主流分布式id方案总结
superleeyom opened this issue · comments

在简单系统中,我们常常使用 db 的 id 自增方式来标识和保存数据,随着系统的复杂,数据的增多,分库分表成为了常见的方案,db 自增已无法满足要求。这时候全局唯一的 id 生成系统就派上了用场。当然这只是 id 生成其中的一种应用场景。
- 全局唯一的 id:无论怎样都不能重复,这是最基本的要求了
- 高性能:基础服务尽可能耗时少,如果能够本地生成最好
- 高可用:虽说很难实现 100% 的可用性,但是也要无限接近于 100% 的可用性
- 简单易用:能够拿来即用,接入方便,同时在系统设计和实现上要尽可能的简单
现在就目前主流的分布式 id 生成方案做一个总结。
UUID
这个 jdk 自带的工具类就能实现:
UUID.randomUUID().toString()MySQL 官方有明确的建议主键要尽量越短越好,36 个字符长度的 UUID 不符合要求,如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能。
数据库自增
利用 MySQL 数据库的自增主键,来作为唯一的全局 id,专门用一张表来生成主键,表结构如下:
CREATE TABLE `distributed_id` (
`id` bigint(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`extra` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '额外字段',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci COMMENT='主键id生成';extra是额外字段,因为你要总要插入点什么,才能生成一个自增主键 id,这种方式存在问题是,每次生成一个id,都要请求MySQL,如果 MySQL 挂掉了,那么也就无法生成唯一 id 了,且 ID 发号性能瓶颈限制在单台 MySQL 的读写性能。
数据库多主模式
既然一台 MySQL 有风险,那么可以将 MySQL 扩展为两台,采用双主模式集群,设置每台 MySQL 的步长和起始值,其中一台 MySQL 的起始值为 1,步长为 2,一台的起始值为 2,步长为 2,配置如下:
# mysql-1,这里需要注意,执行如下命令前,最好先删除「主键id生成表」,否则可能不生效
# 最好连接 mysql 命令行界面执行,Navicat 等工具有时候会不生效
set global auto_increment_offset = 1;
set global auto_increment_increment = 2;
# mysql-2
set global auto_increment_offset = 2;
set global auto_increment_increment = 2;
# 查询是否修改成功
SHOW global VARIABLES LIKE 'auto_inc%'; 通过如上的配置后,MySQL-1 生成:1、3、5、7 ... 系列主键 id,MySQL-2 生成 2、4、6、8 ... 系列的主键 id,即使其中一台 MySQL 挂了,另外一台 MySQL 还可以继续生成 id,然后专门搭建一个后台服务 distributedd-service 服务,暴露 http 接口,专门用于其他服务生成分布式 id。这里我写了一个简单示例:distributedd-service ,可以参考一下;
但是这种还是有很大局限性,系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?首先,要调整新增加 MySQL 的起始值足够大,其次,之前两台的 MySQL 的步长肯定得修改,而且在修改步长的同时,很有可能会产生重复的 id,并且这种方式强依赖数据库,每次生成一个 id 都要请求数据库,数据库压力还是很大,每次获取 ID 都得读写一次数据库,只能靠堆机器来提高性能。
号段模式
