Hyperparameter Evolution
glenn-jocher opened this issue · comments

📚 This guide explains hyperparameter evolution for YOLOv5 🚀. Hyperparameter evolution is a method of Hyperparameter Optimization using a Genetic Algorithm (GA) for optimization. UPDATED 28 March 2023.
Hyperparameters in ML control various aspects of training, and finding optimal values for them can be a challenge. Traditional methods like grid searches can quickly become intractable due to 1) the high dimensional search space 2) unknown correlations among the dimensions, and 3) expensive nature of evaluating the fitness at each point, making GA a suitable candidate for hyperparameter searches.
Before You Start
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7. Models and datasets download automatically from the latest YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install1. Initialize Hyperparameters
YOLOv5 has about 30 hyperparameters used for various training settings. These are defined in *.yaml files in the /data directory. Better initial guesses will produce better final results, so it is important to initialize these values properly before evolving. If in doubt, simply use the default values, which are optimized for YOLOv5 COCO training from scratch.
yolov5/data/hyps/hyp.scratch-low.yaml
Lines 2 to 34 in 2da2466
2. Define Fitness
Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: mAP@0.5 contributes 10% of the weight and mAP@0.5:0.95 contributes the remaining 90%, with Precision P and Recall R absent. You may adjust these as you see fit or use the default fitness definition (recommended).
Lines 12 to 16 in 4103ce9
3. Evolve
Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cacheTo evolve hyperparameters specific to this scenario, starting from our initial values defined in Section 1., and maximizing the fitness defined in Section 2., append --evolve:
# Single-GPU
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
# Multi-GPU
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --device $i --evolve > evolve_gpu_$i.log &
done
# Multi-GPU bash-while (not recommended)
for i in 0 1 2 3 4 5 6 7; do
sleep $(expr 30 \* $i) && # 30-second delay (optional)
echo 'Starting GPU '$i'...' &&
"$(while true; do nohup python train.py... --device $i --evolve 1 > evolve_gpu_$i.log; done)" &
doneThe default evolution settings will run the base scenario 300 times, i.e. for 300 generations. You can modify generations via the --evolve argument, i.e. python train.py --evolve 1000.
Line 608 in 6a3ee7c
The main genetic operators are crossover and mutation. In this work mutation is used, with a 80% probability and a 0.04 variance to create new offspring based on a combination of the best parents from all previous generations. Results are logged to runs/evolve/exp/evolve.csv, and the highest fitness offspring is saved every generation as runs/evolve/hyp_evolved.yaml:
# YOLOv5 Hyperparameter Evolution Results
# Best generation: 287
# Last generation: 300
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
# 0.54634, 0.55625, 0.58201, 0.33665, 0.056451, 0.042892, 0.013441
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)We recommend a minimum of 300 generations of evolution for best results. Note that evolution is generally expensive and time consuming, as the base scenario is trained hundreds of times, possibly requiring hundreds or thousands of GPU hours.
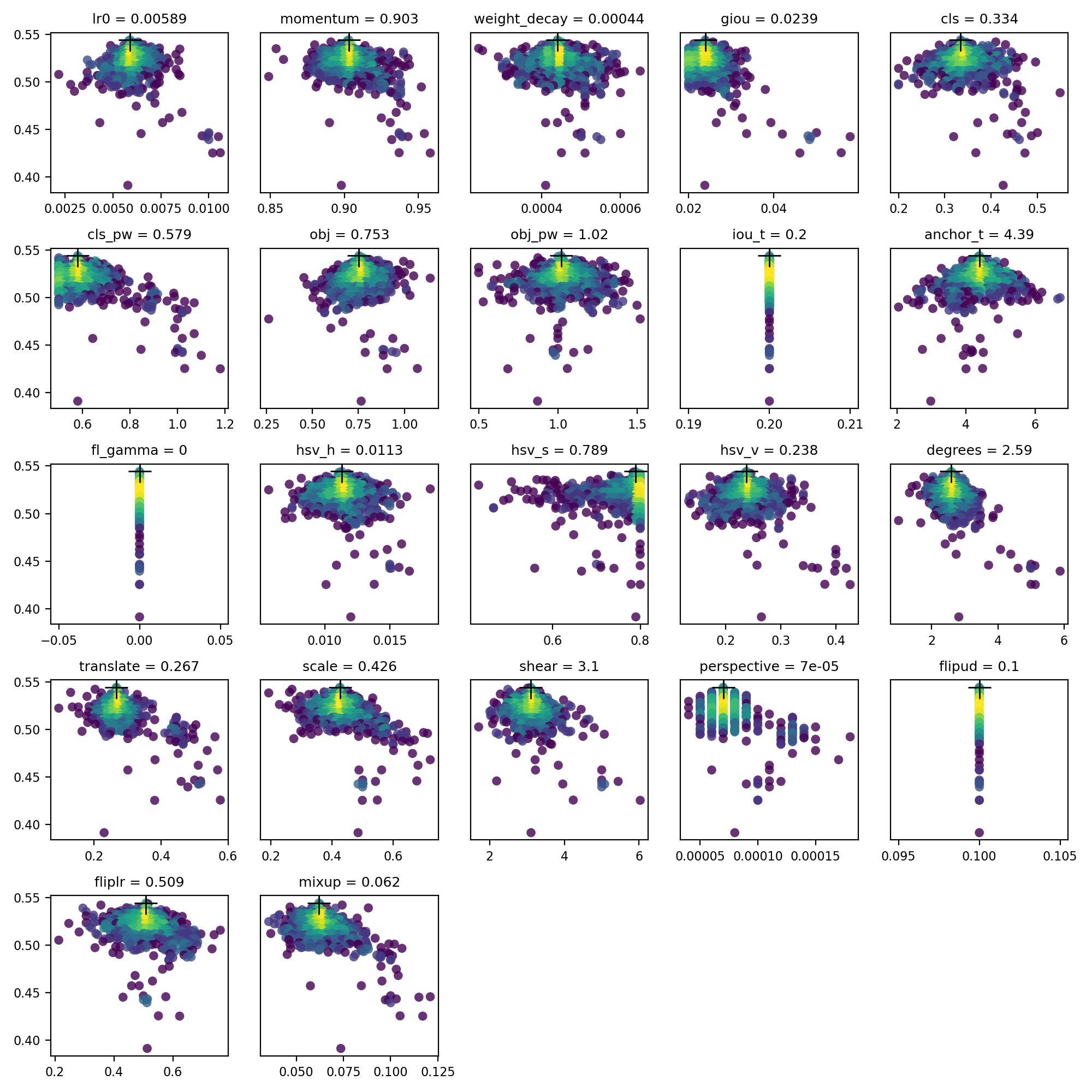
4. Visualize
evolve.csv is plotted as evolve.png by utils.plots.plot_evolve() after evolution finishes with one subplot per hyperparameter showing fitness (y axis) vs hyperparameter values (x axis). Yellow indicates higher concentrations. Vertical distributions indicate that a parameter has been disabled and does not mutate. This is user selectable in the meta dictionary in train.py, and is useful for fixing parameters and preventing them from evolving.
Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide


Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit.

@glenn-jocher I trained with --evolve, --nosave hyper parameter but i didnt receive last weights in runs folder.

@buimanhlinh96 , evolve is will find the best hyper params after 10 epoch (if you didn't change it), you will want to take what was found to be the best and do a full training!
@glenn-jocher did you find 10 epoch to give a decent indication about a full training? Is it whats the most cost efficient from what you have seen ?
@Ownmarc there is no fixed evolve scenario. You create the scenario and then just append --evolve to it and let it work. If you want to evolve full training, well, you know what to do. Any assumption about results from shorter training correlating with results of longer trainings is up to you.
And did you find any correlations between model sizes ? Will some "best" hyp on yolov5s also do a good job on yolov5x or would it require its own evolve ?
@Ownmarc I have not evolved per model, but it's fairly obvious that whatever works best for a 7M parameter model will not be identical to whatever works best for a 90M parameter model.

@glenn-jocher , I believe the V3.0 release has changed in the train.py. I didn't find the hyp at L18-43 in train.py . Instead , I found the
data/hyp.scratch.yaml
file with hyp set.
so, if I want to change the hyp to training , rewrite the hyp.scratch.yaml file is OK, right?
.
@Frank1126lin yes that's correct:
hyp.scratch.yamlwill be automatically used by defaulthyp.custom.yamlcan be force-selected bypython train.py --hyp hyp.custom.yaml
Line 445 in c2523be

@buimanhlinh96 ,hello, did you find the best hyp result after training with --evolve?

