
- ckpt:微调、初始模型目录
- datasets:数据读取模块
- deployment:模型设备配置
- Images:数据集
- nets:训练模型
- preprocessing:预处理模块
- test:测试目录
- utils:训练公用组件
- command.bat:windows下的训练命令

read_dataset:保存不同数据集(pascalvoc2007,vehicle)TFRecords的读取功能dataset_factory:数据工厂模块路由,找到不同的数据集(vehicle,pascalvoc_2007)读取逻辑utils:数据模块的公用组件dataset_to_tfrecords:将数据集转换成tfrecorddataset_config:数据模块一些数据集的配置文件
数据模块最终要的是TFRecords的读取逻辑,需要对不同的数据集进行处理(pascalvoc2006、vehicle)。类的设计如下:

建立一个基类,TFRecordsReaderBase类(该基类在utils/dataset_utils.py中定义)
PascalvocTFrecords(read_dataset/pascalvoc2007.py)和VehicleTFRecords(read_dataset/vehicle.py)继承数据读取基类,实现属性(param)和方法(get_data())细节。

-
ssd_vgg_300:SSD的网络模块 -
utils:SSD网络用到的公用组件 -
nets_factory:可以根据需要选择不同网络模型如果想要添加更多的模型,可以找到相关模型代码放入
nets_model文件当中,并在nets_factory中进行配置
由于网络用到的基础代码组件较多,项目多个模块都会用到basic_tools中的函数。在根目录建立一个utils目录放入basic_tools。

预处理模块结构如下图:

其中processing目录下为SSD模型对应的预处理源码,utils中为源码所需要的一些公用组件函数,preprocessing_factory.py用来获取相应模型的预处理。
目的:
-
在图像的深度学习中,对输入数据进行数据增强(Data Augmentation),为了丰富图像训练集,更好的提取图像特征,泛化模型(防止模型过拟合)
-
还有一个最根本的目的就是要把图片变成符合大小要求
- YOLO算法:输入图片大小变换为448 x 448
- SSD算法:输入图片大小变换为300 x 300
指通过剪切、旋转/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。
为什么要进行数据增强?

假设数据集中有两个类(福特、雪佛兰),其中福特汽车大多数车头朝左,雪佛兰汽车大多数车头朝右。
模型完成训练后,输入下面的图像(福特),神经网络会认为是雪佛兰!

为什么会发生这种现象? 因为算法可能会寻找区分一个类和另一个类的最明显特征。在这个例子中,这个特征就是福特汽车朝向左边,雪佛兰汽车朝向右边。神经网络的好坏取决于输入的数据。
怎么解决这个问题?
需要减少数据集中不相关特征的数量。对上面的汽车类型分类器来说,只需要将现有数据集中的照片水平翻转,使汽车朝向另一侧。现在,用新的数据集训练神经网络,通过增强数据集,可以防止神经网络学习到不相关的模式,提升效果。(在没有采集更多的图片前提下)
在机器学习过程中的什么位置进行数据增强?
在向模型输入数据之前增强数据集。
-
离线增强。预先进行所有必要的变换,从根本上增加数据集的规模(例如,翻转所有图像并将其保存到磁盘,这样数据集数量会增加2倍)。
-
在线增强,或称为动态增强。可通过对即将输入模型的小批量数据执行相应的变换,这样同一张图片每次训练时被随机执行图像变换,相当于增加了数据集。
该项目也是进行这种在线增强
- 翻转
tf.image.random_flip_left_right
水平或垂直翻转图像。一些架构并不支持垂直翻转图像。但垂直翻转等价于将图片旋转$180 ^0$再水平翻转。下面就是图像翻转的例子。

