NVIDIA Jetson Nvidia Jetson Nano, Xavier NX, Orin Deployment tutorial
AyushExel opened this issue · comments

Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
This guide explains how to deploy a trained model into NVIDIA Jetson Platform and perform inference using TensorRT and DeepStream SDK. Here we use TensorRT to maximize the inference performance on the Jetson platform. UPDATED 18 November 2022.
Hardware Verification
We have tested and verified this guide on the following Jetson devices
- Seeed reComputer J1010 built with Jetson Nano module
- Seeed reComputer J2021 built with Jetson Xavier NX module
Before You Start
Make sure you have properly installed JetPack SDK with all the SDK Components and DeepStream SDK on the Jetson device as this includes CUDA, TensorRT and DeepStream SDK which are needed for this guide.
JetPack SDK provides a full development environment for hardware-accelerated AI-at-the-edge development. All Jetson modules and developer kits are supported by JetPack SDK.
There are two major installation methods including,
- SD Card Image Method
- NVIDIA SDK Manager Method
You can find a very detailed installation guide from NVIDIA official website. Also you can find guides corresponding to the above-mentioned reComputer J1010 and reComputer J2021.
Install Necessary Packages
- Step 1. Access the terminal of Jetson device, install pip and upgrade it
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip- Step 2. Clone the following repo
git clone https://github.com/ultralytics/yolov5- Step 3. Open requirements.txt
cd yolov5
vi requirements.txt- Step 5. Edit the following lines. Here you need to press i first to enter editing mode. Press ESC, then type :wq to save and quit
# torch>=1.7.0
# torchvision>=0.8.1Note: torch and torchvision are excluded for now because they will be installed later.
- Step 6. install the below dependency
sudo apt install -y libfreetype6-dev- Step 7. Install the necessary packages
pip3 install -r requirements.txtInstall PyTorch and Torchvision
We cannot install PyTorch and Torchvision from pip because they are not compatible to run on Jetson platform which is based on ARM aarch64 architecture. Therefore we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.
Visit this page to access all the PyTorch and Torchvision links.
Here are some of the versions supported by JetPack 4.6 and above.
PyTorch v1.10.0
