This module makes heavily use of pyltp
- Install pyltp
pip install pyltp - Download NLP model from 百度雲
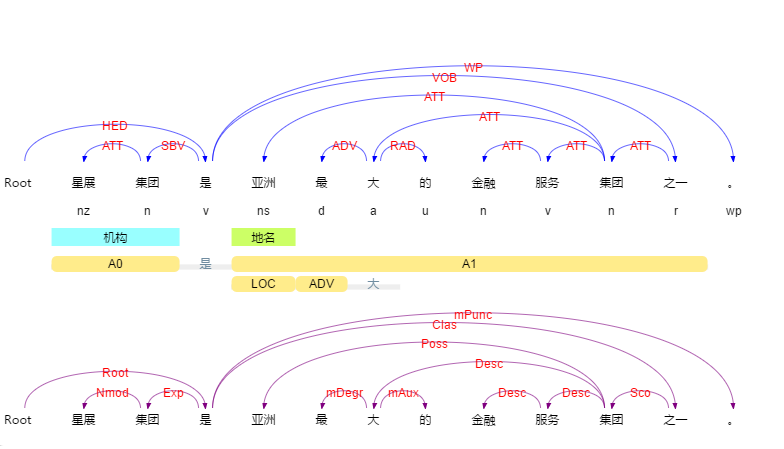
LTP has an excellent semantic parsing module shown below:
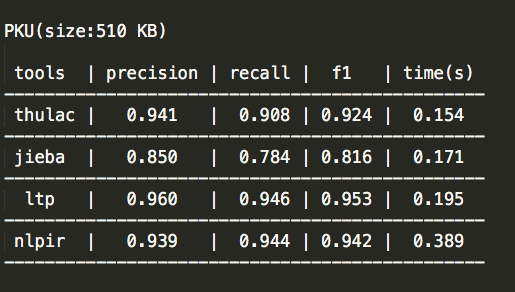
Also, in general, LTP performs better than other open-source Chinese NLP libraries,like Jieba ,here's the comparison on word tokenization for SIGHAN Bakeoff 2005 PKU, 510KB dataset:
The extractor module tries to break down a Chinese sentence into a Triple relation (e1, e2, r), which can be understood by computer
e.g. 星展集团是亚洲最大的金融服务集团之一, 拥有约3千5百亿美元资产和超过280间分行, 业务遍及18个市场。
are parsed as follows:
e1:星展集团, e2:亚洲最大的金融服务集团之一, r:是
e1:星展集团, e2:约3千5百亿美元资产, r:拥有
e1:业务, e2:18个市场, r:遍及
However, this extractor is about ~70% accurate and is still under improvement at this moment. Feel free to comment and make pull request.
哈工大社会计算与信息检索研究中心研制的语言技术平台 LTP