Weights & Biases with YOLOv5 🌟
glenn-jocher opened this issue · comments

- About Weights & Biases
- First-Time Setup
- Viewing runs
- Disabling wandb
- Advanced Usage: Dataset Versioning and Evaluation
- Reports: Share your work with the world!
About Weights & Biases
Think of W&B like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models — architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
- Debug model performance in real time
- GPU usage visualized automatically
- Custom charts for powerful, extensible visualization
- Share insights interactively with collaborators
- Optimize hyperparameters efficiently
- Track datasets, pipelines, and production models
First-Time Setup
Toggle Details
When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device.W&B will create a cloud project (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run name within that project as project/name. You can also manually set your project and run name as:
$ python train.py --project ... --name ...YOLOv5 notebook example:


Viewing Runs
Toggle Details
Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in realtime . All important information is logged:- Training & Validation losses
- Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95
- Learning Rate over time
- A bounding box debugging panel, showing the training progress over time
- GPU: Type, GPU Utilization, power, temperature, CUDA memory usage
- System: Disk I/0, CPU utilization, RAM memory usage
- Your trained model as W&B Artifact
- Environment: OS and Python types, Git repository and state, training command

Disabling wandb
-
training after running
wandb disabledinside that directory creates no wandb run
-
To enable wandb again, run
wandb online
Advanced Usage
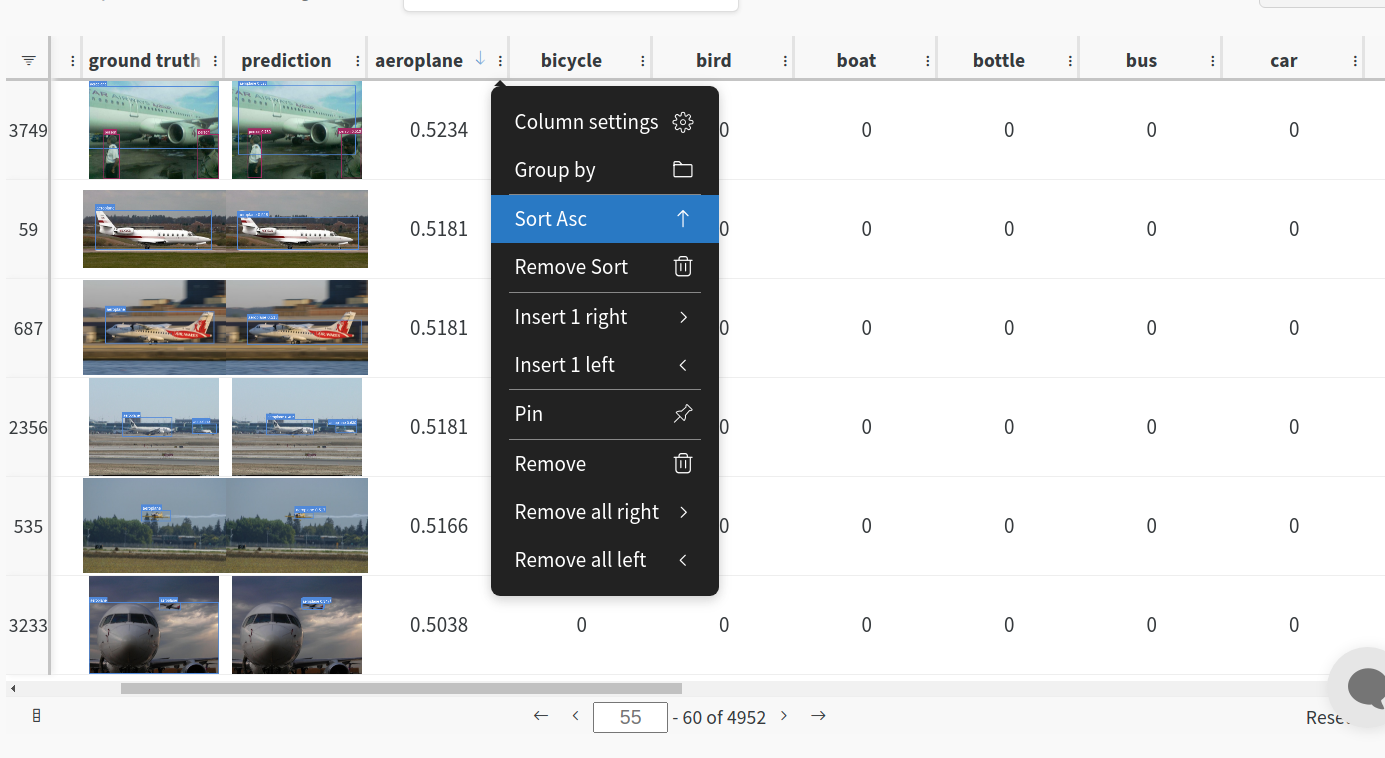
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
1: Train and Log Evaluation simultaneousy
This is an extension of the previous section, but it'll also training after uploading the dataset. This also evaluation Table Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets, so no images will be uploaded from your system more than once.Usage
Code $ python train.py --upload_data val
2. Visualize and Version Datasets
Log, visualize, dynamically query, and understand your data with W&B Tables. You can use the following command to log your dataset as a W&B Table. This will generate a{dataset}_wandb.yaml file which can be used to train from dataset artifact.
Usage
Code $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data ..

