
Table of Contents
|
這裡展示了我在成功大學人工智慧碩士學位時,所撰寫的論文內容及程式碼。如果想查看論文、海報、投影片等內容,請移動到 Paper Section;想查看論文中相關原始碼,請移動到 Code Section;想查看論文的訓練結果 (以 wandb 展示) 或心智圖,請移動到 Additional Links。另外,在觀看本論文內容前,建議到 Background Knowledge 區塊中查看一些相關的背景知識,這些都是我在撰寫論文前精心收集而來的,例如:目前主流 NMT 的相關技術整理、常見的 zh-ja 資料集,以及相關的 related work 整理。 This repository provides detail and code of the thesis for my Master's degree in Artificial Intelligence at National Cheng Kung University. Please navigate to the Paper Section to view my papers, posters, slides, etc; Code Section to view the source code of the paper; Additional Links to see the training results (displayed on wandb) or the mindmap of the paper. In addition, it is recommended to review some of the background knowledge in the Background Knowledge section, which I have carefully collected before writing the thesis; for example, the current NMT-related techniques, zh-ja datasets, and related work. Built With
The TRUE COVER of this repository
|
English Abstract
Neural machine translation has been improved by the introduction of encoder-decoder networks in recent years. However, the translation between Chinese and Japanese has not yet achieved the same high quality as that between English and other languages due to the lack of parallel corpora and less similarity in languages.
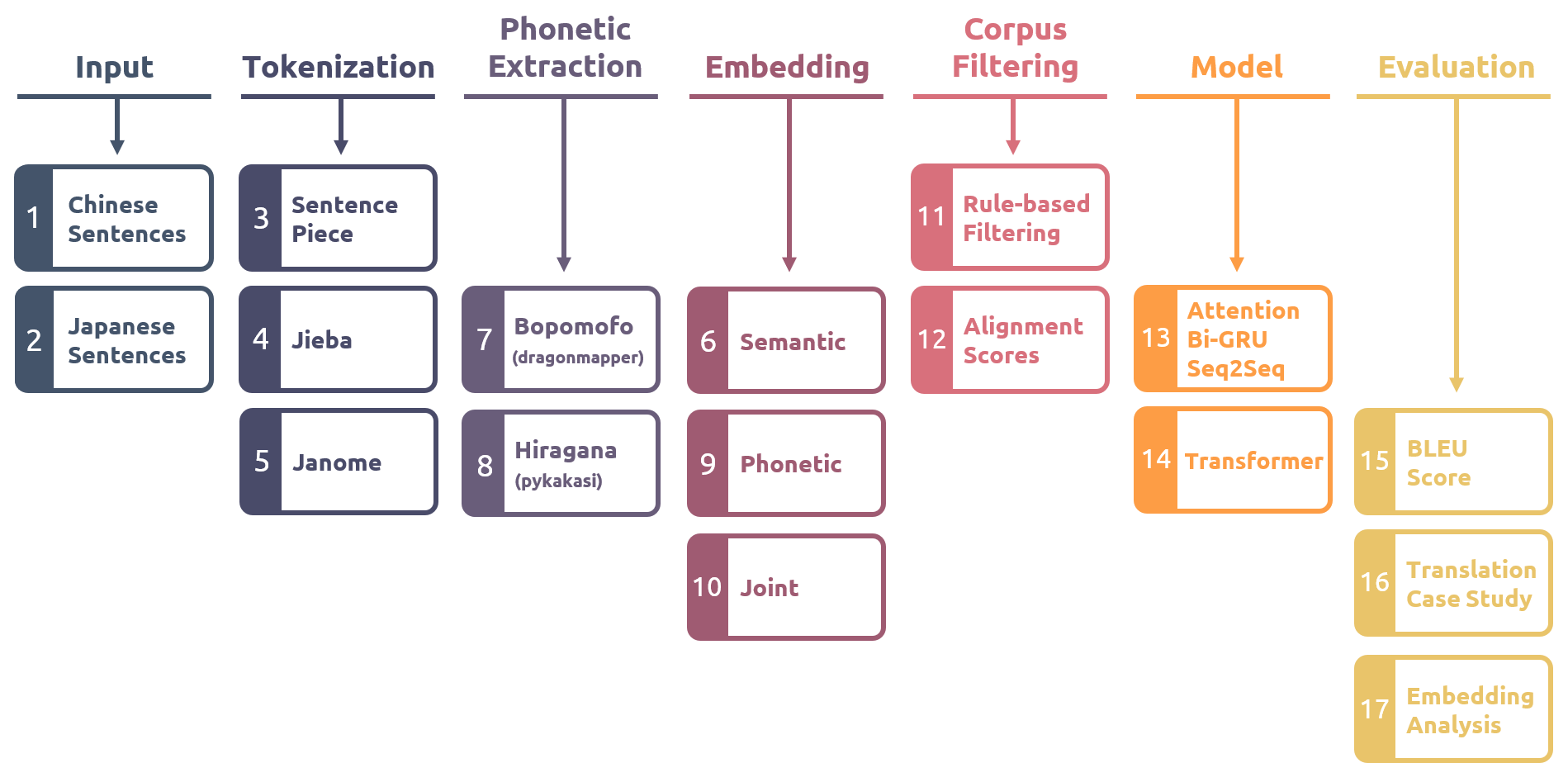
This paper attempts to use phonetic information as an additional feature for Chinese and Japanese and aims to improve translation quality through feature engineering. We first extracted Chinese bopomofo and Japanese hiragana as phonetic information from the corpus with three tokenization approaches. Second, the embedding with semantics and embedding with phonetics are generated by training separately on the text and phonetic information. Third, we combined both embeddings to create a joint semantic-phonetic embedding and implemented it into two mainstream neural machine translation models for training and further extracting the features.