Hello, I run :
python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'

Hello, I run :
python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolveand got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'
I also have same problem.
Hello, I run :
python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'I also have same problem.
remove ‘anchor’ line will slove the problem
Hello, I run :
python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'I also have same problem.
remove ‘anchor’ line will slove the problem
Thanks for helping. Could you explain more ? Which anchor line (in training or yaml)?
Removed this line and worked, But I need some explanation. Thanks again
Constrain to limits
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
Hello, I run :
python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'I also have same problem.
remove ‘anchor’ line will slove the problem
Thanks for helping. Could you explain more ? Which anchor line (in training or yaml)?
Removed this line and worked, But I need some explanation. Thanks again
Constrain to limits
for k, v in meta.items(): hyp[k] = max(hyp[k], v[1]) # lower limit hyp[k] = min(hyp[k], v[2]) # upper limit hyp[k] = round(hyp[k], 5) # significant digits
line475 in train.py:
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
#'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
Hello, I run :
python train.py --epochs 10 --data coco128.yaml --cfg yolov5s.yaml --weights yolov5s.pt --cache --evolve
and got an error like:
Namespace(adam=False, batch_size=16, bucket='', cache_images=True, cfg='./models/yolov5s.yaml', data='./data/coco128.yaml', device='', epochs=3, evolve=True, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[640, 640], local_rank=-1, logdir='runs/', multi_scale=False, name='', noautoanchor=False, nosave=False, notest=False, rect=False, resume=False, single_cls=False, sync_bn=False, total_batch_size=16, weights='', workers=8, world_size=1)
Traceback (most recent call last):
File "train.py", line 525, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'I also have same problem.
remove ‘anchor’ line will slove the problem
Thanks for helping. Could you explain more ? Which anchor line (in training or yaml)?
Removed this line and worked, But I need some explanation. Thanks again
Constrain to limits
for k, v in meta.items(): hyp[k] = max(hyp[k], v[1]) # lower limit hyp[k] = min(hyp[k], v[2]) # upper limit hyp[k] = round(hyp[k], 5) # significant digitsline475 in train.py:
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
#'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
Many Thanks...

#'anchors
Is commenting out anchors line will affect the hyper parameters?
@Samjith888 autoanchor will create new anchors if a value is found for hyp['anchors'], overriding any anchor information you specify in your model.yaml. i.e. you can set anchors: 5 to force autoanchor to create 5 new anchors per output layer, replacing the existing anchors. Hyperparameter evolution will evolve you an optimal number of anchors using this parameter.

@glenn-jocher You mean that if you comment out ['anchors'] in the 'hyp.scratch.yaml' file, the autoanchor will not work.Will yolov5_master produce anchors based on the value of my model.yaml ['anchors']?
If we do not comment the ['anchors'] in the 'hyp.scratch.yaml' file, will autoanchor produce the specified number of anchors on each Detect layer?
@xinxin342 if a nonzero anchor hyperparameter is found, existing anchor information will be deleted and new anchors will be force-autocomputed.

wow ! this tutorials helps a lot ! many thanks !

Is there an argument to limit the maximum number of object detection per frame?
@Sergey-sib your question is not related to hyperparameter evolution.
Line 610 in 0fda95a

Hi @glenn-jocher
The command:
for i in 0 1 2 3; do
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve --device $i &
done
Seems that for multi-gpu evolution, it just repeat same progress in 4 GPUs with same parameters.
For example, I want to choose a best learning rate from the range of (0.1, 0.5), and the generations is 200. My understanding is that it will try 200 different lr to find a best one. Right?
So for multi-gpu evolution, if use the command
for i in 0 1 2 3; do
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve --device $i &
done
It seems just repeat it four times? I think it should be something like that each gpu trys 50 different lr for the range of (0.1,0.2) (0.2,0.3) (0.3,0.4) and (0.4,0.5).
Please correct me if my understanding is not right. Thanks.
@cxzhou95 the tutorial commands are correct. The multi-GPU tutorial command instructs four GPUs to evolve 300 generations each, reading and writing to a common evolve.txt. If not stopped prematurely this will evolve 1200 generations on all hyperparameters.

