Two attempts to compress 3DLUTs via learning: low-rank decomposition and hash. Higher performance with much smaller models!
☺️
CLUT-Net: Learning Adaptively Compressed Representations of 3DLUTs for Lightweight Image Enhancement
- Fengyi Zhang, Hui Zeng, Tianjun Zhang, Lin Zhang
- ACMMM2022

Framework of our proposed CLUT-Net which consists of
- A neural network
- N basis CLUTs
- Two transformation matrices
The N basis CLUTs cover various enhancement effects required in different scenes. The neural network predicts content-dependent weights according to the downsampled input to fuse the basis CLUTs into an image-adaptive one, from which the transformation matrices adaptively reconstruct the corresponding standard 3DLUT to enhance the original input image.
- Fengyi Zhang, Lin Zhang, Tianjun Zhang, Dongqing Wang
- ICME2023

Framework of our proposed HashLUT-based image enhancement network which contains
- N progressive basis HashLUTs
- A collision-compensation network
- An expert network.
The basis HashLUTs not only cover the enhancement effects required by different scenes but also are set with progressive resolutions, cooperating with the collision-compensation network to largely mitigate the impact of hash conflict. The expert network selectively fuses the results of different HashLUTs by predicting image-adaptive weights based on the understanding of the characteristics of the input image.
Our two approaches are approximately contemporaneous (in 2022) and both intend to reduce the parameter amount and improve the performance for 3DLUT-based enhancement models via learning.
- The first approach works by delicately designed decomposition of 3DLUT motivated and abided by its channel correlations.
- The second approach directly, randomly, and even roughly improves the space utilization of 3DLUT through hashing but compensates afterward.
Although both have successfully achieved our goal, they exhibit different characteristics.
For example, compressing through decomposition would require a relatively large amount of parameters of transformation matrices than that of the basis CLUTs, while not extra space is needed except for the HashLUTs themselves. The standard 3DLUT would be reconstructed from CLUT but not from HashLUT. Such a relatively implicit representation of HashLUT makes it not easy to regularize with existing tools such as TotalVariance loss and Monotonicity loss.
pip install -r requirements.txt
The fast deployment of 3DLUT and CLUT relies on the CUDA implementation of trilinear interpolation in Image-Adaptive-3DLUT. To install their trilinear library, do:
cd trilinear_cpp
sh setup.sh
Warning:
import torchbeforeimport trilinear
Currently, HashLUT is implemented based on the fast hash encoding of NVIDIA Tiny-CUDA-NN. Please refer to their official site for compilation and PyTorch extension. (Don't be afraid cause it's gonna be really easy.)
- MIT-Adobe FiveK Dataset & HDR+ Burst Photography Dataset
- We use the setting of Image-Adaptive-3DLUT in our experiments, please refer to their page for details and data link.
- PPR10K
Prepare the dataset in the following format and you could use the provided FiveK Dataset class.
- <data_root>
- input_train
- input_test
- target_train
- target_test
Or you need to implement your own Class for your customed data format or directory arrangement.
To get started as soon as possible, only modify <data_root> to your own path and then:
python train.py --data_root <your_own_path>
You can train a specific model like:
# -1-1 for the standard 3DLUT-based model without decomposition
python train.py --model CLUTNet 20+-1+-1
python train.py --model CLUTNet 20+05+10
python train.py --model CLUTNet 20+05+20
python train.py --model HashLUT 7+13
python train.py --model HashLUT 6+13 SmallBackbone
Refer to parameter.py for default settings as well as other hyper-parameters.
By default, the images, models, and logs generated during training are saved in <save_root>/<dataset>/<name>.
We provide several pretrained models on the FiveK datset:
- CLUTNet 20+05+10 (25.56 PSNR)
- CLUTNet 20+05+20 (25.68 PSNR)
- HashLUT 7+13 (25.62 PSNR)
- HashLUT 6+13 SmallBackbone (25.57 PSNR) (A lighter version with about 110K params.)
To evaluate them, just
python test.py --model CLUTNet 20+05+10 --epoch 310
python test.py --model CLUTNet 20+05+20 --epoch 361
python test.py --model HashLUT 7+13 --epoch 299
python test.py --model HashLUT 6+13 SmallBackbone --epoch 367
To evaluate your own trained model of a specific epoch, specify the epoch and keep the other parameters the same as training.
-
Strong correlations

