系统以Bangumi的动画数据为基础,分别通过深度学习算法Word2Vec、Wide&Deep实现推荐系统的召回层和排序层,使用用户的动画收藏序列训练模型,实现为用户推荐动画,相似动画以及推荐相似用户的功能。可以实时监控用户最新收藏的动画,及时更新用户特征,优化推荐结果,使其反映出用户的最新兴趣变化。
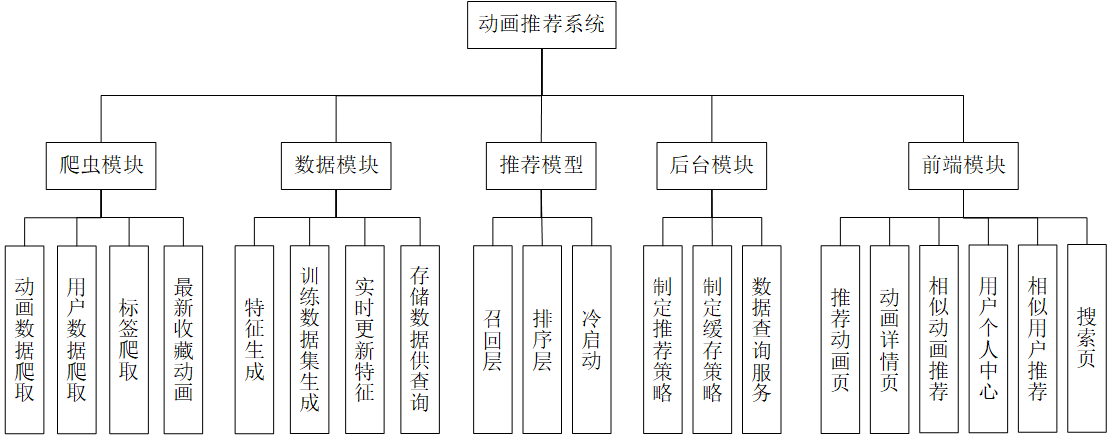
系统主要分为爬虫部分、数据部分、推荐模型、后台、前端。爬虫通过Scrapy实现,数据部分使用Pandas对数据进行处理,推荐模型使用TensorFlow和Gensim实现,后台通过Servlet+Jetty实现,前端通过React实现。
(1)使用Python的爬虫框架Scrapy全量抓取用户和动画数据,之后实时抓取用户最新收藏的动画信息,并将其存入MongoDB。
(2)对用户收藏动画序列数据集进行处理,利用Python库Pandas对整体数据集进行处理并切分,生成训练集和测试集,并提取用户特征和动画特征保存到Redis。
(3)基于训练数据和用户行为分析,设计并实现动画推荐算法。基于训练数据集,训练推荐系统模型,利用Scrapy获取用户新的收藏记录,不断更新,完善推荐算法,并通过TensorFlow Serving上线模型。
(4)利用React和Java设计并实现前后台功能模块,用户登录后通过模型调用实现用户的个性化动画推荐。
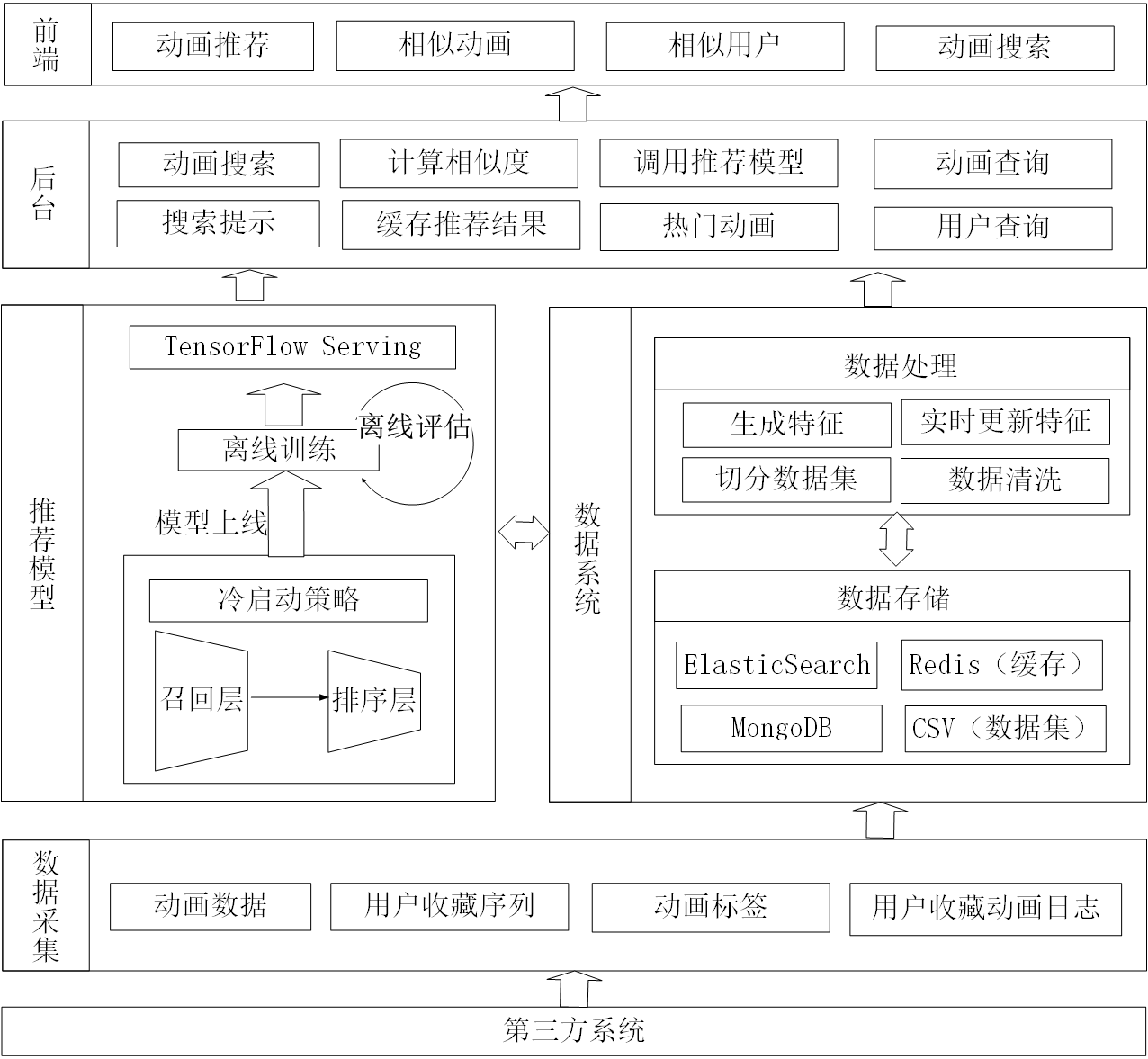
系统主要工作流程如下:
-
首先全量抓取用户数据和动画数据存入MongoDB;
-
将动画数据同步到ElasticSearch;
-
通过Python库Pandas对用户的收藏动画序列进行处理,生成训练集和测试集,并提取用户特征和动画特征保存到Redis;
-
训练模型并通过TensorFlow Serving上线模型;
-
用户登录系统获得推荐结果;
-
用户在原网站收藏新的动画;
-
通过Scrapy获取到用户收藏新动画的这条记录,并重新生成这个用户的特征;
-
用户再次访问系统,系统根据更新后的特征给用户推荐动画。
系统由以下几个模块构成:
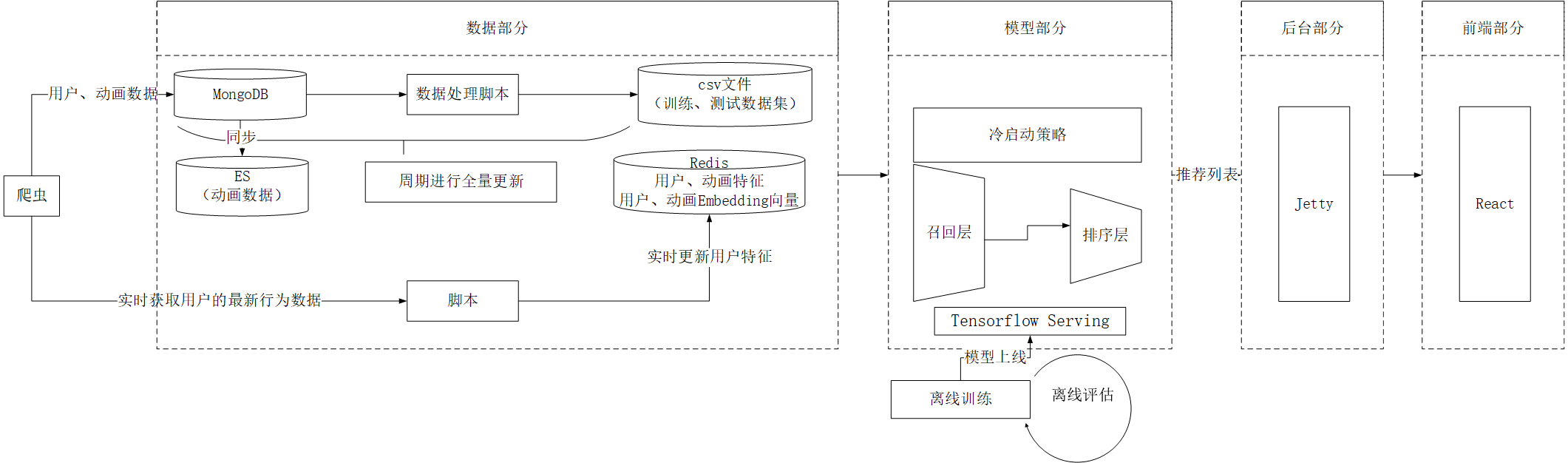
开发环境:PyCharm
技术架构:Python、Scrapy、MongoDB
介绍:使用Scrapy实现,抓取动画和用户的基础信息、网站的所有动画标签信息,实时监控并抓取用户与动画的交互信息;