how to decide the hyperparameter of yolov5s 、 the hyperparameter of yolov5m、 the hyperparameter of yolov5l?
they are setting with the same hyperparameter?
@alicera hyperparameters are evolved on YOLOv5m and then used across all models.

hellow,my command is python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve
Does that mean I will evolve 10 * 300 times?
Does every epochs evolve 300 times?
Or did it evolve 300 times in these 10 epochs?
thank you so much.
@python-faker --evolve evolves the base train.py command for 300 generations. The base command is irrelevant.

@glenn-jocher I am a little confused about evolve, is it used for training or just find the hyperparameters by train a few epochs and then use the hyp found to retrain?
Thanks.

Hi, I tried to evolve but it produced an memory error says:
Traceback (most recent call last):
File "train.py", line 528, in <module>
results = train(hyp.copy(), opt, device)
File "train.py", line 166, in train
dataloader, dataset = create_dataloader(train_path, imgsz, batch_size, gs, opt,
File "D:\workspace\yolov5\utils\datasets.py", line 66, in create_dataloader
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
EOFError: Ran out of input
dataloader = InfiniteDataLoader(dataset,
File "D:\workspace\yolov5\utils\datasets.py", line 84, in __init__
self.iterator = super().__iter__()
File "C:\Users\asus\anaconda3\envs\yolov5\lib\site-packages\torch\utils\data\dataloader.py", line 291, in __iter__
return _MultiProcessingDataLoaderIter(self)
File "C:\Users\asus\anaconda3\envs\yolov5\lib\site-packages\torch\utils\data\dataloader.py", line 737, in __init__
w.start()
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\process.py", line 121, in start
self._popen = self._Popen(self)
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\context.py", line 327, in _Popen
return Popen(process_obj)
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\popen_spawn_win32.py", line 93, in __init__
reduction.dump(process_obj, to_child)
File "C:\Users\asus\anaconda3\envs\yolov5\lib\multiprocessing\reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
MemoryError
What could possibly be wrong?
@siyangxie it appears you may have environment problems. Please ensure you meet all dependency requirements if you are attempting to run YOLOv5 locally. If in doubt, create a new virtual Python 3.8 environment, clone the latest repo (code changes daily), and pip install -r requirements.txt again. We also highly recommend using one of our verified environments below.
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.6. To install run:
$ pip install -r requirements.txtEnvironments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Google Colab Notebook with free GPU:
- Kaggle Notebook with free GPU: https://www.kaggle.com/models/ultralytics/yolov5
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Docker Image https://hub.docker.com/r/ultralytics/yolov5. See Docker Quickstart Guide
Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are passing. These tests evaluate proper operation of basic YOLOv5 functionality, including training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu.
@glenn-jocher I run the following commands, but the hyp is the same as hyp.scratch, why is that?
for i in 0 1 2 3; do
nohup python train.py --img 640 \
--batch 50 \
--epochs 10 \
--data ./data/widerface.yaml \
--cfg ./models/yolov5l.yaml \
--weights /app/models_saved/face_detect_l.pt \
--single-cls --cache --evolve --device $i > evolve_gpu_$i.log &
done
The evolve.png is as follows:

I comment anchor in train.py as mentioned before, is that the cause?
@Edwardmark Hello, thank you for your interest in our work! This issue seems to lack the minimum requirements for a proper response, or is insufficiently detailed for us to help you. Please note that most technical problems are due to:
- Your modified or out-of-date code. If your issue is not reproducible in a new
git cloneversion of this repo we can not debug it. Before going further run this code and verify your issue persists:
$ git clone https://github.com/ultralytics/yolov5 yolov5_new # clone latest
$ cd yolov5_new
$ python detect.py # verify detection
# CODE TO REPRODUCE YOUR ISSUE HERE-
Your custom data. If your issue is not reproducible in one of our 3 common datasets (COCO, COCO128, or VOC) we can not debug it. Visit our Custom Training Tutorial for guidelines on training your custom data. Examine
train_batch0.jpgandtest_batch0.jpgfor a sanity check of your labels and images. -
Your environment. If your issue is not reproducible in one of the verified environments below we can not debug it. If you are running YOLOv5 locally, verify your environment meets all of the requirements.txt dependencies specified below. If in doubt, download Python 3.8.0 from https://www.python.org/, create a new venv, and then install requirements.
If none of these apply to you, we suggest you close this issue and raise a new one using the Bug Report template, providing screenshots and minimum viable code to reproduce your issue. Thank you!
Requirements
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.6. To install run:
$ pip install -r requirements.txtEnvironments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Google Colab Notebook with free GPU:
- Kaggle Notebook with free GPU: https://www.kaggle.com/models/ultralytics/yolov5
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Docker Image https://hub.docker.com/r/ultralytics/yolov5. See Docker Quickstart Guide
Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are passing. These tests evaluate proper operation of basic YOLOv5 functionality, including training (train.py), testing (test.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu.