-
Weak correlations

-
Learned matrices

-
3D visualization of the learned basis 3DLUTs (Left: initial identity mapping. Right: after training)
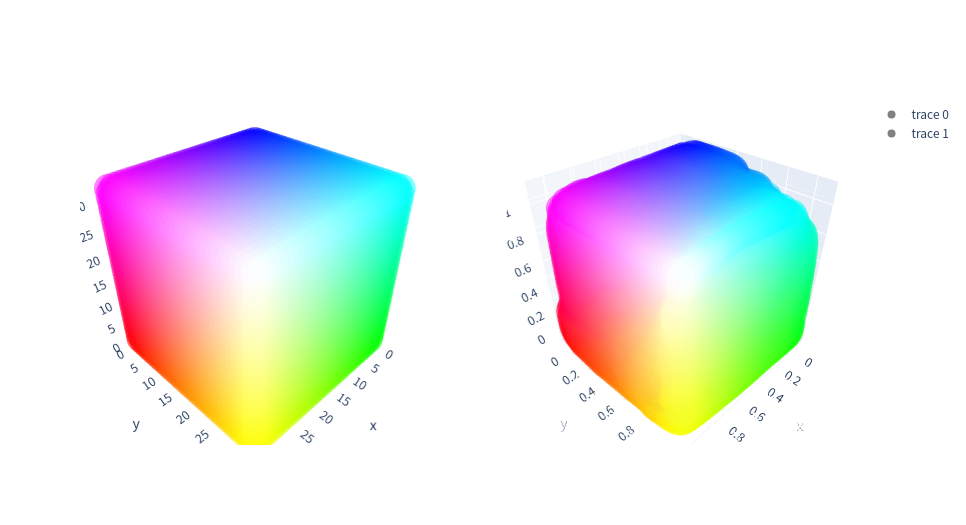
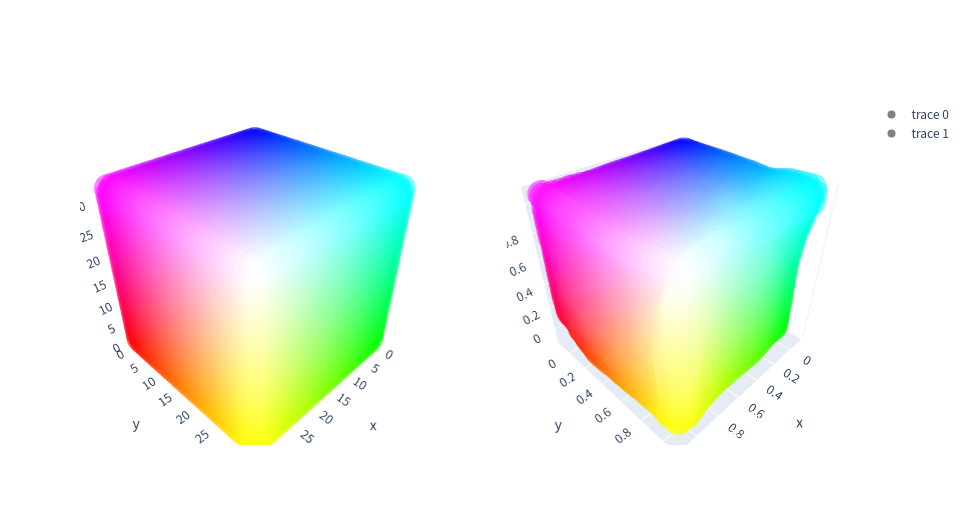
-
Grid occupancy visualization







All the visualization codes could be found in utils/.
-
This repo.'s framework and the implementation of CLUTNet are built on the excellent work of Zeng et al: Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time. TPAMI2020
-
The multi-resolution HashLUTs are implemented based on the fast hash encoding of NVIDIA Tiny-CUDA-NN.
Great appreciation for the efforts of the above work and all collaborators and for your interest!
Sincerely hope our work helps! 🌟 🔔
@inproceedings{clutnet,
author = {Zhang, Fengyi and Zeng, Hui and Zhang, Tianjun and Zhang, Lin},
title = {CLUT-Net: Learning Adaptively Compressed Representations of 3DLUTs for Lightweight Image Enhancement},
year = {2022},
isbn = {9781450392037},
url = {https://doi.org/10.1145/3503161.3547879},
doi = {10.1145/3503161.3547879},
booktitle = {Proceedings of the 30th ACM International Conference on Multimedia},
pages = {6493–6501},
numpages = {9},
}
@INPROCEEDINGS{hashlut,
author={Zhang, Fengyi and Zhang, Lin and Zhang, Tianjun and Wang, Dongqing},
booktitle={2023 IEEE International Conference on Multimedia and Expo (ICME)},
title={Adaptively Hashing 3DLUTs for Lightweight Real-time Image Enhancement},
year={2023},
volume={},
number={},
pages={2771-2776},
doi={10.1109/ICME55011.2023.00471}}