For example, if you have 4 nodes in devloud as below:
- devcloud@192.168.20.2
- devcloud@192.168.21.2
- devcloud@192.168.22.2
- devcloud@192.168.23.2
we use 192.168.20.2 as master node to run mpirun, which should be able to ssh the other 3 nodes without passwd. you could use following steps in 192.168.20.2
ssh-keygen -t rsa
ssh-copy-id -i /home/devcloud/.ssh/id_rsa devcloud@192.168.20.2
ssh-copy-id -i /home/devcloud/.ssh/id_rsa devcloud@192.168.21.2
ssh-copy-id -i /home/devcloud/.ssh/id_rsa devcloud@192.168.22.2
ssh-copy-id -i /home/devcloud/.ssh/id_rsa devcloud@192.168.23.2Since devcloud hasn't support NFS yet, you need to setup the conda env, build diffuser code, accelerate config in every node.
accelerate config in each node.
-
master node, node 0 in 192.168.20.2
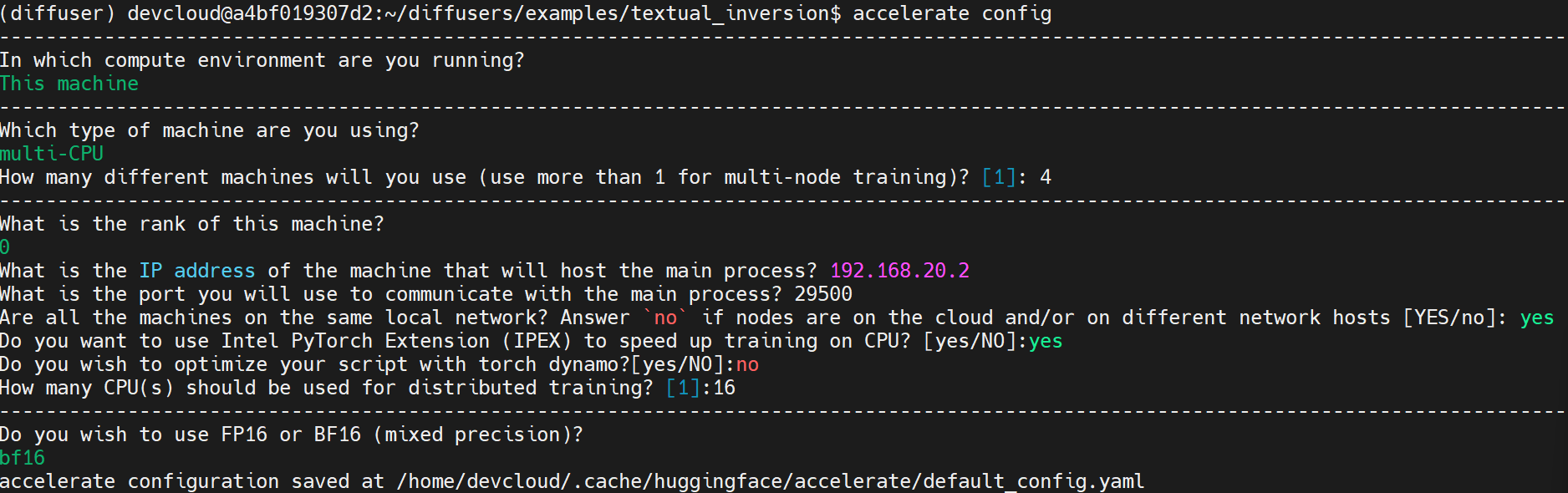
-
other nodes, for example, node 3 in 192.168.23.2
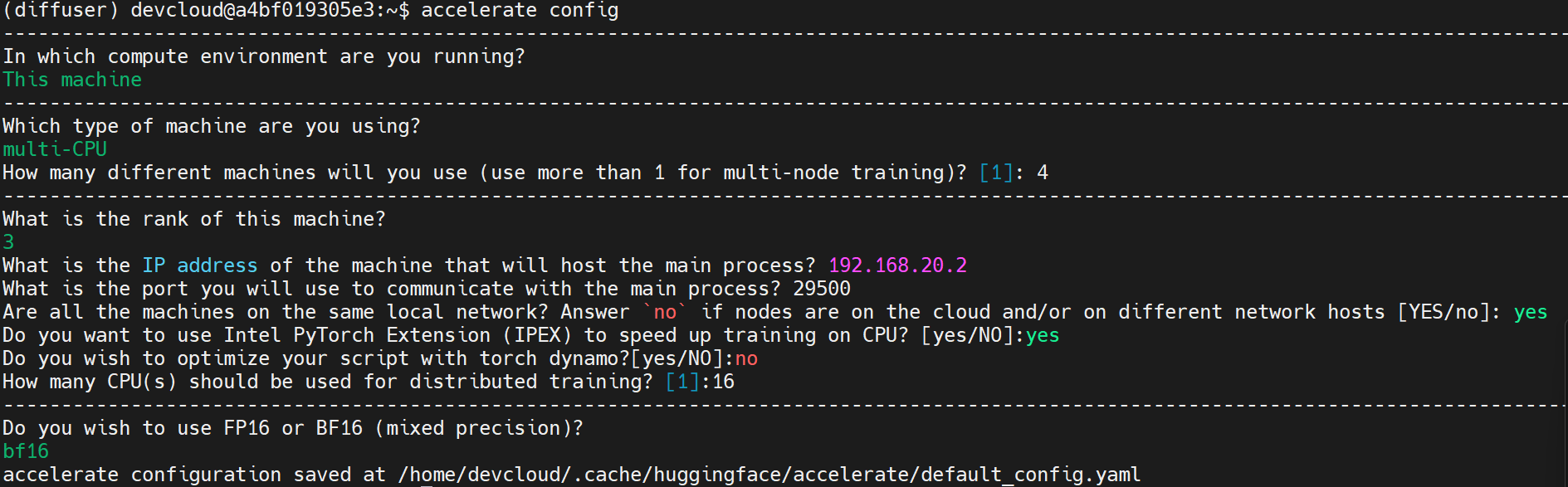


Since devcloud has no infiniband, you need to set I_MPI_HYDRA_IFACE explicity in master node(192.168.20.2), otherwise, mpirun will fail.
ifconfig to get the working NIC port, it's ens786f1 in master node. After the setup, you could run mpirun in master node.

export I_MPI_HYDRA_IFACE=ens786f1conda create -n diffuser python==3.9
conda activate diffuser
conda install gperftools -c conda-forge
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install transformers
pip install accelerate
python -m pip install intel_extension_for_pytorch
python -m pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpugit clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install .accelerate config
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libiomp5.so
export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
export CCL_ATL_TRANSPORT=ofi
export CCL_WORKER_COUNT=1 (enable ccl to work with ipex bf16 training, ccl offers optimization for bf16)
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="<path_to_finetune_images>"
In this case, we use 1 dicoo image to do the few-shot finetuing, and we use 1 virtual token as soft prompt.

mpirun -f nodefile -n 16 -ppn 4 accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<dicoo>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--seed=7 \
--gradient_accumulation_steps=1 \
--max_train_steps=200 \
--learning_rate=2.0e-03 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir=./textual_inversion_cat \
--mixed_precision bf16 \
--save_as_full_pipelineOnce you are done, you can refer to the run_inference.py to do the inference.