Supported by JetPack 4.4 (L4T R32.4.3) / JetPack 4.4.1 (L4T R32.4.4) / JetPack 4.5 (L4T R32.5.0) / JetPack 4.5.1 (L4T R32.5.1) / JetPack 4.6 (L4T R32.6.1) with Python 3.6
file_name: torch-1.10.0-cp36-cp36m-linux_aarch64.whl
URL: https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl
PyTorch v1.12.0
Supported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8
file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Step 1. Install torch according to your JetPack version in the following format
wget <URL> -O <file_name>
pip3 install <file_name>For example, here we are running JP4.6.1 and therefore we choose PyTorch v1.10.0
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl- Step 2. Install torchvision depending on the version of PyTorch that you have installed. For example, we chose PyTorch v1.10.0, which means, we need to choose Torchvision v0.11.1
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.11.1 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install Here a list of the corresponding torchvision version that you need to install according to the PyTorch version:
- PyTorch v1.10 - torchvision v0.11.1
- PyTorch v1.12 - torchvision v0.13.0
DeepStream Configuration for YOLOv5
- Step 1. Clone the following repo
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo- Step 2. Copy gen_wts_yoloV5.py from DeepStream-Yolo/utils into yolov5 directory
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5- Step 3. Inside the yolov5 repo, download pt file from YOLOv5 releases (example for YOLOv5s 6.1)
cd yolov5
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt- Step 4. Generate the cfg and wts files
python3 gen_wts_yoloV5.py -w yolov5s.ptNote: To change the inference size (defaut: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280- Step 5. Copy the generated cfg and wts files into the DeepStream-Yolo folder
cp yolov5s.cfg ~/DeepStream-Yolo
cp yolov5s.wts ~/DeepStream-Yolo- Step 6. Open the DeepStream-Yolo folder and compile the library
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0- Step 7. Edit the config_infer_primary_yoloV5.txt file according to your model
[property]
...
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
...- Step 8. Edit the deepstream_app_config file
...
[primary-gie]
...
config-file=config_infer_primary_yoloV5.txt- Step 9. Change the video source in deepstream_app_config file. Here a default video file is loaded as you can see below
