Zinc Search Console > Results table pane > only 20 records can be displayed as a maximum
luigidid opened this issue · comments

Hello, in the meantime, thank you for the constantly evolving product. Very useful for my projects. One question though: from version 0.1.3 onwards, I don't understand how to enable the limitation of 20 "records" on the "ZincSearch" web application. Thank you. I only ever see 20 records.

Duplicate of #19

Same explanation as #19 (comment)
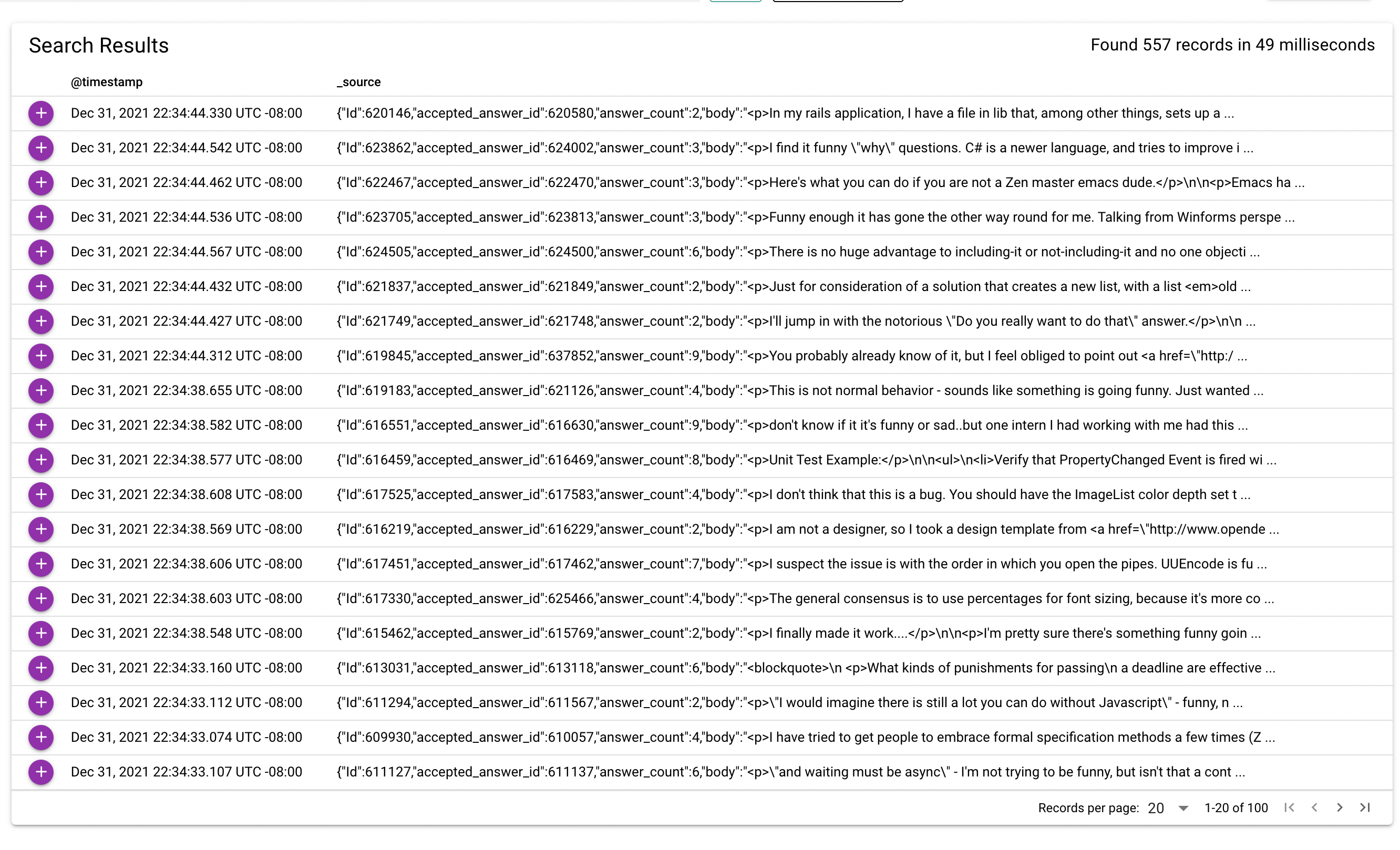
@luigidid Does this explanation help you move forward. Once you search for a term if there are more than 20 records you can go to the next page by using controls at the bottom right hand side of the table.
Same explanation as #19 (comment)
@luigidid Does this explanation help you move forward. Once you search for a term if there are more than 20 records you can go to the next page by using controls at the bottom right hand side of the table.
Hi, on the 0.1.3 version that I have recently installed, it does not return me anymore, as in the previous version, maximum 1000 records. The problem is on the "Zinc Console" WEB interface, in the "Search Results" panel. However, I need to be able to view the total of the records (see example in the image below). I know instead that in the rest call you have implemented pagination search. Very useful, as the deletion of single documents and entire indexes is very useful.