@glenn-jocher I have gone through at least 8 generation cycles buy haven't seen a yolov5/evolve.png file. At what point is this created?
@nanometer34688 evolve.png is generated when evolution completes after 300 generations.
Lines 570 to 571 in 7aeef2d
@glenn-jocher Thank you

Hi fellows CV enthusiasts,
We are agreed that --evolve does not support a different img-size than the initial training img-size?!?!
concretely:
initial training -> img-size 640x640
vs
evolve training -> img-size 1137x640
@MikeHatchi the train.py --img-size argument accepts one scalar value (applied to both train and test sizes), or two scalar values, applied to train and test image sizes, but this is a training argument and not a hyperparameter.
You can evolve on any base scenario you want (including any image size you want).
@glenn-jocher hi and thx
Interesting... I have encountered a problem then when I wanted to evolve: I've chosen to --evolve with --img-size 1137 (with and without --rect as the size of the image is 1137x640) as the pre-trained model has been trained with initial 640x640.
Basically, it returns that 1137 is an unknown size.
If I take off the --img-size 1137, the evolve scenarii are launched
@MikeHatchi all YOLOv5 operations are constrained to run at multiples of the largest output stride of 32. If your requested img size does not meet the constraint it will be modified accordingly. If you believe there is a reproducible bug anywhere, please raise a bug report with code to reproduce. Thank you.
@glenn-jocher thx
basic!
I should have been more focused.
I'll raise a bug report if indeed that's still the case.
Hi @Ownmarc hope you're ok?! (or @glenn-jocher)
I've got 2 questions:
-
doing a scenario with "evolve" will produce a "best.pt" file, right?
Unfortunately, I've done a 40 epochs "evolve" scenario and after 23 hours, no .pt file has been saved. -
if I definitely need a high recall, I can deliberately act here: def fitness(x)?
...
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
...
Many thanks
Nothing happened and GPU's are idle while doing hyper parameter evolution with 4 GPU
Command used
# Multi-GPU
for i in 0 1 2 3; do
nohup python train.py --epochs 10 --data coco128.yaml --weights yolov5m.pt --cache --evolve --device $i > evolve_gpu_$i.log &
done
@Samjith888 you have an error in your commands and should view your evolve_gpu_$i.log files.
@Samjith888 you have an error in your commands and should view your evolve_gpu_$i.log files.
Found the following error inside the log file
Error
Traceback (most recent call last):
File "train.py", line 528, in <module>
results = train(hyp.copy(), opt, device)
File "train.py", line 169, in train
world_size=opt.world_size, workers=opt.workers)
File "/home/yolov5/utils/datasets.py", line 61, in create_dataloader
rank=rank)
File "/home/yolov5/utils/datasets.py", line 378, in __init__
labels, shapes = zip(*[cache[x] for x in self.img_files])
File "/home/yolov5/utils/datasets.py", line 378, in <listcomp>
labels, shapes = zip(*[cache[x] for x in self.img_files])
KeyError: '/home/dataset/train/images/train2014_000000000036.jpg'

What should do for stage 2 Define fitness?
@Tony0726 if you have no alternative fitness requirements, you may simply use the default fitness metric, in which case no action is required on your part.
@glenn-jocher Thanks a lot.