3: Train using dataset artifact
When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that can be used to train a model directly from the dataset artifact. This also logs evaluationUsage
Code $ python train.py --data {data}_wandb.yaml

4: Save model checkpoints as artifacts
To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval. You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be loggedUsage
Code $ python train.py --save_period 1

5: Resume runs from checkpoint artifacts.
Any run can be resumed using artifacts if the--resume argument starts with wandb-artifact:// prefix followed by the run path, i.e, wandb-artifact://username/project/runid . This doesn't require the model checkpoint to be present on the local system.
Usage
Code $ python train.py --resume wandb-artifact://{run_path}

6: Resume runs from dataset artifact & checkpoint artifacts.
Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device The syntax is same as the previous section, but you'll need to lof both the dataset and model checkpoints as artifacts, i.e, set bot--upload_dataset or
train from _wandb.yaml file and set --save_period
Usage
Code $ python train.py --resume wandb-artifact://{run_path}
Reports
W&B Reports can be created from your saved runs for sharing online. Once a report is created you will receive a link you can use to publically share your results. Here is an example report created from the COCO128 tutorial trainings of all four YOLOv5 models ([link](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY)).
Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Notebooks with free GPU:
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide

Status
![]()
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit.

Really cool, I suffer from delaying update due to the google drive file system on Colab. Can't wait to try this method.
@ChristopherSTAN yes, this is similar to the Google Drive with Colab trick you discovered earlier. It adds a few useful features also like public sharing of your runs, and GPU monitoring:
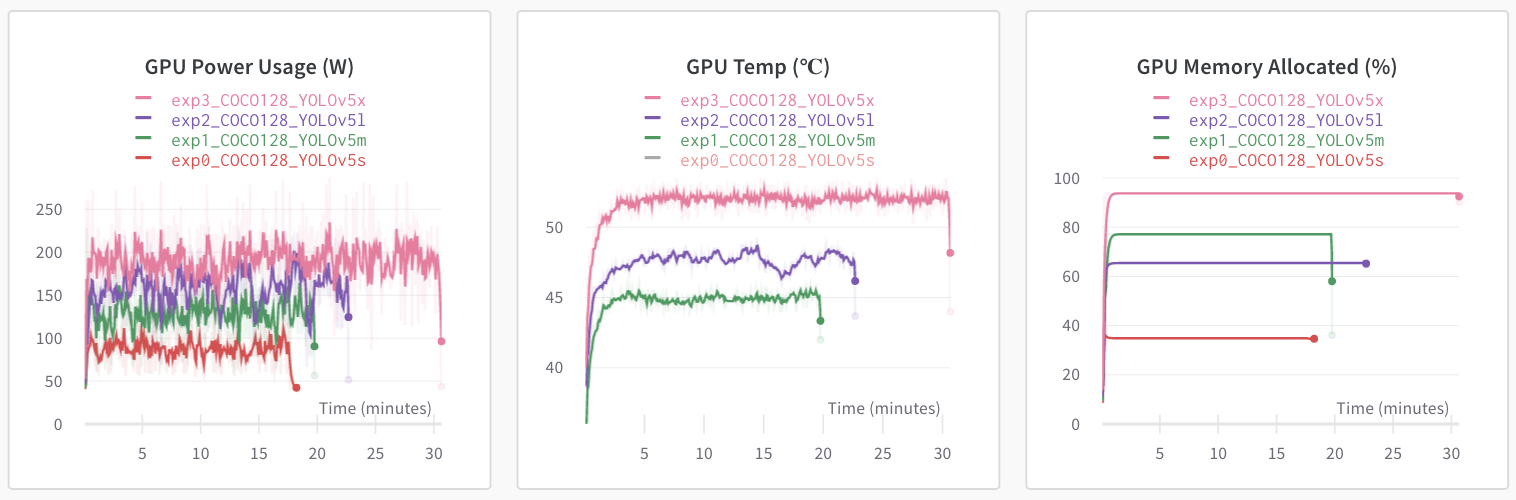
And also good metadata saving, allowing for better reproducibility:
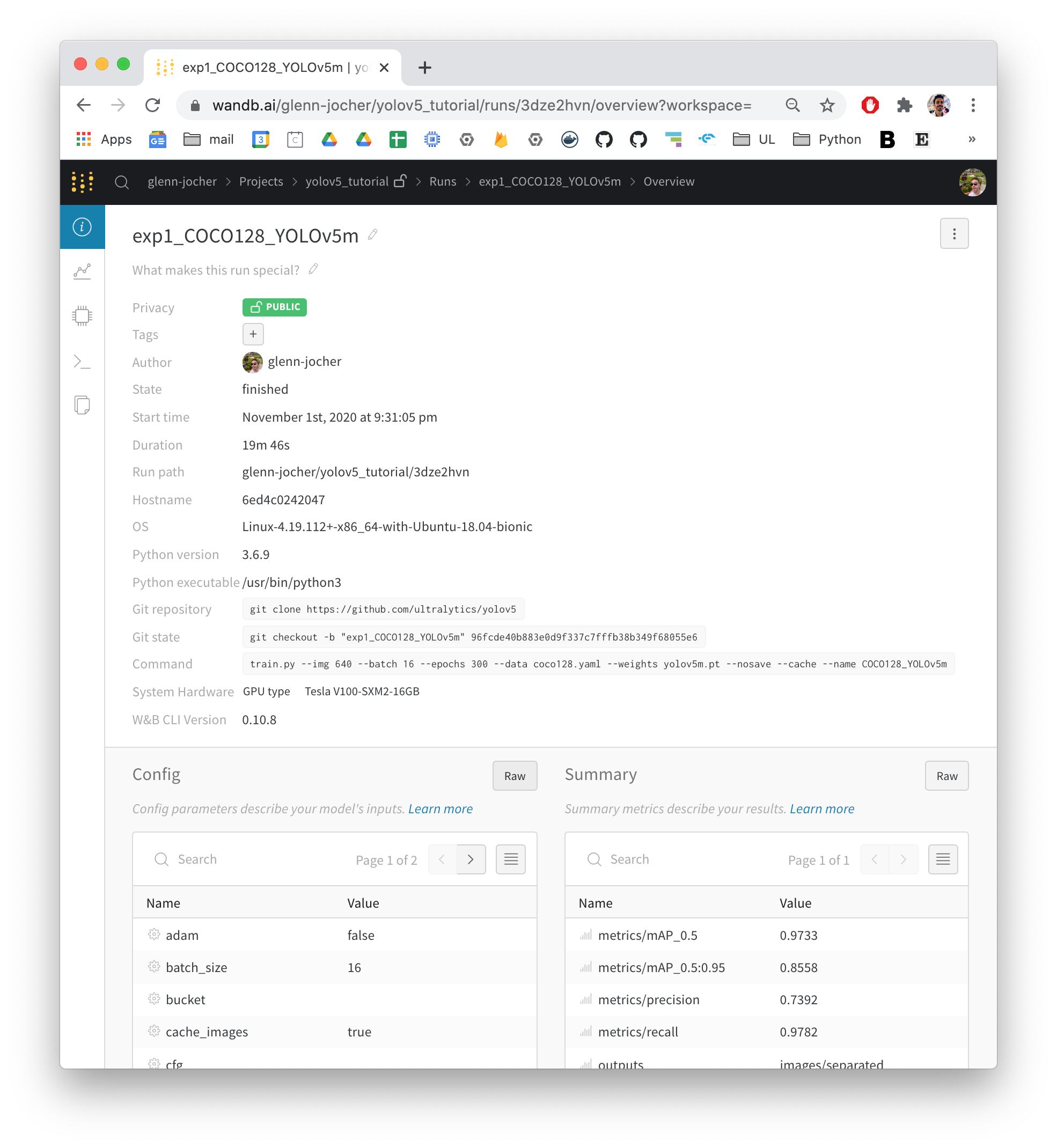

@ChristopherSTAN yes, this is similar to the Google Drive with Colab trick you discovered earlier. It adds a few useful features also like public sharing of your runs, and GPU monitoring:
And also good metadata saving, allowing for better reproducibility:
A stupid question. How can you produce the picture with shadow, it looks elegant.