开发环境:PyCharm
技术架构:Python、Numpy、Pandas
介绍:使用Pandas和Numpy对抓取的数据进行处理,生成推荐模型训练样本数据和测试样本数据到CSV文件,生成用户和动画的特征到Redis,根据最新的用户与动画交互信息更新用户特征向量,从而保证推荐系统的实时性;
开发环境:PyCharm
技术架构:Python、TensorFlow2、TensorFlow Serving、Gensim
召回层所用技术为Embedding,Embedding即用一个稠密向量表示一个对象,这个对象可以是一个词,也可以是一部电影。Embedding最开始来源于自然语言处理领域,将句子输入的深度学习模型中进行训练,最后生成词向量,同类词之间的词向量会有很高的相似度。这表明Embedding可以揭示词之间的潜在关系。
Embedding可以将词进行向量化,那么同样其它物品也可以通过Embedding进行向量化,与词向量使用句子训练不同,如果要生成动画的Embedding向量,可以使用用户收藏动画的序列进行训练。
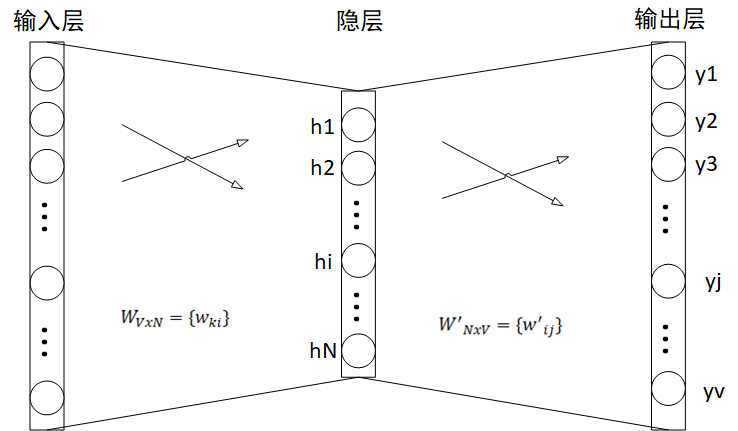
本系统使用Word2Vec算法生成动画的Embedding向量,算法的神经网络结构如图7 Word2Vec神经网络结构图所示。
将动画ID转换为One-Hot向量,在用户的动画收藏序列中使用滑动窗口获取训练样本,将样本中的一个动画ID输入,将相邻的动画ID作为预测目标,模型训练完成后,输入层到隐层之间的每行权重向量即对应了每个动画的Embedding。
使用Python库Gensim实现的Word2Vec算法,将用户的动画收藏序列输入模型进行训练,将训练完后的词向量作为动画的Embedding向量,将评分和评分时间作为权重计算动画Embedding的加权平均作为用户的Embedding向量,从而使最近评分且评分较高的动画有更高的权重,之后将用户和动画Embedding向量存入Redis。
在进行预测时,只需要计算用户Embedding向量和每个动画Embedding向量的余弦相似度即可。
排序层使用谷歌2016年提出的Wide&Deep模型,Wide&Deep模型由Wide部分和Deep部分组成。模型的神经网络结构如图8 Wide&Deep结构图所示。
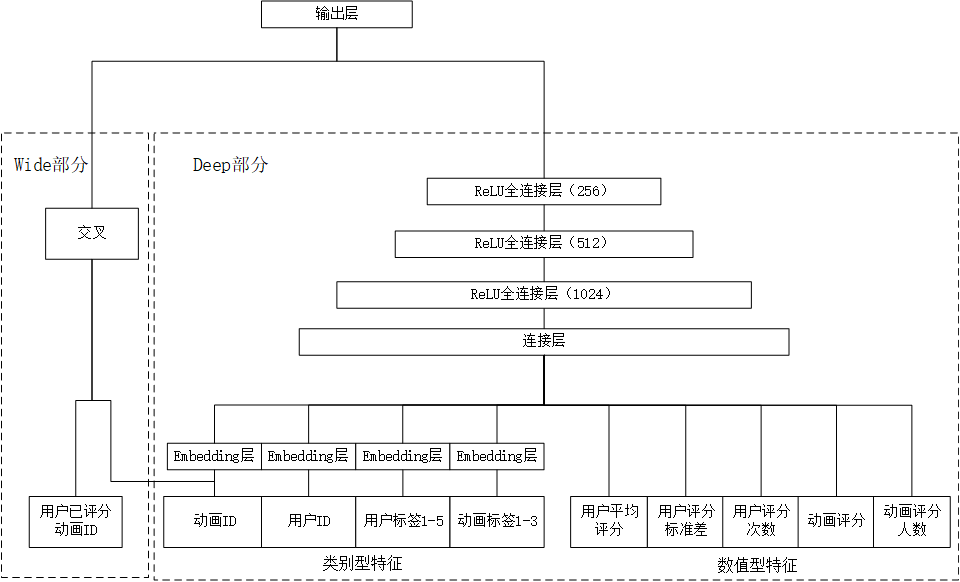
