FinRL: A Deep Reinforcement Learning Framework for Quantitative Finance 








FinRL is an open source framework to help practitioners pipeline the development of trading strategies. In deep reinforcement learning (DRL), an agent learns by continuously interacting with an environment, in a trial-and-error manner, making sequential decisions under uncertainty and achieving a balance between exploration and exploitation. The open source community AI4Finance (to efficiently automate trading) provides resources about deep reinforcement learning (DRL) in quantitative finance, and aim to accelerate the paradigm shift from conventional machine learning approach to RLOps in finance.
To contribute? Please check the end of this page.
Feel free to report bugs via Github issues, join the mailing list: AI4Finance, and discuss FinRL in slack channel:

Roadmaps of FinRL:
FinRL 1.0: entry-level toturials for beginners, with a demonstrative and educational purpose.
FinRL 2.0: intermediate-level framework for full-stack developers and professionals. Check out ElegantRL.
FinRL 3.0: advanced-level services for investment banks and hedge funds. Please check our cloud-native solution GPU-podracer.
FinRL 0.0: we provide tens of training/testing/trading environments in NeoFinRL.
FinRL provides a unified DRL framework for various markets, SOTA DRL algorithms, benchmark finance tasks (portfolio allocation, cryptocurrency trading, high-frequency trading), live trading, etc.
Table of Contents
Prior Arts:
We published papers in FinTech and now arrive at this project:
- 4). FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance, Deep RL Workshop, NeurIPS 2020.
- 3). Deep Reinforcement Learning for Automated Stock Trading: An Ensemble Strategy, paper and codes, ACM International Conference on AI in Finance, ICAIF 2020.
- 2). Multi-agent Reinforcement Learning for Liquidation Strategy Analysis, paper and codes. Workshop on Applications and Infrastructure for Multi-Agent Learning, ICML 2019.
- 1). Practical Deep Reinforcement Learning Approach for Stock Trading, paper and codes, Workshop on Challenges and Opportunities for AI in Financial Services, NeurIPS 2018.
News and Tutorials
- [Towardsdatascience] FinRL for Quantitative Finance: Tutorial for Multiple Stock Trading
- [Towardsdatascience] FinRL for Quantitative Finance: Tutorial for Portfolio Allocation
- [Towardsdatascience] FinRL for Quantitative Finance: Tutorial for Single Stock Trading
- [Towardsdatascience] Deep Reinforcement Learning for Automated Stock Trading
- [Towardsdatascience] ElegantRL: A Lightweight and Stable Deep Reinforcement Learning Library
- [Towardsdatascience] ElegantRL: Mastering PPO Algorithms
- [MLearning.ai] ElegantRL Demo: Stock Trading Using DDPG (Part I)
- [MLearning.ai] ElegantRL Demo: Stock Trading Using DDPG (Part II)
- [Analyticsindiamag.com] How To Automate Stock Market Using FinRL (Deep Reinforcement Learning Library)?
- [Kaggle] Jane Street Market Prediction
- [量化投资与机器学习] 基于深度强化学习的股票交易策略框架(代码+文档)
- [运筹OR帷幄] 领读计划NO.10 | 基于深度增强学习的量化交易机器人:从AlphaGo到FinRL的演变过程
- [深度强化实验室] 【重磅推荐】哥大开源“FinRL”: 一个用于量化金融自动交易的深度强化学习库
- [矩池云Matpool] 在矩池云上如何运行FinRL股票交易策略框架
- [Neurohive] FinRL: глубокое обучение с подкреплением для трейдинга
- [ICHI.PRO] 양적 금융을위한 FinRL: 단일 주식 거래를위한 튜토리얼
Overview
A YouTube video about FinRL library. [YouTube] AI4Finance Channel for quant finance.
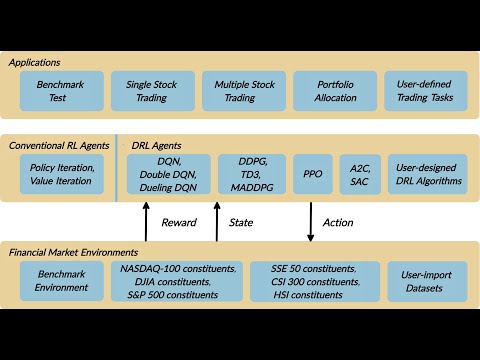

