一个使用Python实现的Pixiv爬虫
运行时输出参考下图(2x faster)

支持功能
-
每日/月/年的不同排行榜
-
个人收藏
-
特定画师的作品
-
特定关键词的作品(支持高级关键词搜索,例如
(Lucy OR 边缘行者) AND (5000users OR 10000users)) -
马赛克拼图(
image_mix)

设计思路
-
Notations
-
artwork_id: "93172108" -
artwork_url: https://www.pixiv.net/artworks/93172108每个
artwork可能包含多张图片 -
image_url: "https://i.pximg.net/img-original/img/2021/10/02/18/47/29/93172108_p1.jpg"
-
-
采用流水线设计
不同阶段分别收集
artwork url,image url,并传入下一阶段使用 -
模块化程度高,耦合度低
例如已有
image url(e.g., 配合Pxer使用),则可以考虑直接传入downloader下载
graph LR;
F[start]-->A;
A<==run parallelly==>A;
A[crawler]--send artwork_url-->B[collector];
B<==run parallelly==>B;
B--send image url-->D[downloader];
D==run parallelly==>D;
D-->E[end];
-
./image_mix:马赛克拼图 -
./pixiv_crawler:Pixiv爬虫 -
./templatesPixiv网站部分json,html的样例说明见
./pixiv_crawler/collector/selectors.py
./image_mix/README.md
Python >= 3.9pip install requirements.txt -r
配置文件为./pixiv_crawler/config.py,含:warning:项必须修改
-
MODE_CONFIG部分该设置仅适用于抓取排行榜图片
START_DATE: 排行榜开始日期⚠️ RANGE: 日期范围⚠️ MODE: 哪个类型的排行榜(参考文件中RANKING_MODES)⚠️ CONTENT_MODE: 下载插画、漫画或是全部类型的作品(参考文件中CONTENT_MODES)⚠️ N_ARTWORK: 排行榜前k幅作品⚠️
-
OUTPUT_CONFIG部分该设置用于控制输出信息程度,可用于调试