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4Run the Inference
deepstream-app -c deepstream_app_config.txt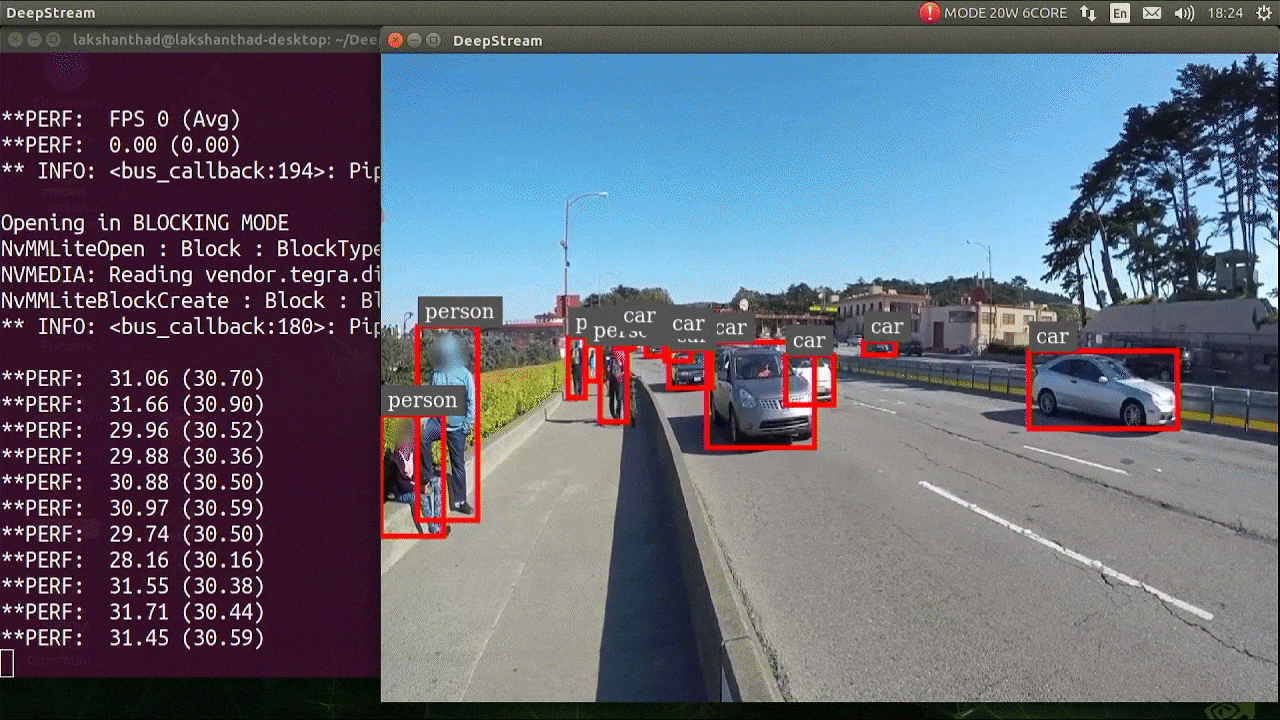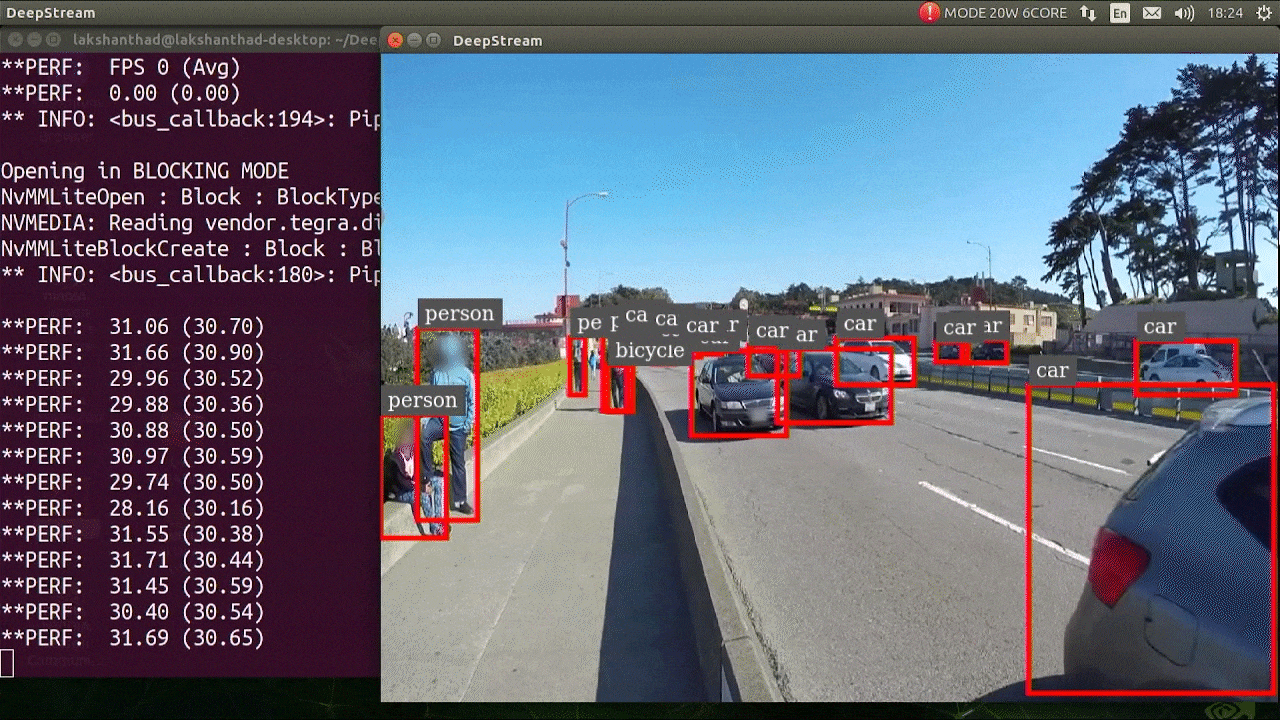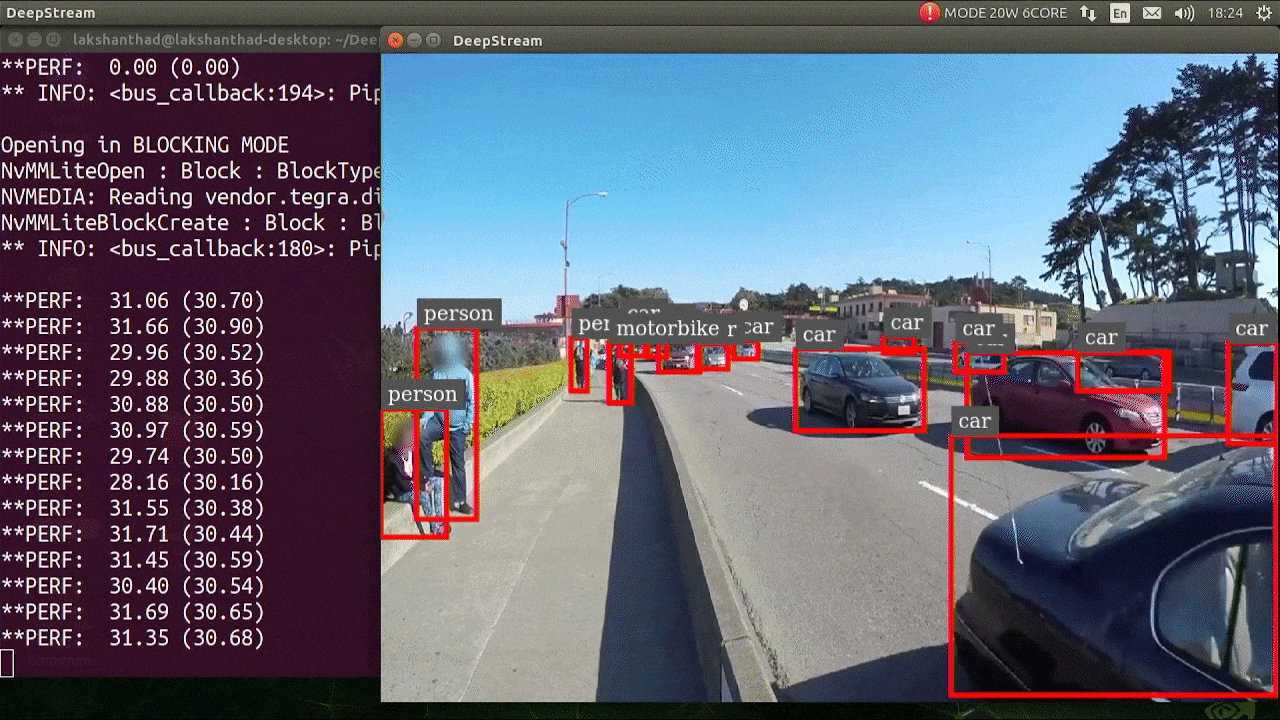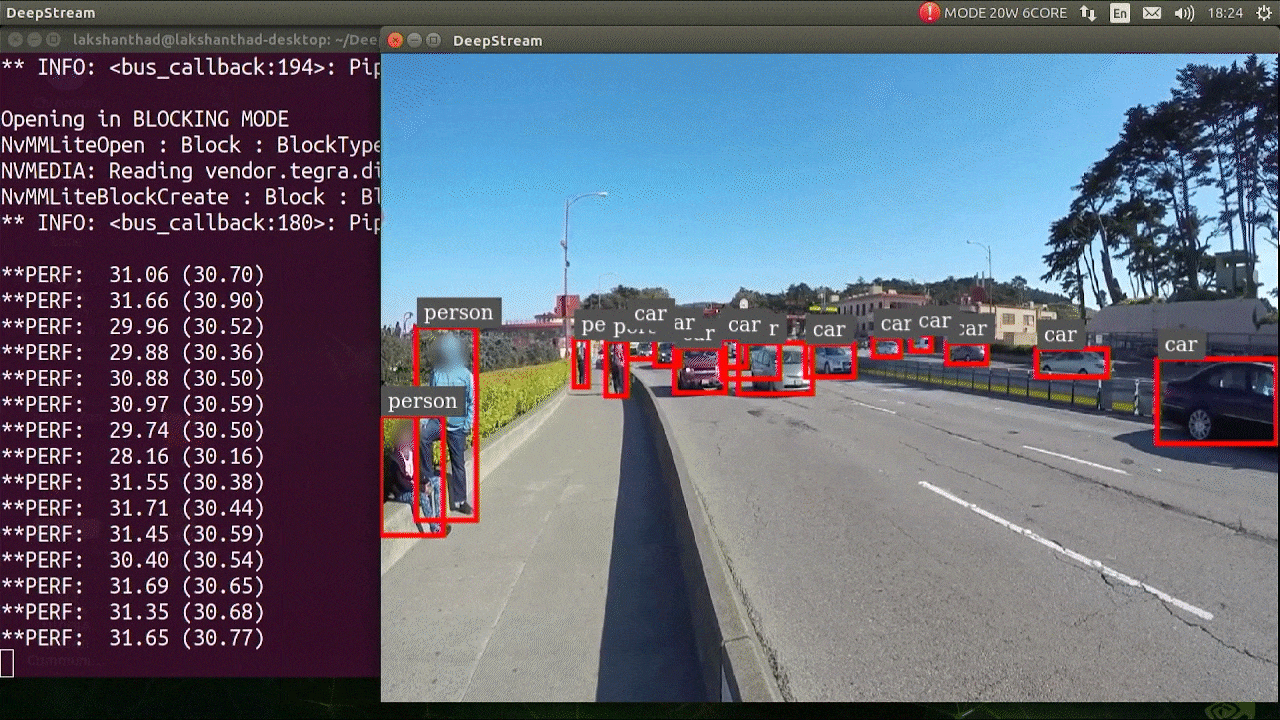
The above result is running on Jetson Xavier NX with FP32 and YOLOv5s 640x640. We can see that the FPS is around 30.
INT8 Calibration
If you want to use INT8 precision for inference, you need to follow the steps below
- Step 1. Install OpenCV
sudo apt-get install libopencv-dev- Step 2. Compile/recompile the nvdsinfer_custom_impl_Yolo library with OpenCV support
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0-
Step 3. For COCO dataset, download the val2017, extract, and move to DeepStream-Yolo folder
-
Step 4. Make a new directory for calibration images
mkdir calibration- Step 5. Run the following to select 1000 random images from COCO dataset to run calibration
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
doneNote: NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from head -1000. For example, for 2000 images, head -2000. This process can take a long time.
- Step 6. Create the calibration.txt file with all selected images
realpath calibration/*jpg > calibration.txt- Step 7. Set environment variables
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1- Step 8. Update the config_infer_primary_yoloV5.txt file
From
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...To
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...- Step 9. Run the inference
deepstream-app -c deepstream_app_config.txt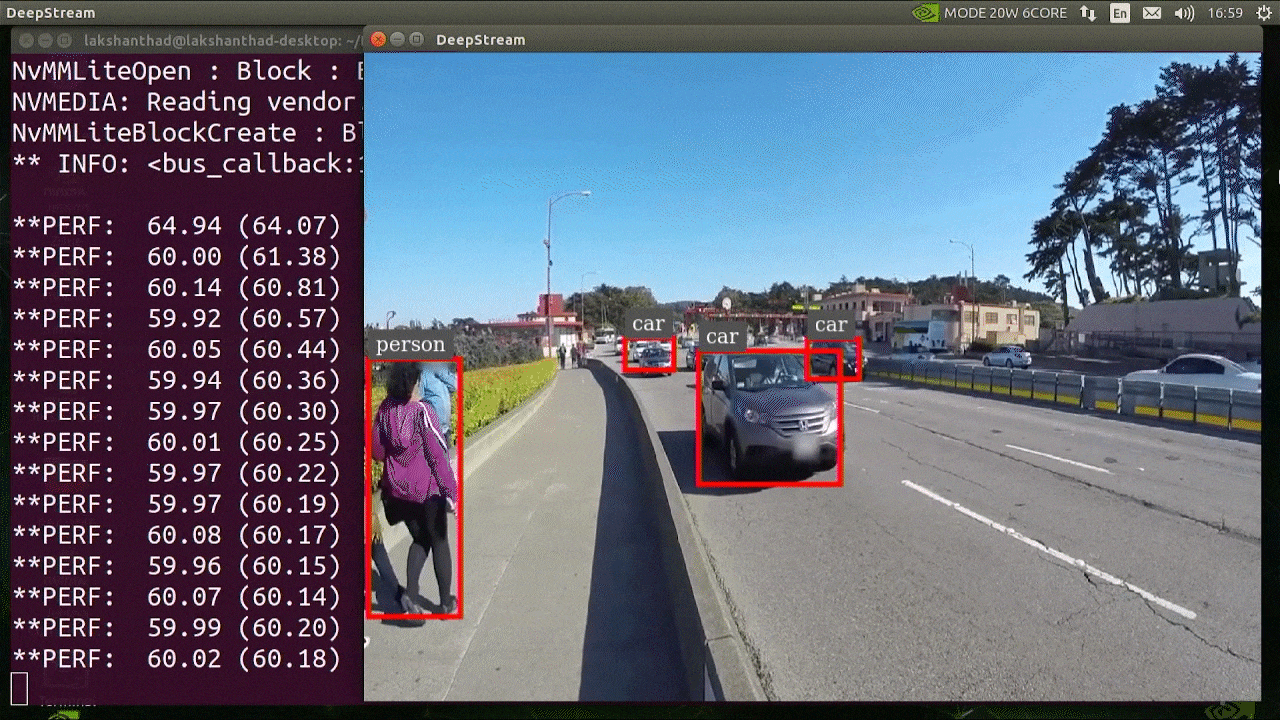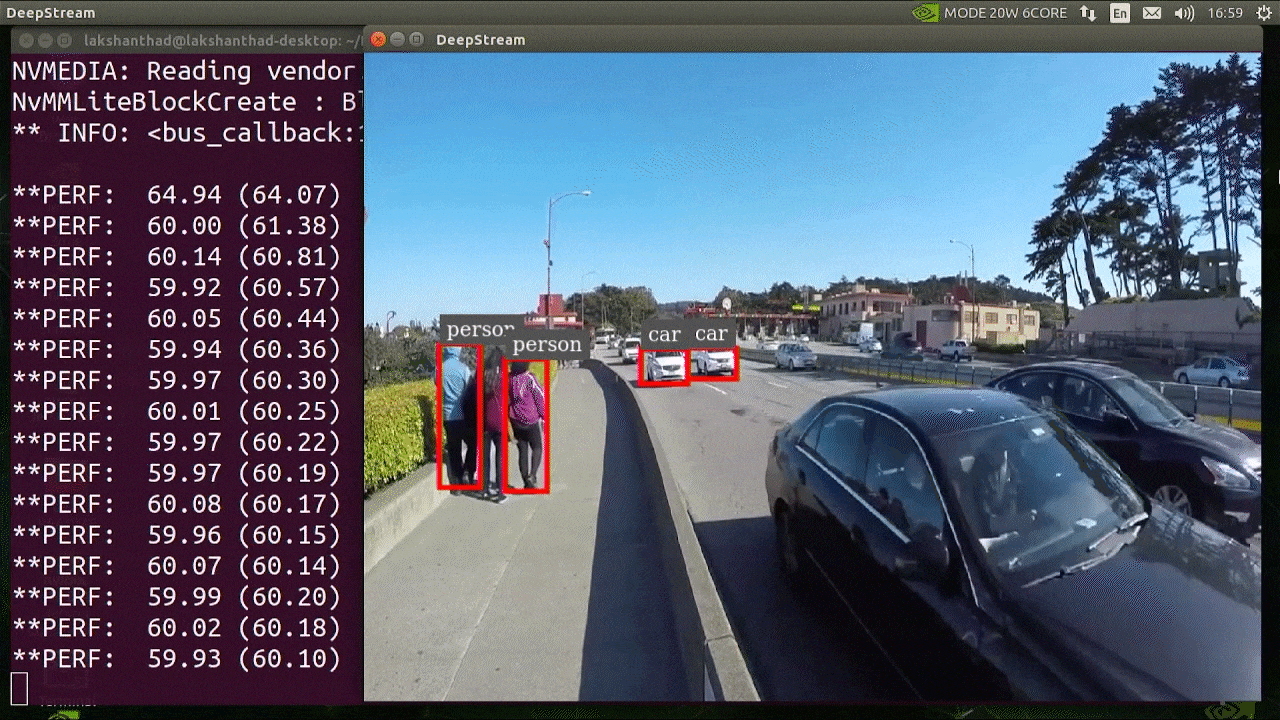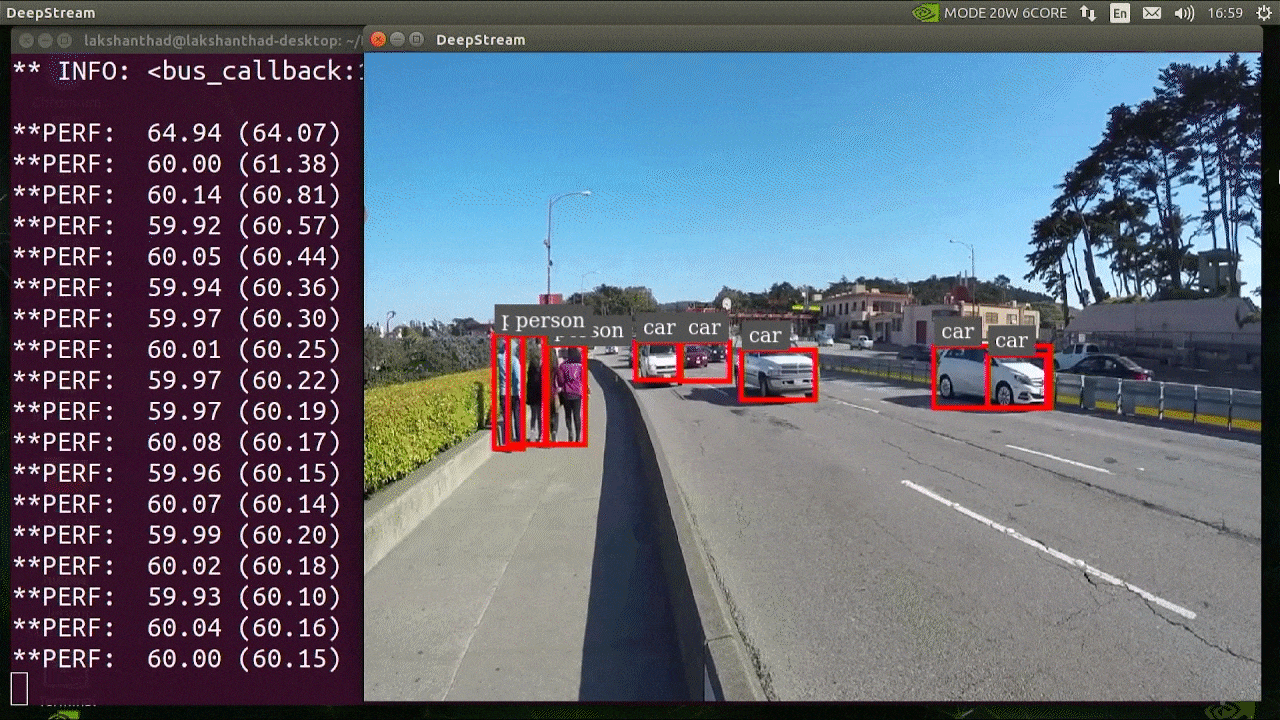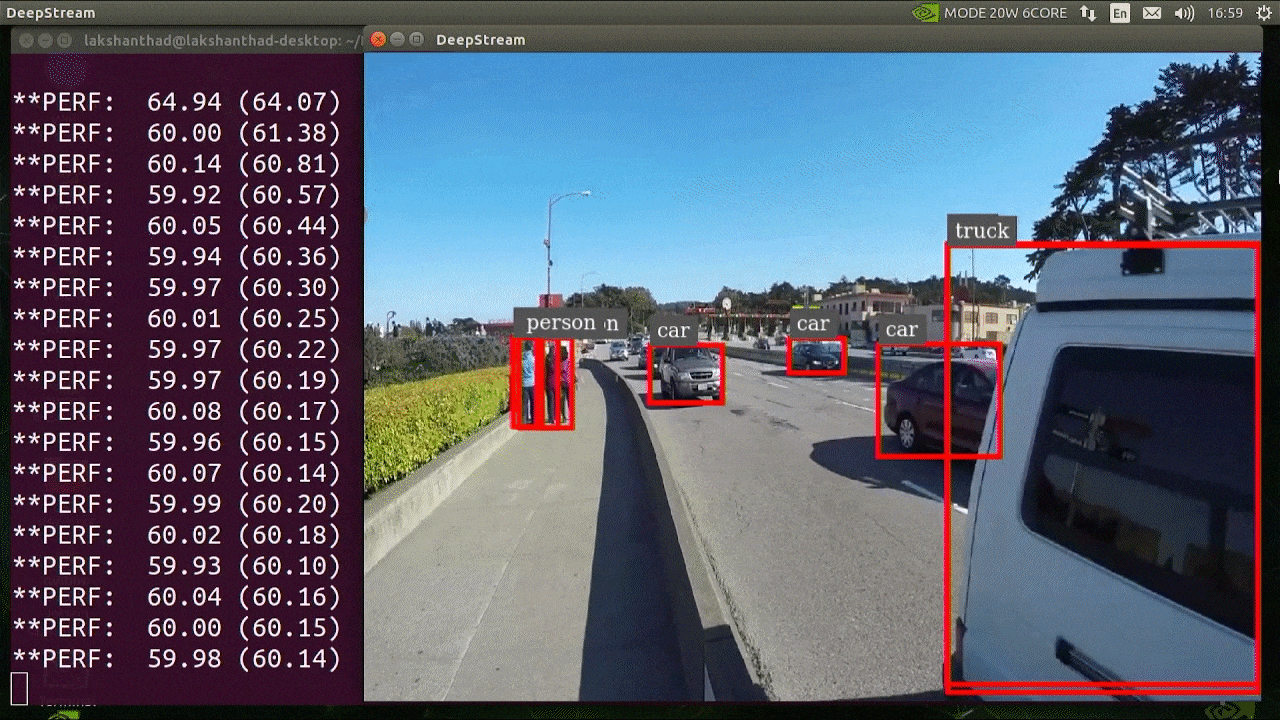
The above result is running on Jetson Xavier NX with INT8 and YOLOv5s 640x640. We can see that the FPS is around 60.
Benchmark results
The following table summarizes how different models perform on Jetson Xavier NX.
| Model Name | Precision | Inference Size | Inference Time (ms) | FPS |
|---|---|---|---|---|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
| FP32 | 640x640 | 33.33 | 30 | |
| INT8 | 640x640 | 16.66 | 60 | |
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
Additional
This tutorial is written by our friends at seeed @lakshanthad and Elaine

