pip install muggle-ocr
pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com muggle-ocr
貌似官方仓库已删除
pip install muggle-ocr-1.0.3.tar.gz
pip install ddddocr
未开源,windows下web接口
# muggle_ocr
import muggle_ocr
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
with open(r"test1.png", "rb") as f:
b = f.read()
text = sdk.predict(image_bytes=b)
print(text)
# muggle_ocr
import muggle_ocr
# ModelType.Captcha 可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
with open(r"test1.png", "rb") as f:
b = f.read()
text = sdk.predict(image_bytes=b)
print(text)
# muggle-ocr/ muggle_ocr_flask
import requests
import base64
url = "http://127.0.0.1:5000/muggle_ocr/captcha"
r = requests.post(url,data=base64.b64encode(open('1.png','rb').read()).decode())
print(r.text)
在1.2.0开始,ddddocr的识别部分进行了一次beta更新,主要更新在于网络结构主体的升级,其训练数据并没有发生过多的改变,所以理论上在识别结果上,原先可能识别效果的很好的图形在1.2.0上有一小部分概率会有一定程度的下降,也有可能原本识别不好的图形在1.2.0之后效果却变得特别好。 测试代码:
import ddddocr
ocr = ddddocr.DdddOcr()
with open("test.jpg", 'rb') as f:
image = f.read()
res = ocr.classification(image)
print(res)
通过在初始化ddddocr的时候使用beta参数即可快速切换新模型
import ddddocr
ocr = ddddocr.DdddOcr(beta=True)
with open("test.jpg", 'rb') as f:
image = f.read()
res = ocr.classification(image)
print(res)




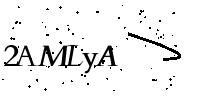




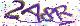

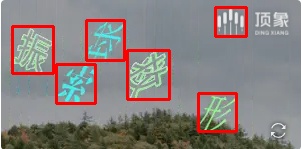
# ddddocr / ocr_api_server
resp = requests.post("http://{host}:{port}/ocr/file", files={'image': image_bytes})
resp = requests.post("http://{host}:{port}/ocr/b64/text", data=base64.b64encode(file).decode())
import os
import requests
import base64
path = 'test/文字验证码'
def xiaridenuanfeng_Tools(file):
length = len(os.path.splitext(os.path.basename(file))[0])
base64_data = base64.b64encode(open(file, 'rb').read()).decode("utf8")
r = requests.get(
f'http://127.0.0.1:8888/aqwj/?code={base64_data}&length={length}')
print(os.path.basename(file), r.text)
for file in os.listdir(path):
full_file = os.path.join(path, file)
xiaridenuanfeng_Tools(full_file)
2a8r.jpeg code:2a8r
2acd.jpeg code:2acd
2amlya.png 识别失败
2bghz.png code:2bghz
6k9d.jpeg code:6k9d
8a62n1.png 识别失败
aabd.jpeg code:aabd
aftf.bmp code:aftf
f2339.png 识别失败
jepy.png code:jepv
小滑块为单独的png图片,背景是透明图,如下图

然后背景为带小滑块坑位的,如下图

det = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
res = det.slide_match(target_bytes, background_bytes)
print(res)
提示:如果小图无过多背景部分,则可以添加simple_target参数, 通常为jpg或者bmp格式的图片
slide = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.jpg', 'rb') as f:
target_bytes = f.read()
with open('background.jpg', 'rb') as f:
background_bytes = f.read()
res = slide.slide_match(target_bytes, background_bytes, simple_target=True)
print(res)
一张图为带坑位的原图,如下图

一张图为原图,如下图

slide = ddddocr.DdddOcr(det=False, ocr=False)
with open('bg.jpg', 'rb') as f:
target_bytes = f.read()
with open('fullpage.jpg', 'rb') as f:
background_bytes = f.read()
img = cv2.imread("bg.jpg")
res = slide.slide_comparison(target_bytes, background_bytes)
print(res)
det = ddddocr.DdddOcr(det=False, ocr=False)
with open('target.png', 'rb') as f:
target_bytes = f.read()
with open('background.png', 'rb') as f:
background_bytes = f.read()
res = det.slide_match(target_bytes, background_bytes)
print(res)
import ddddocr
import cv2
det = ddddocr.DdddOcr(det=True)
with open("test.jpg", 'rb') as f:
image = f.read()
poses = det.detection(image)
print(poses)
im = cv2.imread("test.jpg")
for box in poses:
x1, y1, x2, y2 = box
im = cv2.rectangle(im, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)
cv2.imwrite("result.jpg", im)
举些例子:
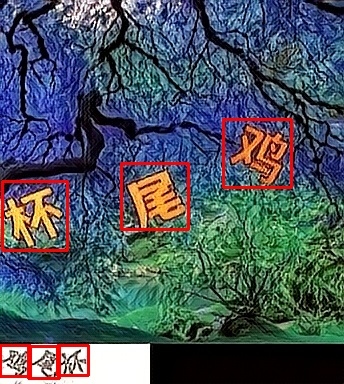








import sys
sys.path.append(".")
import base64
import requests
with open("ocr/文字验证码/8we1.png", 'rb') as f:
image = f.read()
image = base64.b64encode(image)
image = str(image, 'utf8')
data = {
"clientKey":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"task":
{
"type": "ImageToTextTaskTest",
"body": image # base64编码后的图片
}
}
r = requests.post("https://api.yescaptcha.com/createTask", json=data).json()
print(r)
{'errorId': 0, 'errorCode': '', 'status': 'ready', 'solution': {'text': '8we1'}, 'taskId': '1fb204c2-d8d7-11ec-9dc6-8a3e9a7e9eea'}
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别
return result["message"]
return ""
if __name__ == "__main__":
img_path = r"qnzg.png"
result = base64_api(uname='', pwd='', img=img_path, typeid=3)
print(result)