- 旋转 rotate

- 裁剪 random_crop
随机从原始图像中采样一部分,然后将这部分图像调整为原始图像大小。

- 平移、缩放等方法



TensorFlow 官方源码都是基于 vgg与inception论文的图像增强,全部通过tf.image相关API来预处理图像。TensorFlow 官网也提供了一些模型的预处理(数据增强)过程。
网址:
https://github.com/tensorflow/models/tree/master/research/slim/preprocessing
在ssd_vgg_preprocessing.py文件中,有两个过程(训练和测试)的预处理函数,通过preprocess_image函数获取
preprocess_image(image,labels,bboxes,out_shape,data_format,is_training=False,**kwargs):
1、训练过程中,对图像进行了一些随机性的变换
preprocess_for_train(image, labels, bboxes,out_shape, data_format='NHWC',scope='ssd_preprocessing_train')
- image:一张RGB图片
- labels:shape为(N, ),N为图片中 Ground Truth 物体数量,记录所有物体类型的数字编号
- bboxes:GT, shape为(N, 4),其中数据分别是[ymin, xmin, ymax, xmax],数值范围都在(0, 1]之间
- out_shape:(height, width),图片输出的形状根据模型要求大小指定
- return:
变化后的image
标签(labels)
变化后的bboxes
2、测试过程
preprocess_for_eval(image, labels, bboxes,out_shape=EVAL_SIZE, data_format='NHWC', resize=Resize.WARP_RESIZE)
- image:一张RGB图片
- labels:shape为(N, ),N为图片中 Ground Truth 物体数量,记录所有物体类型的数字编号
- bboxes:GT, shape为(N, 4),其中数据分别是[ymin, xmin, ymax, xmax],数值范围都在(0, 1]之间
- out_shape:EVAL_SIZE=(300, 300),SSD固定的要求
- resize=Resize.WARP_RESIZE
- return:
处理后的image
标签(labels)
处理后的bboxes
bbox_img:[0, 0, 1, 1],做后续的NMS以及score过滤使用


model_deploy位于TensorFlow slim模块的deployment目录下,可以使得用多个 GPU / CPU在同一台机器或多台机器上执行同步或异步训练变得更简单。
官方网址:
https://github.com/tensorflow/models/blob/master/research/slim/deployment/model_deploy.py
术语解释:
- replica: 使用多机训练时, 一台机器对应一个replica
- clone: tensorflow里多GPU训练是每个GPU上都有完整的模型,各自进行前向传播计算,得到的梯度交给CPU平均然后统一反向传播计算,每个GPU上的模型叫做一个clone。
- parameter server: 多机训练时计算梯度平均值并执行反向传播操作的参数服务器,功能类比于单机多GPU(也叫单机多卡)时的CPU。(未考证, TODO)
- worker server:一般指的是单机多卡中的GPU,用于训练
class DeploymentConfig(object):
配置参数:
num_clones=1:每一个计算设备上的模型克隆数(每台计算机的GPU/CPU总数)clone_on_cpu=False:如果为True,将只在CPU上训练replica_id=0:指定某个计算机去部署,默认第0台计算机(TensorFlow会给个默认编号)num_replicas=1:多少台可用计算机num_ps_tasks=0:用于参数服务器的计算机数量,0为不使用计算机作为参数服务器worker_job_name='worker':工作服务器名称ps_job_name='ps':参数服务器名称
方法:
config.variables_device()
作为tf.device(func)的参数,返回使用变量的设备
一般用于指定全局步数变量的设备,默认运行计算机的"/device:CPU:0"config.inputs_device()
作为tf.device(func)的参数,指定输入数据所使用的设备。
默认运行计算机的"/device:CPU:0"config.optimizer_device()
作为tf.device(func)的参数,返回学习率、优化器所在的设备。
默认运行计算机的"/device:CPU:0"config.clone_scope(self, clone_index)
返回指定编号的设备命名空间
按照这样编号,clone_0,clone_1...
-
model_deploy.create_clones(config, model_fn, args=None, kwargs=None):
作用:每个clone创建一个复制的模型- config:一个DeploymentConfig的配置对象
- model_fn:用于回调的函数model_fn,
- args=None, kwargs=None:回调函数model_fn的参数
返回元组
Clone(outputs, scope, device)组成的列表,列表大小为指定的num_clones数量- outputs:网络模型的每一层节点
- scope: 第i个GPU设备的命名空间,config.clone_scope(i)
- clone_device:第i个GPU设备
-
model_deploy.optimize_clones(clones, optimizer,regularization_losses=None, **kwargs):
作用:计算所有给定的clones的总损失以及每个需要优化的变量的总梯度- clones: 元组列表,每个元素Clone(outputs, scope, device)
- optimizer:选择的优化器
- **kwargs:可选参数,优化器优化的变量
返回:
- total_loss:总损失
- grads_and_vars:每个需要优化变量的总梯度组成的列表

