![]()
BRANCH NOTICE: The ultralytics/yolov3 repository is now divided into two branches:
- Master branch: Forward-compatible with all YOLOv5 models and methods (recommended).
$ git clone https://github.com/ultralytics/yolov3 # master branch (default)- Archive branch: Backwards-compatible with original darknet *.cfg models (not recommended).
$ git clone -b archive https://github.com/ultralytics/yolov3 # archive branch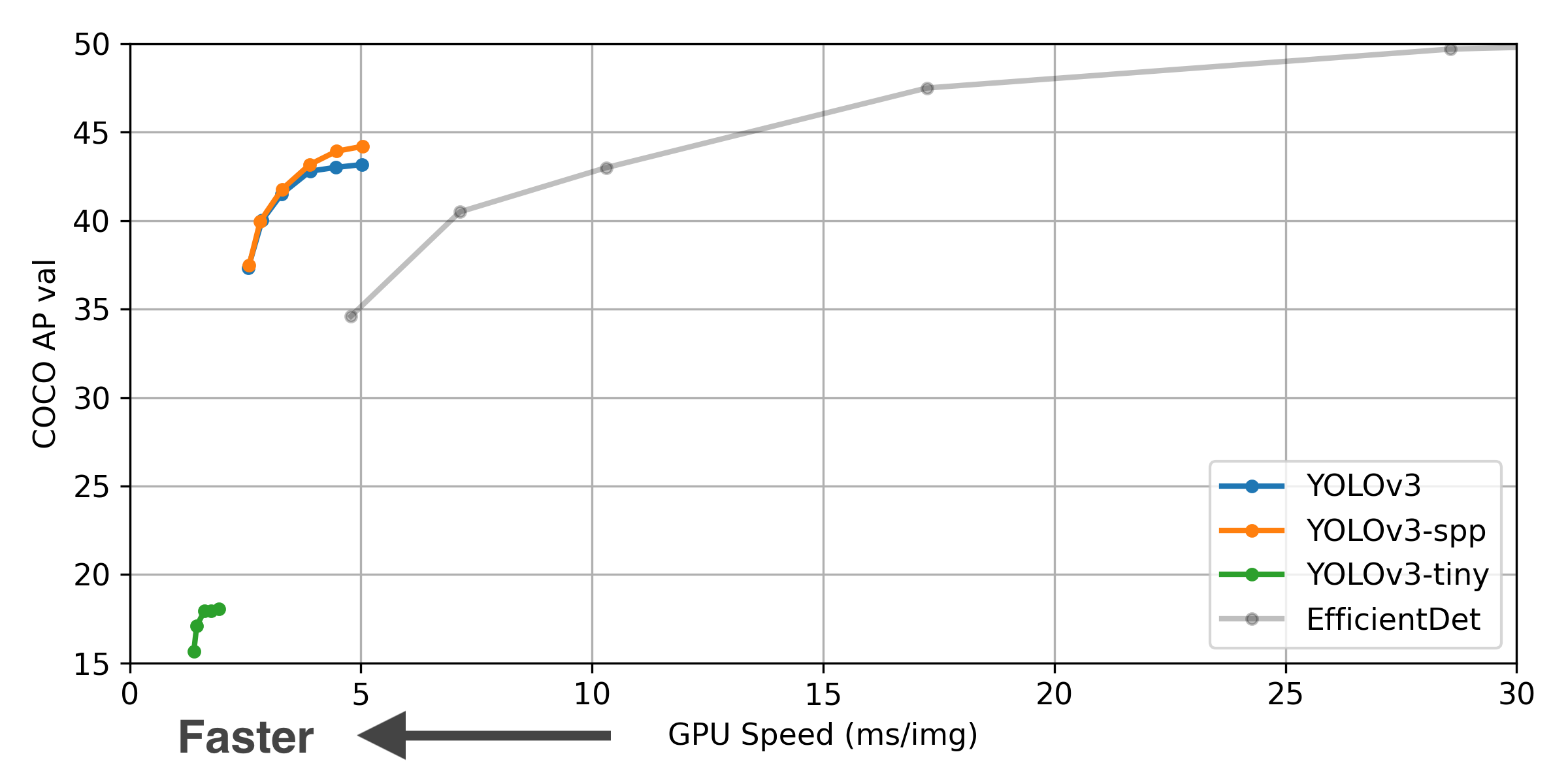 ** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 43.3 | 43.3 | 63.0 | 4.8ms | 208 | 61.9M | 156.4B | |
| YOLOv3-SPP | 44.3 | 44.3 | 64.6 | 4.9ms | 204 | 63.0M | 157.0B | |
| YOLOv3-tiny | 17.6 | 34.9 | 34.9 | 1.7ms | 588 | 8.9M | 13.3B |
** APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or TTA. Reproduce mAP by python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
** SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes image preprocessing, FP16 inference, postprocessing and NMS. NMS is 1-2ms/img. Reproduce speed by python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
** Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA by python test.py --data coco.yaml --img 832 --iou 0.65 --augment
Python 3.8 or later with all requirements.txt dependencies installed, including torch>=1.7. To install run:
$ pip install -r requirements.txt- Train Custom Data 🚀 RECOMMENDED
- Weights & Biases Logging 🌟 NEW
- Multi-GPU Training
- PyTorch Hub ⭐ NEW
- ONNX and TorchScript Export
- Test-Time Augmentation (TTA)
- Model Ensembling
- Model Pruning/Sparsity
- Hyperparameter Evolution
- Transfer Learning with Frozen Layers ⭐ NEW
- TensorRT Deployment
YOLOv3 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Google Colab Notebook with free GPU:
- Kaggle Notebook with free GPU: https://www.kaggle.com/ultralytics/yolov3
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Docker Image https://hub.docker.com/r/ultralytics/yolov3. See Docker Quickstart Guide