@prabhatsharma ok, thanks a lot. I saw the change made in the appropriate thread: 2e62092
It seems to me a good and flexible solution for now. In any case, I look forward to being able to download the new version of the SW and I will give you some feedback. I anticipate that I am currently using the simple binary running on a Virtual Machine with S.O RedHat 6.x. Thanks again.
@prabhatsharma Hi, when i will can see and download the new version of binary file of Zinc, that will contain the search through 'max_row' parameter? Thanks a lot for the work that you be conducted. Bye! reference: 2e62092
@luigidid I should be able to make a release sometime this week.
@luigidid I should be able to make a release sometime this week.
Thank's a lot @prabhatsharma . I am using the product with a lot of enthusiasm. ;)
@luigidid Changes are in. Can you please check the latest release - https://github.com/prabhatsharma/zinc/releases/tag/v0.1.4 , https://gallery.ecr.aws/prabhat/zinc
@luigidid Changes are in. Can you please check the latest release - https://github.com/prabhatsharma/zinc/releases/tag/v0.1.4 , https://gallery.ecr.aws/prabhat/zinc
Hi @prabhatsharma , Thank you! i will install the binary and give you feedback.
One question. I didn't understand the Zinc process how much RAM it consumes. Does the data remain completely on the file system or is it copied to RAM memory? From what I understand the searches are performed on the Index files residing on the File System. Bye!
It is memory mapped.
It is memory mapped.
Hi. thanks.
The problem is that in my opinion, however, it consumes too much RAM. Example: I have seen that for a few Kilobyes that are inserted in a .json (bulk ingestion), i find MegaBytes consumed proportional in RAM memory. Example: 10 Kylobytes of a single .json, become 100 Mbytes in ram +/-.

In conclusion, it does not seem to me an optimal RAM management by Bluge. Is it possible to verify this high resource usage?
In addition, at each RUN Ingestion, I had to schedule continuous restarts of the zinc process to limit RAM usage. If I don't do the restart, all the memory is saturated.
Bye
It's a known problem that I am working on. What is your batch size?
It's a known problem that I am working on. What is your batch size?

usually below 100 records, for a field layout:

Workload closed by days:

@luigidid Is it possible for you to join the slack channel at https://join.slack.com/t/zinc-nvh4832/shared_invite/zt-11r96hv2b-UwxUILuSJ1duzl_6mhJwVg . I would love to understand more on how you are using zinc the specific problems that you are facing and what is the best solution to them.
Check the latest release https://github.com/prabhatsharma/zinc/releases/tag/v0.1.5 . It has implementation to reduce memory usage by huge margin.
Check the latest release https://github.com/prabhatsharma/zinc/releases/tag/v0.1.5 . It has implementation to reduce memory usage by huge margin.
Hi, thanks for the change. I have installed the new Zinc (0.1.5) - [ process are launched in background on linux RHEL6 ]:

and disabled the restart after each "bulk ingestion" run.
I confirm that now the RAM usage has actually been optimized. As already said, for my prokect, I collect a ".json" file with a maximum of 500 records in each run:

I take this opportunity to request the introduction in WEB-UI of a progress bar or circle bar to alert the user of the research in progress. Also I noticed that the ">" filter in the search bar does not produce the expected results.
If I have a string field, can I use the '>' operator in the "search" field?
TNX! bye
This change in UI should help. @luigidid @safeie . Check "Max records to return" field. Let me know what you think. I will push it in the next release.
It is in this commit - 2e62092
Hi @prabhatsharma , testing the search in the UI, I saw that if I insert the value of 70,000 in the new inputbox and, in the index in which I am searching, the total records is 65,000 c.ca, I see that the search limits the result to a maximum of 10,000. Can it be solved? I would like to see all 70,000 even with difficulty for browser RAM limit reasons. Thank you!
Example:

you can set an env MAX_RESULTS=100000 to change to default limit 10000
you can set an env
MAX_RESULTS=100000to change to default limit10000
how can I do? how do I and when can I set that environment variable? thank you.
if you run zinc as container, you can set environment by command -e MAX_RESULTS=100000, or in k8s you can set environment like this:
env:
- name: MAX_RESULTS
value: 1000000
or you just run as a system command, you can start zinc like this:
MAX_RESULTS=10000 ./zinc
tell me if it can help you, or you can tell me what method you run zinc.
if you run zinc as container, you can set environment by command
-e MAX_RESULTS=100000, or in k8s you can set environment like this:env: - name: MAX_RESULTS value: 1000000or you just run as a system command, you can start zinc like this:
MAX_RESULTS=10000 ./zinctell me if it can help you, or you can tell me what method you run zinc.
Perfect! I use Zinc in linux RHEL 6.x, as a stand-alone "job" process and, in the background.
Ok, I have restart it by passing the env variable at the start of the process. Problem solved! ;) TNX!

Test OK:

Hi @prabhatsharma , since I installed the latest version of the SW, the empty @timestamp field appears in the index. Could you please check? Thank you.

here the content of json bulk example:
{ "index" : { "_index" : "collectionTimeResponse28012022" } } { "DATA": "2022/01/28", "ORA": "16:04:12", "METHOD_NAME": "XXXXXXXXXXXX", "SESSION": "CEDFF2147AD57DEEC5494E981AD6159C", "ESITO": "OK", "A2A": "XXXXXXXXXXXX", "RESPONSE_TIME": "0.711", "ERROR": "--", "IP_CLIENT": "XXXXXXXXXXXX, XXXXXXXXXXXX", "NODE": "NODE02" } { "index" : { "_index" : "collectionTimeResponse28012022" } } { "DATA": "2022/01/28", "ORA": "16:04:15", "METHOD_NAME": "XXXXXXXXXXXX", "SESSION": "B718AA4AA2D6210830E79CFA77258AB1", "ESITO": "OK", "A2A": "XXXXXXXXXXXX", "RESPONSE_TIME": "0.961", "ERROR": "--", "IP_CLIENT": "XXXXXXXXXXXXX, XXXXXXXXXXXX", "NODE": "NODE02" }
..and the index layout is this:

before installing the latest version, the layout of the index was:


I raised an issue in Bluge to use another roaring golang implementation. It increases perf by about 30% and reduces memory pressure by about the same amount.
Bluge optimisation is the only way to increase zinc perf. GRPC api would also help in zinc but that’s not really fixing the core problem.
Closing this issue.