@AyushExel awesome! Should this be renamed to something like NVIDIA Jetson Nano deployment tutorial?
@glenn-jocher yeah. "Nvidia Jetson Nano deployment tutorial sounds good".
And maybe just pin or add to wikis?
@AyushExel awesome, added to wiki. I think I'll add to README also. Are those times in the last table right BTW?
@glenn-jocher yes. It's also mentioned here - https://wiki.seeedstudio.com/YOLOv5-Object-Detection-Jetson/


thanks for the great documentation @AyushExel
I'll give it a try in the next day or two
Hi @AyushExel
For step 4.
python3 gen_wts_yoloV5.py -w yolov5s.pt I get an error Illegal instruction (core dumped)
I'm using a Seeed reComputer J1010 (Jetson Nano) with Jetpack 4.6.2 and I've tried a couple of times with a fresh flash of the Jetson each time.
I noticed that YoloV5 requires Python 3.7, whereas Jetpack 4.6.2 includes Python 3.6.9, so I used YoloV5 v6.0 (and v6.2 initially)
EDIT: also tried JP4.6.1 (same result)
thanks in advance
Andrew
@lakshanthad do you know what's causing this?
thanks @AyushExel
I've found the crash report (which I can send to you or @lakshanthad)
It's pretty big- around 9mb
I also noticed the SeeedStudio article here: similar/the same?
https://wiki.seeedstudio.com/YOLOv5-Object-Detection-Jetson/
I haven't tried this yet- its a bit more complicated
The first 10 lines are:
ProblemType: Crash
Architecture: arm64
CrashCounter: 1
Date: Tue Oct 11 18:06:08 2022
DistroRelease: Ubuntu 18.04
ExecutablePath: /usr/bin/python3.6
ExecutableTimestamp: 1656503157
ProcAttrCurrent: Error: [Errno 22] Invalid argument
ProcCmdline: python3 gen_wts_yoloV5.py -w yolov5s.pt
ProcCwd: /home/nano/yolov5

Hello @barney2074,
Can I know exactly after which command you encounter this crash? And please attach the report here if possible.
I also noticed the SeeedStudio article here: similar/the same?
https://wiki.seeedstudio.com/YOLOv5-Object-Detection-Jetson/
Yes. Most content on this GitHub is based on that wiki. That wiki mainly explains the entire process from labeling to deploying
Hi @lakshanthad
This occurs after the command **python3 gen_wts_yoloV5.py -w yolov5s.pt**
I've put the crash report here: https://drive.google.com/drive/folders/14bu_dNwQ9VbBLMKDBw92t0vUc3e9Rh00?usp=sharing
I have also tried the Seeed wiki- I'll put outcome in a separate post to avoid confusing the issue
thanks
Andrew
Hi @lakshanthad
At step 19 of the Seeed wiki (serialising the model) I get the following error:
I've tried a few different models, including https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt and some custom ones
nano@ubuntu:~/tensorrtx/yolov5/build$ sudo ./yolov5 -s best.wts best.engine n6
Loading weights: best.wts
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: (Unnamed Layer* 0) [Convolution]:kernel weights has count 3456 but 1728 was expected
[10/12/2022-09:55:05] [E] [TRT] 4: (Unnamed Layer* 0) [Convolution]: count of 3456 weights in kernel, but kernel dimensions (6,6) with 3 input channels, 16 output channels and 1 groups were specified. Expected Weights count is 3 * 6*6 * 16 / 1 = 1728
[10/12/2022-09:55:05] [E] [TRT] 4: [convolutionNode.cpp::computeOutputExtents::39] Error Code 4: Internal Error ((Unnamed Layer* 0) [Convolution]: number of kernel weights does not match tensor dimensions)
[10/12/2022-09:55:05] [E] [TRT] 3: [network.cpp::addScale::737] Error Code 3: API Usage Error (Parameter check failed at: optimizer/api/network.cpp::addScale::737, condition: shift.count > 0 ? (shift.values != nullptr) : (shift.values == nullptr)
)
yolov5: /home/nano/tensorrtx/yolov5/common.hpp:153: nvinfer1::IScaleLayer* addBatchNorm2d(nvinfer1::INetworkDefinition*, std::map<std::__cxx11::basic_string<char>, nvinfer1::Weights>&, nvinfer1::ITensor&, std::__cxx11::string, float): Assertion `scale_1' failed.
Aborted
nano@ubuntu:~/tensorrtx/yolov5/build$

@barney2074
I had the same issue too in Jetson-nano b01 dev. It is solved by setting the following environment variable:
export OPENBLAS_CORETYPE=ARMV8
But after that, a problem occurs when building deepstream.
dinobei@dinobei-desktop:~/DeepStream-Yolo$ CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo
make: Entering directory '/home/dinobei/DeepStream-Yolo/nvdsinfer_custom_impl_Yolo'
g++ -c -o yolo.o -Wall -std=c++11 -shared -fPIC -Wno-error=deprecated-declarations -I/opt/nvidia/deepstream/deepstream/sources/includes -I/usr/local/cuda-10.2/include yolo.cpp
In file included from yolo.cpp:26:0:
yolo.h:44:10: fatal error: nvdsinfer_custom_impl.h: No such file or directory
#include "nvdsinfer_custom_impl.h"
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Makefile:70: recipe for target 'yolo.o' failed
make: *** [yolo.o] Error 1
make: Leaving directory '/home/dinobei/DeepStream-Yolo/nvdsinfer_custom_impl_Yolo'
Thanks @dinobei
One step forward....
I'm not sure if deploying Yolov5 models on Jetson hardware is inherently tricky- but from my perspective, it would be great if there was an easier path.
Andrew
@lakshanthad do you know what's happening in this error? I seems like its originating from deepstream-yolo module. Is there a way to run this without that?
@barney2074 I haven't had time to try it out on my nano yet so I'm not of much help here. I'll try it out soon
Hello,
Sorry for the late reply. Can I know how DeepStream was installed in the first place? @dinobei @barney2074. Sometimes improper DeepStream installations can cause errors later on.
It is recommended to choose it inside NVIDIA SDK Manager when installing JetPack. Because this ensures that there will be no compatibility or missing dependency issues.

