This deployment is based on validated pattern framework that uses GitOps to easily provision all operators and apps. It deploys a Chatbot application that leverages the power of Large Language Models (LLMs) in conjunction with the Retrieval-Augmented Generation (RAG) framework running on Red Hat OpenShift to generate a project proposal for a given Red Hat product.
- Podman
- Red Hat Openshift cluster running in AWS. Supported regions are us-west-2 and us-east-1.
- GPU Node to run Hugging Face Text Generation Inference server on Red Hat OpenShift cluster.
- Create a fork of the rag-llm-gitops git repository.
The goal of this demo is to demonstrate a Chatbot LLM application augmented with data from Red Hat product documentation running on Red Hat OpenShift. It deploys an LLM application that connects to multiple LLM providers such as OpenAI, Hugging Face, and NVIDIA NIM. The application generates a project proposal for a Red Hat product
- LLM Application augmented with content from Red Hat product documentation.
- Multiple LLM providers (OpenAI, Hugging Face, NVIDIA)
- Vector Database, such as PGVECTOR or REDIS, to store embeddings of RedHat product documentation.
- Monitoring dashboard to provide key metrics such as ratings
- GitOps setup to deploy e2e demo (frontend / vector database / served models)

Figure 1. Overview of the validated pattern for RAG Demo with Red Hat OpenShift

Figure 2. Logical diagram of the RAG Demo with Red Hat OpenShift.

Figure 3. Schematic diagram for workflow of RAG demo with Red Hat OpenShift.

Figure 4. Schematic diagram for Ingestion of data for RAG.

Figure 5. Schematic diagram for RAG demo augmented query.
In Figure 5, we can see RAG augmented query. Llama 2 model is used for for language processing, LangChain to integrate different tools of the LLM-based application together and to process the PDF files and web pages, vector database such as PGVECTOR or REDIS, is used to store vectors, HuggingFace TGI is used to serve the Llama 2 model, Gradio is used for user interface and object storage to store language model and other datasets. Solution components are deployed as microservices in the Red Hat OpenShift cluster.
View and download all of the diagrams above in our open source tooling site.
 Figure 6. Proposed demo architecture with OpenShift AI
Figure 6. Proposed demo architecture with OpenShift AI
- Hugging Face Text Generation Inference Server: The pattern deploys a Hugging Face TGIS server. The server deploys
mistral-community/Mistral-7B-v0.2model. The server will require a GPU node. - EDB (PGVECTOR) / Redis Server: A Vector Database server is deployed to store vector embeddings created from Red Hat product documentation.
- Populate VectorDb Job: The job creates the embeddings and populates the vector database.
- LLM Application: This is a Chatbot application that can generate a project proposal by augmenting the LLM with the Red Hat product documentation stored in vector db.
- Prometheus: Deploys a prometheus instance to store the various metrics from the LLM application and TGIS server.
- Grafana: Deploys Grafana application to visualize the metrics.
git clone https://github.com/<<your-username>>/rag-llm-gitops.git
cd rag-llm-gitops
oc login --token=<> --server=<> # login to Openshift cluster
podman machine start
# Copy values-secret.yaml.template to ~/values-secret-rag-llm-gitops.yaml.
# You should never check-in these files
# Add secrets to the values-secret.yaml that needs to be added to the vault.
cp values-secret.yaml.template ~/values-secret-rag-llm-gitops.yamlAs a pre-requisite to deploy the application using the validated pattern, GPU nodes should be provisioned along with Node Feature Discovery Operator and NVIDIA GPU operator. To provision GPU Nodes
Following command will take about 5-10 minutes.
./pattern.sh make create-gpu-machinesetWait till the nodes are provisioned and running.

Alternatiely, follow the instructions to manually install GPU nodes, Node Feature Discovery Operator and NVIDIA GPU operator.
*Note:: This pattern supports two types of vector databases, PGVECTOR and REDIS. By default the pattern will deploy PGVECTOR as a vector DB. To deploy REDIS, change the global.db.type to REDIS in values-global.yaml.
---
global:
pattern: rag-llm-gitops
options:
useCSV: false
syncPolicy: Automatic
installPlanApproval: Automatic
# Possible value for db.type = [REDIS, PGVECTOR]
db:
index: docs
type: PGVECTOR <--- Default is PGVECTOR, Change the db type to REDIS for REDIS deployment
main:
clusterGroupName: hub
multiSourceConfig:
enabled: trueFollowing commands will take about 15-20 minutes
Validated pattern will be deployed
./pattern.sh make install- Login to the OpenShift web console.
- Navigate to the Workloads --> Pods.
- Select the
rag-llmproject from the drop down. - Following pods should be up and running.

