Transfer Learning with Frozen Layers
glenn-jocher opened this issue · comments

📚 This guide explains how to freeze YOLOv5 🚀 layers when transfer learning. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also results in reductions to final trained accuracy. UPDATED 28 March 2023.
Before You Start
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7. Models and datasets download automatically from the latest YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installFreeze Backbone
All layers that match the freeze list in train.py will be frozen by setting their gradients to zero before training starts.
Lines 119 to 126 in 771ac6c
To see a list of module names:
for k, v in model.named_parameters():
print(k)
# Output
model.0.conv.conv.weight
model.0.conv.bn.weight
model.0.conv.bn.bias
model.1.conv.weight
model.1.bn.weight
model.1.bn.bias
model.2.cv1.conv.weight
model.2.cv1.bn.weight
...
model.23.m.0.cv2.bn.weight
model.23.m.0.cv2.bn.bias
model.24.m.0.weight
model.24.m.0.bias
model.24.m.1.weight
model.24.m.1.bias
model.24.m.2.weight
model.24.m.2.biasLooking at the model architecture we can see that the model backbone is layers 0-9:
Lines 12 to 48 in 58f8ba7
so we can define the freeze list to contain all modules with 'model.0.' - 'model.9.' in their names:
python train.py --freeze 10Freeze All Layers
To freeze the full model except for the final output convolution layers in Detect(), we set freeze list to contain all modules with 'model.0.' - 'model.23.' in their names:
python train.py --freeze 24Results
We train YOLOv5m on VOC on both of the above scenarios, along with a default model (no freezing), starting from the official COCO pretrained --weights yolov5m.pt:
$ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --img 512 --hyp hyp.finetune.yamlAccuracy Comparison
The results show that freezing speeds up training, but reduces final accuracy slightly.
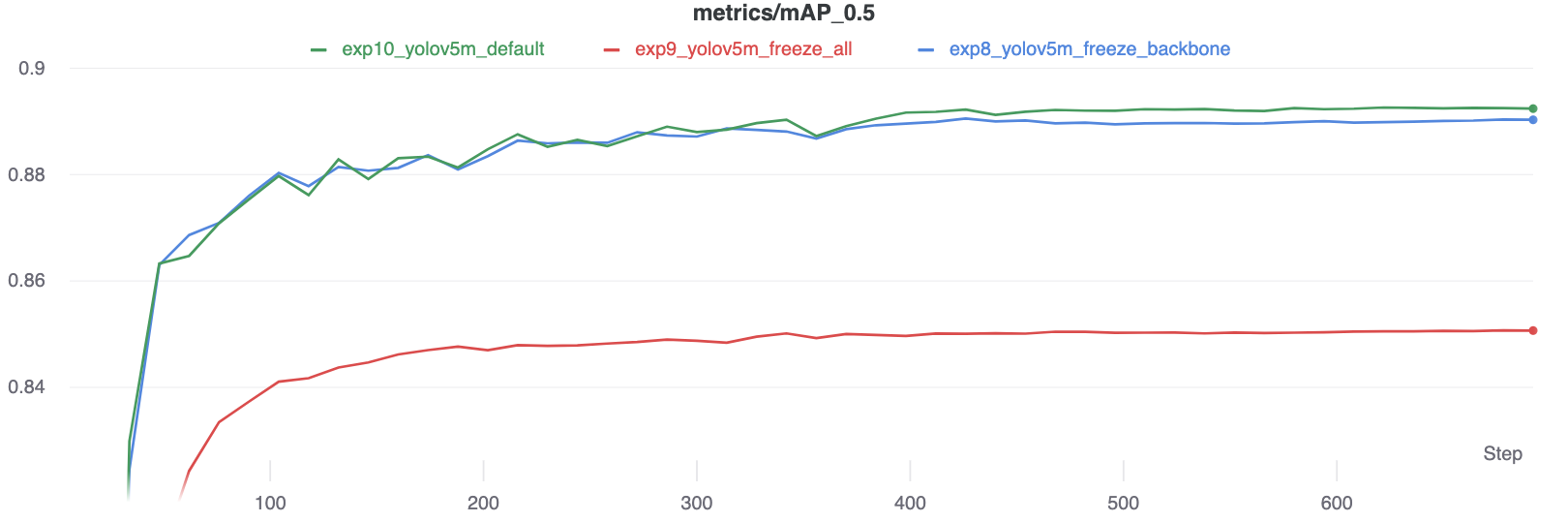
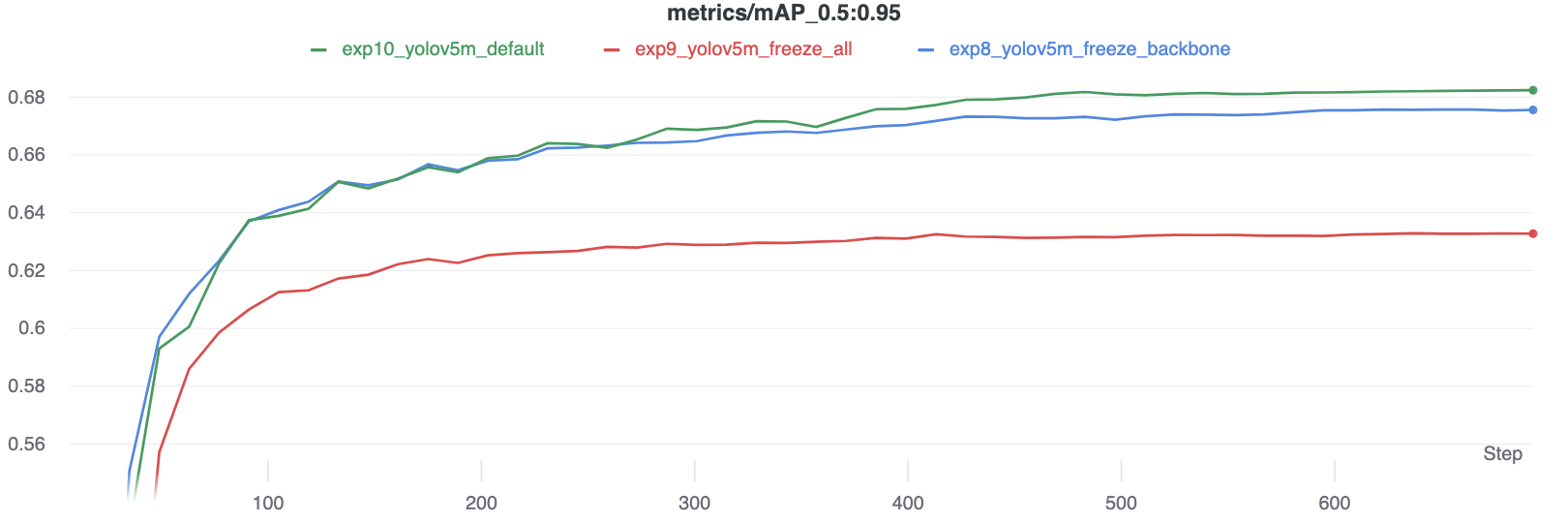
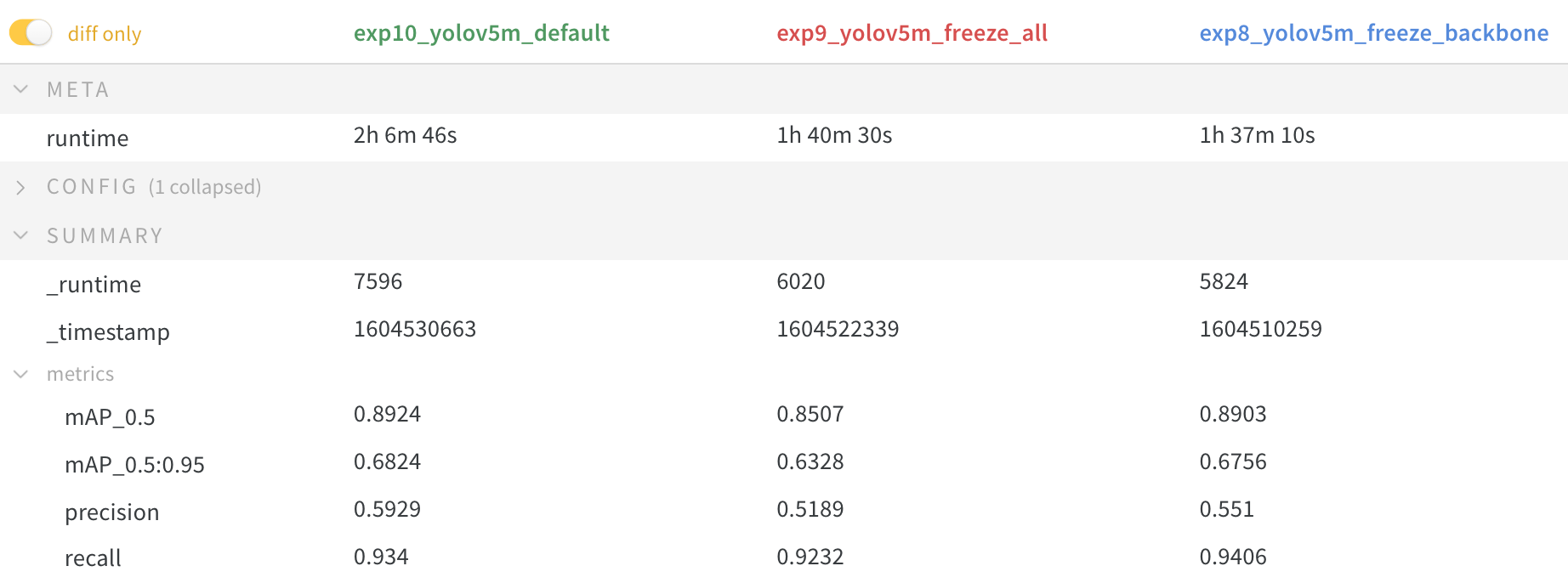
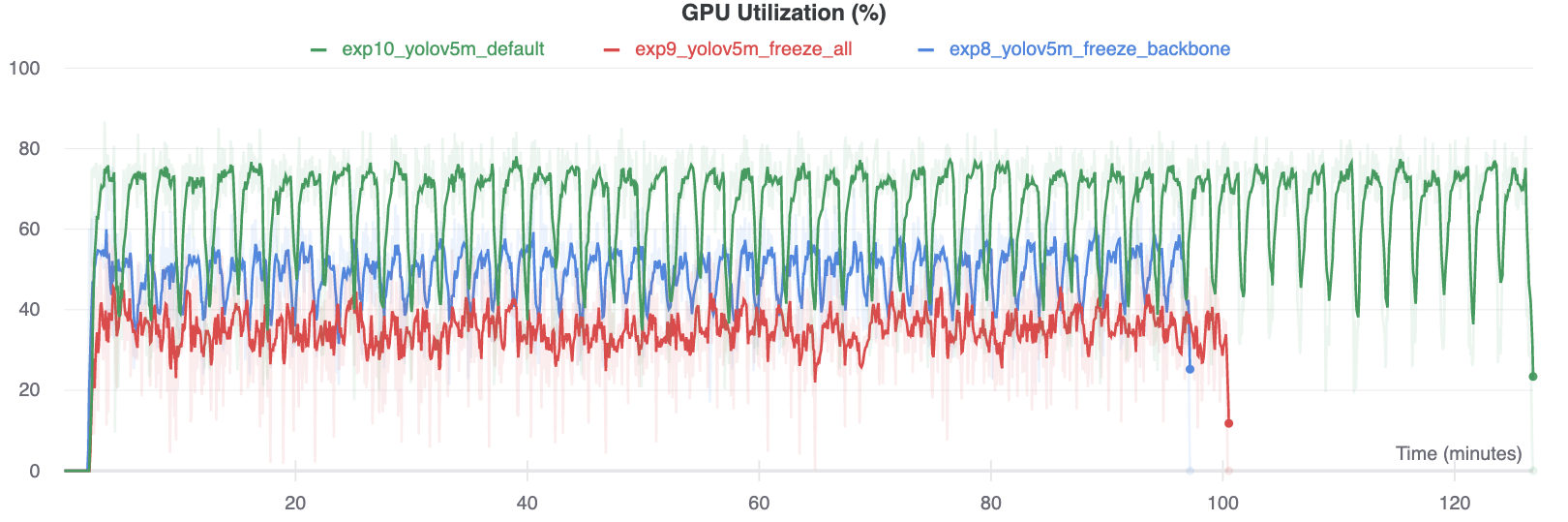
GPU Utilization Comparison
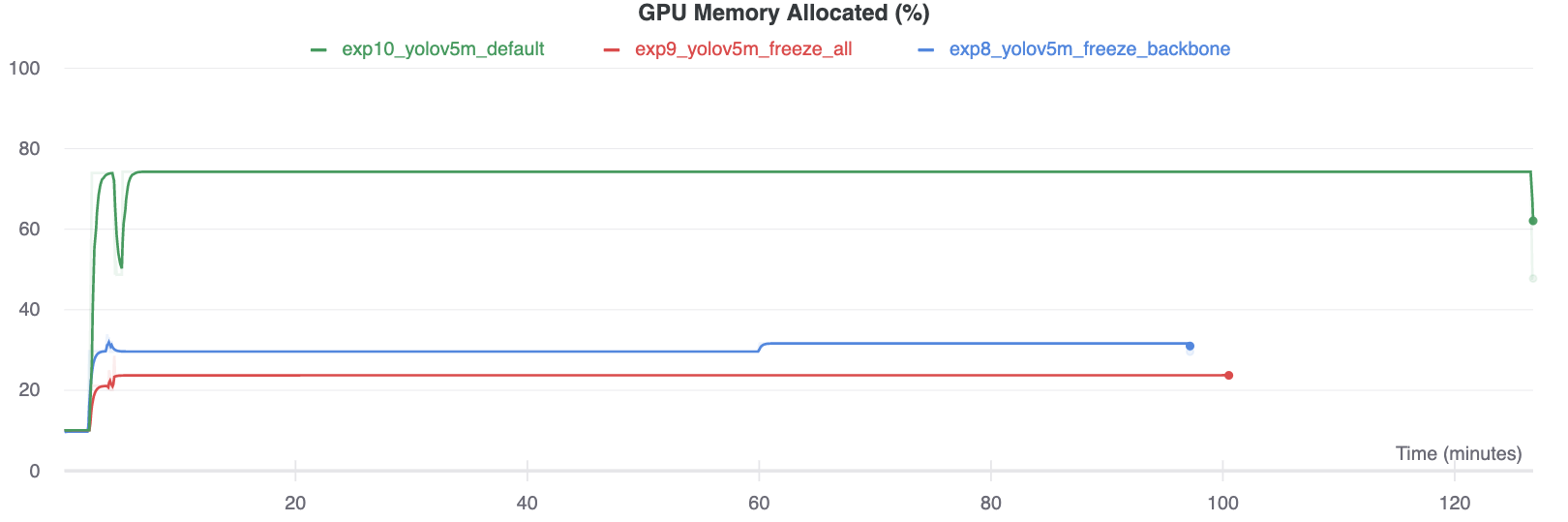
Interestingly, the more modules are frozen the less GPU memory is required to train, and the lower GPU utilization. This indicates that larger models, or models trained at larger --image-size may benefit from freezing in order to train faster.
Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide


Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit.

I noticed that there's an argument in yolov3 train.py code "--freeze-layer"?
Please, what does it do?
It states that it freezes all non-output layer?
Please can you provide more clarification about this?
Thank you.
Omobayode

@glenn-jocher Another dimension to this is generalization. I assume your results are shown for a test dataset. But for generalization to new datasets, freezing might also help prevent overfitting to ttraining data (and therefore improve robustness/generalization).
@mphillips-valleyit interesting point, though hard to quantify beyond existing val/test metrics.
It could be done with separate datasets--models pretrained on COCO, measure their generalization (freezing vs. non-freezing fine-tuning) to OpenImages for common categories. If I'm able to post results on this at some point, I will.

@mphillips-valleyit how is your custom data training result by transfer lerning ? could you attach you train log here?

@glenn-jocher Might be interesting to do a final step by unfreezing and training the complete netwerk again with differentiated learning rate. So complete training process would be (default method in fast.ai):
- Freeze the backbone
- (optional reset the head weights)
- Train the head for a while
- Unfreeze the complete network
- Train the complete network with lower learning rate for backbone
@ramonhollands that's an interesting idea, though I'm sure the devil is in the details, such as the epochs you take these actions at, the LRs used, dataset and model etc. I don't have time to investigate further, but you should be able to reproduce the above tutorial and apply the extra steps you propose to quantify differences. If you do please share your results with us.
One point to mention is that classification and detection may not share a common set of optimal training steps, so what works for fast.ai may not correlate perfectly to detection architectures like YOLO. Would be very interested to see experimental results.
Ill take that challenge the coming weeks. Trying to wrap your amazing work in the fast.ai framework to be able to use best of both worlds, including the fastai learning rate finder and discriminate learning rates etc. The method should work for detection architectures as well (https://www.youtube.com/watch?v=0frKXR-2PBY). Ill keep you updated.

I trained a model with an online dataset containing 5 categories, and now I'm trying to fine-tune it with my own images, which contain the same 5 categories plus an additional one. My images are similar to the ones from the online dataset, so I thought that transfer learning would work. However, this is what I obtain while fine-tuning:
Class = all, Images = 3, Targets = 0, P = 0, R = 0, mAP@.5 = 0, mAP@.5:.95 = 0
When I visualize the labels everything looks correct, so I don't understand is why Targets is 0. I also modified the dataset configuration yaml file adding the new category.
The fine-tuning works when I remove my additional category and fine-tune with the same 5 categories.
Does anybody know what am I doing wrong here?
Thanks in advance!

@aritzLizoain
I have done something similar. In my case, I created a dataset that borrows certain classes from COCO and OpenImages. Then I fine tuned a pretrained yolov5 (trained on COCO) model on my custom dataset. The performance of the fine-tuned model isn't good.
@ramonhollands LR finder sounds very cool, but be careful because sometimes LRs that work well for training can cause instabilities without a warmup to ramp the LR from 0 to it's initial value.
@aritzLizoain no targets found during testing means no labels are found for your images. Follow the Custom training tutorial to create a custom dataset:
https://docs.ultralytics.com/yolov5/tutorials/train_custom_data

While using Transfer Learning (both with layers freeze and without), it happens that model "forgets" data it was trained on (metrics on original data are getting worse). So, I think problem might be in too large learning rate. Can you please give a little bit more details on what hyperparameters should be changed when finetuning the model? (maybe change lr0 to the last lr that was during original training and removing warmup epochs, or is it a wrong approach?)