utils当中的train_tools.py为训练所用到的一些API函数、组件。train_tools当中将要用到API的如下:
- train_tools.reshape_list:将嵌套列表展开为单列表
- train_tools.deploy_loss_summary:为GPU复制模型参数,并添加损失以及模型变量到TensorBoard(第一个设备的模型观察损失、观察变量)
- train_tools.configure_learning_rate:配置学习率
- train_tools.configure_optimizer:配置优化器
- train_tools.get_trainop:所有GPU/CPU设备计算总损失、每个变量的梯度和
- train_tools.get_init_fn:训练时初始化训练参数
- DeploymentConfig 在训练之前配置相应的设备信息(是用GPU训练还是CPU训练,是用多个GPU训练还是单个GPU训练,是用多台计算机训练还是一台计算机训练)
- 生成一个模型实例
- 定义全局步长
- 获取图片队列数据
- 数据输入、网络计算结果、定义损失并复制模型到clones, 添加变量到Tensorboard
- 定义学习率、优化器
- 定义会话
需要在训练之前配置相应的设备信息
deploy_config = model_deploy.DeploymentConfig(
num_clones=FLAGS.num_clones, # GPU设备数量
clone_on_cpu=FLAGS.clone_on_cpu,
replica_id=0,
num_replicas=1, # 1台计算机
num_ps_tasks=0
)
用到的参数
# 设备的命令行参数配置
tf.app.flags.DEFINE_integer('num_clones', 1, "可用设备的GPU数量")
tf.app.flags.DEFINE_boolean('clone_on_cpu', False, "是否只在CPU上运")
生成一个SSD网络实例
#get_network()返回一个类
ssd_class = nets_factory.get_network(FLAGS.model_name)
# 获取默认网络参数
ssd_params = ssd_class.default_params._replace(num_classes=3)
# 初始化网络
#生成一个模型实例
ssd_net = ssd_class(ssd_params)
SSDNet含有默认default_params参数,可以作为网络init初始化的参数。
用到的参数
tf.app.flags.DEFINE_string(
'model_name', 'ssd_300_vgg', '用于训练的网络模型名称')
# 定义一个全局步长参数(网络训练都会这么去进行配置)
# 使用指定设备 tf.device
with tf.device(deploy_config.variables_device()):
global_step = tf.train.create_global_step()
1、获取样本(和默认框default anchors)
在config.inputs_device()指定的设备下进行
(1)数据工厂返回数据规范信息
#通过数据工厂取出规范信息
dataset = dataset_factory.get_dataset(FLAGS.dataset_name, FLAGS.train_or_test, FLAGS.dataset_dir)
用到的参数
tf.app.flags.DEFINE_string(
'dataset_name', 'vehicle', '要加载的数据集名称')
tf.app.flags.DEFINE_string(
'train_or_test', 'train', '指定训练集还是测试集')
tf.app.flags.DEFINE_string(
'dataset_dir', None, 'TFRecords文件的目录')
(2)获取每一层计算出来的默认框deafault anchors(用于与GT样本标记)
#获取网络计算的anchors结果
# 获取形状,用于输入到anchors函数参数当中
ssd_shape = ssd_net.params.img_shape
# 计算出SSD每一层(共六层)的默认框
ssd_anchors = ssd_net.anchors(ssd_shape)
(3)利用train_tools打印网络参数
train_tools.print_configuration(ssd_params, dataset.data_sources)
(4)通过deploy_config.inputs_device()指定输入数据的设备
指定设备上下文环境以及作用域上下文环境
with tf.device(deploy_config.inputs_device()):
with tf.name_scope(FLAGS.dataset_name + '_data_provider'):
(5)slim.dataset_data_provider.DatasetDataProvider通过get方法获取数据
provider = slim.dataset_data_provider.DatasetDataProvider(
dataset,
num_readers=4,
common_queue_capacity=20 * FLAGS.batch_size,
common_queue_min=10 * FLAGS.batch_size,
shuffle=True)
[image, shape, glabels, gbboxes] = provider.get(['image', 'shape',
'object/label',
'object/bbox'])
用到的参数
tf.app.flags.DEFINE_integer(
'batch_size', 32, '每批次训练样本数')
2、数据预处理
(1)获取预处理工厂函数,并进行数据增强
image_preprocessing_fn = preprocessing_factory.get_preprocessing(FLAGS.model_name, is_training=True) # 获取预处理函数
#该函数返回变换后的image,标签和变换后的bboxes
image, glabels, gbboxes = image_preprocessing_fn(image, glabels, gbboxes,
out_shape=ssd_shape,
data_format=DATA_FORMAT)
(2)对获取出来的groundtruth labels 和 bboxes进行编码
对Default boxes进行正负样本标记通过Ground Truth计算IoU:使 Ground Truth 数量与预测结果一一对应
# 8732 anchor, 得到8732个与GT 对应的标记的anchor
# gclasses:目标类别
# glocalisations:目标的位置
# gscores:是正还是负样本
gclasses, glocalisations, gscores = ssd_net.bboxes_encode(glabels, gbboxes, ssd_anchors)
3、将样本组成一个batch并放入队列
使用tf.train.batch和slim.prefetch_queue.prefetch_queue分别进行批处理并放入队列。
tf.train.batch(tensor_list, batch_size, num_threads, capacity)
batch_queue = slim.prefetch_queue.prefetch_queue(tensor_list, capacity=capacity)
# tensor_list:tensor组成的单列表 [tensor, tensor, tensor]
# [Tensor, [6], [6], [6]] 嵌套的列表要转换成单列表形式
r = tf.train.batch(train_tools.reshape_list([image, gclasses, glocalisations, gscores]),
batch_size=FLAGS.batch_size,
num_threads=4,
capacity=5 * FLAGS.batch_size)
# r应该是一个19个Tensor组成的一个列表
# 将batch放入队列
# 1个r:批处理的样本, 5个设备,5个r, 5组32张图片
# 队列的目的是为了不同设备需求
batch_queue = slim.prefetch_queue.prefetch_queue(r,
capacity=deploy_config.num_clones)
update_ops, first_clone_scope, clones = train_tools.deploy_loss_summary(deploy_config,batch_queue,ssd_net,summaries,batch_shape,FLAGS)
参数:
- deploy_config:训练设备
- batch_queue:数据队列
- ssd_net:模型
- summaries:TensorBoard观察的变量
- batch_shape:队列的Tensor元素数量(数据队列的大小)
- FLAGS:参数
return:
- update_ops:默认第一个clone的变量操作结合
- first_clone_scope:第一个clone的名字
- clones:所有clone组成的列表(outputs, clone_scope, clone_device)