Thanks @dinobei
One step forward.... I'm not sure if deploying Yolov5 models on Jetson hardware is inherently tricky- but from my perspective, it would be great if there was an easier path.
Andrew
Well. If you just want to deploy, you can use the pre-trained PyTorch model to perform the inference. In this case, follow until and including the Install PyTorch and Torchvision section in the above guide. After that, execute python detect.py --source <video_source>. But the goal of this document is to use TensorRT to increase performance on the Jetson platform. And to use TensorRT with a video stream, DeepStream SDK is used.
So there are 2 ways of deployment on Jetson.
- Without TensorRT
- With TensoRT and DeepStream SDK
The first method is the fastest deployment. However, the second method ensures the model performance is better on the Jetson hardware compared with the first method.
I think this document can be divided into two.
- Without TensorRT (fastest deployment)
- With TensorRT and DeepStream SDK (takes some time to deploy)
Any suggestions? I can work to reorganize it as above and update this guide.
@lakshanthad
thank you for reply.
What about TensorRT without DeepStream?
Is using TensorRT and DeepStream SDKs faster than using TensorRT alone? (model performance)
Hello, Sorry for the late reply. Can I know how DeepStream was installed in the first place? @dinobei @barney2074. Sometimes improper DeepStream installations can cause errors later on.
It is recommended to choose it inside NVIDIA SDK Manager when installing JetPack. Because this ensures that there will be no compatibility or missing dependency issues.
I made a huge mistake. I didn't install DeepStream SDK. I thought DeepStream-Yolo and DeepStream SDK are the same.
Currently, JetPack was installed by SDcard image method, I will try reinstalling it with NVIDIA SDK Manager and share the results.
Can I know how DeepStream was installed in the first place
Hi @lakshanthad
I installed using SDKManager, and did an OS flash at the same time i.e a completely 'fresh' system.
I'm aiming to get my custom YoloV5 model running on the Jetson, although I tried yolov5s.pt as a test to try to eliminate the problem i.e it is not just my custom model
Just to clarify my understanding: the TensorRT .engine needs to be generated on the same processor architecture as used for inferencing. i.e can't generate it on an x86/RTX machine and run inferencing on an ARM (Jetson) one ??
Andrew
Hello, Sorry for the late reply. Can I know how DeepStream was installed in the first place? @dinobei @barney2074. Sometimes improper DeepStream installations can cause errors later on.
It is recommended to choose it inside NVIDIA SDK Manager when installing JetPack. Because this ensures that there will be no compatibility or missing dependency issues.I made a huge mistake. I didn't install DeepStream SDK. I thought DeepStream-Yolo and DeepStream SDK are the same. Currently, JetPack was installed by SDcard image method, I will try reinstalling it with NVIDIA SDK Manager and share the results.
Yes. Please try again and share your results.
Can I know how DeepStream was installed in the first place
Hi @lakshanthad I installed using SDKManager, and did an OS flash at the same time i.e a completely 'fresh' system.
I'm aiming to get my custom YoloV5 model running on the Jetson, although I tried yolov5s.pt as a test to try to eliminate the problem i.e it is not just my custom model
Just to clarify my understanding: the TensorRT .engine needs to be generated on the same processor architecture as used for inferencing. i.e can't generate it on an x86/RTX machine and run inferencing on an ARM (Jetson) one ??
Andrew
Yes, you are right. The .engine file should be generated on the same processor architecture as used for inferencing. It also means serializing and deserializing should be done on the same architecture. When you use DeepStream SDK as mentioned in this guide, after you run deepstream-app -c deepstream_app_config.txt, it will first serialize the model (generate .engine) and then after sometime deserialize the model to do the inferencing.
However, the guide that you found out on Seeed wiki that you mentioned earlier, when only TensorRT is used without DeepStream SDK, you need to manually do this serialize and deserialize work.
Coming back to the issues you are still facing, is any of the issues you mentioned before solved, or do they still exist?
Could we debug like this? First try without TensorRT.
- At the beginning of this GitHub page, go through
Install Necessary PackagesandInstall PyTorch and Torchvision - Execute
python3 detect.py --source <video_source>that will useyolov5s.ptas the default model for inference
Please let me know whether this works at first.
@lakshanthad thank you for reply. What about TensorRT without DeepStream? Is using TensorRT and DeepStream SDKs faster than using TensorRT alone? (model performance)
There is no big difference. The way to use only TensorRT is this. However, there is no example present to view detection on real-time video. The repo only supports image inferencing at the moment. DeepStream SDK comes with real-time video detection support. However, if you are comfortable with maybe OpenCV, it could be possible to grab the video frames as images using OpenCV and do the inferencing while only using the TensorRT Github mentioned before.
@glenn-jocher yeah. "Nvidia Jetson Nano deployment tutorial sounds good". And maybe just pin or add to wikis?
@glenn-jocher @AyushExel Could we change the title to "NVIDIA Jetson Platform Deployment"? It is better to have a common name rather than only "Jetson Nano".
Thank you.
2. Execute
python3 detect.py --source <video_source>that will useyolov5s.ptas the default model for inference
Hi @lakshanthad
Yes, detect.py does work (real slow....) on my Jetson Nano
As I noted before- YoloV5 v6.2 requires Python >= 3.7.0, so I used YoloV5 v6.0
git clone https://github.com/ultralytics/yolov5 --branch v6.0
thanks
Andrew


Using Jetpack 4.6.2 on the Jetson Nano. Faced the same issue as @barney2074 despite installing everything with the NVIDIA SDK Manager. The core dumped error starts popping up when installing torchvision. Unfortunately, the fix suggested by @dinobei did not work for me.
What did work for me, however, was downgrading Numpy from 1.19.5 to 1.19.4. I do not remember where exactly I read something about that creating problems, so cannot provide a source, but it worked. Posting this here incase someone else runs into the same issue.
many thanks for the info- I don't have the device to hand, but will try it next week & report back
Andrew
@glenn-jocher yeah. "Nvidia Jetson Nano deployment tutorial sounds good". And maybe just pin or add to wikis?
@glenn-jocher @AyushExel Could we change the title to "NVIDIA Jetson Platform Deployment"? It is better to have a common name rather than only "Jetson Nano".
Thank you.
Didn't see this before. I'll make a PR to do this
I've revisited this now that I've got some more time & also a different device
(proper dev kit version, rather than the Seeed version with limited memory)
I have made some progress- I had to vary from the instructions a bit to get this far & have taken some notes- I can provide this if it helps
The current status is:
- deepstream app working with yolov5 model. I've played around with it and go it working with a camera rather than mp4. I wouldn't say the performance is brilliant (around 5fps at 640x480)
- running yolov5 directly does work, but is incredibly slow. It seems to recognise the GPU- but does not use it at all. In fact, inferencing with the CPU is faster- refer below screenshot. Is this what you would expect ??