那能不能批量获取呢?那就是号段模式,号段模式的意思就是,每次从数据库只获取一个号段,比如 (1,1000],然后分布式 id 服务 distributedd-service 在本地加载到内存中,然后采用自增的方式来生成 id,不需要每次都请求数据库。等这个号段使用完了,再去数据库申请一个新的号段。这种方式的好处就是解除了对数据库的强依赖,即使数据库挂了,分布式 id 服务 server 在本地还能支撑一段时间,另外为了提高分布式 id 服务的可用性,发号器服务也可以部署成集群,防止单点故障,但是也有个小缺陷的地方,就是假如分布式 id 服务重启了,就可能会丢失一部分的 id 号段。
那关于号段模式的实践,目前已经有开源的方案,就是滴滴的tinyid。
滴滴TinyId
DB 号段算法的数据库设计如下:
CREATE TABLE `tiny_id_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`biz_type` varchar(64) NOT NULL COMMENT '业务类型,不同的业务id隔离',
`max_id` int(11) NOT NULL COMMENT '当前最大可用id',
`step` int(11) NOT NULL COMMENT '号段的长度,也就是步长',
`version` int(11) NOT NULL COMMENT '乐观锁,每次更新都加上version,保证并发更新的准确性',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='db号段表';那么我们可以通过如下几个步骤来获取一个可用的号段:
- A. 查询当前的 max_id 信息:
select id, biz_type, max_id, step, version from tiny_id_info where biz_type='test'; - B. 计算新的 max_id:
new_max_id = max_id + step - C. 更新 DB 中的 max_id:
update tiny_id_info set max_id=#{new_max_id} , verison=version+1 where id=#{id} and max_id=#{max_id} and version=#{version} - D. 如果更新成功,则可用号段获取成功,新的可用号段为
(max_id, new_max_id] - E. 如果更新失败,则号段可能被其他线程获取,回到步骤 A,进行重试
分布式 id 发号器服务 distributedd-service 对外提供 http 服务,用于生成 id,搭建发号器服务 server 集群,每个节点都相当于一个 id 号段,请求经过负载均衡,落到某个节点上,从事先加载好的号段中获取一个 id,如果号段还没有加载,或者已经用完,则向 db 再申请一个新的可用号段,读写数据库的频率从 1 减小到了 1/step ,多台 server 之间因为号段生成算法的原子性,而保证每台 server 上的可用号段不重,从而使 id 生成不重。其实这种在并发量不高的情况下,其实基本上已经满足大部分使用场景,但是如果并发量比较高的话,还是会存在一些问题:
- 使用 http 方式获取一个 id,存在网络开销,性能和可用性都不太好
- db 是一个单点,可能会有单点故障问题
- 当 id 用完时需要访问 db 加载新的号段,db 更新存在乐观锁,此时 id 生成耗时明显增加
TinyId 给出了如下的优化方案:
-
双号段缓存:在号段使用到一定的程度,起一个线程,异步去加载下一个号段,保证内存中始终有可用的号段,则可避免性能波动。
-
多db支持:既然一个 db 可能单点故障,那就部署多台 db,原理跟上面讲的数据库多主模式一样,数据库 A 只生成奇数 id,数据库 B 只生成偶数 id。id 生成服务,随机向多个 db 申请号段。这时候,原本 DB 号段算法的数据库需要进行修改下:
CREATE TABLE `tiny_id_info` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `biz_type` varchar(64) NOT NULL COMMENT '业务类型,不同的业务id隔离', `max_id` int(11) NOT NULL COMMENT '当前最大可用id', `step` int(11) NOT NULL COMMENT '号段的长度,也就是步长', `delta` int(4) NOT NULL COMMENT 'id每次的增量,理解为id的自增步长,类似auto_increment_increment', `remainder` int(4) NOT NULL COMMENT '代表余数', `version` int(11) NOT NULL COMMENT '乐观锁,每次更新都加上version,保证并发更新的准确性', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='db号段表';
通过 delta 和 remainder 两个字段我们可以根据使用方的需求灵活设计 db 个数,使 db 能水平进行扩展,比如将AB两个 db 的 delta 都设置为 2,remainder A 设置为 0,B 设置为 1,则 A 则只生成偶数号段,B 则生成奇数号段。
-
增加tinyid-client:既然 http 会有网络开销,那就把 id 在本地,也就是客户端生成,就是说,id 生成服务 server 不直接生产id了,而是转为生产号段,id 生成的逻辑,转到本地,通过提供一个
tinyid-clientsdk 组件,引入到其他服务里面,在本地构建双号段、id生成,如此 id 生成则变成纯本地操作,性能大大提升。
雪花算法
雪花算法(snowflake)是 twitter 开源的分布式 ID 生成算法,雪花算法的描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的,据此可生成一个 64 bits 的唯一ID(long)。
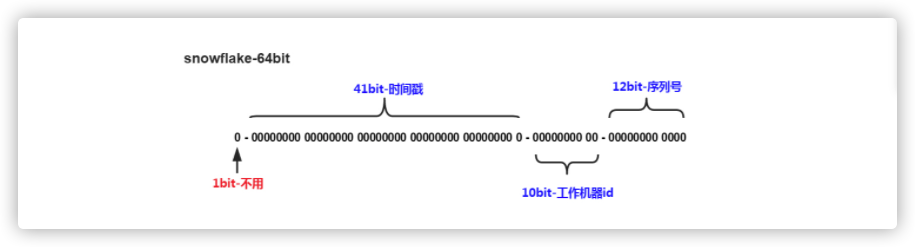
算法产生的是一个 long 型 64 比特位的值,由于一般分布式 id 均为正数(0 是代表正数,1 代表负数),第 1 位固定为 0,接下来是 41 位的毫秒单位的时间戳,我们可以计算下:
2^41/1000*60*60*24*365 = 69年
也就是这个时间戳可以使用 69 年不重复,这个对于大部分系统够用了。10 位的数据机器位,所以可以部署在 1024 个节点。12 位的序列,在毫秒的时间戳内计数。 支持每个节点每毫秒产生 4096 个 ID 序号,所以最大可以支持单节点差不多四百万的并发量。
雪花算法要保证 id 不重复,最重要的就是要保证 workerid 不重复,也就是机器码不能重复。如果要部署的服务节点不多,直接可以通过 jvm 的启动参数方式传过来,应用启动的时候获取启动参数(workId 终端 ID 和 datacenterId 数据中心 ID),保证每个节点启动的时候传入不同的启动参数即可。
java -jar xxx.jar -DworkerId=1 -DdatacenterId=123
这里我用 Java 工具类库 Hutool 封装的工具类 IdUtil 生成唯一 id,伪代码如下:
long workerid = System.getProperty("workerId ");
long datacenterId = System.getProperty("datacenterId ");
Snowflake snowflake = IdUtil.getSnowflake(workerid, datacenterId);
long distributedId = snowflake.nextId();
如果机器特别多,人工去为每台机器去指定一个机器 id,人力成本太大且容易出错,并且雪花算法,强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。所以一些大厂对 snowflake 进行了改造,比如百度的 uid-generator,美团的 Leaf 等开源方案。
美团 Leaf
目前美团 Leaf 有两种方案,一种也是基于号段模式,叫 Leaf-segment 数据库方案,他的原理其实跟滴滴的 tinyid 类似的,这里就不再复述了。另外一种是基于雪花算法的,叫 Leaf-snowflake 方案,Leaf-snowflake 方案完全沿用 snowflake 方案的 bit 位设计,即是 “1+41+10+12” 的方式组装 ID 号。Leaf-snowflake 方案使用 Zookeeper 持久顺序节点的特性自动对 snowflake 节点配置 workId:
- 启动
Leaf-snowflake服务,连接 Zookeeper,在 leaf_forever 父节点下检查自己是否已经注册过(是否有该顺序子节点)。 - 如果有注册过直接取回自己的 workerId( zk 顺序节点生成的 int 类型 ID 号),启动服务。
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的 workerId 号,启动服务。
除了每次会去 zk 拿数据以外,也会在本机文件系统上缓存一个 workerId 文件。当 ZooKeeper 出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。
另外关于时钟回拨问题,Leaf-snowflake 方案在服务启动阶段,就会去检测机器时间是否发生了大步长的回拨:
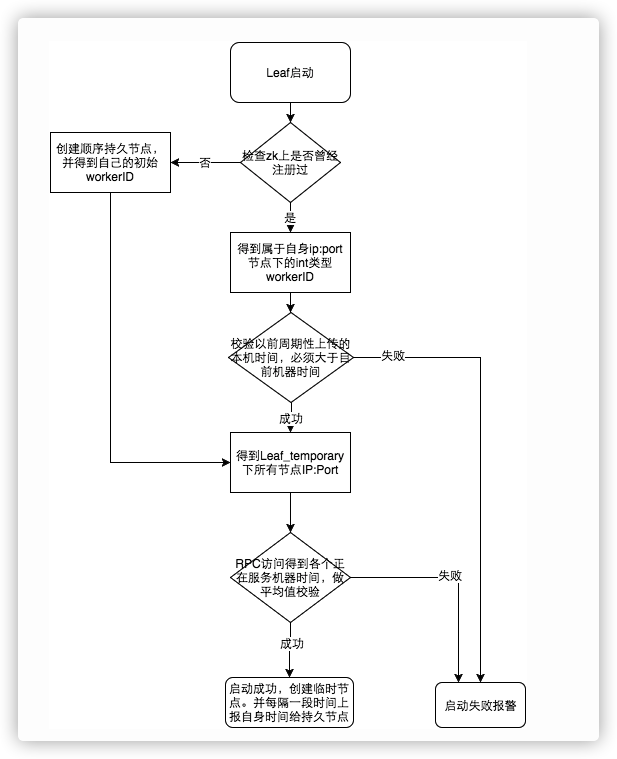
更细节的问题,可以参考美团技术团队写的:《Leaf——美团点评分布式ID生成系统》。
百度 uid-generator
百度的 UidGenerator 以组件(sdk)形式工作在应用项目中, 支持自定义 workerId 位数和初始化策略, 从而适用于 docker 等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator 通过借用未来时间来解决 sequence 天然存在的并发限制; 采用RingBuffer 来缓存已生成的 UID, 并行化 UID 的生产和消费, 同时对 CacheLine 补齐,避免了由 RingBuffer 带来的硬件级「伪共享」问题,最终单机 QPS 可达 600 万。
相比于标准的雪花算法比特位的分布,百度的 UidGenerator 稍微有些不一样:
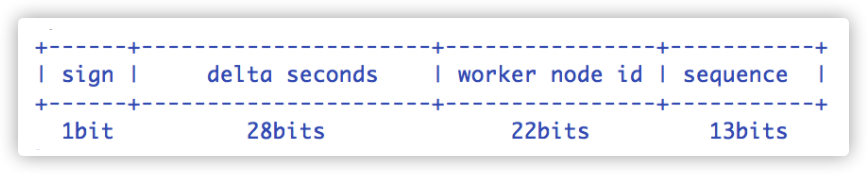
- sign(1bit):固定 1bit 符号标识,即生成的 UID 为正数。
- delta seconds (28 bits):当前时间,单位:秒。
- worker id (22 bits):机器id,最多可支持约 420w 次机器启动,内置实现为在启动时由数据库分配,默认分配策略为用后即弃。
- sequence (13 bits):每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
百度的 UidGenerator 默认提供的 workid 生成策略:应用在启动时会往数据库表 WORKER_NODE 表中去插入一条数据,数据插入成功后返回的该数据对应的自增唯一 id 就是该机器的 workId。
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;但是百度的 uid-generator 项目已经基本上不维护了,但是**还是挺棒的,如果可以的话,自己可以按照这个思路改造。
其他方案
除了上面主流的方案,还有一些其他的方案:
- 使用 Redis 的自增原理,利用 Redis 中的 incr 命令来实现原子性的自增与返回,使用 setnx 保证并发更新的准确性。
- MongoDB 的 ObjectId,其实它本质还是雪花算法。
- 利用 zookeeper 的持久顺序节点特性。
总结
就目前这些方案来说,我个人更比较推荐:滴滴TinyId 和 美团 Leaf 两种开源方案,这两种方案已经经过了成熟的商业实践,适用于大部分的公司业务,我们自己公司目前使用的就是美团Leaf-segment数据库方案。
参考文档

总结的好哇。感谢。
@yihong0618 哈哈,谢谢

不知道是否还存活,我有几个疑问,烦请大佬说明下:
号段模式下
- 多db支持的话,应该都是多主数据库,多主数据库之间应该是有数据复制机制的,以保证数据在各个主库中的一致性,也就是a库等于b库的数据。这时号段表a库和号段表b库的号段配置数据还能保持不一致吗?
- 号段模式的delta和remainder字段,delta代表了id的增量,也就是可以控制奇偶数,那remainder的字段的作用有何用呢?