i trained with --evolve with multi gpu
# Multi-GPU
for i in 0 1 2 3; do
nohup python train.py --img 640 --batch 32 --workers 8 --multi-scale --epochs 10 --data dataset.yaml --single-cls --weights yolov5s.pt --evolve --cache --device $i 2>&1 | tee evolve_gpu_$i.log &
done
but didn't get the weights in save, the folder was empty; train/evolve/weights was empty
@satyajitghana evolution does not produce weights, it evolves hyperparameters.
i trained with --evolve with multi gpu
# Multi-GPU for i in 0 1 2 3; do nohup python train.py --img 640 --batch 32 --workers 8 --multi-scale --epochs 10 --data dataset.yaml --single-cls --weights yolov5s.pt --evolve --cache --device $i 2>&1 | tee evolve_gpu_$i.log & donebut didn't get the weights in save, the folder was empty;
train/evolve/weightswas empty
Getting key error while using the same command
@satyajitghana evolution does not produce weights, it evolves hyperparameters.
aaah okay, makes sense. cool.
@Samjith888 was using a custom dataset, try with the included coco128.yaml
but turns out, evolution wasn't meant to save weights, so i guess its okay, i got my hyper params though.
@Samjith888 was using a custom dataset, try with the included coco128.yaml
but turns out, evolution wasn't meant to save weights, so i guess its okay, i got my hyper params though.
I'm using a custom dataset , not for coco128.yaml.. Already posted the error earlier here, but it disappeared somehow .

Hi All,
I did comment this line: #'anchors': (0, 2.0, 10.0), # anchors per output grid (0 to ignore)
but still getting this error:
Traceback (most recent call last):
File "train.py", line 561, in
hyp[k] = max(hyp[k], v[1]) # lower limit
KeyError: 'anchors'
any ideas? fix?
thanx
Frederik
@frederikvanduuren for hyperparameter evolution this line should be uncommented, and set to 0 to ignore, or to a standard anchor count (i.e. 3) to evolve anchor count.

How to choose the number of the epoch? In this tutorial, the epoch is 10, but if I have my own custom dataset. The baseline model needs 75 epochs to convergence. Should I set --evolve --epochs 75?
@TommyZihao Hi Tommy, i did set the epochs to 100, but you should see how much you need so the mAP & recall does converge to a maximum level
@TommyZihao Hi Tommy, i did set the epochs to 100, but you should see how much you need so the mAP & recall does converge to a maximum level
Would 100 epochs take a super long time?

Hi, @glenn-jocher , i used command 'python train.py --img 640 --batch 16 --epochs 300 --data mydataset.yaml --weights yolov5l.pt --evolve --cache' to take a try of Hyperparameter Evolution, but after more than 100 epochs, my yolov5/runs/train/evolve folder just have following files, no yolov5/runs/evolve/hyp_evolved.yaml, the weights folder is empty too.

meanwhile, in the yolov5 root folder, there is no yolov5/evolve.txt and yolov5/evolve.png.
Do you have any idea what might be the possible cause ? thanks !
@wwdok you have not finished training a single generation. < 1 generation will not produce any evolution output.
@frederikvanduuren @glenn-jocher I got it ! In my case, 300 epochs is 1 generation, by default, it need 1 generation to output yolov5/runs/evolve/hyp_evolved.yaml, and need 300 generations(that means 90000 epochs) to output the yolov5/evolve.png
@wwdok yes exactly! For this reason it may make sense to use a different base scenario that produces a fitness faster (i.e. perhaps only train to 100 epochs). But be careful, because you want your base scenario results to correlate strongly with your actual underlying scenario (training 300 epochs), so as you reduce your epoch count to zero the correlation with 300-epoch results will also reduce to zero.
In layman's terms, hyperparameters that help you achieve the best results over short trainings (i.e. in 10 epochs), will not be the same ones that help you achieve the best results at 300 epochs. At 10 epochs things like weight decay don't matter for example, so evolving on short trainings will cause your weight decay to evolve down to zero, which will cause earlier overfitting and worse results at 300 epochs. It's a balancing act each person has to decide on.

