구체 클래스를 의존하게 하는 것보단, 스노우타이어, 일반타이어, 광폭 타이어가 구현하고 있는 타이어라는 인터페이스를 새로 정의하고, 자동차는 타이어 인터페이스를 의존하게 하는 것이 좋음. 인터페이스가 아닌 구현체에 의존하게 된다면 구현체의 유연한 변경이 어려워지기 때문에, 구현 클래스 또는 하위 클래스보다 변경 가능성이 낮은 인터페이스, 추상 클래스, 상위 클래스에 의존하는 것이 좋음
-
SOLID 정리
SRP : 어떤 클래스를 변경해야 하는 이유는 오직 하나뿐이어야 한다. OCP : 자신의 확장에는 열려 있고, 주변의 변화에 대해서는 닫혀 있어야 한다. LSP : 서브 타입은 언제나 자신의 기반 타입으로 교체할 수 있어야 한다. ISP : 클라이언트는 자신이 사용하지 않는 메서드에 의존 관계를 맺으면 안 된다. DIP : 자신보다 변하기 쉬운 것에 의존하지 마라.

-
객체의 생성에도 유의미한 이름을 사용하라
객체의 생성자가 오버로딩되는 경우 어떠한 값으로 생성되는지 정보가 부족할 수 있음. 그러므로 이러한 경우에는 정적 팩토리 메소드를 사용하는 것보다 명확한 코드를 작성하게 해줄 것임. But 구현을 드러내는 이름은 피하는 것이 좋음
// 두 번째 인자가 무엇인지 파악이 어렵다. Product product = new Product("사과", 10000); // 이름을 부여하여 두 번째 인자를 명확하게 파악할 수 있다. // private 생성자를 통해 Product product = Product.withPrice("사과", 10000);
-
함수는 하나의 역할만 해야한다 예를 들어 다음과 같은 Switch 문은 정말 흔히 작성하는 코드이지만, 많은 문제를 내포하고 있음
public Money calculatePay(Employee e) throws InvalidEmployeeType { switch(e.type) { case COMMISSIONED: return calculateCommisionedPay(e); case HOURLY: return calculateHourlyPay(e); case SALARIED: return calculateSalariedPay(e); default: throw new InvalidEmployeeType(e.type); } }
하지만 위의 코드는 다음과 같은 문제점 목록을 가지고 있음
- 함수가 너무 길다. 새로운 직원 타입이 추가되면 더 길어질 것이다.
- 한 가지 작업만을 수행하지 않는다. 해딩 직원이 어느 타입인지 확인하고 있다.
- SRP를 위반한다. 새로운 직원 타입이 추가되어도 임금을 계산하는 함수를 변경해야 한다.
- OCP를 위반한다. 새로운 직원 타입이 추가되면 새로운 임금 계산 로직을 위하 코드를 변경해야 한다.
- 유사한 함수가 계속 파생될 수 있다. 이러한 직원의 타입에 따른 코드는 다른 곳에 중첩될 수 있다.
public abstract class Employee { public abstract int calculatePay(); public abstract void deliverPay(); } public class EmployeeFactory { public Employee makeEmployee(EmployeeRecord r) throws InvalidEmployeeType { switch (r.type) { case COMMISSIONED: return new CommissionedEmployee(r); case HOURLY: return HourlyEmployee(r); case SALARIED: return SalariedEmployee(r); default: throw new InvalidEmployeeType(r.type); } } } // 이를 해결하기 위해 Employee를 추상클래스로 만들고, 직원 유형에 따른 하위 클래스를 선언 // 물론 하위 객체를 생성하기 위한 switch문은 불가피함. 하지만 그래도 유사한 함수마다 분기해주는 것을 // 처리해줄 수 있으며, 위의 문제점 중 상당수를 해결할 수 있을 것임
-
명령과 조회를 분리하라(Command 와 Query 의 분리)
함수는 뭔가를 수행하거나 뭔가를 조회하거나 하나의 역할만을 해야함. 두 개의 역할을 동시에 하면 이상한 함수가 탄생함. 예를 들어 다음과 같이 key값이 존재하는지 확인하고, 존재하지 않으면 데이터를 추가하여 성공하면 true 실패하면 false를 반환하는 함수가 있다고 하자.