@glenn-jocher Might be interesting to do a final step by unfreezing and training the complete netwerk again with differentiated learning rate. So complete training process would be (default method in fast.ai):
- Freeze the backbone
- (optional reset the head weights)
- Train the head for a while
- Unfreeze the complete network
- Train the complete network with lower learning rate for backbone
How do you set a different learning rate for the backbone?
You have to split the backbone and head parameters and add additional param groups for both with different 'lr' argument (https://pytorch.org/docs/stable/optim.html). I wrote some initial code which Ill post later today.
See https://github.com/ramonhollands/different_learning_rates/blob/master/train.py
I have added two parameters to experiment with:
- freeze-backone (which freezes backbone on start and unfreezes after 4 epoch
- diff-backbone (which lowers the learning rate for backbone, divided by 10)
I started some experiments which where encouraging but did not have enough time to finish up yet.

@glenn-jocher I am curious about result pics in "Accuracy Comparison", why can the mAP of exp9_freeze_all increase as training progresses? Now that all params are frozed, they won't be optimized and performance should be a flat line?
@laisimiao exp9_freeze_all freezes all layer except output layer, which has an active gradient.

Hey @glenn-jocher , How do I add replace the FC output layer and add a new one??

I don't understand why the time to get train on the model with all frozen layers, it's more than the backbone frozen layer. It would not be the inverse??

Hi @glenn-jocher . I trained the model with icevision(a wrapper around this repo). However, I could not find out a proper way to export the model with export.py to TorchScript model. https://github.com/ultralytics/yolov5/blob/master/models/export.py
Saving the weights of yolo5 throws the following:
torch.save(model.state_dict(), "models/yolo.pth")
python export.py --weights ~/Documents/imageai/models/yolo.pt
Namespace(weights='/home/turgut/Documents/imageai/models/yolo.pt', img_size=[640, 640], batch_size=1, device='cpu', include=['torchscript', 'onnx', 'coreml'], half=False, inplace=False, train=False, optimize=False, dynamic=False, simplify=False, opset_version=12)
YOLOv5 🚀 v5.0-180-ge8c5237 torch 1.7.1+cu110 CPU
Traceback (most recent call last):
File "/home/turgut/Documents/yolov5/models/export.py", line 165, in <module>
export(**vars(opt))
File "/home/turgut/Documents/yolov5/models/export.py", line 47, in export
model = attempt_load(weights, map_location=device) # load FP32 model
File "/home/turgut/Documents/yolov5/models/experimental.py", line 120, in attempt_load
model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
KeyError: 'model'
If I save the model, then I get:
torch.save(model, "model.pth")
Namespace(weights='/home/turgut/Documents/imageai/model.pth', img_size=[640, 640], batch_size=1, device='cpu', include=['torchscript', 'onnx', 'coreml'], half=False, inplace=False, train=False, optimize=False, dynamic=False, simplify=False, opset_version=12)
YOLOv5 🚀 v5.0-180-ge8c5237 torch 1.7.1+cu110 CPU
Traceback (most recent call last):
File "/home/turgut/Documents/yolov5/models/export.py", line 165, in <module>
export(**vars(opt))
File "/home/turgut/Documents/yolov5/models/export.py", line 47, in export
model = attempt_load(weights, map_location=device) # load FP32 model
File "/home/turgut/Documents/yolov5/models/experimental.py", line 119, in attempt_load
ckpt = torch.load(attempt_download(w), map_location=map_location) # load
File "/home/turgut/.local/share/r-miniconda/envs/r-reticulate/lib/python3.9/site-packages/torch/serialization.py", line 594, in load
return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
File "/home/turgut/.local/share/r-miniconda/envs/r-reticulate/lib/python3.9/site-packages/torch/serialization.py", line 853, in _load
result = unpickler.load()
File "/home/turgut/.local/share/r-miniconda/envs/r-reticulate/lib/python3.9/site-packages/torch/nn/modules/module.py", line 778, in __getattr__
raise ModuleAttributeError("'{}' object has no attribute '{}'".format(
torch.nn.modules.module.ModuleAttributeError: 'Model' object has no attribute 'param_groups_fn'
Is there a way to sort this out?
@turgut090 see TorchScript, ONNX, CoreML Export tutorial:
YOLOv5 Tutorials
- Train Custom Data 🚀 RECOMMENDED
- Tips for Best Training Results ☘️ RECOMMENDED
- Weights & Biases Logging 🌟 NEW
- Supervisely Ecosystem 🌟 NEW
- Multi-GPU Training
- PyTorch Hub ⭐ NEW
- TorchScript, ONNX, CoreML Export 🚀
- Test-Time Augmentation (TTA)
- Model Ensembling
- Model Pruning/Sparsity
- Hyperparameter Evolution
- Transfer Learning with Frozen Layers ⭐ NEW
- TensorRT Deployment
@glenn-jocher Thanks for your reply. Does this mean that I have to train a model only with this specific script? Here, I see:
https://docs.ultralytics.com/yolov5/tutorials/model_export
https://github.com/ultralytics/yolov5/blob/master/train.py in order to have checkpoints?
Lines 401 to 408 in bb79e13
Other options are yolov5m.pt, yolov5l.pt, and yolov5x.pt, or your own checkpoint from
training a custom dataset runs/exp0/weights/best.pt.
@turgut090 all tutorials in this repo operate correctly with models trained in this repo.
Naturally we can't speak to 3rd party implementations, nor do we provide support for them at this time.