@wwdok yes exactly! For this reason it may make sense to use a different base scenario that produces a fitness faster (i.e. perhaps only train to 100 epochs). But be careful, because you want your base scenario results to correlate strongly with your actual underlying scenario (training 300 epochs), so as you reduce your epoch count to zero the correlation with 300-epoch results will also reduce to zero.
@glenn-jocher Can we clarify this a bit please, I read it like this: 10 epochs for evolving will result in 3000 total epochs generating 300 generations of hyperparameters. Or is it really 90000 as @wwdok stated (which would be ridiculous time wise)? Further I understand any img size parameters will not taken into account, but could we evolve with a smaller resolution set perhaps to speed it up a bit? If so how to achieve this other than modify the data set?
@thhart its very simple. Your base scenario is run for n generations. Your base scenario is what you are optimizing, it's epoch count is up to you.
@thhart its very simple. Your base scenario is run for
ngenerations. Your base scenario is what you are optimizing, it's epoch count is up to you.
Simple is in the eye of the viewer, however it is not obvious IMHO how to configure the amount of generations being calculated. So when is this amount hit when I use --epoch 10 as parameter?
@thhart I think the number you're looking for is just epochs * generations

Running --evolve and after the first 10 epochs (first run out of 300 or whatever it is) i get the following error:
anchor_t anchors box cls cls_pw degrees fl_gamma fliplr flipud giou hsv_h hsv_s hsv_v iou_t lr0 lrf mixup momentum mosaic obj obj_pwperspective scale shear translatewarmup_bias_lrwarmup_epochswarmup_momentumweight_decay
4 3 0.05 0.5 1 0 0 0 0 0.05 0.014 0.68 0.36 0.2 0.01 0.2 0 0.937 1 1 1 0.001 0.5 0 0 0.1 3 0.8 0.0005
Evolved fitness: 0.4112 0.2054 0.2402 0.08847 0.04911 0.02177 0.02316
Traceback (most recent call last):
File "train.py", line 578, in
hyp[k] = float(x[i + 7] * v[i]) # mutate
IndexError: index 28 is out of bounds for axis 0 with size 28
Any idea what is wrong?
@LinusJ79 if you believe you have a reproducible bug please raise a full bug report issue using the bug report template with code to reproduce, thank you!

Hi! A few questons regarding evolve @glenn-jocher
1: why hasn't fl_gamma, flip_ud or iou_th changed in your picture?
2: Why are only 22 of the 28 hyperparameters evolved?
2: Is there a way to lock in certain hyperparameters that I know I want at a certain value?
3: Is mosiac disabled as usual with -rect?
- You can disable evolution for any parameters using the meta dictionary in train.py, or by setting their initial values to zero in your hyp.yaml file.
- The displayed results are from an earlier version with less hyperparmeters, we should update this.
- Yes, see #1 above, use
metadict. - Yes --rect causes mosaic to be disabled.

@glenn-jocher If we initialise any hyper parameter with 0 and the minimum value is also 0.0 then it doesn't evolve because -
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
@abhiagwl4262 yes this is correct. The mutations are gain-based so a zero initial condition will prevent it from mutating.
@glenn-jocher As initial values of hyper-parameter, we are using hyp.scratch which have some parameters initialised with 0. So, those parameters are not taking part in mutation. Can you please add hyp.scratch that sets better initialisation for Hyper-parameters.
@abhiagwl4262 yes I see. You may want to use hyp.finetune.yaml to see if it's a better starting point for evolution.
If you want you can also increase the zero values in hyp.scratch slightly, i.e. to 0.01 or 0.1 to initialize them for evolution.

What is the population size for the GA? It seems it only trains 1 model? Is this correct? If so, what is it performing crossover with?
@NMVRodrigues yes that is correct, population size is 1 due to high expense of each member, so we omit crossover and apply mutation to a randomly selected top-5 member from all previous populations. The implementation is here. If you have ideas for improvement please let us know!
Lines 572 to 597 in ed2c742
@glenn-jocher Well in this scenario that would not ensure the exploitation of optimal solutions. There are other mutation operators that could be added, or just replace the standard one, to improve this scenario without any significant complexity/expense increase. I would be glad to try and implement them to help and improve this feature!
@NMVRodrigues yes, this is a challenge as we have a unique problem set that is not quite suited to the off-the-shelf GA methods, mainly due to the very high evaluation cost of a single population member, so the current implementation is the best compromise we found. Feel free to submit PRs with any updates to the evolution code in train.py if you see spots for improvement!