detect.py runs inference on a variety of sources, downloading models automatically from the latest YOLOv3 release and saving results to runs/detect.
$ python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
rtsp://170.93.143.139/rtplive/470011e600ef003a004ee33696235daa # rtsp stream
rtmp://192.168.1.105/live/test # rtmp stream
http://112.50.243.8/PLTV/88888888/224/3221225900/1.m3u8 # http streamTo run inference on example images in data/images:
$ python detect.py --source data/images --weights yolov3.pt --conf 0.25
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', project='runs/detect', save_conf=False, save_txt=False, source='data/images/', update=False, view_img=False, weights=['yolov3.pt'])
Using torch 1.7.0+cu101 CUDA:0 (Tesla V100-SXM2-16GB, 16130MB)
Downloading https://github.com/ultralytics/yolov3/releases/download/v1.0/yolov3.pt to yolov3.pt... 100% 118M/118M [00:05<00:00, 24.2MB/s]
Fusing layers...
Model Summary: 261 layers, 61922845 parameters, 0 gradients
image 1/2 /content/yolov3/data/images/bus.jpg: 640x480 4 persons, 1 buss, Done. (0.014s)
image 2/2 /content/yolov3/data/images/zidane.jpg: 384x640 2 persons, 3 ties, Done. (0.014s)
Results saved to runs/detect/exp
Done. (0.133s)
To run batched inference with YOLO3 and PyTorch Hub:
import torch
from PIL import Image
# Model
model = torch.hub.load('ultralytics/yolov3', 'yolov3', pretrained=True).autoshape() # for PIL/cv2/np inputs and NMS
# Images
img1 = Image.open('zidane.jpg')
img2 = Image.open('bus.jpg')
imgs = [img1, img2] # batched list of images
# Inference
prediction = model(imgs, size=640) # includes NMSDownload COCO and run command below. Training times for YOLOv3/YOLOv3-SPP/YOLOv3-tiny are 6/6/2 days on a single V100 (multi-GPU times faster). Use the largest --batch-size your GPU allows (batch sizes shown for 16 GB devices).