VERBOSE: 输出最多的信息(不建议开启)PRINT_ERROR: 输出遇到异常的类型(可用于调试,偶尔TimeOut属于正常情况)
-
NETWORK_CONFIG部分PROXY: 代理设置(Clash无需修改,SSR需要修改端口号)⚠️ HEADER: 基础请求头,目前仅含浏览器头
-
USER_CONFIG部分-
USER_ID: 修改成自己的uid,参考个人资料页面的网址https://www.pixiv.net/users/{UID}⚠️ -
COOKIE: 配置种最关键的一项⚠️ ⚠️ ⚠️ -
打开浏览器的
DevTools(一般为F12),切换到Network栏 -
访问排行榜并刷新页面,在
DevTools中找到ranking.php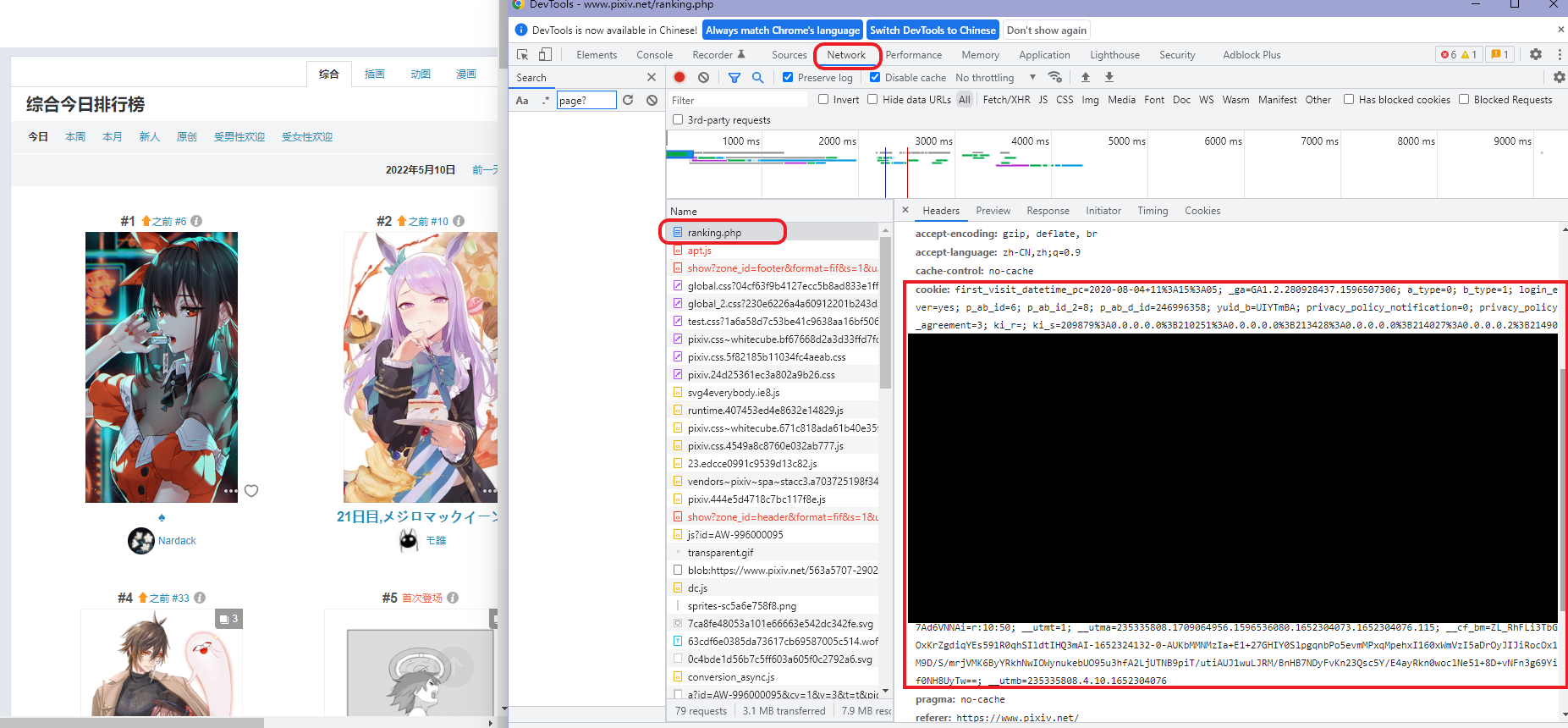
将
cookie:后面所有的字符(最大的红框所示)复制到配置的COOKIE中⚠️
-
-
-
DOWNLOAD_CONFIG部分STORE_PATH: 图片保存位置N_TIMES: 下载失败后的重复请求次数WITH_TAG: 是否需要抓取标签FAIL_DELAY: 下载失败后延时(秒)N_THREAD: 并行下载的线程数量(根据CPU核数调整)⚠️ THREAD_DELAY: 每个线程启动的延时(秒)

参考./pixiv_crawler/main.py中注释代码
capacity参数用于限制下载流量
-
下载排行榜作品
正确配置
MODE_CONFIG,修改主程序app = RankingCrawler(capacity=200) app.run()
-
下载个人公开收藏作品
正确配置
USER_CONFIG,修改主程序n_images参数用于限制最大下载数量app = BookmarkCrawler(n_images=20, capacity=200) app.run()
-
下载某位画师的作品
artist_id参数为画师的uidapp = UserCrawler(artist_id="32548944", capacity=200) app.run()
-
下载某个关键词的作品
注:按照热门度排序需要
premium账户正确配置
USER_CONFIG,修改主程序keyword参数为关键词n_images参数用于限制最大下载数量app = KeywordCrawler(keyword="(Lucy OR 边缘行者) AND (5000users OR 10000users)", order=False, mode=["safe", "r18", "all"][-1], n_images=20, capacity=200) app.run()
python main.py
COOKIE过期时间较长,一般几天内可重复使用