在config.optimizer_device()下指定学习率以及优化器并添加学习率到TensorBoard
learning_rate = tf_utils.configure_learning_rate(FLAGS, num_samples, global_step)- FLAGS:学习率设置相关参数
- global_step:全局步数
optimizer = tf_utils.configure_optimizer(FLAGS, learning_rate)- learning_rate:学习率
用到的参数:
tf.app.flags.DEFINE_string(
'optimizer', 'rmsprop', '优化器种类 可选"adadelta", "adagrad", "adam","ftrl", "momentum", "sgd" or "rmsprop".')
tf.app.flags.DEFINE_string(
'learning_rate_decay_type', 'exponential','学习率迭代种类 "fixed", "exponential", "polynomial"')
tf.app.flags.DEFINE_float(
'learning_rate', 0.01, '模型初始学习率')
tf.app.flags.DEFINE_float(
'end_learning_rate', 0.0001, '模型训练迭代后的终止学习率')
slim.learning.train(
train_op, # 梯度更新操作
logdir=FLAGS.train_model_dir, # 模型存储目录
master='',
is_chief=True,
init_fn=train_tools.get_init_fn(FLAGS), # 初始化参数的逻辑,预训练模型的读取和微调模型判断
summary_op=summaries_op, # 观察的变量
number_of_steps=FLAGS.max_number_of_steps, # 最大步数
log_every_n_steps=10, # 打印频率
save_summaries_secs=60, # 保存摘要频率
saver=saver, # 保存模型参数
save_interval_secs=600, # 保存模型间隔
session_config=config, # 会话参数配置
sync_optimizer=None)
使用slim.learning.train定义会话完成训练,slim的其他参数可参考下面,其中有一个init_fn参数,这个参数是需要我们提供读取预训练参数还是微调之后的参数作为初始化 ,train_tools.get_init_fn(FLAGS)进行了封装。
参数:
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(log_device_placement=False, # 打印每个变量所在的设备信息
gpu_options=gpu_options)
tf.GPUOptions:per_process_gpu_memory_fraction配置tensorflow使用多大的显存, 可以通过下面的方式,来设置GPU使用的显存大小。
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8) #使用80%的显存allow_growth=True:按需分配
- ConfigProto中log_device_placement是否打印每个变量所在的设备信息
tf.app.flags.DEFINE_integer(
'max_number_of_steps', None, '训练的最大步数')
tf.app.flags.DEFINE_string(
'train_model_dir', ' ', '训练输出的模型目录')
# pre-trained模型路径.
tf.app.flags.DEFINE_string(
'pre_trained_model', None, '用于fine-tune的已训练好的基础参数文件位置')
PRE_TRAINED_PATH=.\ckpt\pre_trained\ssd_300_vgg.ckpt #预训练模型
TRAIN_MODEL_DIR=.\ckpt\fine_tuning\ #训练模型目录
DATASET_DIR=.\Images\tfrecords\ #训练数据集
python train_ssd_network.py --train_model_dir=${TRAIN_MODEL_DIR} --dataset_dir=${DATASET_DIR} —dataset_name="commodity_2018" --train_or_test=train --model_name=ssd_vgg_300 --pre_trained_path=${PRE_TRAINED_PATH} --weight_decay=0.0005 --optimizer=adam --learning_rate=0.001 --batch_size=2
保存模型文件夹:



- 定义输入数据占位符
- preprocess(数据预处理:将测试图片resize成模型指定大小)
- 模型预测
- 定义会话,得到模型预测结果
- postprocess(预测结果后期处理)
- 通过score筛选bbox
- 调整超出图片的bbox
- 使用nms去除冗余检测
- 预测结果显示(matplotlib)
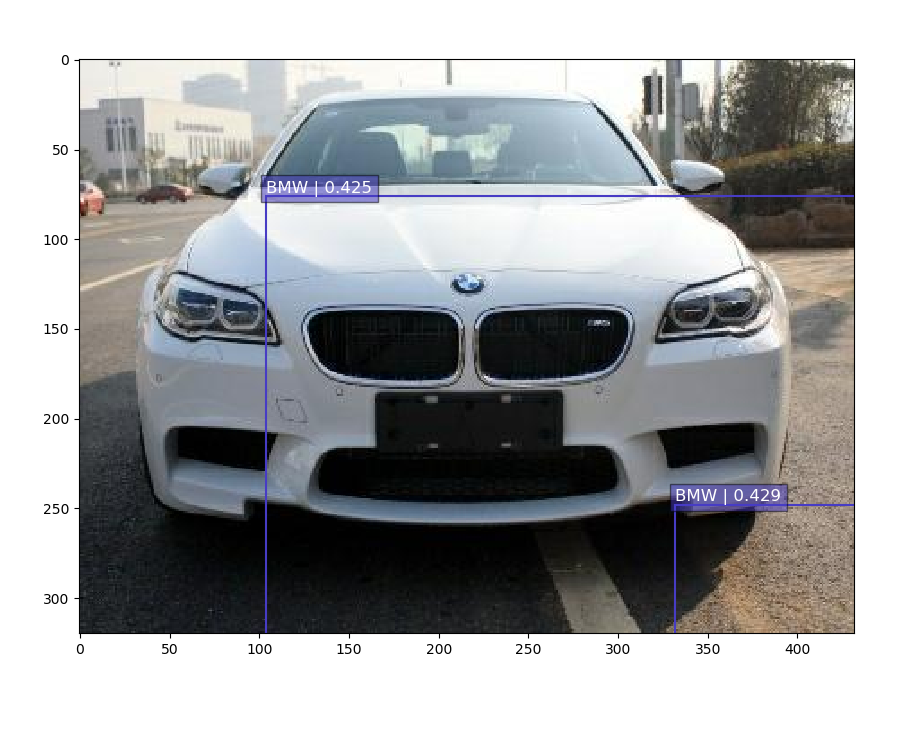


python detector.py --ckpt_path=..\ckpt\fine_tuning\model.ckpt-0 --image_path=test_img\2.jpg

导出模型需要用到TensorFlow的SavedModelBuilder模块。使用简介如下
# 建立builder
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
# 建立元图格式,写入文件
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'detected_model':
prediction_signature,
},
main_op=tf.tables_initializer(),
strip_default_attrs=True)
# 保存
builder.save()
- SavedModelBuilder()
- export_path 是导出目录的路径。如果目录不存在,将创建该目录。
- FLAGS.model_version指定模型的版本,一般以数字的字符串类型指定,如1,2,3
- SavedModelBuilder.add_meta_graph_and_variables():将元图和变量添加到构建器
-
sess:TensorFlow会话
-
tags: 保存元图的标记集,默认使用tf.saved_model.tag_constants.SERVING,参考该文件:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/tag_constants.py
-
signature_def_map:指定一个tensorflow::SignatureDef的签名映射,是一套协议,能够提供给TensorFlow ServingAPI使用
- 键:可以取自定义别名
- prediction_signature = tf.saved_model.signature_def_utils.build_signature_def()
- inputs={'images': tensor_info_x} 指定输入
- outputs={'scores': tensor_info_y} 指定输出
使用 tf.saved_model.utils.build_tensor_info(tensor) - method_name:参考:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/saved_model/signature_constants.py
使用tf.saved_model.signature_constants.PREDICT_METHOD_NAME
-
strip_default_attrs:True,保证向前兼容
-
- SSD的输入、输出
img_input = tf.placeholder(tf.float32, shape=(300, 300, 3))predictions, localisations, _, _ = ssd_net.net(img_4d, is_training=False)
- 加载最新的ckpt
- 建立
builder=tf.saved_model.builder.SavedModelBuilder(export_path) - 添加元图和变量
builder.add_meta_graph_and_variables()
安装:
docker pull tensorflow/serving
使用Docker运行容器并开启Serving服务:
docker_run.bat