@bamboosdu It is a screenshot with extra white background. Shadow is already included.
@sithu31296 yes, you to take the screenshot at just the right time of day to get the correct shadow.

Hello @glenn-jocher, and thanks for this really useful tool.
I face two issues though :
- i don't see any parser for the --logdir argument in train.py, so even after having pulled the last YOLOv5 version this way of launching a training yields an error
- is it intended that the default run save paths are different than with a native YOLOv5 run (./yolov5/runs/train/ vs ./yolov5/runs/ before) ?
The only think i could think of regarding these issues is that i am still running my trainings under Python 3.6.5 that, if i'm not mistaken, was still recent enough a few weeks back.
What do you think ?
Thanks in advance !
J.
@codename5281 default directories have been updated in Unified '/project/name' results saving #1377. See Custom Training Tutorial and Colab notebook for new examples.
https://github.com/ultralytics/yolov5#tutorials

Thank you for the informations!
@glenn-jocher Could you tell me how I can implement a cross-validation k-fold in YOLOv5 associated with W&B?
I would like to evaluate the 5-fold charts at the same time.
@karasinski-mauro interesting question. I was reading up a bit of k-fold validation at https://scikit-learn.org/stable/modules/cross_validation.html, and it seems like an interesting idea to reduce reliance on a particular split, but at the same time very computationally expensive and perhaps not suitable for most applications.
If you are interested in applying it nonetheless, it would require a bit of additional custom code. One thing I can point you to is the autosplit() we have in YOLOv5, which will take a directory of images and randomly split them according to your requested ratios. You can run this several times to create independent k-fold splits for your data.
Lines 918 to 923 in c0ffcdf

I'm facing a problem with logging into wandb. Instead of each run to be logged separately, it merges with an existing run within a project. Is yolov5 facing some issue with wandb? anyone with a similar problem? Also cannot move the runs from one project to another in wandb profile.
@thesauravs yes this was a bug we patched a few days ago in #1852. Please git pull to receive this update and let us know if you have any other issues!
@thesauravs yes this was a bug we patched a few days ago in #1852. Please
git pullto receive this update and let us know if you have any other issues!
I'm using colab notebook and command git clone. The problem persists.
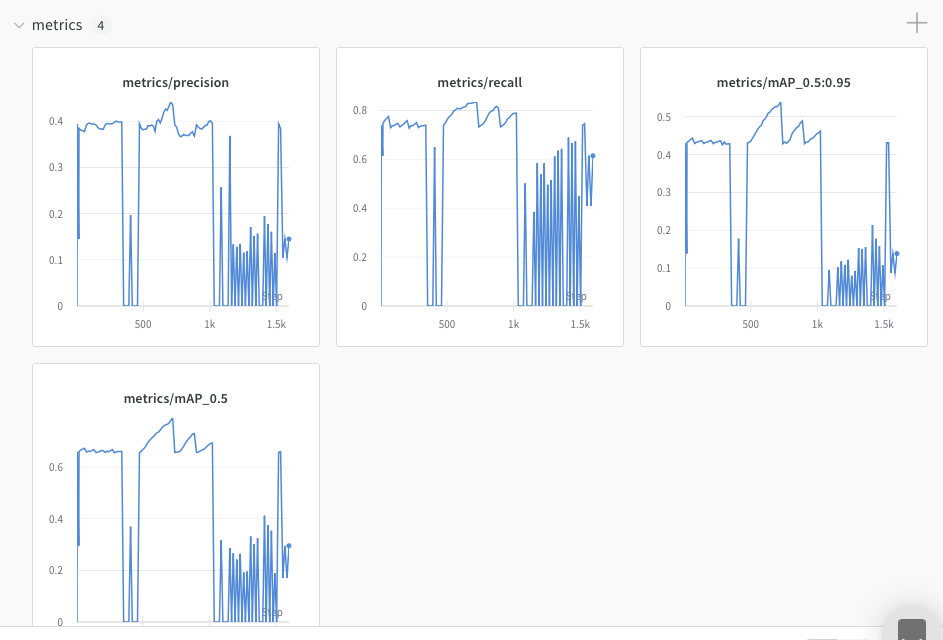
@thesauravs if the issue is reproducible please open a bug report with exact code to reproduce.