public boolean set(String attribute, String value); if(set("username", "Seungmin")) {}
이 함수가 key가 존재하는 경우 overwrite하는지 혹은 존재하지 않을 경우에만 업데이트 하는지 등 자세한 내용을 알 수 없을 것. 그 이유는 위의 함수가 명령과 조회를 한번에 처리하기 때문. 그렇기 때문에 위의 함수를 분리하여 다음와 같이 작성해주는 것이 명확함
public boolean attributeExists(String attribute); public boolean setAttribute(String attribute, String value); if(attributeExists("username")) { setAttribute("username", "Seungmin"); }
-
오류코드보다는 예외를 활용하자
public Status deletePage(Page page) { if(deletePage(page) == E_OK) { if(registry.deleteReference(page.name) == E_OK) { if(configKeys.deleteKey(page.name.makeKey()) == E_OK) { log.info("page deleted"); return E_OK; } else { log.error("config key not deleted"); } } else { log.error("reference not deleted"); } } else { log.error("page not deleted"); } return E_ERROR; }
오류코드를 반환하면 그에 따른 분기가 일어나게 되고, 또 분기가 필요한 경우 중첩되기 마련 → 따라서 각각의 함수에서 예외를 발생시켜 잡아 코드를 간결하게 작성하자
public void deletePage(Page page) { try { deletePageAndAllReferences(page); } catch (Exception e) { log.error(e.getMessage()); } } public void deletePageAndAllReferences(Page page) throws Exception { deletePage(page); registry.deleteReference(page.name); configKeys.deleteKey(page.name.makeKey()); }
-
여러 예외가 발생하는 경우 Wrapper 클래스로 감싸자
외부 라이브러리를 이용하면 다양한 예외 클래스를 마주하게 됨. 그리고 이러한 예외들을 처리하려면 다음과 같이 상당히 번거로워짐
ACMEPort port = new ACMEPort(12); try { port.open(); } catch (DeviceResponseException e) { log.error(e.getMessage()); } catch (ATM1212UnlockedException e) { log.error(e.getMessage()); } catch (GMXError e) { log.error(e.getMessage()); } finally { ... }
이러한 상황에서 Wrapper 클래스를 이용해 감싸면 효율적으로 예외 처리를 할 수 있음
LocalPort port = new LocalPort(12); try { port.open(); } catch (PortDeviceFailure e) { log.error(e.getMessage()); } finally { ... } public class LocalPort { private ACMEPort innerPort; public LocalPort(int portNumber) { this.innerPort = new ACMEPort(portNumber); } public void open() { try { innerPort.open(); } catch (DeviceResponseException e) { throw new PortDeviceFailure(e); } catch (ATM1212UnlockedException e) { throw new PortDeviceFailure(e); } catch (GMXError e) { throw new PortDeviceFailure(e); } } }
-
테스트 코드의 작성
-
클래스의 최소화
클래스 역시 함수와 마찬가지로 간결하게 작성하는 것이 중요. 함수는 물리적 크기를 측정했다면 클래스는 몇개의 역할 또는 책임을 갖는지를 척도로 활용하며, 단일 책임 원칙에 따라 1가지 책임만을 가져야함
-
클래스의 응집도
-
변경하기 쉬운 클래스
요구사항은 수시로 변하기 때문에, 변경하기 쉬운 클래스를 만드는 것이 중요. 변경하기 쉬운 클래스는 기본적으로 단일 책임 원칙을 지켜야함. 또한 구현체 보다는 추상체에 의존하여야하고 결국 핵심은 다형성임
abstract public class SQL { public SQL(String table, Column[] columns) abstract public String generate(); } public class CreateSQL extends SQL { public CreateSQL(String table, Column[] columns) @Override public String generate() } public class SelectSQL extends SQL { public SelectSQL(String table, Column[] columns) @Override public String generate() }
-
설계 품질을 높여주는 4가지 규칙
- 모든 테스트를 실행하라: 테스트가 쉬운 코드를 작성하다 보면 SRP를 준수하고, 더 낮은 결합도를 갖는 설계를 얻을 수 있음
- 중복을 제거하라: 깔끔한 시스템을 만들기 위해 단 몇 줄이라도 중복을 제거해야함
- 프로그래머의 의도를 표현하라: 좋은 이름, 작은 클래스와 메소드의 크기, 표준 명칭, 단위 테스트 작성 등을 통해 이를 달성할 수 있음
- 클래스와 메소드의 수를 최소로 줄여라: 클래스와 메소드를 작게 유지함으로써 시스템 크기 역시 작게 유지할 수 있음
-
디미터 법칙
디미터의 법칙은 어떤 모듈이 호출하는 객체의 속사정을 몰라야 하다는 것. 그렇기에 객체는 자료를 숨기고 함수를 공개해야함. 만약 자료를 그대로 노출하면 내부 구조가 드러나 결합도가 높아짐
final String outputDir = FileManager.getInstance().getOptions().getModule().getAbsolutePath();
이 코드는 지나치게 객체의 속사정에 깊이 관여하고 있음. 따라서 위와 같은 코드를 다음과 같이 나눠야함
Options options = ctxt.getOptions(); File scratchDir = opts.getScratchDir(); final String outputDir = scratchDir.getAbsolutePath();
그리고 만약 위의 클래스들인 자료 구조라면 괜찮지만 객체라면 내부 구조를 숨겨야 하므로 한번 더 수정을 해주어야함. 절대 경로를 얻는 이유는 임시 파일을 생성하기 위함이기에 위의 코드를 다음과 같이 임시 파일을 생성하라는 메세지를 보내는 것이 좋음
BufferedOutputStream bos = ctxt.createScartchFileStream(classFileName);
즉, 데이터가 아닌 객체를 참고할 때 여러 번의 .을 사용하는 경우, 객체에게 메세지를 보내도록 변경하자.