Fake News Detection Using Natural Language Processing (NLP) and Classification Modeling
Distinguishing Between Subreddit Posts From the r/TheOnion & r/nottheonion
Abstract
Early in 2019, WhatsApp announced it was deleting over 2 million accounts a month to prevent the rampant spread of fake news.1 Their decision came after incidents of violent attacks in India were triggered by the spread of fake news on the messaging platform.2 I was curious about how WhatsApp created their fake news filter, so I made one myself using open source data from Reddit. I scraped around 30,000 posts from subreddits r/TheOnion and r/nottheonion and built a classification model that could distinguish between fake news from r/TheOnion and absurd news from r/nottheonion. While building this model, I optimized for accuracy. That is, I wanted to have the highest possible outcomes of True Negatives and True Positives, and least amount of False Positives and False Negatives. The worse scenario is deleting an account or post that shares authentic news, mistaking it for fake news. After cleaning, analyzing, and performing NLP functions to the data, I created optimal classification models using Pipeline and GridSearch to help me determine the best parameters for my model. The classification model with the highest accuracy score of 90% vectorized the data using CountVectorizer(ngram_range= (1, 3)) and trained the data using MultinomialNB(alpha = 0.36). Additionally, to interpret coefficients of the model, I used CountVectorizer(stop_words = custom) & LogisticRegression(C = 1.0, solver='liblinear'). See more of my findings in the Model Evaluation section of this Readme.
Methodology
To build a classification model to distinguish between Subreddit posts from r/TheOnion and r/nottheonion, I implemented a nonlinear data science workflow.
| Data Science Workflow | Description |
|---|---|
| Data Acquisition | Scrape ~15k posts from r/TheOnion & r/nottheonion, total of ~30k posts. Used pushshift.io API wrapper to acquire data. Clean the data. |
| Exploratory Data Analysis | Create data visualizations to observe trends about the data. What are distinguishing characteristics about each subreddit? |
| Natural Language Processing | Prepare text for modeling. Count Vectorize the data and analyze trends among posts. |
| Modeling | Using Pipeline and GridSearch, find the best combination of vectorizers and models to achieve the best accuracy when designating a post as either from r/TheOnion or r/nottheonion. |
Model Selection
Throug Pipeline and Gridsearch, I tested four sets of models with unique parameters. My best model in terms of highest accuracy score was Model 3. My best model in terms of coefficient interpretability was Model 1.
Model 1 | Best Coefficient Interpretability:
CountVectorizer(stop_words=None, ngram_range=(1,1))
LogisticRegression(C=1, solver='liblinear')
Train score 0.96Test score 0.87
Model 2:
TfidfVectorizer(max_df=0.75, min_df=3, n_gram=(1,3))
LogisticRegression(C=1, solver='liblinear')
Train score 0.92Test score 0.86
Model 3 | Best Accuracy Score:
CountVectorizer(stop_words=None, ngram_range=(1,3))
MultinomialNB(alpha=0.36)
Train score 0.997Test score 0.90
Model 4:
TfidfVectorizer(max_df = .75, min_df = 4, ngram_range=(1,2))
MultinomialNB(alpha=0.1)
Train score 0.92Test score 0.87
Model Evaluation
Below is a visualization of my confusion matrix for model 3, which reveals the values of True Positives, True Negatives, False Positives (Type I error), and False Negatives (Type II errors). I optimized my model to achieve the highest Accuracy score, and also measure the Positive Predictive Rate, True Positive Rate, True Negative Rate, and Misclassification Rate.

Additionally, I also used model 1 to help me interpret estimate values for my coefficients. I determined which words had the highest positive impact on determining whether a post would be classified as coming from r/TheOnion or r/nottheonion. I calculated the exponential of the coefficients to determine the likelihood of how a post gets classified.
