闲来无事简单是写了写,如何在HDFS上执行SQL,不像Hive不需要MySQL支持,只需要简单配置一下需要执行的SQL和日志的格式,同时支持对日志进行正则过滤和提取必要字段。支持JSON格式的日志。
##############
# HDFS
##############
log.hdfs=hdfs://192.168.1.32:9000
##############
# SQL
##############
# 简单查询
log.sql1=create /sql/out1 as select * from s order by id desc
# 简单查询
log.sql2=create /sql/out2 as select id,name,grade from s where id>10 order by grade desc limit 0,10
# 查询最高的成绩
log.sql3=create /sql/out3 as select max(grade) as grade from s
# 表连接
log.sql4=create /sql/out4 as select s.id,s.name,s.grade,t.id,t.name from s join t on s.tid=t.id limit 0,10
# 分组查询
log.sql5=create /sql/out5 as select s.tid,count(s.id) as s.count from s group by s.tid
# 表连接分组查询
log.sql6=create /sql/out6 as select t.name,count(t.id) as t.count from s join t on s.tid=t.id group by t.id,t.name order by t.count desc limit 0,5
# log chain
log.chain=sql1,sql2,sql3,sql4,sql5,sql6
##############
# VAR
##############
# log table
log.table.t=/sql/teacher.txt:id|name:#split:#filter
log.table.s=/sql/student.txt:id|name|grade|tid:#split:#filter
# split
log.split=|
# log filter
log.filter=(^[^#].*)# 执行命令
hadoop jar sql.jar com.engine.MrEngine /log/chain.conf
# 简单查询
select * from s order by id desc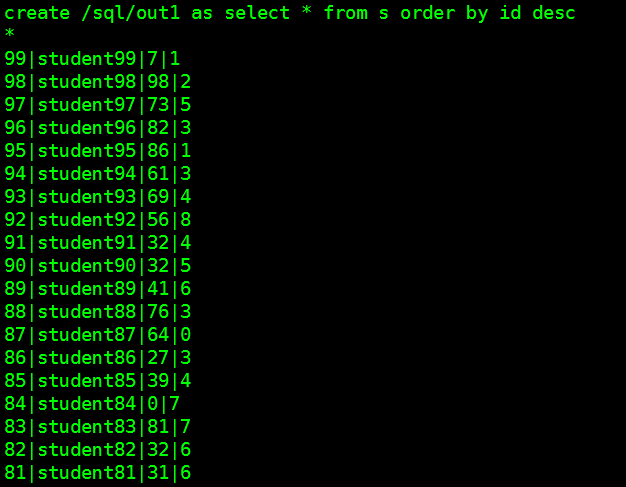
# 简单查询
select id,name,grade from s where id>10 order by grade desc limit 0,10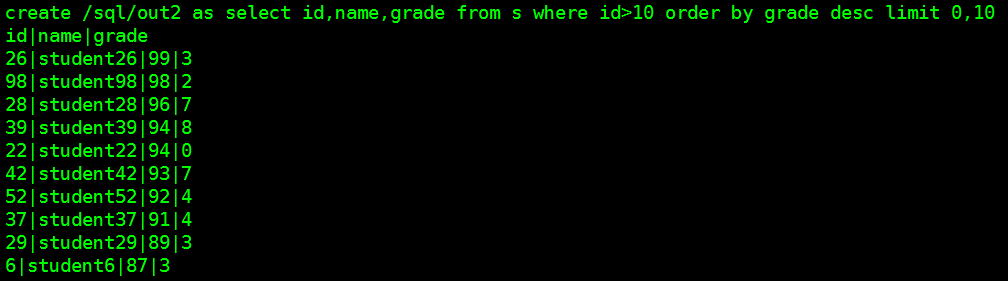
# 查询最高的成绩
select max(grade) as grade from s
# 表连接
select s.id,s.name,s.grade,t.id,t.name from s join t on s.tid=t.id limit 0,10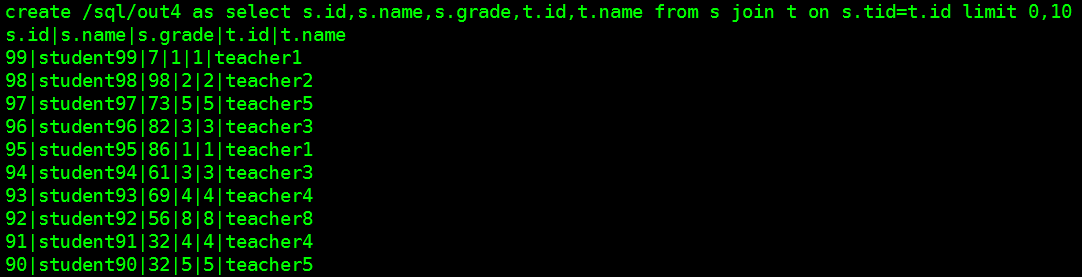
# 分组查询
select s.tid,count(s.id) as s.count from s group by s.tid 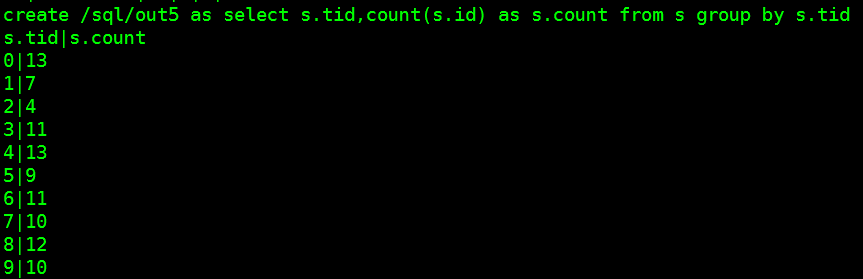
# 表连接分组查询
select t.name,count(t.id) as t.count from s join t on s.tid=t.id group by t.id,t.name order by t.count desc limit 0,5