The results show that the models trained and fine-tuned with joint embeddings yield higher BLEU scores than those using semantic or phonetic embeddings only. We also conducted case studies on the translation results. The translations generated with joint embeddings tend to select the correct and even more precise words and retain Japanese katakana and English words, resulting in semantic improvements. Besides, four analyses conducted on joint embeddings and semantic embeddings all gave positive feedback, which showed that the joint embeddings could preserve and even outperform the vector meanings possessed by the semantic embeddings.
The reveal of BLEU scores and embedding analysis demonstrates that simply using a small corpus to extract phonetic information as a feature can positively affect the Chinese and Japanese word vectors. In addition, the use of joint semantic-phonetic embeddings can effectively improve the performance of Chinese-Japanese neural machine translation systems.
Chinese Abstract
近年來,神經機器翻譯因引入編碼器-解碼器網路而逐漸完善,但是在中文及日文的翻譯任務中,由於訓練資料的缺乏,以及和西方語言的差異性,始終無法獲得像英文與其他語言之間的高翻譯品質。本篇論文嘗試使用聲音資訊作為中日文的額外特徵,並將該特徵應用於中日文的神經機器翻譯系統當中,旨在透過以特徵工程的方式來加強翻譯品質。
本論文基於三種分詞方法,在不同的分詞下,提取出語料庫中的中文注音以及日文平假名做為聲音資訊。接著,利用文字資訊以及聲音資訊,分別訓練出帶有語義以及帶有語音的詞嵌入;我們混合兩者,建立同時帶有語義及語音的「合併詞嵌入」,並將其投入至兩種主流的神經機器翻譯模型,進行訓練與進一步的特徵提取。
實驗採用雙語評估替補分數 (BLEU) 對翻譯結果進行評分,結果表明,使用合併詞嵌入進行訓練與微調的模型,皆獲得比單純使用語義或語音的詞嵌入還要更高的分數。我們亦對模型的翻譯結果進行案例分析,由合併詞嵌入產生出的翻譯能夠保留正確,甚至更為精確的詞彙;也能夠保留片假名與英文術語,得到語義上的提升。實驗另外對合併詞嵌入和單純包含語義的詞嵌入進行四項分析,每項分析皆獲得正面回饋,顯示合併詞嵌入能夠保留,甚至超越語義詞嵌入所持有的向量涵義。
綜合翻譯分數以及詞嵌入分析,我們發現單純使用小型語料庫提取語音資訊作為特徵,便能對中日文的詞向量帶來正面影響;此外,使用合併語義和語音的詞嵌入,能夠進一步有效提升中日文神經機器翻譯系統的效能。
You can view the poster I designed for this paper in poster.pdf.
You can view my full paper in thesis.pdf.
You can view my slides of oral defense in oral_defense.pdf.
- Attention-based Bi-GRU Model (w/o pretrained embedding)
- Attention-based Bi-GRU Model (w/ pretrained embeddings)
- Transformer (w/o pretrained embedding)
- Transformer (w/ pretrained embeddings)
I have used whimsical to create a casual roadmap (mind map).
You can also go to wandb to see all the parameters, loss, perplexity and BLEU Scores of the experiment.
Reach out to the maintainer at one of the following places:
- GitHub issues
- The email which is located in GitHub profile
If you want to say thank you or/and support active development of Chinese-Japanese Neural Machine Translation with Semantic-Phonetic Embedding:
- Add a GitHub Star to the project.
- Write interesting articles about the project on Dev.to, Medium or personal blog.
Together, we can make Chinese-Japanese Neural Machine Translation with Semantic-Phonetic Embedding better!
The original setup of this repository is by Shih-Chieh Wang.
For a full list of all authors and contributors, check the contributor's page.
This project is licensed under the MIT license.
See LICENSE for more information.