It would be great to have a tutorial on editing the deepstream config to use a custom yolov5 model
I think converting to .engine is fairly clear using export.py but the it looks like the settings in the config file, label file etc need to be altered
[property]
gpu-id=0
net-scale-factor=0.0039215697906911373
model-color-format=0
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
labelfile-path=labels.txt
batch-size=1
network-mode=0
num-detected-classes=80
interval=0
gie-unique-id=1
process-mode=1
network-type=0
cluster-mode=2
maintain-aspect-ratio=1
parse-bbox-func-name=NvDsInferParseYolo
custom-lib-path=nvdsinfer_custom_impl_Yolo/libnvdsinfer_custom_impl_Yolo.so
engine-create-func-name=NvDsInferYoloCudaEngineGet
[class-attrs-all]
nms-iou-threshold=0.45
pre-cluster-threshold=0.25
topk=300

Hello everyone,
Thank you @AyushExel and @glenn-jocher, it is a great tutorial about yolov5 on Jetson devices.
I am running my Jetson Orin on Jetpack 5.0.1-b118 and CUDA11.4. I have pull the docker of Yolove-latest-arm64. The training on the docker is working good, but it can only train on CPU. I have tried to set --device=0 (for GPU on Orin). However, the docker cannot detect CUDA on the Orin. I have tried to uninstall the newest Pytorch version and try with the PyTorch v1.12.0
and install by the .whl file.
However, the docker container with pytorch still cannot define the CUDA on the Orin. Do you have any idea or thought about this problem?
Thank you so much.
@Iongng198 are you running your docker command with --gpus all? See Dockerfile for common (not jetson-specific) Docker usage examples:
yolov5/utils/docker/Dockerfile
Lines 40 to 41 in e40662f
@glenn-jocher Yes, I pulled and run the docker with --gpus all, but it still cannot detect the CUDA. I have tried on both Nvidia Jetson Nano and Nvidia Orin. The version of yolov5, which I was pulling is ultralytics/yolov5:latest-arm64 as the adm64 is not compatible with the Nvidia devices.

Here is the image I have tried on Jetson Nano with ultralytics/yolov5:latest-arm64

Hey !
I was testing out this tutorial on a docker container as I dont have access to the Jetson board right now.
I was using the image: nvcr.io/nvidia/pytorch:22.10-py3
I followed all the steps except the torch and torchvision part. By default the docker image ships with torch==1.13.0
The error
root@d202a4fe2857:/workspace/yolov5# python3 gen_wts_yoloV5.py -w yolov5s.pt
Traceback (most recent call last):
File "gen_wts_yoloV5.py", line 5, in
from utils.torch_utils import select_device
File "/workspace/yolov5/utils/torch_utils.py", line 22, in
from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
File "/workspace/yolov5/utils/general.py", line 30, in
import cv2
File "/opt/conda/lib/python3.8/site-packages/cv2/init.py", line 181, in
bootstrap()
File "/opt/conda/lib/python3.8/site-packages/cv2/init.py", line 175, in bootstrap
if __load_extra_py_code_for_module("cv2", submodule, DEBUG):
File "/opt/conda/lib/python3.8/site-packages/cv2/init.py", line 28, in __load_extra_py_code_for_module
py_module = importlib.import_module(module_name)
File "/opt/conda/lib/python3.8/importlib/init.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/opt/conda/lib/python3.8/site-packages/cv2/gapi/init.py", line 290, in
cv.gapi.wip.GStreamerPipeline = cv.gapi_wip_gst_GStreamerPipeline
AttributeError: partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline' (most likely due to a circular import)
Is this expected on a docker system?
AttributeError: partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline' (most likely due to a circular import)
A simple google search solved the issue
https://stackoverflow.com/questions/72706073/attributeerror-partially-initialized-module-cv2-has-no-attribute-gapi-wip-gs
Followed by
https://stackoverflow.com/questions/55313610/importerror-libgl-so-1-cannot-open-shared-object-file-no-such-file-or-directo
Hey !
I was testing out this tutorial on a docker container as I dont have access to the Jetson board right now.
I was using the image: nvcr.io/nvidia/pytorch:22.10-py3
Im getting this error on step 6 of DeepStream configuration
root@d202a4fe2857:/workspace/DeepStream-Yolo# CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo
make: Entering directory '/workspace/DeepStream-Yolo/nvdsinfer_custom_impl_Yolo'
g++ -c -o nvdsinfer_yolo_engine.o -Wall -std=c++11 -shared -fPIC -Wno-error=deprecated-declarations -I/opt/nvidia/deepstream/deepstream/sources/includes -I/usr/local/cuda-11.4/include nvdsinfer_yolo_engine.cpp
nvdsinfer_yolo_engine.cpp:26:10: fatal error: nvdsinfer_custom_impl.h: No such file or directory
26 | #include "nvdsinfer_custom_impl.h"
| ^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
make: *** [Makefile:70: nvdsinfer_yolo_engine.o] Error 1
CUDA version
root@d202a4fe2857:/workspace/DeepStream-Yolo# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
root@d202a4fe2857:/workspace/DeepStream-Yolo#
I think its failing as deepstream may not be included in this container. Any resources on how to set that up is appreciated

Good news! I just deploy yolov5s(6.2) in Jetson Nano, about 10 fps with trt, and 7 fps with torch.
what size image/video?
I have been working with the YoloV5-v6.1 models extensively on the Jetson Nano and performed quite a few benchmarking experiments to select which network to deploy. In my setup, I do not use Deepstream for inference, but instead run it in real-time using a USB camera with OpenCV. My setup is running with JetPack 4.6.2 SDK, CuDNN 8.2.1, TensorRT 8.2.1.8, CUDA 10.2.300, PyTorch v1.10.0, Torchvision v0.11.1, python 3.6.9, numpy v1.19.4.
My FPS calculation is not based only on inference, but on complete loop time - so that would include preprocess + inference + the NMS stage. The FPS calculation is averaged over all loop times. These figures are not meant to be exact, but only indicative - so please do not consider them to be extremely accurate, however this was enough for my use-case.
P.S - When exporting TensorRT models, make sure the fan on the Nano is switched on for optimum performance. You may also need to increase the swap size to ensure proper export and operation - I increased my swap size to 4GB.
In the table below, 'No save' refers to passing the --nosave flag during inference with the V5 model (since it turns off the run logging and video creation). 'No view' refers to commenting out the display window created during inference showing the camera feed with detections. I assumed that both of these operations contributed to some processing overhead, so you can see you get better results with them turned off. However, I realize that it may be necessary to have either one of them running at the least to see how the detector performs, so the options can be toggled.
Hope this is of help to you guys.

@AyushExel awesome! Should this be renamed to something like NVIDIA Jetson Nano deployment tutorial?
I guess Nvidia Jetson would be better since it contains also xavier

Hi @AyushExel @lakshanthad, Can I ask what is the difference between the gen_wts_yoloV5.py from DeepStream-Yolo/utils and export.py from yolov5? What is the use case for each of them?

Hi there,
I am trying to install yolo5 network on Xavier nx. I followed your instructions in this link: https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano
when I get to this point in the installation instructions in deepstream configurations step:
python3 gen_wts_yoloV5.py -w yolov5s.pt
it gives me the following error: "Illegal instruction"
How do I solve this problem? Please reply to this message since resolving this problem is crucial for my use case.
Best Regards,
Farough
I didn't see this error @Farouq-Mot . Maybe @chaos1984 can help?
Hi @AyushExel @lakshanthad, Can I ask what is the difference between the
gen_wts_yoloV5.pyfromDeepStream-Yolo/utilsandexport.pyfromyolov5? What is the use case for each of them?
export.py exports models to different formats. It's not really specialized to stream through a particular hardware. Deepstream_yolo adds a bunch of customizations to facilitate streaming results from yolov5 on trt devices.

@chaos1984 @AyushExel @dinobei @lakshanthad
Hi,
I get this error "Illegal instruction", during deployment of the yolov5 network on Jetson xavier nx. Please see the attached image. This error happens when I run this command in this deepstream configuration step:
python3 gen_wts_yoloV5.py -w yolov5s.pt
I follow instructions on your github link: https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano
Please let me know how to fix this problem. Any help is greatly appreciated
Regards,
Farough
Today I flashed the jetson xaveir nx using SDK manager, with jetpack 4.6.1.
Then followed your instaructions. At the torchvision installation step, I get this error:
Illegal instruction
Please see the attached image.

@chaos1984 @AyushExel
help is appreciated
Regards,
Farough
Not sure what's happening but these issues are related to the environment and not yolov5. Try troubleshooting via trt foums

Not sure what's happening but these issues are related to the environment and not yolov5. Try troubleshooting via trt foums
@AyushExel I already asked to nvidia. This is the answer they gave to me.
https://forums.developer.nvidia.com/t/calib-table-not-found-when-running-deepstream/237493/5
@lakshanthad any help?

Hi, @Alberto1404, i had this issue also.
For some reason when you recompile and use OPENCV=1 in cmd, it doesn't actually build with opencv.
Quick fix is to just go into the makefile and change the opencv query to opencv=1.
Then just recompile without the opencv flag.
@arminbiglari Thank you so much for your reply.
Could you please share the modified Makefile? Not sure which line to modify exactly (I guess it is line 33)
Thank you
-----UPDATE-----
After modifying it, I get same error. @arminbiglari How do you create the calibration file calib.table? Where is it pointing to?