I have a problem when I evolve the hyper params, there is no model.pt in the evolve folder,and the wandb broke out a error.I think it is because the weight didn't save but transfered to wandb, in my code it is at line445.
I changed the no save option to avoid this error, but it can't evolve.
I disable the wandb and it can run correctly.
Can you fix this? thanks in advance.

@zzttqu thanks for the info! Evolution will not save any checkpoints (for speed). If you believe you have a reproducible bug, please raise a new issue using the 🐛 Bug Report template, providing screenshots and a minimum reproducible example to help us better understand and diagnose your problem. Thank you! @AyushExel seems like --evolve with wandb may have a problem.

@glenn-jocher okay I'll try to reproduce this and fix it after our meeting. Can we also include a CI test for evolve to automate this process in the future ?
@AyushExel evolve CI is an interesting idea. I'd need to add an optional argument to --evolve in some way because currently evolution is hard-coded to 300 generations.
@glenn-jocher @zzttqu I found the problem. The default behaviour now is to log the final stripped model but the model is not found in case of evolve operation. I'll just push a quick fix
This should fix the problem #2634

@glenn-jocher Hi, sorry for bothering you. I have a question about hyperparameter evolve. I first evolved my own model No.1 (which is based on yolov5s) for 10 generations and trained a new model No.2 based on new hyperparameters. Then I would like to continue the evolution. According to what you said in another thread, if the 'evolve.txt' exists, then I just need to run the same command (which evolves on model No.1). However, when I ran the command, I found that the hyperparameters displayed at the start do not match with the hyperparameters in the evolve.txt (ones I used to train model No.2). I just wonder is this correct? Sorry if it is trivial, I am new to this area. Thank you for your time and help in advance!
@psyjw they should not match, you are starting a new generation.
@glenn-jocher Much thanks! I thought it will display the last generation's hyperparameters. By the way, could you tell me is there any difference if I continue training evolution on model No.1 or I train evolution on model No.2? If I train on model No.2, does it still read the values from the 'evolve.txt'?
Evolution scenario is entirely up to you. Evolve.txt is the sole source used.

what is the mutate formula corresponding to the code below? @glenn-jocher
https://github.com/ultralytics/yolov3/blob/26cb451811b7aca5ddd069d03167c1db9b711a6b/train.py#L606
@youyuxiansen this is a probabilistic mutation equation bounded at upper and lower limits, prototyped using empirical results. There is no documentation other than the actual equation. To understand it better you can simply use it to generate a population of values and visualize the histogram of the population.
@youyuxiansen this is a probabilistic mutation equation bounded at upper and lower limits, prototyped using empirical results. There is no documentation other than the actual equation. To understand it better you can simply use it to generate a population of values and visualize the histogram of the population.
@glenn-jocher Thank you for such a timely response! I still have some questions. Can you explain the means of "mutation probability" and "sigma"? Why it be chosen to 0.8 and 0.2? And why the v be clipped to (0.3, 3.0)? I guess you must make some try on it right? I'm interested in learning about the inspiration! I would be grateful if you could talk about the details. Thanks!
@youyuxiansen all parameters above are based upon empirical results of YOLOv5 evolution experimentation with COCO
@youyuxiansen all parameters above are based upon empirical results of YOLOv5 evolution experimentation with COCO
Got it!Thanks.

I'm trying to run --evolve on 2 GPUs but the process is stuck at nohup: redirecting stderr to stdout
This is the shell script that I ran:
#!/bin/bash
for i in 1 2; do
nohup python train.py --img 640 --batch 16 --epochs 100 --data QMUL.yaml --weights yolov5m.pt --cache --evolve --device $i > evolve_gpu_$i.log &
done
Am I doing something wrong?
@OrjwanZaafarani you can always try the command without the nohup if it's causing problems, or you can redirect to /dev/null:
In ipython console:
# YOLOv5m6 evolve on COCO
for i in [0, 1, 2, 3, 4, 5, 6, 7]:
!python train.py --batch 32 --weights '' --cfg yolov5m6.yaml --data coco.yaml --epochs 300 --img 640 --hyp hyp.scratch-p6-evolve.yaml --evolve --device {i} > /dev/null 2>&1 &