Hi @glenn-jocher, is there a way to visualize mAP/P/R/losses vs epoch instead of step or wall time in wandb.ai?
@lrbrrr yes! This change was implemented in a recent PR about a week ago, apologies for the lengthy wait. If you git pull and train again your wandb dashboard will log per epoch now.
@lrbrrr yes! This change was implemented in a recent PR about a week ago, apologies for the lengthy wait. If you git pull and train again your wandb dashboard will log per epoch now.
I just tried this coco128 dataset on google colab. I don't see the epoch as option for x-axis.
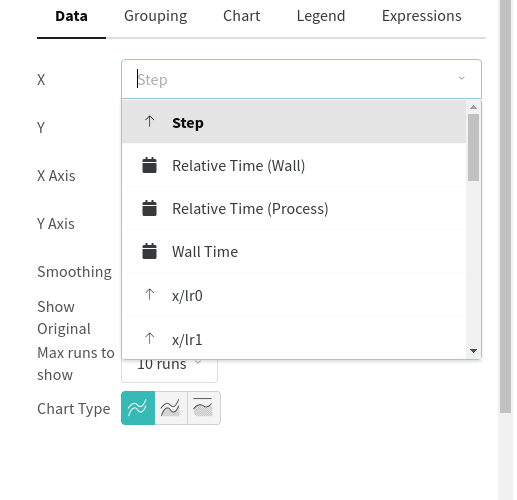
@lrbrrr plotting defaults to epochs on the x axis now, no action is required on your part (there's no need to select anything).

Hi Glenn
We are an academic group currently working on producing a paper in the title of Olive harvesting using Yolov5 architecture. We are pleased with the olive detection output results from Yolo 5 which showed a robust precision and mAP compared to other Yolo versions and RCNN algorithms. However, we are currently trying to test different hyperparameters using sweep from WandB. All the attempts in implementing sweep in the train.py file were failed. We appreciate it if you could help us with the issues as we have limited time in submitting the paper. We finally got this error after we delete all action="store_true" from arg parser:
train.py: error: unrecognized arguments: --batch_size=29 --cache_images=true --exist_ok=false --global_rank=-1 --hyp.anchor_t=8 --hyp.box=0.07246915121169895 --hyp.cls=0.8503969655436721 --hyp.cls_pw=1 --hyp.fliplr=0.2868210743865315 --hyp.hsv_h=0.028518921869036012 --hyp.hsv_s=1.234917241085553 --hyp.hsv_v=0.23896492378841477 --hyp.iou_t=0.1541829325843371 --hyp.lr0=0.014132676777321062 --hyp.lrf=0.15258688586250735 --hyp.momentum=0.9728345474816077 --hyp.mosaic=1 --hyp.obj=2 --hyp.obj_pw=2 --hyp.scale=0.39897504402382566 --hyp.translate=0.069231722815808 --hyp.warmup_bias_lr=0.08910230413617964 --hyp.warmup_epochs=5 --hyp.warmup_momentum=0.6153657972615175 --hyp.weight_decay=0.0007967895019431605 --image_weights=true --linear_lr=false --log_artifacts=false --log_imgs=11 --multi_scale=false --save_dir=runs/train/exp --single_cls=false --sync_bn=false --total_batch_size=9 --world_size=1
@jaafreh ah good question. I'm not an expert in sweeps but perhaps @AyushExel could help you here. It might be good to create a sweeps tutorial. I've experimented in the past, i.e. here https://wandb.ai/glenn-jocher/COCO128_evolve with a 300-generation evolution for COCO128.
The way I did the above evolution was to evolve hyps following the Hyperparameter Evolution Tutorial, and then visualize the results using either the built-in plots or also the W&B sweeps visualizer.

@glenn-jocher sure I think we can come up with a nice sweeps tutorial. Let's discuss the details in our meeting tonight.

Any idea why my YOLOv5 W&B runs aren't getting an "outputs" section, as in the above screenshot? I'm very interested in using W&B's dynamic "show predicted bounding boxes at each training step" feature demonstrated at 3:00 in this video, but I can't see to figure out how to do that!
(I'm using the latest master version of YOLOv5.)
Hi @adrianholovaty, In a previous update, the bounding box logger was updated to log only in the final epoch. But we're working on building a better W&B integration where you'll be able to set an argparse --bbox-interval to set the number of epochs-interval after which the bounding boxes will be plotted. If it is set to 1, the boxes will be plotted after every epoch. We'll keep you updated on the progress
@AyushExel Thanks, that makes perfect sense. Keep up the great work — you guys are awesome!