Note: If the hf-text-generation-server is not running, make sure you have followed the steps to configure a node with GPU from the instructions provided above.
- Click the
Application boxicon in the header, and selectRetrieval-Augmented-Generation (RAG) LLM Demonstration UI

-
It should launch the application
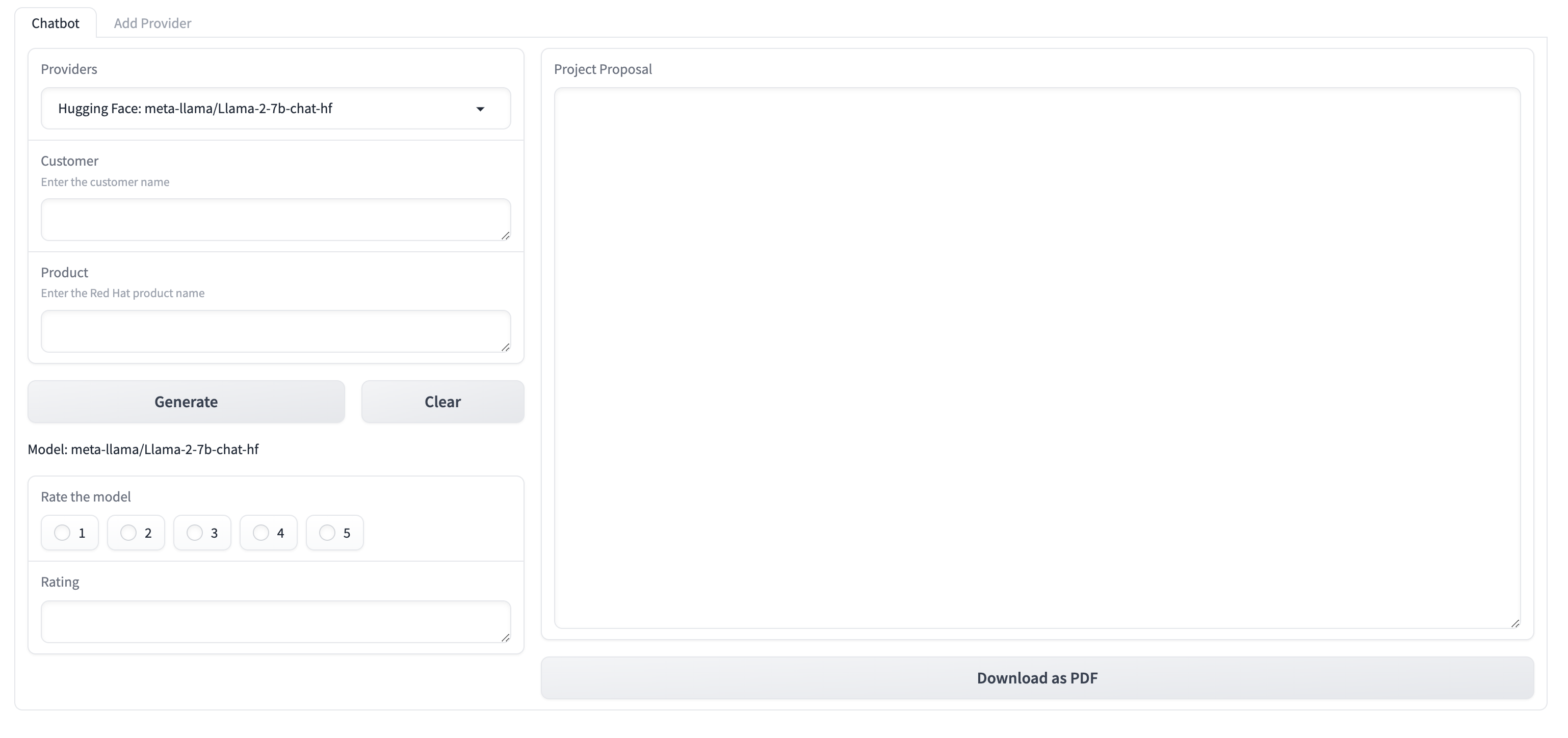

-
It will use the default provider and model configured as part of the application deployment. The default provider is a Hugging Face model server running in the OpenShift. The model server is deployed with this valdiated pattern and requires a node with GPU.
-
Enter any company name
-
Enter the product as
RedHat OpenShift -
Click the
Generatebutton, a project proposal should be generated. The project proposal also contains the reference of the RAG content. The project proposal document can be Downloaded in the form of a PDF document.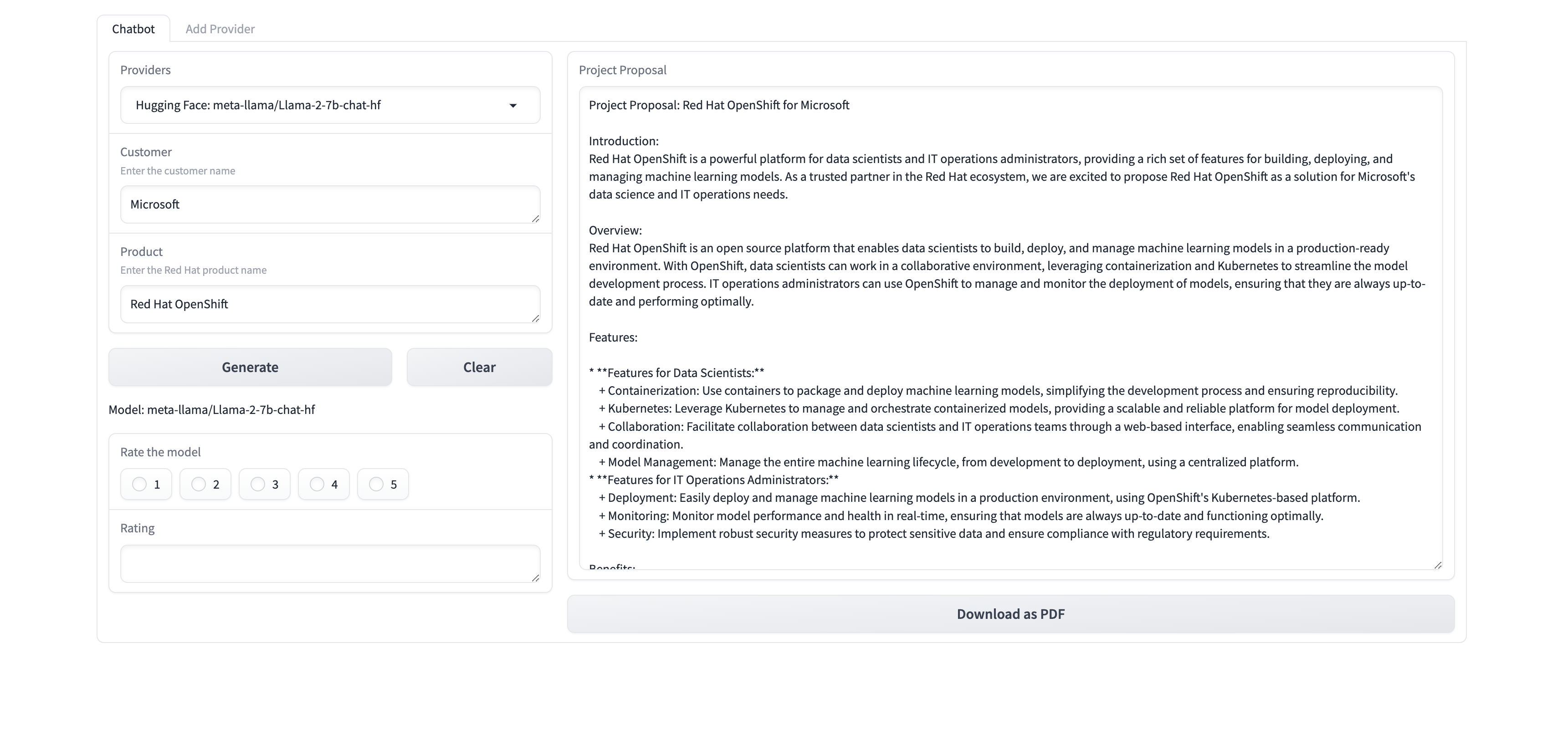

You can optionally add additional providers. The application supports the following providers
- Hugging Face Text Generation Inference Server
- OpenAI
- NVIDIA
Click on the Add Provider tab to add a new provider. Fill in the details and click Add Provider button. The provider should be added in the Providers dropdown uder Chatbot tab.

Follow the instructions in step 3 to generate the proposal document using the OpenAI provider.

You can provide rating to the model by clicking on the Rate the model radio button. The rating will be captured as part of the metrics and can help the company which model to deploy in prodcution.
By default, Grafana application is deployed in llm-monitoring namespace.To launch the Grafana Dashboard, follow the instructions below:
- Grab the credentials of Grafana Application
- Navigate to Workloads --> Secrets
- Click on the grafana-admin-credentials and copy the GF_SECURITY_ADMIN_USER, GF_SECURITY_ADMIN_PASSWORD
- Launch Grafana Dashboard
- Click the
Application boxicon in the header, and selectGrafana UI for LLM ratings
- Enter the Grafana admin credentials.
- Ratings are displayed for each model.
- Click the

GOTO: Test Plan