@arminbiglari Thank you so much for your reply. Could you please share the modified Makefile? Not sure which line to modify exactly (I guess it is line 33) Thank you
-----UPDATE----- After modifying it, I get same error. @arminbiglari How do you create the calibration file calib.table? Where is it pointing to?
just run the inference step 9:“deepstream-app -c deepstream_app_config.txt”. The calib.table will be created when calibrating.

I get this error "Illegal instruction", during deployment of the yolov5 network on Jetson xavier nx. Please see the attached image. This error happens when I run this command in this deepstream configuration step:
Try:
sudo OPENBLAS_CORETYPE=ARMV8 python3 setup.py install

How should we deploy a instance segmentation model with deepstream ?

I am getting this error when on Step4 of the DeepStream setup:

How do I fix this?

Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
This guide explains how to deploy a trained model into NVIDIA Jetson Platform and perform inference using TensorRT and DeepStream SDK. Here we use TensorRT to maximize the inference performance on the Jetson platform. UPDATED 18 November 2022.
Hardware Verification
We have tested and verified this guide on the following Jetson devices
- Seeed reComputer J1010 built with Jetson Nano module
- Seeed reComputer J2021 built with Jetson Xavier NX module
Before You Start
Make sure you have properly installed JetPack SDK with all the SDK Components and DeepStream SDK on the Jetson device as this includes CUDA, TensorRT and DeepStream SDK which are needed for this guide.
JetPack SDK provides a full development environment for hardware-accelerated AI-at-the-edge development. All Jetson modules and developer kits are supported by JetPack SDK.
There are two major installation methods including,
- SD Card Image Method
- NVIDIA SDK Manager Method
You can find a very detailed installation guide from NVIDIA official website. Also you can find guides corresponding to the above-mentioned reComputer J1010 and reComputer J2021.
Install Necessary Packages
- Step 1. Access the terminal of Jetson device, install pip and upgrade it
sudo apt update sudo apt install -y python3-pip pip3 install --upgrade pip
- Step 2. Clone the following repo
git clone https://github.com/ultralytics/yolov5
- Step 3. Open requirements.txt
cd yolov5 vi requirements.txt
- Step 5. Edit the following lines. Here you need to press i first to enter editing mode. Press ESC, then type :wq to save and quit
# torch>=1.7.0 # torchvision>=0.8.1Note: torch and torchvision are excluded for now because they will be installed later.
- Step 6. install the below dependency
sudo apt install -y libfreetype6-dev
- Step 7. Install the necessary packages
pip3 install -r requirements.txtInstall PyTorch and Torchvision
We cannot install PyTorch and Torchvision from pip because they are not compatible to run on Jetson platform which is based on ARM aarch64 architecture. Therefore we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.
Visit this page to access all the PyTorch and Torchvision links.
Here are some of the versions supported by JetPack 4.6 and above.
PyTorch v1.10.0
Supported by JetPack 4.4 (L4T R32.4.3) / JetPack 4.4.1 (L4T R32.4.4) / JetPack 4.5 (L4T R32.5.0) / JetPack 4.5.1 (L4T R32.5.1) / JetPack 4.6 (L4T R32.6.1) with Python 3.6
file_name: torch-1.10.0-cp36-cp36m-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl
PyTorch v1.12.0
Supported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8
file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Step 1. Install torch according to your JetPack version in the following format
wget <URL> -O <file_name> pip3 install <file_name>For example, here we are running JP4.6.1 and therefore we choose PyTorch v1.10.0
cd ~ sudo apt-get install -y libopenblas-base libopenmpi-dev wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- Step 2. Install torchvision depending on the version of PyTorch that you have installed. For example, we chose PyTorch v1.10.0, which means, we need to choose Torchvision v0.11.1
sudo apt install -y libjpeg-dev zlib1g-dev git clone --branch v0.11.1 https://github.com/pytorch/vision torchvision cd torchvision sudo python3 setup.py installHere a list of the corresponding torchvision version that you need to install according to the PyTorch version:
- PyTorch v1.10 - torchvision v0.11.1
- PyTorch v1.12 - torchvision v0.13.0
DeepStream Configuration for YOLOv5
- Step 1. Clone the following repo
cd ~ git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Step 2. Copy gen_wts_yoloV5.py from DeepStream-Yolo/utils into yolov5 directory
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
- Step 3. Inside the yolov5 repo, download pt file from YOLOv5 releases (example for YOLOv5s 6.1)
cd yolov5 wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- Step 4. Generate the cfg and wts files
python3 gen_wts_yoloV5.py -w yolov5s.ptNote: To change the inference size (defaut: 640)
-s SIZE --size SIZE -s HEIGHT WIDTH --size HEIGHT WIDTH Example for 1280: -s 1280 or -s 1280 1280
- Step 5. Copy the generated cfg and wts files into the DeepStream-Yolo folder
cp yolov5s.cfg ~/DeepStream-Yolo cp yolov5s.wts ~/DeepStream-Yolo
- Step 6. Open the DeepStream-Yolo folder and compile the library
cd ~/DeepStream-Yolo CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1 CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- Step 7. Edit the config_infer_primary_yoloV5.txt file according to your model
[property] ... custom-network-config=yolov5s.cfg model-file=yolov5s.wts ...
- Step 8. Edit the deepstream_app_config file
... [primary-gie] ... config-file=config_infer_primary_yoloV5.txt
- Step 9. Change the video source in deepstream_app_config file. Here a default video file is loaded as you can see below
... [source0] ... uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4Run the Inference
deepstream-app -c deepstream_app_config.txt

The above result is running on Jetson Xavier NX with FP32 and YOLOv5s 640x640. We can see that the FPS is around 30.INT8 Calibration
If you want to use INT8 precision for inference, you need to follow the steps below
- Step 1. Install OpenCV
sudo apt-get install libopencv-dev
- Step 2. Compile/recompile the nvdsinfer_custom_impl_Yolo library with OpenCV support
cd ~/DeepStream-Yolo CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1 CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- Step 3. For COCO dataset, download the val2017, extract, and move to DeepStream-Yolo folder
- Step 4. Make a new directory for calibration images
mkdir calibration
- Step 5. Run the following to select 1000 random images from COCO dataset to run calibration
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \ cp ${jpg} calibration/; \ doneNote: NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from head -1000. For example, for 2000 images, head -2000. This process can take a long time.
- Step 6. Create the calibration.txt file with all selected images
realpath calibration/*jpg > calibration.txt
- Step 7. Set environment variables
export INT8_CALIB_IMG_PATH=calibration.txt export INT8_CALIB_BATCH_SIZE=1
- Step 8. Update the config_infer_primary_yoloV5.txt file
From
... model-engine-file=model_b1_gpu0_fp32.engine #int8-calib-file=calib.table ... network-mode=0 ...To
... model-engine-file=model_b1_gpu0_int8.engine int8-calib-file=calib.table ... network-mode=1 ...
- Step 9. Run the inference
deepstream-app -c deepstream_app_config.txt

The above result is running on Jetson Xavier NX with INT8 and YOLOv5s 640x640. We can see that the FPS is around 60.Benchmark results
The following table summarizes how different models perform on Jetson Xavier NX.
Model Name Precision Inference Size Inference Time (ms) FPS
YOLOv5s FP32 320x320 16.66 60
FP32 640x640 33.33 30
INT8 640x640 16.66 60
YOLOv5n FP32 640x640 16.66 60Additional
This tutorial is written by our friends at seeed @lakshanthad and Elaine
Hello, @AyushExel
thanks for sharing good information.
Is there any way to use the above without using deepstream?
Thank you.

This is the error I am currently getting. How can I fix this?
I got it to work by downgrading OpenCV from the default 4.7.0 to 4.5.1!

Thanks for the tutorial. Used it to configure and run YoloV5s on an Orin AGX Dev Kit.
Result running in the 30Watt Mode:
Model Name Precision Inference Size FPS
YOLOv5s FP32 640x640 55

Hey, man. Thank you for your tutorial, but I got the problem with INT8 calibration when I did "deepstream-app -c deepstream_app_config.txt":

i fixed the problem, please remake CUDA_VER......
i got another problem.the engine model which is produced by "deepstream-app -c deepstream_app_config.txt" and its name is "model_b1_gpu0_int8.engine", i used it on yolov5-6.1 detect.py and the error was as follows:


how can I solve this.

when I try this order sudo python3 gen_wts_yoloV5.py -w yolov5s.pt on my jetson nano
and it will feedback this Illegal instruction
@junxi-haoyi hello! Thank you for reaching out. The "Illegal instruction" error typically means that the executable code being run is not compatible with the CPU architecture of the device.
To resolve this issue, you can try setting the OPENBLAS_CORETYPE environment variable to a compatible architecture for your device. For instance, you could use ARMV8 for most ARM-based devices such as the Jetson Xavier NX.
Here's an example of how you can do this:
sudo OPENBLAS_CORETYPE=ARMV8 python3 setup.py installThis command sets the OPENBLAS_CORETYPE environment variable to ARMV8 for the subsequent python3 setup.py install command, ensuring compatibility with the CPU architecture.
I hope this helps! If you have any further questions or encounter any more issues, feel free to ask.