Hi, thank you for your awesome works!
I have a question about the freezing backbone layers in detail.
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False ](`url`)
If you freeze like above, as my best knowledge, the running vars and means of batch normalization layer will be trained cause the module is not changed to eval mode like module.eval().
How do you think about this issue? I wonder it was intended.
Best,
Jihwan Eom
@JihwanEom the batchnorm learnable parameters gamma and beta are frozen by the above code, stats continue computing as normal while in train mode. See https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html
Thank you for kind explanation.
Then, the general freezing means only detaching gradients on parameters? Or include off tracking running means and vars?
@JihwanEom yes that's correct. The above freezing code only affects parameters and does not halt batchnorm stats updates (mean and var).

Hello!
Thank you for your article.
You can tell us in more detail how to add a new class to an already trained model.
That is, I trained the model to identify 5 objects, now I need the model to detect 6 classes, i.e. start finding another new one.
How to do it correctly?
I tried a frieze of 10 layers and 24, I tried to specify all 6 classes and only one new one in yaml for training, but the result was a model that finds the new class poorly and forgets the old ones.
@Partisanus you should train a model on all classes you want it to be able to detect on. See https://en.wikipedia.org/wiki/Catastrophic_interference
You can freeze or not freeze layers also, but this is a separate topic.

I am using pre-trained(on 80 coco classes) yolov5s.pt model and training it to detect 3 more classes. I used this data.yml file when i started training.
train: /content/yolov5/datasets/animal-dataset/train/images
val: /content/yolov5/datasets/animal-dataset/valid/images
nc: 83
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush', 'lion', 'frog', 'tiger']
according to above code i want to add lion, frog and tiger with index 80, 81 and 82 respectively.
and as described by @glenn-jocher, i added --freeze 10.
!python train.py --img 640 --batch 16 --epochs 5 --data data.yaml --weights yolov5s.pt --cache --freeze 10
but the problem i am facing is that now it only detects last 3 classes only not other 80 classes.
I tried this also in data.yaml: names: ['lion', 'frog', 'tiger'] with nc: 83 but nothings seems to work.
Please can someone help and provide more clarification about this?
Thanks,
Dhruvil Dave
@glenn-jocher I will try this also.
train: # train images (relative to 'path')
- images/data_a
- images/data_b
but i have one question here, I am using this coco dataset from roboflow https://public.roboflow.com/object-detection/microsoft-coco-subset. it already gives all the train and valid values in images-labels format.
This dataset has at-least 118k train images and my custom dataset has only 1900 train images.
My only question here:
will this going to affect the prediction rate for my custom dataset since the number of images in my dataset is much lower than the coco dataset which i will be using?
@dhruvildave22 yes, just as you say one dominant dataset will receive more attention than a smaller dataset if you train both at the same time.
We have a parameter called --image-weights in train.py which will sample images based on their performance, so poorly performing images should be then overly represented and the problem you describe may be mitigated. This is highly experimental, but you can try it out and see if it helps your situation.
Line 487 in 71621df

@glenn-jocher Might be interesting to do a final step by unfreezing and training the complete netwerk again with differentiated learning rate. So complete training process would be (default method in fast.ai):
- Freeze the backbone
- (optional reset the head weights)
- Train the head for a while
- Unfreeze the complete network
- Train the complete network with lower learning rate for backbone
Hi @ramonhollands @glenn-jocher .
I would like to ask you about this experiment. First of all, what is the benefit of freezing only the backbone, training the network and then retraining the whole network? I've been searching but I can't find anything related to this. I would like to apply this technique, but I don't know what is the benefit of training it that way, instead of training the net only once with the backbone frozen. On the other hand, what are the disadvantages?
Based on your evidence, is it a correct way to apply transfer learning in this way? what results you obtained?
I hope you can help me.
Best regards