Wide部分是一个简单的单层神经网络,作用是让模型具有记忆能力,即两个物品的共现频率,例如用户观看了动画A就会观看动画B,相当于记住了训练数据中的规则,并在最后的推荐结果中有所体现。
而Deep部分是一个多层神经网络,输入层会将类别型特征进行Embedding,因此Deep部分也是一个Embedding+MLP模型。作用是提高模型的泛化能力[9],即对未出现过的特征组合的预测能力。
使用TensorFlow实现排序层模型,对于数值型特征直接输入模型,类别型特征由先转换成One-Hot向量,由于One-Hot向量过于稀疏且维度很大,所以需要经过Embedding层转换成稠密的低维向量。连接层将输入的每个特征进行拼接,生成更高维的向量,再经过两层全连接层,最终到达输出层。
模型训练完成后,会将模型保存到文件,然后通过TensorFlow Serving加载模型,提供线上推断服务。
开发环境:IDEA、Postman
技术架构:Java、Jetty、Servlet、Redis、ElasticSearch
介绍:提供用户和动画数据的查询功能,动画的搜索功能,负责协调数据部分、推荐模型和前端,制定推荐策略、冷启动策略。
开发环境:VSCode、Nodejs
技术架构:React、Material-UI、Ant Design Charts、Fetch
介绍:使用React实现,主页展示对用户的个性化推荐、动画详情页展示动画详细信息以及相似动画推荐、个人中心页展示个人信息以及相似用户、搜索页可对动画进行搜索。
-
启动MongoDB
-
启动Redis
redis-server "D:\Program Files\Redis-x64-5.0.9\redis.windows.conf" -
启动ElasticSearch
-
全量爬取动画数据
scrapy crawl anime
-
将所有的动画数据导入ElasticSearch
mongodb-to-elasticsearch.py
-
全量爬取用户“看过”的动画
scrapy crawl user
-
全量爬取用户“抛弃”的动画
scrapy crawl user_dropped
-
全量爬取网站的动画标签
scrapy crawl tag
-
实时增量爬取用户用户“看过”的动画
scrapy crawl timeline
-
特征工程,生成训练集、测试集到CSV文件,生成用户特征、动画特征到Redis
