Simple attention APIs for masked attention in transformers.
To understand more about this read primer.md.
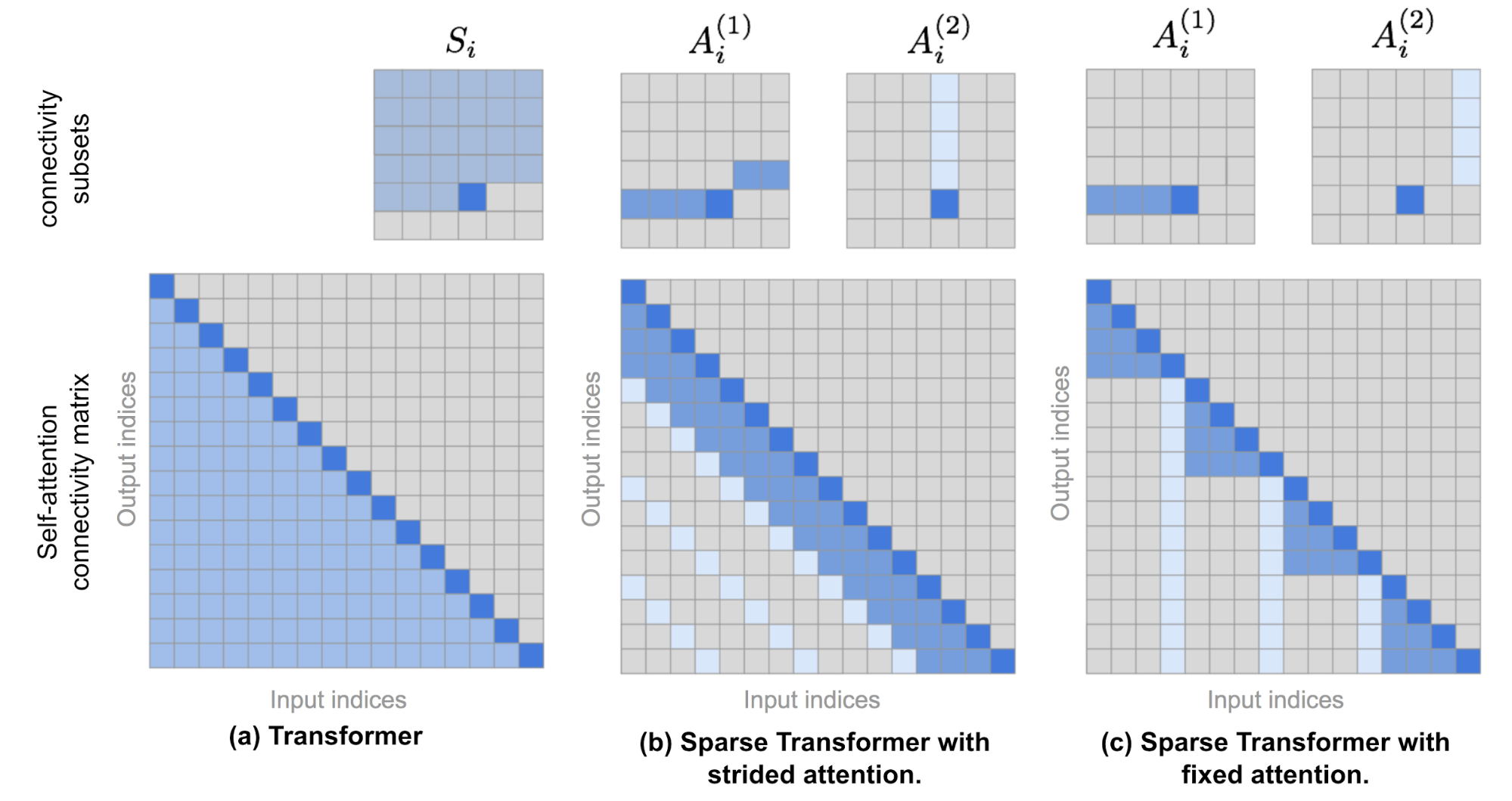
This package is aimed at making different attention patterns used in transformers easy to use. For eg. if you want to perform attention on only the 10% of all the tokens, then removing the compute for 90% improves speed and reduces memory complexity. Consider the sparse attention used by GPT3, or the one used by BigBIRD and another from Longformer:



Currently you need to write your own CUDA kernels or use code from longformer, which does something similar. However in all the cases it is very difficult to use this and also none provides any speed up on CPUs. With this simple package we aim to solve this problem.