Hi I have two YOLOV5L models with face detection and hand detection seperately. Is it possible to merge one YOLOv5L model able to detect both face and hand?
@jjjonathan14 the correct workflow is to train a single model on multiple datasets to create a single face, hand model:
https://community.ultralytics.com/t/how-to-combine-weights-to-detect-from-multiple-datasets

@glenn-jocher Might be interesting to do a final step by unfreezing and training the complete netwerk again with differentiated learning rate. So complete training process would be (default method in fast.ai):
- Freeze the backbone
- (optional reset the head weights)
- Train the head for a while
- Unfreeze the complete network
- Train the complete network with lower learning rate for backbone
Hi @ramonhollands @glenn-jocher . I would like to ask you about this experiment. First of all, what is the benefit of freezing only the backbone, training the network and then retraining the whole network? I've been searching but I can't find anything related to this. I would like to apply this technique, but I don't know what is the benefit of training it that way, instead of training the net only once with the backbone frozen. On the other hand, what are the disadvantages?
Based on your evidence, is it a correct way to apply transfer learning in this way? what results you obtained?
I hope you can help me. Best regards
@Juanjojr9 The backbone mainly acts as a general visual feature extractor that "may" generalize across different datasets. So starting from a well-trained backbone can make your network have good initial parameters that (1) may generalize well and (2) can fasten training. Headers are mainly trained for specific tasks (such as regressing bounding boxes and classification on specific dataset. You might want to train header weights specific to your custom dataset.
@jjjonathan14 the correct workflow is to train a single model on multiple datasets to create a single face, hand model: https://community.ultralytics.com/t/how-to-combine-weights-to-detect-from-multiple-datasets
thanks for the anwser. Is it possible to do meta learning with YOLOv5 models?
@jjjonathan14 what's meta learning?

Dear author, could you save the parameters of each layer of yolov5 into a Pt file, and then use multiple Pt files to form a new model for reasoning? What knowledge do I need to learn if I want to achieve this effect? thank you
@shizhanhao I don't understand your question exactly but it doesn't sound like a feasible plan to me.
@shizhanhao I don't understand your question exactly but it doesn't sound like a feasible plan to me.
thank you!

@jjjonathan14 what's meta learning?
Meta learning refers to a pretty broad area of "learning about learning" and can refer to multiple subfields. Usually, it refers to algorithms that learn about other algorithms. A classic example would be training 10 networks on the same task and data, and then having a "meta learner" learn to which of those networks to "listen to" for the final result. In essence - ensemble learning.

I think that only set "requires_grad = False " is not enough for BN layer, because BN has another two params that do not need to calc grad, but they will change as the training. Is that ok?
@ghoshaw these are not parameters subject to weight decay.


Hi, I want to know what hardware and pytorch version do you use in this experiment?

@glenn-jocher sir, when im doing my transfer learning in yolov5, the electricity cuts off and the training stops, my question is, can i still continue the training? can i use --resume? how to continue interrupted transfer learning?
@glenn-jocher sir, when im doing my transfer learning in yolov5, the electricity cuts off and the training stops, my question is, can i still continue the training? can i use --resume? how to continue interrupted transfer learning?

Ill take that challenge the coming weeks. Trying to wrap your amazing work in the fast.ai framework to be able to use best of both worlds, including the fastai learning rate finder and discriminate learning rates etc. The method should work for detection architectures as well (https://www.youtube.com/watch?v=0frKXR-2PBY). Ill keep you updated.
so have you figure out how to unfreeze backbone after epoch?

I just want to detect person and motorcycle classes, how can I reduce the number of parameters?

I just want to detect person and motorcycle classes, how can I reduce the number of parameters?
The most straightforward way would be to use a smaller existing model of nano than small in the Terminal output you showed YOLOv5s:
--cfg yolov5n.yaml
You can further set the numbers to be smaller if you want a smaller model than the nano one:
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
https://github.com/ultralytics/yolov5/blob/master/models/yolov5n.yaml#L5-L6
@bryanbocao hi there! It's great that you're looking to optimize the model for your specific use case. To reduce the number of parameters, you can consider using a smaller existing model such as nano instead of small in the YOLOv5 model configuration. Additionally, you can adjust the depth_multiple and width_multiple parameters in the configuration file to further reduce the size of the model. You can find these settings in the yolov5n.yaml file at lines 5-6. I hope this helps!
@glenn-jocher Thanks for your reply!
Additionally, you can adjust the depth_multiple and width_multiple parameters in the configuration file to further reduce the size of the model.
That's what I did eventually :)
@bryanbocao you're welcome! Great to hear that you found a solution by adjusting the depth_multiple and width_multiple parameters. If you have any more questions or need further assistance, feel free to ask. Good luck with your YOLOv5 project!

