CrossEntropy Exercise not working despite every step being marked as correct
alramalho opened this issue · comments

Hello everyone.
First of all thanks for the amazing content and effort put around RL, it really helps to streamline the thoughts and making a plan for someone that is trying to teach himself.
Now to the issue:
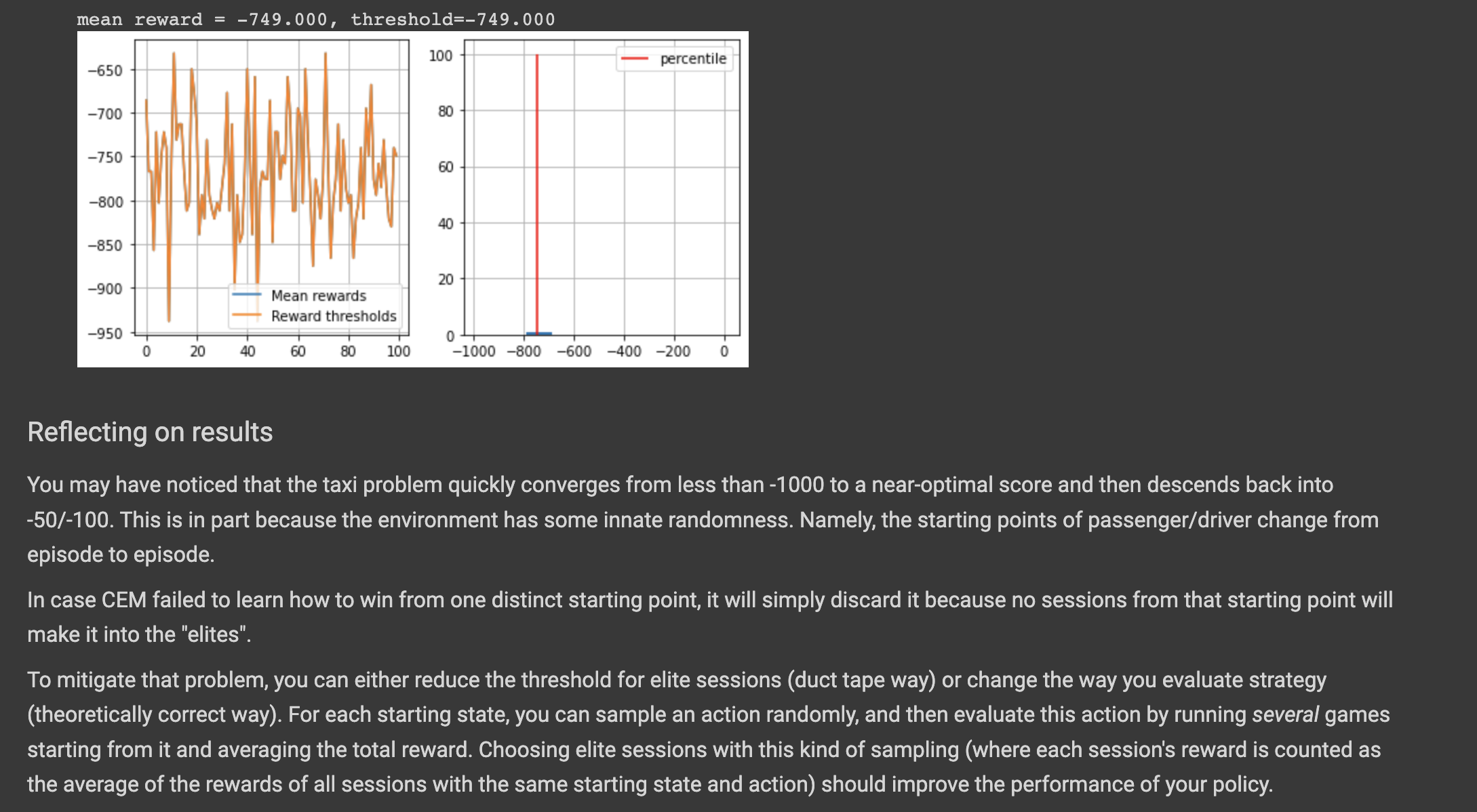
I was doing week 1 first assingneent: crossentropy_method.ipynb and unfortunately i'm not achieving the desired results when plotting the rewards at the very end.
Everything looks somewhat fine to me and the intermediate checks are all passing. Can anybody tell me what am I missing? I have a feeling it's somewhat in the the dimensionality of select_elites method but I'm not sure.
Can I get a tip? Thanks 🙏
Plots:
select_elites method:
def select_elites(states_batch, actions_batch, rewards_batch, percentile):
"""
Select states and actions from games that have rewards >= percentile
:param states_batch: list of lists of states, states_batch[session_i][t]
:param actions_batch: list of lists of actions, actions_batch[session_i][t]
:param rewards_batch: list of rewards, rewards_batch[session_i]
:returns: elite_states,elite_actions, both 1D lists of states and respective actions from elite sessions
Please return elite states and actions in their original order
[i.e. sorted by session number and timestep within session]
If you are confused, see examples below. Please don't assume that states are integers
(they will become different later).
"""
reward_threshold = np.percentile(rewards_batch, percentile)
elite_states = []
elite_actions = []
for i in range(len(rewards_batch)):
if rewards_batch[i] >= reward_threshold:
elite_states.extend(states_batch[i])
elite_actions.extend(actions_batch[i])
return elite_states, elite_actionsget new policy method
def get_new_policy(elite_states, elite_actions):
"""
Given a list of elite states/actions from select_elites,
return a new policy where each action probability is proportional to
policy[s_i,a_i] ~ #[occurrences of s_i and a_i in elite states/actions]
Don't forget to normalize the policy to get valid probabilities and handle the 0/0 case.
For states that you never visited, use a uniform distribution (1/n_actions for all states).
:param elite_states: 1D list of states from elite sessions
:param elite_actions: 1D list of actions from elite sessions
"""
# goal: create policy that acts according to elite set
# create new dict policy (s x a)
new_policy = np.zeros([n_states, n_actions])
# increment number of times action was picked for each state
for s,a in zip(elite_states, elite_actions):
new_policy[s][a] +=1
print(new_policy)
# divide to proportinal probabilities
for s in range(len(new_policy)):
sum = np.sum(new_policy[s])
for a in range(len(new_policy[s])):
if sum != 0:
new_policy[s][a] = new_policy[s][a] / sum
else:
new_policy[s][a] = 1 / n_actions
return new_policyI am aware that some code can be optimized, but I decided to left it as is since it was faster to streamline and break down for learning purposes.