首先,我要十分感謝 Stahlberg, F. (2020). Neural Machine Translation: A Review and Survey;這篇論文整理了現今 NMT 主流技術的走向,讓我受益良多。我在完整閱讀後整理了一些筆記,歡迎大家參考。
First of all, I would like to express my great appreciation to Stahlberg, F. (2020). Neural Machine Translation: A Review and Survey; I have benefited a lot from this paper, which collates the current trends of NMT mainstream technologies. I have organized some notes after reading it, and I hope you will find these notes inspiring.
NMT Techonology Notes
| Topic (click to view full note) | Description |
|---|---|
| Embedding | Word, Phrase, Sentence 各種級別的 Embedding |
| Encoder-Decoder | 現今 NMT 主流架構,一開始被固定的 latent space 所限制,後來有 attention 解決問題 |
| Attention | Attention, Self-attention, Multi-head attention 是 NMT 成功的主要原因之一,裡面還比較了 RNN 和 CNN-based NMT。推薦可以參考李弘毅教授的教學影片獲得更細節的知識:Conditional Generation by RNN & Attention 和 Transformer |
| Decoding | Decoding 是最終翻譯過程的核心,較常見的方法有:Beam Search、Generating Diverse Translations、Top-k sampling。另外,裡面也介紹一些即時翻譯的 decoding 方法 |
| Open-Vocabulary | 使用 UNK token 無法完全解決單字量過多所造成的問題。我們可以改變模型的輸入,例如:Word-based NMT、Character-based NMT、Subword-based NMT;其中,主流的 subword 最常見的擷取方法為 BPE (Byte pair encoding) |
| Monolingual dataset | 應用非常巨量的單邊語言詞庫 (monolingual corpus),來擴充平行詞庫 (parallel corpus),加強翻譯的資料集數量。目前最有名的作法是 Back-translation。其他還有利用 Unsupervised NMT 來取消對平行詞庫的需求。(Data-Sparsity 提到) |
| Multilingual NMT | 從 1-1 翻譯進階為多種語言之間的交叉翻譯,常見的名詞為 Zero-shot translation, Pivot-based zero-shot translation |
| Model Errors | 比較 model errors 和 search errors 的關係,以及進階解決 length deficiency 的問題 |
| Training Methods | 介紹 training 所會用到的 loss,以及多種問題如 overfitting、vanishing gradient、degradation、exposure bias。以及介紹解決方法,例如:Regularization、Residual connections、Reinforcement Learning、Adversarial Learning、Dual Supervised Learning |
| Interpretability | 解釋 NMT 模型和翻譯結果的方法。常見的有 Post-hoc Interpretability、Model-intrinsic Interpretability、Quality estimation、Word Alignment (Alignment-based NMT) |
| Alternative Models | 提出更多基於 Transformer、attention、Encoder-Decoder 的架構之上,加入 memory 或修改原架構的方法。例如:Relative Position Representation、Memory-augmented Neural Networks、Non-autoregressive |
| Data Sparsity | 處理資料集雜訊 (noise) 過多的方法:Corpus Filtering、Domain Adaptation。處理平行資料集 (parallel corpus) 太少的方法: Low-resource NMT、Unsupervised NMT |
| Model Size | Model size 是在移動平台上的一大限制。為了降低 size 有的方法刪除不必要的 weights 或重複的 neurons;其中兩個最核心的方法為 Neural Architecture Search (NAS)、Knowledge Distillation |
| Extended Context | 基於一般 NMT 架構,加入其他系統來和 NMT 合併:Multimodal NMT、Tree-based NMT、Graph-Structured Input NMT、Document-level Translation |
| NMT-SMT Hybird System | 利用 SMT 依然優於 NMT 的部分,來和 NMT 結合互補。例如:SMT-supported NMT、System Combination |
資料是深度學習的靈魂,感謝這些資料集的貢獻者成就了今日的翻譯系統。本篇論文使用了 Asian Scientific Paper Excerpt Corpus (ASPEC) 作為研究的資料集,但在申請 ASPEC 之前也有研究其他可能會使用的資料集。以下列出幾個中日文資料集。 (許多資料集需要和官方申請權限,而很抱歉這邊沒有提供其下載連結)
Data is the soul of deep learning, and thanks to the contribution of these datasets for making today's translation system possible. We use Asian Scientific Paper Excerpt Corpus (ASPEC) as the dataset for our research, but other possible datasets were also explored before applying for ASPEC. Below is a list of some Chinese and Japanese parallel corpora. (Many of the datasets require official permission, and sorry that the download links are not available here.)
