Applied MLOps to Maintain Model Freshness on Kubernetes
This is the repository for the Berlin Buzzwords 2021 talk.
Abstract
As machine learning becomes more pervasive across industries the need to automate the deployment of the required infrastructure becomes even more important. The ability to efficiently and automatically provision infrastructure for modeling training, evaluation, and serving becomes an important component of a successful ML pipeline. Combined with the ever growing popularity of Kubernetes, a full-cycle, containerized method for managing models is needed.
In this talk we will present a containerized architecture to handle the full machine learning lifecycle of an NLP model. We will describe our technologies and tools used along with our lessons learned along the way. We will show how models can be trained, evaluated, and served in an automated fashion with room for extensibility to be customized for specific workloads.
Attendees of this talk will come away with a working knowledge of how a machine learning pipeline can be constructed and managed inside Kubernetes. Knowledge of NLP is not required. All code presented will be available on GitHub.
Summary
This project ingests tweets, determines trending hashtags, and sorts movie search results based on trending hashtags. The classification of movie overviews is done by a zero-shot classifier. The repository includes tools for training and deploying NLI model, managing search relevance scoring, and data ingest. Follow the steps outlined below to try it out.
Architecture
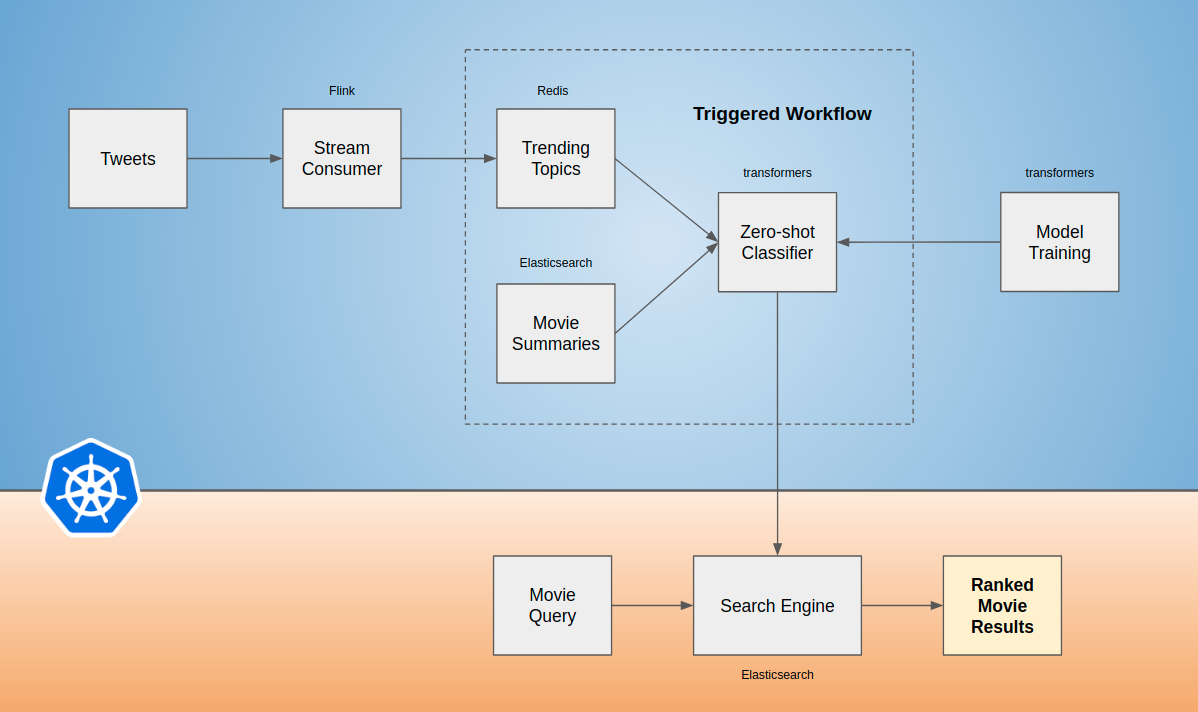
Usage
In the commands below, localhost is where Elasticsearch is running and tmdb is the name of the index.
- Run the
build.shscript to build the Java (Maven) projects and the docker images. - Create a
twitter.envfile with your Twitter credentials like:
CONSUMER_KEY=
CONSUMER_SECRET=
TOKEN=
TOKEN_SECRET=
- Run
docker-compose up - Once the containers are up, we can index some movie documents in Elasticsearch:
cd data-scripts/
./1-index.sh localhost tmdb
localhost is the address of Elasticsearch and tmdb is the name of the Elasticsearch index. To see a few indexed documents run: ./data-scripts/3-query.sh
- Load the relevance rankings into the MySQL database. Run the script
load-judgments.shscript or the command below.
docker-compose run mysql mysql -u root --password=password -h mysql < judgments.sql
Do the following steps if you want to tinker with search relevance. Otherwise just skip the next two steps.