Hello @alramalho, I hope that my answer isn't too late :D. I notice that you are extend the elite states/actions instead of append which means that the subsequent batches of elite states/actions won't be chronological as it requires. also, you need to choose tune t_max, then you can work with it until you get the normal rewards. If you want to improve the rewards, you need to follow the Reflecting on results section.

As you can see, it keeps progressing with me.
Another thing I want to mention; is your get_new_policy is reasonably 'delay' if the word didn't betray me.
get_new_policy_1 is your function, get_new_policy_2 improvement function:
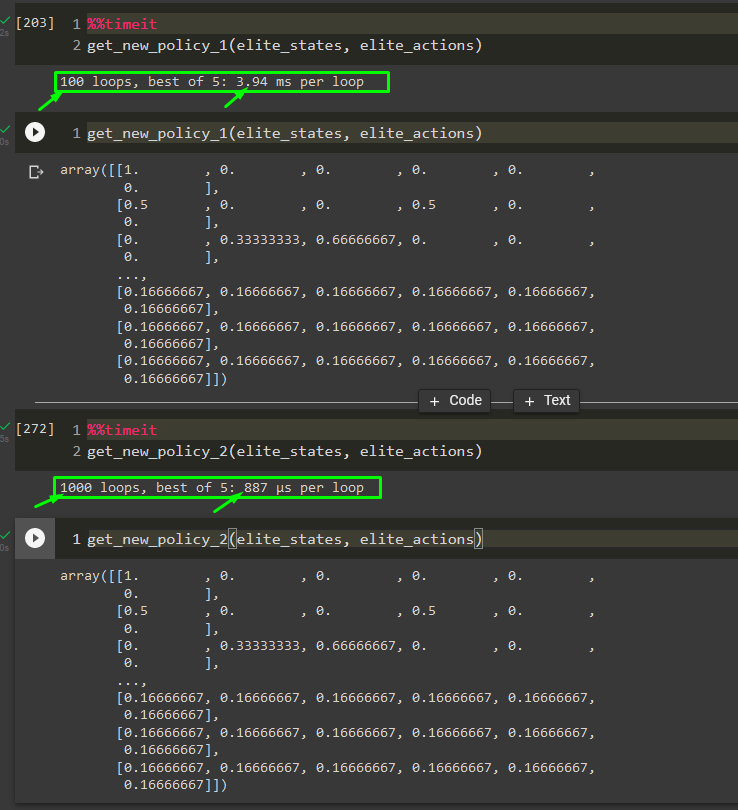
If you can, try to use the comprehensive list for vectorization mapping. Ref: https://stackoverflow.com/a/46470401/14473118
Hope that help.
Regards,