FeatureEng.py
-
召回层,生成用户和动画的Embedding向量
embedding.py
-
排序层,训练模型
WideNDeep.py
使用TensorBoard
tensorboard.exe --logdir=D:\python_project\bangumi_spider\bangumi_spider\resources\tensorboardlog http://localhost:6006/
-
模型上线
# 1. 拉取镜像 docker pull tensorflow/serving # 2. 运行容器 docker run -t --rm -p 8501:8501 -v "D:\IDEA\bangumi-recommend-system\src\main\resources\model\neuralcf:/models/recmodel" -e MODEL_NAME=recmodel tensorflow/serving
运行RecSysServer
-
修改镜像
npm config set registry https://registry.npm.taobao.org npm config get registry -
创建项目
npx create-react-app bangumi-recommend-system-front cd D:\IDEA\react\bangumi-recommend-system-front
-
安装依赖
# Meatrial-UI npm install @material-ui/core npm install @material-ui/icons npm install @material-ui/lab # 消息订阅与发布 npm install pubsub-js # React路由 npm install --save react-router-dom # Ant Design Charts npm install @ant-design/charts # 滑动加载 https://github.com/ankeetmaini/react-infinite-scroll-component npm install --save react-infinite-scroll-component
-
启动
npm start
-
启动成功后访问 http://localhost:3000/