In this Assignment , we will apply the knowledge learned about NLP, specifically NER and CRF, to search and analyze the name of the disease and its treatment method according to the provided data.
- ‘BeHealthy’ has a web platform that allows doctors to list their services and manage patient interactions and provides services for patients such as booking interactions with doctors and ordering medicines online. Here, doctors can easily organise appointments, track past medical records and provide e-prescriptions.
- Example sentences below: __“The patient was a 62-year-old man with squamous cell lung cancer, which was first successfully treated by a combination of radiation therapy and chemotherapy.”__
Suppose you have been given such a data set in which a lot of text is written related to the medical domain. As you can see in the dataset, there are a lot of diseases that can be mentioned in the entire dataset and their related treatments are also mentioned implicitly in the text, which you saw in the aforementioned example that the disease mentioned is cancer and its treatment can be identified as chemotherapy using the sentence.
-
Disease analysis and disease name can be based on the form below.
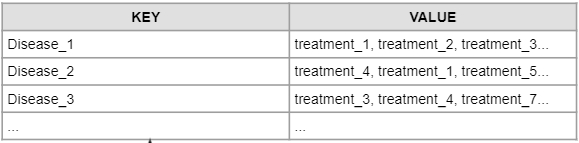
-
Dataset: Provided by the Upgrad educational institution. You can consult and download from this repo.
-
There are three labels that have been used in this dataset: O, D and T, which are corresponding to ‘Other’, ‘Disease’ and ‘Treatment’, respectively.
-
We don't have any more interpretive information about data. You can refer to the code in the Jupyter Notebook file to understand how to handle it

- In this project we use some of the following libraries, you can install it according to the version noted in the requirement.txt file.
Pandas version 1.4.2 Numpy version 1.22.3 spacy version 3.4.3 scikit-learn version 0.23.1
- Our approach is as follows:
- Data preprocessing
- Concept identification
- Defining the features for CRF
- Getting the features words and sentences
- Defining input and target variables
- Building the model
- Evaluating the model
- Identifying the diseases and predicted treatment using a custom NER
- This project was inspired by our group exercise on loan market analysis.
- References on Reference_1. Reference_2. Reference_3.
Created by :
Pham Van Thai: phamthai.ats@gmail.com
Feel free to contact us!
- We do not have any constraints about License on the use of our results. You can use it for free.