DRL Algorithms
We implemented Deep Q Learning (DQN), Double DQN, DDPG, A2C, SAC, PPO, TD3, GAE, MADDPG, etc. using PyTorch and OpenAI Gym.
Status
Version History [click to expand]
- 2020-12-14 Upgraded to Pytorch with stable-baselines3; Remove tensorflow 1.0 at this moment, under development to support tensorflow 2.0
- 2020-11-27 0.1: Beta version with tensorflow 1.5
- 2021-08-25 0.3.1: pytorch version with a three-layer architecture, apps (financial tasks), drl_agents (drl algorithms), neo_finrl (gym env)
Installation:app
Installation (Recommend using cloud service - Google Colab or AWS EC2)
Download to local:
git clone https://github.com/AI4Finance-LLC/FinRL-Library.gitInstall the unstable development version of FinRL using pip:
pip install git+https://github.com/AI4Finance-LLC/FinRL-Library.gitPrerequisites
For OpenAI Baselines, you'll need system packages CMake, OpenMPI and zlib. Those can be installed as follows:
Ubuntu
sudo apt-get update && sudo apt-get install cmake libopenmpi-dev python3-dev zlib1g-dev libgl1-mesa-glxMac OS X
Installation of system packages on Mac requires Homebrew. With Homebrew installed, run the following:
brew install cmake openmpiWindows 10
To install stable-baselines on Windows, please look at the documentation.
Create and Activate Python Virtual-Environment (Optional but highly recommended)
cd into this repository:
cd FinRL-LibraryUnder folder /FinRL-Library, create a Python virtual-environment:
pip install virtualenvVirtualenvs are essentially folders that have copies of python executable and all python packages.
Virtualenvs can also avoid packages conflicts.
Create a virtualenv venv under folder /FinRL-Library
virtualenv -p python3 venvTo activate a virtualenv:
source venv/bin/activate
To activate a virtualenv on windows:
venv\Scripts\activate
Dependencies
The script has been tested running under Python >= 3.6.0, with the following packages installed:
pip install -r requirements.txtStable-Baselines3 using Pytorch
About Stable-Baselines 3
Stable-Baselines3 is a set of improved implementations of reinforcement learning algorithms in PyTorch. It is the next major version of Stable Baselines. If you have questions regarding Stable-baselines package, please refer to Stable-baselines3 installation guide. Install the Stable Baselines package using pip:
pip install stable-baselines3[extra]
A migration guide from SB2 to SB3 can be found in the documentation.
Stable-Baselines using Tensorflow 2.0
Still Under Development
Docker Installation
Option 1: Use the bin
# grant access to execute scripting (read it, it's harmless)
$ sudo chmod -R 777 docker/bin
# build the container!
$ ./docker/bin/build_container.sh
# start notebook on port 8887!
$ ./docker/bin/start_notebook.sh
# proceed to party!Option 2: Do it manually
Build the container:
$ docker build -f docker/Dockerfile -t finrl docker/Start the container:
$ docker run -it --rm -v ${PWD}:/home -p 8888:8888 finrlNote: The default container run starts jupyter lab in the root directory, allowing you to run scripts, notebooks, etc.
Run
python main.py --mode=trainBacktesting
Use Quantopian's pyfolio package to do the backtesting.
Data
The stock data we use is pulled from Yahoo Finance API.
(The following time line is used in the paper; users can update to new time windows.)

Contributions
- FinRL is an open source library specifically designed and implemented for quant finance. Trading environments incorporating market frictions are used and provided.
- Trading tasks accompanied by hands-on tutorials with built-in DRL agents are available in a beginner-friendly and reproducible fashion using Jupyter notebook. Customization of trading time steps is feasible.
- FinRL has good scalability, with a broad range of fine-tuned state-of-the-art DRL algorithms. Adjusting the implementations to the rapid changing stock market is well supported.
- Typical use cases are selected and used to establish a benchmark for the quantitative finance community. Standard backtesting and evaluation metrics are also provided for easy and effective performance evaluation.
Citing FinRL
@article{finrl2020,
author = {Liu, Xiao-Yang and Yang, Hongyang and Chen, Qian and Zhang, Runjia and Yang, Liuqing and Xiao, Bowen and Wang, Christina Dan},
journal = {Deep RL Workshop, NeurIPS 2020},
title = {FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance},
url = {https://arxiv.org/pdf/2011.09607.pdf},
year = {2020}
}
Call for Contributions
Will maintain FinRL with the "AI4Finance" community and welcome your contributions!
Please check the contributing guidances.
Contributors
Thanks to all the people who contribute.
Support various markets
Support more markets for users to test their stategies.
SOTA DRL algorithms
Maintain a pool of SOTA DRL algorithms.
Benchmarks for typical trading tasks
To help quants have better evaluations, we will maintain benchmarks for many trading tasks, upon which you can improve for your own tasks.
Support live trading
Supporting live trading can close the simulation-reality gap, which allows quants to switch to the real market when they are confident with the results.
LICENSE
MIT