- Initialize the Quepid database:
docker-compose run --rm quepid bin/rake db:setup
- Start Quepid.
docker-compose up quepid
At this point, you have the following containers running:
flink-twitter- Capturing counts of hashtags and persisting those counts in Redis.elasticsearch- Elasticsearch.classifier- A zero-shot learning classifier exposed through a REST service.quepid- The Quepid search relevance tool.redis- Cache for storing hashtag counts and by Quepid.mysql- Used for Quepid's search relevance data storage
NLI Model Training and Inference
An NLI model must be trained (or use a pre-trained model) to classify indexed documents.
The nli-training directory contains files needed to fine-tune an NLI model on BERT using the MNLI dataset. If you want to change the parameters of the training modify the train.sh script. Change to the nli-training directory and run build.sh to build the image. Now run the docker image to start training using the run-image.sh script. Model artifacts will be written to ./models/.
To use the model, modify zero-shot-classifier/classifier.py to change the name of the model to point to the directory containing the trained model. The model can then be uploaded to the HuggingFace model hub, version controlled with DVC, or stored somewhere else.
Lastly, set the environment variable in docker-compose.yml to specify the model for the classifier container. (You can use your own model or any model available through the HuggingFace model hub.)
Capturing Trending Hashtag Counts
The Apache Flink job will be running and capturing hashtags and their counts. The hashtags and their counts will be sorted and the most frequently occurring hashtags and their counts will be persisted to the Redis cache.
Get Trending Hashtags from the Cache
The commands below walk through how to read the trending hashtags from Redis using the redis-client container.
First, test the connection to Redis with a PING.
docker-compose run redis-client redis-cli -h redis -p 6379 PING
Get all keys in the cache (there should be just one key called hashtags):
docker-compose run redis-client redis-cli -h redis -p 6379 --scan --pattern '*'
Now get the type of key hashtags (which is zset):
docker-compose run redis-client redis-cli -h redis -p 6379 TYPE hashtags
Get the top 3 most frequently occurring hashtags from the hashtags:
docker-compose run redis-client redis-cli -h redis -p 6379 ZREVRANGEBYSCORE hashtags +inf -inf | head -n 3
This will give output such as:
1) "Transportation"
2) "Sales"
3) "Retail"
Get the first trending hashtag to a file (./redis-client/get-hashtags.sh):
docker-compose run redis-client redis-cli -h redis -p 6379 ZREVRANGEBYSCORE hashtags +inf -inf | head -n 1 | sed 's/[0-9])//g' | tr -d ' "' > hashtags
Use the Hashtags for the Classifier as Potential Categories
Now we can use the top N trending hashtags as the categories for the zero-shot-classifier. You would probably want to run this step nightly or so based on your types of indexed documents and how much they are affected by trending hashtags.
Now we can update the indexed documents (movies) with a field containing the classifier's score for the hashtag. In the example commands below, the hashtag is christmas. This command updates all of the indexed documents by passing each document's summary to the zero-shot classifier along with the category (hashtag christmas). The result is a value between 0 and 1 indicating how well the model thinks the movie summary matches the category. (For example, for the category christmas the movie "Jingle all the Way" will likely get a score greater than 0.9 while the movie "Space Jam" will receive a much lower score.) A new field called classification_christmas is added to each document containing the value.
cd data-scripts/
./2-classify.sh localhost tmdb christmas
Now when we search we can sort the results descending by the classification_christmas field. Use the command below to run a search:
./data-scripts/3-query-sort-by-classification.sh localhost tmdb christmas
The command above searches for movies matching the Family genre and sorts them by the value in the classification_christmas field. This gives a list of search results which are family movies with Christmas movies returned first. "Jingle all the Way" will be returned much earlier in the search results than "Space Jam."
Search Quality Measurements
Doing a faceted search for "Family" genre "christmas" movies gives 40 results. An ideal result is "Jingle All the Way." But some of the results are not less relevant to what we want. For instance, the movie "Savannah" (ID 207871) contains a character named "Christmas Moultrie" and is not a "christmas" movie. Other results may take place around the time of Christmas (such as "The Christmas Bunny").
The search:
{
"query": {
"bool": {
"must": [
{
"match": {
"genres": "Family"
}
},
{
"match": {
"overview": "christmas"
}
}
]
}
}
}
The manual relevance scores are captured in judgments.csv and judgments.sql for easy importing into a database.
To assess the performance of the model, we can calculate the N/DCG for a "Family" search sorted on the category_christmas field. Run the following search:
{
"_source": true,
"sort": [
{
"classification_christmas" : {
"order" : "desc"
}
}
],
"query": {
"match": {
"genres": "Family"
}
}
}
Go through the results and correlate each document (by its ID) to the relevance score from the table above. This gives us a baseline DCG score that we can use to evaluate future models.
Important: We are treating the table of documents as the only relevant documents. Any search result not included in the table will be assigned a relevance score of 0. This uses the assumption that a "Christmas" movie will have "christmas" somewhere in the description.
To automate the scoring process described above just run:
docker-compose run score-calculator
This command executes a search with a term (currently set in the Java project) and calculates the N/DCG score using the search results and the judgments in the database. You can use this score to compare the performance of your model iterations over time. (Train model, deploy it, update indexed documents, run the score-calculator to evaluate the model's performance by comparing it to the baseline score.)
License
Licensed under the Apache License, version 2.0.