Currently the code should be like this:
from mask_attention import attention as att
...
m = torch.Tensor([
[[1., 1., 1., 1.],
[1., 0., 1., 0.],
[1., 0., 0., 1.],
[0., 1., 0., 0.]],
[[1., 1., 1., 1.],
[1., 0., 1., 1.],
[0., 0., 1., 0.],
[1., 1., 1., 1.]]
]))
# pass the query and key vectors and attend where m == 0
w = att.mask_attn(tensor1 = q, tensor2 = k, mask_to_attend_to = m == 0, fill = -1e6)Our inspiration is pytorch_geometric and our aim is to make it even more simpler while writing good tests.
- fix segfault in
libtorch_example/attn.cpp, this is important because then we will understand theAT_DISPATCH_ALL_TYPESused in pytorch.- study more about
AT_DISPATCH_ALL_TYPES, is that really needed, can we bypass it?
- study more about
- Reverse engineer
pytorch/atenmodule and see what the exactgemmop to call. Though we now know thatEIGEN/LAPACKis called still is it possible to keep things inatenas much as possible.- [HARD CALL = 5] if in 5 attempts we cannot figure out a way to use
atenwe switch to directly callingEIGEN, though we will then need to write the wrappers for conversion totorch::Tensor.
- [HARD CALL = 5] if in 5 attempts we cannot figure out a way to use
- Write a code to run the finalised
gemm_opinlibtorch_exampleso we can verify code in C++, easy to port to python then. - Optimise the code such that it is as fast as
huggingface/transformers.transformersis written purely inpytorchno C++ bindings. We should match their speed, only then do we have a fighting chance.
- Write a wrapper for calling on CPU and CUDA (later) but we should have the wrapper like
pytorchdoes.- This will require studying
Cmake, hack takes priority over proper software dev.
- This will require studying
- Add CUDA support, this should not be too difficult giving simpler structure.
- SHOW FINGER to all those who are not open sourcing their work but merely giving binaries.
Before running the code ensure that you have pytorch installed as you will be using path from there. Though you can run directly from libtorch (C++ bindings of pytorch) our aim is to use this in python. To install run the following commands:
git clone https://github.com/yashbonde/mask_attention_transformer.git
cd mask_attention_transformer && chmod +x compile.sh
./compile.sh
If everything works correctly you should see something like this:
:: Found path to pytorch Cmake file --> /usr/local/lib/python3.9/site-packages/torch/share/cmake
-- The C compiler identification is AppleClang 12.0.0.12000031
-- The CXX compiler identification is AppleClang 12.0.0.12000031
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working C compiler: /Library/Developer/CommandLineTools/usr/bin/cc - skipped
-- Detecting C compile features
-- Detecting C compile features - done
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /Library/Developer/CommandLineTools/usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD
-- Performing Test CMAKE_HAVE_LIBC_PTHREAD - Success
-- Found Threads: TRUE
-- Found Torch: /usr/local/lib/python3.9/site-packages/torch/lib/libtorch.dylib
-- Configuring done
-- Generating done
-- Build files have been written to: /Users/yashbonde/Desktop/AI/fun/mask_attention_transformer/csrc/build
Scanning dependencies of target torch_mask_attention
[ 50%] Building CXX object CMakeFiles/torch_mask_attention.dir/mask_attention.cpp.o
[100%] Linking CXX shared library libtorch_mask_attention.dylib
[100%] Built target torch_mask_attention
:: Starting Test Runs (Library) ...
<built-in method dot_prod of PyCapsule object at 0x10860de40>
Inputs
-0.9181 -1.2182 0.1413
-0.0464 -0.0939 -1.5106
[ CPUFloatType{2,3} ]
0.6372 -1.0086 -0.8513
-0.3029 -0.6439 -1.3351
[ CPUFloatType{2,3} ]
---> tensor([0.5233, 2.0913])
:: Installing Python Version
Obtaining file:///Users/yashbonde/Desktop/AI/fun/mask_attention_transformer
Installing collected packages: mask-attention
Attempting uninstall: mask-attention
Found existing installation: mask-attention 0.0.1
Uninstalling mask-attention-0.0.1:
Successfully uninstalled mask-attention-0.0.1
Running setup.py develop for mask-attention
Successfully installed mask-attention
:: Starting Test Runs (Python) ...
<function dot_prod at 0x122e4d670>
out tensor([1.3461, 2.5791])
:: ... Complete