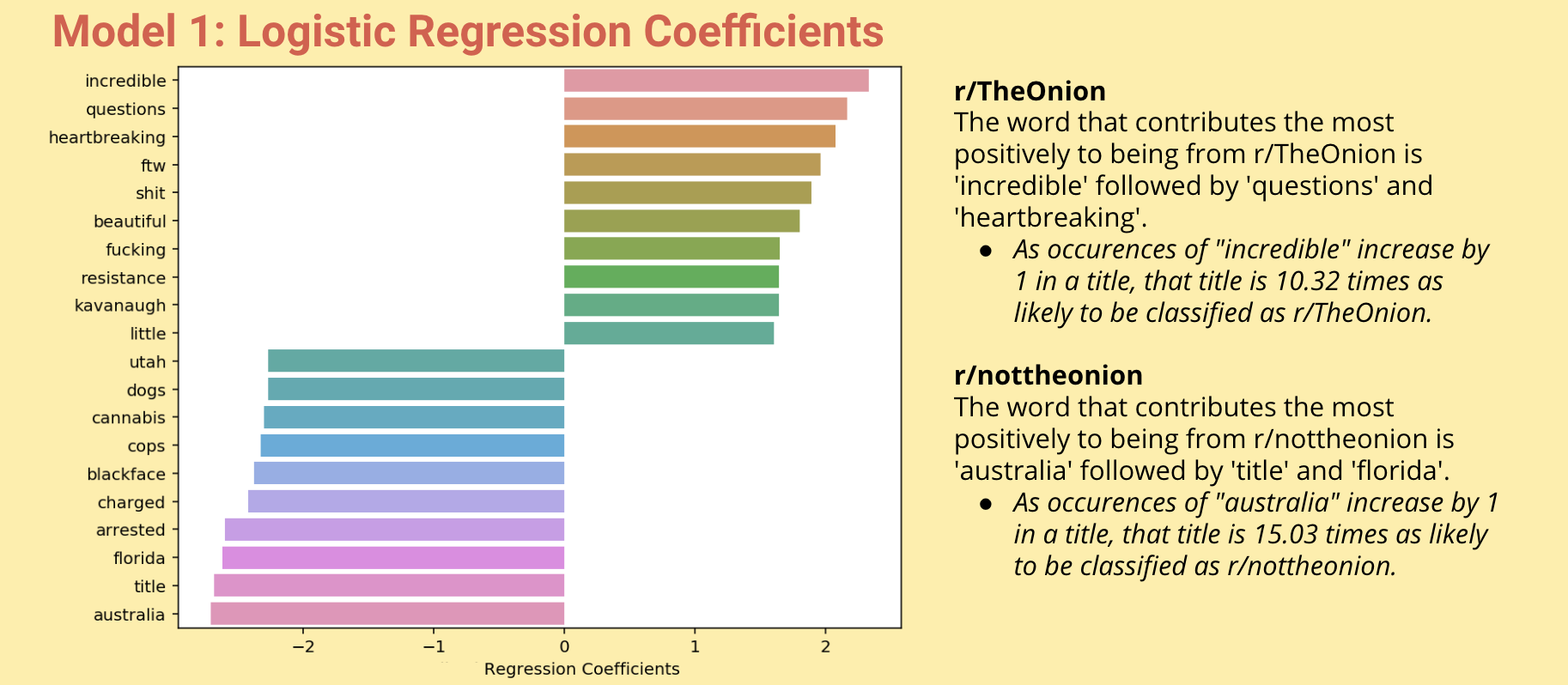
Conclusions and Next Steps
While I did achieve a high accuracy of around 90%, it's still not perfect. If WhatsApp were to implement this model when deleting 2 million accounts a month, they would be misclassifying about 10% - 11% of authentic accounts as fake ones. When implementing machine learning models to block, delete, or censor social media and messaging accounts, how many are misclassified? In my next iteration of this project, I would do more research on whether and how platforms like WhatsApp create fake news filters, and what their accuracy and misclassification scores are. Additionally, since news gets spread not only as text but also as images and videos, my next step would also be to research how to implement a machine learning model on multi-media objects.