Chinese-Japanese NMT Datasets
| Date | Provenance | Description | Related Link |
|---|---|---|---|
| 2020 | IWSLT 2020 - Open Domain Translation | 包含大量網路爬蟲的平行語料庫,用於 Open domain translation 的競賽。分為四種等級: existing_parallel, webcrawled parallel filtered (19M), webcrawled parallel unfiltered (161.5M), webcrawled unaligned (15.6M) |
|
| 2020 | WAT 2020 The 7th Workshop on Asian Translation | 主要用於 WAT 競賽。其中有三大資料集 (ASPEC, JPO Patent Corpus, JIJI Corpus),都需要寄信審核索取。 |
ASPEC, JPO Patent Corpus, JIJI Corpus |
| 2017 | Japanese to English/Chinese/Korean Datasets for Translation Quality Estimation and Automatic Post-Editing | 簡單資料集,用來測試 QE 和 APE 的。 (travel (8,783 segments), hospital (1,676 segments)) | PDF, Dataset |
| 2015 | Constructing a Chinese—Japanese Parallel Corpus from Wikipedia | 從維基百科自動擷取的中日平行資料,包含:126,811 parallel sentences, 131,509 parallel fragments, 198 dev, 198 test |
PDF, Dataset |
| 2011 | JEC Basic Sentence Data | Excel file containing all the sentences in Japanese, English and Chinese, it contains: 5304 sentences | Dataset |
PS. Yang, W., Shen, H. and Lepage, Y., (2017). Inflating a small parallel corpus into a large quasi-parallel corpus using monolingual data for Chinese-Japanese machine translation. Journal of Information Processing 講解了中日資料集缺乏的問題,還有該論文解決的方法。
以下是我在整理相關論文時所記錄的筆記,主要分為三大部分,(1) 是針對 IWSLT 2020 Open Domain Translation 競賽時,一些團隊使用 SOTA 技術改善 NMT 問題的論文。 (2) 是針對中文特徵進行研究的論文。 (3) 是針對語音特徵進行研究的論文
The following are the notes I have taken while reviewing the related papers. They are divided into three parts: (1) papers that use the SOTA methods to improve the NMT problem in the IWSLT 2020 Open Domain Translation competition. (2) Papers that extract the Chinese language features. (3) Papers that extract the phonetic features.
Open Domain Translation
| Paper (click to view full note) | Description |
|---|---|
| LIT Team’s System Description for Japanese-Chinese Machine | IWSLT 2020 open domain translation task 強調 open domain 的翻譯,並且給予大量包含雜訊資料集。作者使用了以下方法處理資料集: Parallel Data Filter、Web Crawled Sentence Alignment、Back-translation;並且對 baseline 模型進行了以下加強:Bigger Transformer、Relative Position Representation |
| Octanove Labs’ Japanese-Chinese Open Domain Translation System | 同上,為 IWSLT 2020 open domain translation task 的回饋,作者利用以下方法處理資料集:Parallel Corpus Filtering、Back-Translation;而模型做了以下處理:Random parameter search、ensembling。作者先對資料進行分析,並自訂 rules 和 classifiers 來去除不必要資料,且隨著 back-translation 使用率提高,獲得更好成積。另外,作者也提出了 top-k sampling 與 external data 的幫助 |
| CASIA’s System for IWSLT 2020 Open Domain Translation | Video, PDF |
Chinese Feature
| Paper (click to view full note) | Description |
|---|---|
| Chinese–Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information Unsupervised neural machine translation | 作者將 UNMT 運用於中日文這類 logographic languages,特別是將中日文切成更小的 sub-character-level 來實作。裡面運用到的方法有:Shared BPE Embeddings、Encoder–Decoder Language Models、Back-Translation。結果展示了 sub-character 和 high token sharing rate 的重要性,也點出了 NMT quality metric (例如 BLEU) 的不足 |
| Improving Character-level Japanese-Chinese Neural Machine Translation with Radicals as an Additional Input Feature | 作者嘗試在 character-level NMT 加入額外特徵-部首 (radical)。因為中文屬於 logograms,作者基於 character-level 額外加入部首當作特徵。結果展示了部首當作特徵能提升效能,甚至翻譯出 reference 沒有翻譯成功的單詞 |
Phonetic Feature
| Paper (click to view full note) | Description |
|---|---|
| Diversity by Phonetics and its Application in Neural Machine Translation | 作者在西方語言及中文之間的翻譯中加入 phonetic 特徵,使用 Soundex, NYSIIS, Metaphone 來取出西方語言的 phonetic 特徵,使用 pinyin 取出中文特徵。利用 distribution plotting, Quantitative verifications, Density Measure 等來進一步確認 phonetic 特徵的實用性 |
| Robust Neural Machine Translation with Joint Textual and Phonetic Embedding | 作者提出一般翻譯系統常見的語料庫錯字問題。作者使用 phonetic 特徵來強化及平衡 semantic 特徵的缺失。分析在 joint embedding 中不同 semantic-phonetic 特徵權重 (beta) 分別影響翻譯系統的程度。另外發現 phonetic 特徵中,中文的同音字會分布於類似的位置 |