Hello Guys, @glenn-jocher
I'm a beginner training yolov5s on the custom dataset.
Question
1) What is the standard data size required for yolo5 model training (FOR Good model)
NOTE : Some of images are unannotated

2) How much map@ score should I need to get the best inference on real-world data and how to improve that?
Thanks,
@Practcdi hi there! Please see our Tips for Best Training Results
YOLOv5 Tutorials
- Train Custom Data
🚀 RECOMMENDED - Tips for Best Training Results
☘️ RECOMMENDED

@glenn-jocher how can i visualize iteration based train loss in wandb?
@fcakyon iteration means one optimizer update typically, or one batch processed, but losses and metrics are only logged at the end of each epoch. Losses within each epoch are not saved.
@glenn-jocher by iteration based, i mean logging the training loss at every 100 iteration, for instance.
Other frameworks such as mmdetection send the training loss logs after each iteration windows (per 100 iteration for instance) to wandb and send the validation accuracy after each epoch.
One epoch may take 5-6 hours to complete, so being able to visualize loss within epoch (instead of waiting a full epoch) tells a lot on he future of training.
Does it make sense to you?
@fcakyon ah yes that makes sense. Unfortunately we don't have a similar capability right now, we'd need some updates to train.py in order to do this. I can see some epochs taking very long, i.e. OIv6 or Objects365. The main workaround currently is to view training losses directly in the 'Logs' panel which seems to update every few seconds.
https://wandb.ai/glenn-jocher/activations/runs/tlau254q/logs
@glenn-jocher i see, thanks for the fast response!


I keep getting the error AttributeError: module 'utils.loggers.wandb' has no attribute 'Image' in the init.py file inside utils/loggers folder when trying to train my custom dataset on YOLOv5.
I've made sure I have the latest version of the git repo, as well as wandb, installed, I tried a couple of workarounds like using 'wandb.sdk.data_types.image.Image' or 'wandb.data_types.Image'
But even with these I still keep getting the error of attribute not found, and I've spent almost my entire Sunday trying to figure out why this isn't recognizing the wandb attribute...
PLEASE help if you can @glenn-jocher , because my engineering project is kind of hanging on the line if I can't get it trained
@KAttal007
https://wandb.ai/glenn-jocher/test/runs/1gitmoxr
We've created a few short guidelines below to help users provide what we need in order to start investigating a possible problem. Once we have this then @AyushExel, our wandb expert can look into the problem.
How to create a Minimal, Reproducible Example
When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to reproduce the problem. This is referred to by community members as creating a minimum reproducible example. Your code that reproduces the problem should be:
✅ Minimal – Use as little code as possible to produce the problem✅ Complete – Provide all parts someone else needs to reproduce the problem✅ Reproducible – Test the code you're about to provide to make sure it reproduces the problem
For Ultralytics to provide assistance your code should also be:
✅ Current – Verify that your code is up-to-date with GitHub master, and if necessarygit pullorgit clonea new copy to ensure your problem has not already been solved in master.✅ Unmodified – Your problem must be reproducible using official YOLOv5 code without changes. Ultralytics does not provide support for custom code⚠️ .
If you believe your problem meets all the above criteria, please close this issue and raise a new one using the
Thank you!

python train.py --upload_data val
hello @glenn-jocher , when i run this command ‘python train.py --upload_data val“ in yolov5 5.0,it occurs: "Instances of wandb.Artifact and wandb.apis.public.Artifact can only be top level keys in wandb.config". I wonder if it's a version problem? may be i should use the latest v6.1? Thank you!
@angbaozhang uploading data as artifact requires wandb==0.12.10 or lower. See this warning https://github.com/ultralytics/yolov5/blob/master/utils/loggers/__init__.py#L86

How does the review from the ip camera in Yolov5 help?

Hello @glenn-jocher ,I am trying to train the model with W&B offline, although I set the "WANDB_MODE" as "offline" in train.py, it always displays network error. So I want to ask you what should I do to train the model with W&B offline.Thank you very much! By the way, my server can't get online
@ma-muyuan have you tried wandb disabled?
Hi @AyushExel , I haven't try wandb disabled, I will try if I don't have any other way.Thank you very much.