I am not sure if this is the right place to ask it. But I have a Yolo5x6 model that I want to "convert" to a Yolo5n or Yolo5s model weights. Is there some technique to do that, without having to retrain the model from scratch?
@skyprince999 hi there! The process you're referring to is known as model distillation or compression, where a larger model (teacher) is used to guide the training of a smaller model (student). However, directly converting weights from a larger model like YOLOv5x6 to a smaller architecture like YOLOv5n or YOLOv5s isn't straightforward because the architectures differ significantly in terms of layer depth and width.
To achieve a smaller model with the knowledge of the larger one, you would typically perform knowledge distillation, which involves training the smaller model using the larger model's outputs as guidance. This process still requires training from scratch but can be faster and result in a more accurate small model than training it directly on the dataset.
For now, YOLOv5 does not support direct weight conversion between different model sizes. You would need to train the smaller model using the standard training procedures, potentially using the larger model's weights for initializing the training process, or you could explore knowledge distillation techniques.
If you're looking to maintain as much performance as possible without retraining from scratch, you might consider fine-tuning the smaller model on your dataset using the larger model's weights as a starting point. This would involve using the --weights flag with the pre-trained larger model's weights and training on your dataset with the smaller model configuration.
Thanks @glenn-jocher for the update. I am aware of the knowledge distillation process. But was wondering if Yolo had some inbuilt mechanism to work with it. Not sure how its done, but I like the idea of initializing the weights of the smaller model with those from the larger model and then training it on the dataset. I'll explore that option.
@skyprince999 You're welcome! Indeed, YOLOv5 doesn't have an inbuilt mechanism for model distillation, but initializing the smaller model with weights from the larger one and then fine-tuning on your dataset is a practical approach. This method leverages the pre-trained knowledge and can lead to better performance than training from scratch. If you need further guidance on fine-tuning or have any other questions, feel free to reach out. Happy coding! 😊🚀

@glenn-jocher Might be interesting to do a final step by unfreezing and training the complete netwerk again with differentiated learning rate. So complete training process would be (default method in fast.ai):
- Freeze the backbone
- (optional reset the head weights)
- Train the head for a while
- Unfreeze the complete network
- Train the complete network with lower learning rate for backbone
Hi @ramonhollands, I am doing the same thing. First, I train the model with a dataset by freezing the head (--freeze 24), then I do another training on the same data, initializing the weights with the previously trained weights (output from the training with freezing) and passing those weights as initial weights (--weights runs/exp/weights/last.pt). Additionally, I pass --hyp where lr1 and lr0 are reduced by 10 times.
In this process, I am training twice on the same dataset. @glenn-jocher @ramonhollands, can you help me reduce this training time by making it the default, where the head will be trained with a low learning rate and the body will be trained with a high learning rate?
Hi @sriram-dsl! Your approach of using a differentiated learning rate after unfreezing the network is indeed a solid strategy, often leading to better fine-tuning of the model. To implement this in YOLOv5, you can adjust the learning rates directly in the hyp.yaml file used during training. Here’s a quick example of how you might set this up:
-
Freeze the backbone and train:
python train.py --freeze 24 --weights yolov5s.pt --data yourdata.yaml --epochs 10
-
Unfreeze and train with differentiated learning rates:
python train.py --weights runs/train/exp/weights/last.pt --data yourdata.yaml --epochs 30 --hyp yourhyp.yaml
In your yourhyp.yaml, specify lower learning rates for earlier layers (backbone) and higher for later layers (head):
lr0: 0.001 # lower base learning rate for backbone
lr1: 0.01 # higher base learning rate for headThis setup should help streamline the process and potentially reduce total training time by more effectively leveraging the initial frozen training phase. 😊👍
@sriram-dsl hi there! Yes, you're correct. In the hyp.scratch-low.yaml, you should adjust lr0 for the base learning rate and lrf for the final learning rate multiplier. This setup allows you to control the learning rates for different parts of the model more effectively during the training process. Here's a quick example:
lr0: 0.001 # lower base learning rate for backbone
lrf: 0.1 # learning rate multiplier for final layersThis configuration helps in fine-tuning the model by applying different learning rates to the backbone and the head. Thanks for pointing that out! 😊👍