$ python train.py --data coco.yaml --cfg yolov3.yaml --weights '' --batch-size 24
yolov3-spp.yaml 24
yolov3-tiny.yaml 64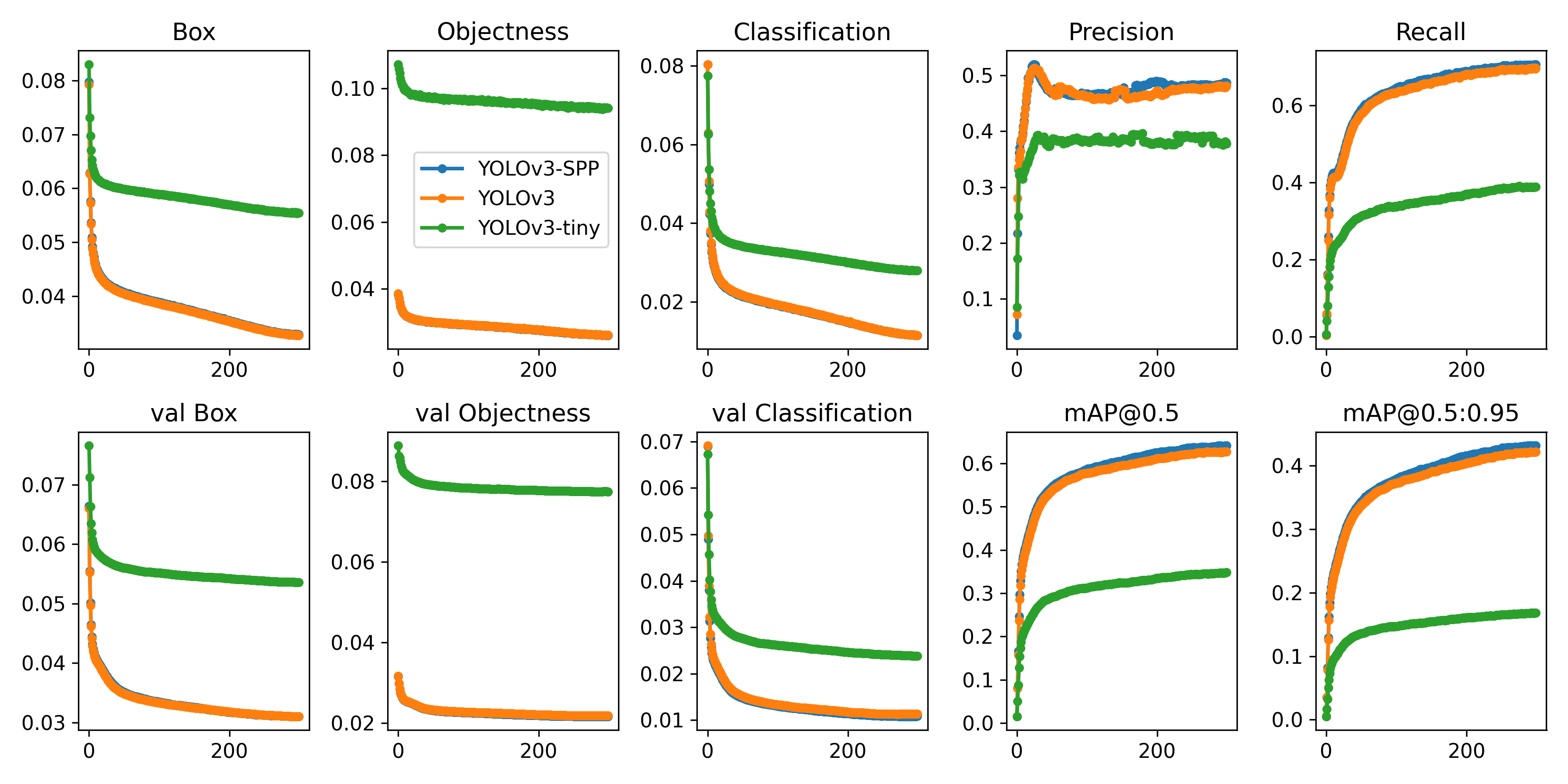
Ultralytics is a U.S.-based particle physics and AI startup with over 6 years of expertise supporting government, academic and business clients. We offer a wide range of vision AI services, spanning from simple expert advice up to delivery of fully customized, end-to-end production solutions, including:
- Cloud-based AI systems operating on hundreds of HD video streams in realtime.
- Edge AI integrated into custom iOS and Android apps for realtime 30 FPS video inference.
- Custom data training, hyperparameter evolution, and model exportation to any destination.
For business inquiries and professional support requests please visit us at https://www.ultralytics.com.
Issues should be raised directly in the repository. For business inquiries or professional support requests please visit https://www.ultralytics.com or email Glenn Jocher at glenn.jocher@ultralytics.com.