
时间复杂度:估计算法的运行时间
时间复杂度大小:O(1) 常数阶 < O(log n) 对数阶 < O(n) 线性阶 < O(n^2) 平方阶
递归的时间复杂度=递归的次数*每次递归中的操作次数
1 什么是大O?
算法最坏情况下的运行时间(算法导论给出的解释)
2 O(n^2)的算法为什么有时候比O(n)的算法更优?
因为算法的时间复杂度省略了常数项,
O(n^2)与O(100n),在n小于100时,O(n^2)比O(100n)更好
3 为什么时间复杂度为什么可以忽略常数项?
因为大O描述的是数据量非常大的时候所表现出的时间复杂度,这个数据量下,常数项已经不起作用了
4 通过求x的n次方了解时间复杂度
时间复杂度为O(n)
int func(int x, int n)
{
int res=1;
for(int i=0; i<n; ++i)
{
res = res *x
}
return res;
}
时间复杂度为O(log(n))
int func(int x, int n)
{
if(n=0)
{
return 1;
}
int res = func(x, n/2);
if(n%2==1)
{
return res*res*x;
}
return res*res;
}
版本1
int fibonacci(int n)
{
if(n<=0)
{
return 0;
}
if(n==1)
{
return 1;
}
return fibonacci(n-1)+fibonacci(n-2);
}
版本2
int fibonacci(int first, int second, int n)
{
if(n <= 0)
{
return 0;
}
if(n<3)
{
return 1;
}
else if(n==3)
{
return first+second;
}
return fibonacci(second, first+second, n-1);
}
同样是递归算法,版本1的时间复杂度为O(2^n),版本2的时间复杂度为O(n)
int binary_search(int arr[], int l, int r, int x)
{
if(l<=r)
{
int mid = l + (r-l)/2;
if(x == arr[mid])
{
return mid;
}
else if(x < arr[mid])
{
return binary_search(arr, l, mid-1, x);
}
else
{
return binary_search(arr, mid+1, r, x);
}
}
return -1;
}

固定部分,不会随着代码的运行产生变化;可变部分,随着代码的运行是可变的。
栈区的数据在代码块结束后,系统会自动回收,而堆区的数据需要手动回收,这是造成内存泄漏的发源地。

32位是寻址空间的大小,所以指针是4字节
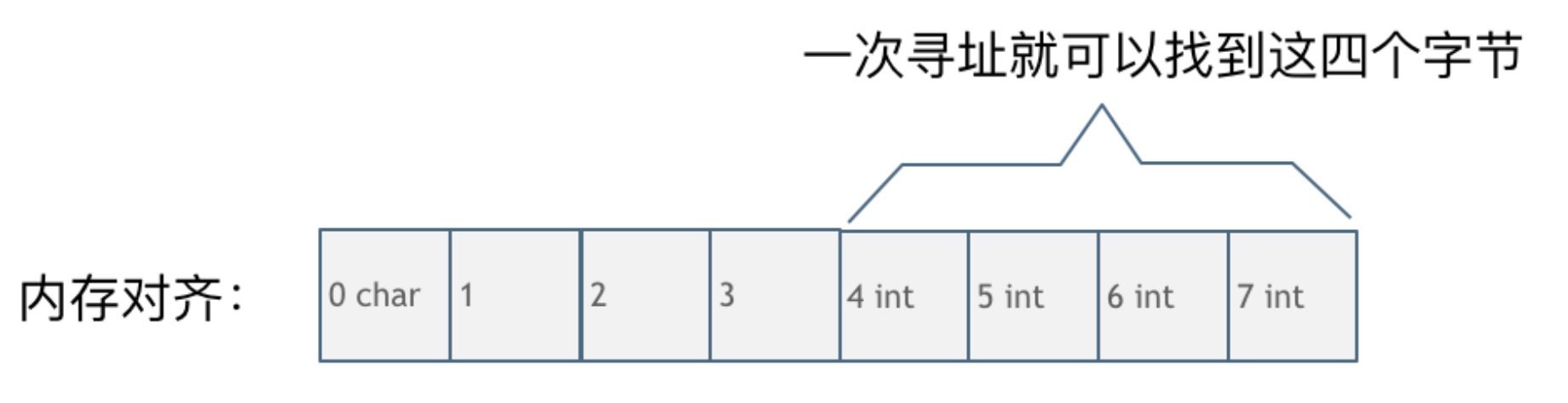
因为CPU读取内存不是一次读取单个字节,而是一次读取一块内存,块的大小可以是4字节,也可以是8字节。如果不做内存对齐,比如char和int在内存中紧挨着,那么可能有多次寻址才能找到int数据,有了内存对齐,只要一次寻址就可以找到int数据。
内存对齐:将一个数据所占内存的大小对齐到块的大小
- 内存对齐
- 没有内存对齐
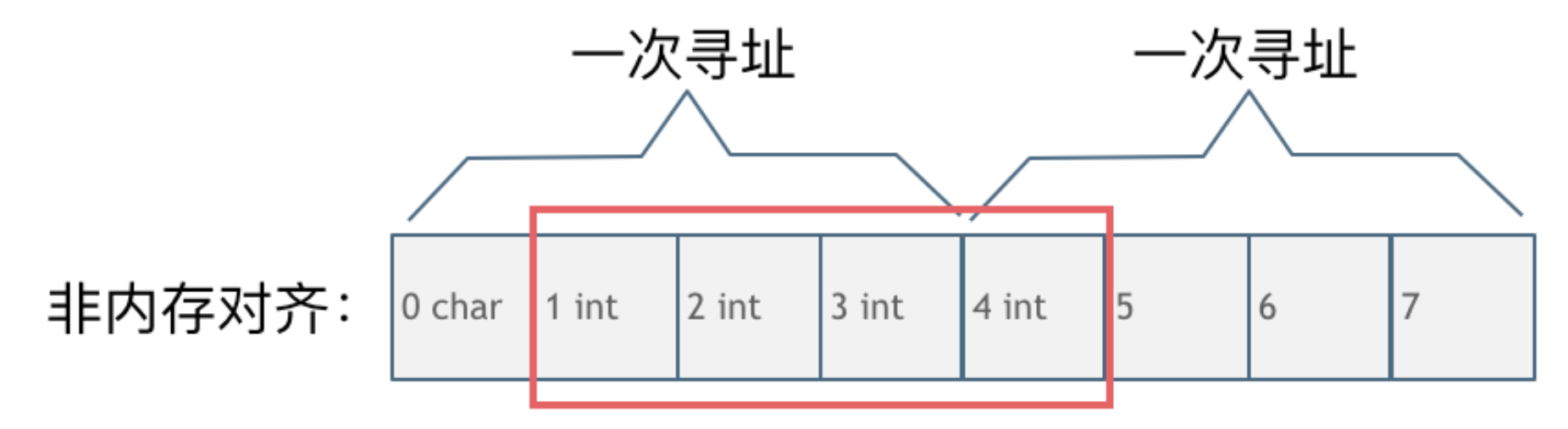
CPU读取int数据要有几步操作:- 因为CPU按块读取内存,所以先读取0 1 2 3这一块的数据
- 再读取4 5 6 7
- 合并1 2 3 4这4个字节的数据才是本次要读取的int数据