There is no file named gen_wts_v5.py in the utils folder of the deepstream-yolo repo? what should I do
@vanshdhar999 you can create the gen_wts_v5.py file manually by following these steps:
- Create a new Python file named
gen_wts_v5.py. - Write the necessary code within this file to generate the required
.wtsand.cfgfiles. - Place this file in the
utilsfolder of theDeepStream-Yolorepository.
If you have specific requirements or need assistance with the content of the gen_wts_v5.py file, please let me know so I can provide you with further guidance.
What is the required code to be written? @glenn-jocher
@vanshdhar999 the gen_wts_v5.py script is used to generate the .wts file from the PyTorch .pt file for YOLOv5 model deployment.
Here's a basic example of what the content of the gen_wts_v5.py file might look like:
import torch
from models.yolo import Model # Import your YOLOv5 model class here
# Load the PyTorch model
model = Model(pretrained=False) # Replace with the actual YOLOv5 model class and load the weights
# Convert and save the model to TorchScript format
# Replace 'input_shape' with the actual input shape of the model
ts = torch.jit.script(model.to(torch.device('cpu')).eval())
ts.save('yolov5s.ts') # Save the TorchScript model
# Convert and save the model to TensorRT engine
import torch2trt
from torch2trt import TRTModule
import pycuda.driver as cuda
# Directories for TensorRT logging
TRT_LOGGER = torch2trt.Logger(torch2trt.LogSeverity.INFO)
model_trt = torch2trt.ts2trt(ts, [torch.randn(1, 3, input_shape, input_shape).to(device)], max_batch_size=1, log_level=torch2trt.LogSeverity.VERBOSE, strict_type_constraints=True)
model_trt.save("yolov5s.trt") # Save the TensorRT enginePlease replace the placeholders with your actual YOLOv5 model class, input shape, and other specific details.
Remember to adjust the script according to your exact requirements and your trained YOLOv5 model. If you need further assistance or have more specific requirements, feel free to let me know.

@glenn-jocher Can we implement Deepstream based trackers like NvDcf or NvSORT by adding the tracker plugin in the config file? I tried but it doesn't seem to work. I want to use Yolov5 along with NvSORT tracker.
Hello! Integrating NvSORT or other DeepStream trackers with YOLOv5 in a DeepStream framework does involve careful configuration. Ensure that the nvinfer and nvtracker plugins are correctly configured in your DeepStream application config file. For NvSORT, your config may look something like this:
[tracker]
enable=1
tracker-width=640
tracker-height=384
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvdcf.so
ll-config-file=config_tracker_NvDCF_perf.yml
gpu-id=0
enable-batch-process=1Make sure paths and parameters match your setup. Additionally, ensure that the model outputs and tracker configs are compatible (location, detection confidence formats, etc.).
If the issue persists, check for any error messages in the logs which might offer more specific insight into what might be going wrong. 😊
@glenn-jocher When I try to run python3 gen_wts_yoloV5.py -w best.pt where "best.pt" is my custom trained model, it gives the error
Traceback (most recent call last): File "gen_wts_yoloV5.py", line 358, in <module> delattr(model.model[-1], 'anchor_grid') File "/home/agx-arka/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1685, in __delattr__ super().__delattr__(name) AttributeError: anchor_grid
Why is it throwing this error?
Hello! It looks like the error is happening because the attribute anchor_grid does not exist in the last module of your model. This might occur if there have been changes in the model's architecture or the library versions are not matching.
A quick fix could be checking whether the attribute exists before trying to delete it. You could modify your gen_wts_yoloV5.py script to include a conditional check:
if hasattr(model.model[-1], 'anchor_grid'):
delattr(model.model[-1], 'anchor_grid')This change ensures that the script only tries to delete the anchor_grid if it exists, potentially circumventing the AttributeError. Make sure your script and your model are compatible in terms of architecture and library versions! 😊
Hi @glenn-jocher I was able to convert the model to onnx using python3 export_yoloV5.py. But when I run inference on deepstream, the model's detections falls off by a lot in comparison to Ultralytics inference. Can you let me know why is that the case?
Hello! The discrepancy in detection performance between the original Ultralytics YOLOv5 inference and the ONNX/DeepStream version might be due to several factors:
- Precision Differences: ONNX might use different precision settings (e.g., FP16 vs FP32) compared to your original setup.
- Post-processing: Ensure that all post-processing steps (like non-max suppression and confidence thresholding) are consistently applied in both environments.
- Model Conversion: Sometimes, model conversion to ONNX can introduce slight discrepancies. Make sure that all model features are supported and correctly translated in ONNX.
To further diagnose, consider comparing the intermediate outputs of both models or checking if the issue persists with different models/samples. A code review might also help ensure settings like input normalization are consistent. 🧐
Hello! The discrepancy in detection performance between the original Ultralytics YOLOv5 inference and the ONNX/DeepStream version might be due to several factors:
- Precision Differences: ONNX might use different precision settings (e.g., FP16 vs FP32) compared to your original setup.
- Post-processing: Ensure that all post-processing steps (like non-max suppression and confidence thresholding) are consistently applied in both environments.
- Model Conversion: Sometimes, model conversion to ONNX can introduce slight discrepancies. Make sure that all model features are supported and correctly translated in ONNX.
To further diagnose, consider comparing the intermediate outputs of both models or checking if the issue persists with different models/samples. A code review might also help ensure settings like input normalization are consistent. 🧐
Thanks for reply. I had implemented https://github.com/marcoslucianops/DeepStream-Yolo. All the plugins for post processing are as per the model's requirements. Is there a way to compensate for the loss from the conversion from pt to onnx? Because to run it on deepstream it supports onnx files in this case for TRT inference.
@vmukund36 hello! Thanks for the update. To address the performance loss after converting your model from .pt to .onnx, you could try the following:
-
Optimize the ONNX Model: Use tools like
onnx-simplifierto optimize the ONNX model. This can sometimes help in preserving model integrity and performance.pip install onnx-simplifier python -m onnxsim input_model.onnx output_model.onnx
-
Precision Tuning: Experiment with different precision formats during the ONNX export or within the DeepStream configuration. Sometimes setting everything explicitly to FP32 might help, although it will increase resource usage.
-
Review Export Settings: Ensure that the export settings in your
export.pyscript match as closely as possible with the inference settings used during training, focusing on details like image sizes and normalizations.
If discrepancies persist, consider further fine-tuning or retraining the model directly in the ONNX format or adjusting the DeepStream pipeline to better accommodate the model's characteristics. 😊
Hi @glenn-jocher I tried with onnx-simplifier as well but the results are the same if not worse. I had tried to convert to onnx format using ultralytics api as well and upon inferencing it gave a similar result. I am not really sure how to make sure to not compromise on model's performance while also inferencing on deepstream(which supports onnx only). Do you recommend trying any other alternative approach in order to not face this issue?
Hello! It sounds like you're facing a challenging issue with the ONNX format in DeepStream. If onnx-simplifier didn't help and direct conversion maintains the performance gap, consider the following approach:
-
Model Re-training: Sometimes, re-training the model with an inference-centric focus, particularly targeting the ONNX export, can help. Adjust training parameters slightly to favor features that translate well in ONNX.
-
Custom Layer Implementation: If certain layers or operations are not translating well, you might need to implement custom layers in DeepStream that match the behavior of the original PyTorch model.
If you've explored all usual routes, these alternative steps might help in maintaining performance consistency. Keep in mind that slight discrepancies between training frameworks and inference engines are common, and achieving an exact match might require a bit of trial and error. 😊

i have a problem when i run model with tensort engine and deepstream SDK. I really want to help me. This is error when i run deepstream and tensorrt. I think it is error nvdsinfer_custom_impl_Yolo

Hello! Thank you for reaching out and providing the screenshot. To assist you better, could you please share a minimum reproducible code example? This will help us understand the context and reproduce the issue on our end. You can find guidance on creating a minimum reproducible example here: Minimum Reproducible Example.
Additionally, please ensure that you are using the latest versions of torch and the YOLOv5 repository from Ultralytics GitHub. Sometimes, updates can resolve underlying issues.
Once we have the necessary details, we can investigate further and provide a more accurate solution. Thank you for your cooperation! 😊