-
Install Horton works stack (that contains Hadoop and other tools)
cd HDP_3.0.1_docker-deploy-scripts_18120587fc7fb/sh docker-deploy-hdp30.sh- In case you experience a port issue like:
C:\Program Files\Docker\Docker\Resources\bin\docker.exe: Error response from daemon: driver failed programming external connectivity on endpoint sandbox-proxy (2e13894570ec36a982eb51009448c128854214a8286088e01da9f7881b6dd100): Error starting userland proxy: Bind for 0.0.0.0:50070: unexpected error Permission denied.- You can fix it by setting different ports inside the
sandbox/proxy/proxy-deploy.shfile, this is dynamically generated when we runsh docker-deploy-hdp30.sh- Edit file
sandbox/proxy/proxy-deploy.sh - Modify conflicting port (first in keypair). For example,
6001:6001to16001:6001 - Save/Exit the File
- Run bash script: bash
sandbox/proxy/proxy-deploy.sh - Repeat steps for continued port conflicts
- In case it still stuck, run:
netcfg -d --this will clean up all networking devices, and requires a reboot
- Edit file
- In case you experience a port issue like:
- Verify sandbox was deployed successfully by issuing the command:
docker ps- You should see two containers, one for the
nginxproxy and another one for the actual tools
- You should see two containers, one for the
- In order to stop the HDP sandbox just run:
docker stop sandbox-hdpdocker stop sandbox-proxy- To remove the containers you just need to do:
docker rm sandbox-hdpdocker rm sandbox-proxy
- To remove the image just run:
docker rmi hortonworks/sandbox-hdp:3.0.1docker rmi hortonworks/sandbox-proxy:1.0
- To start just run:
docker start sandbox-hdpdocker start sandbox-proxy
- In case you want a CNAME, you can add this line to your hosts file:
127.0.0.1 sandbox-hdp.hortonworks.comC:\Windows\System32\drivers\etc\hostson Windows/etc/hostson a MacOSX
- Now we are able to open
Ambariby accessing:http://sandbox-hdp.hortonworks.com:1080/splash.htmlsandbox-hdp.hortonworks.com:8080or127.0.0.1:8080
- The default
Ambariuser is:- username:
maria_dev, password:maria_dev
- username:
-
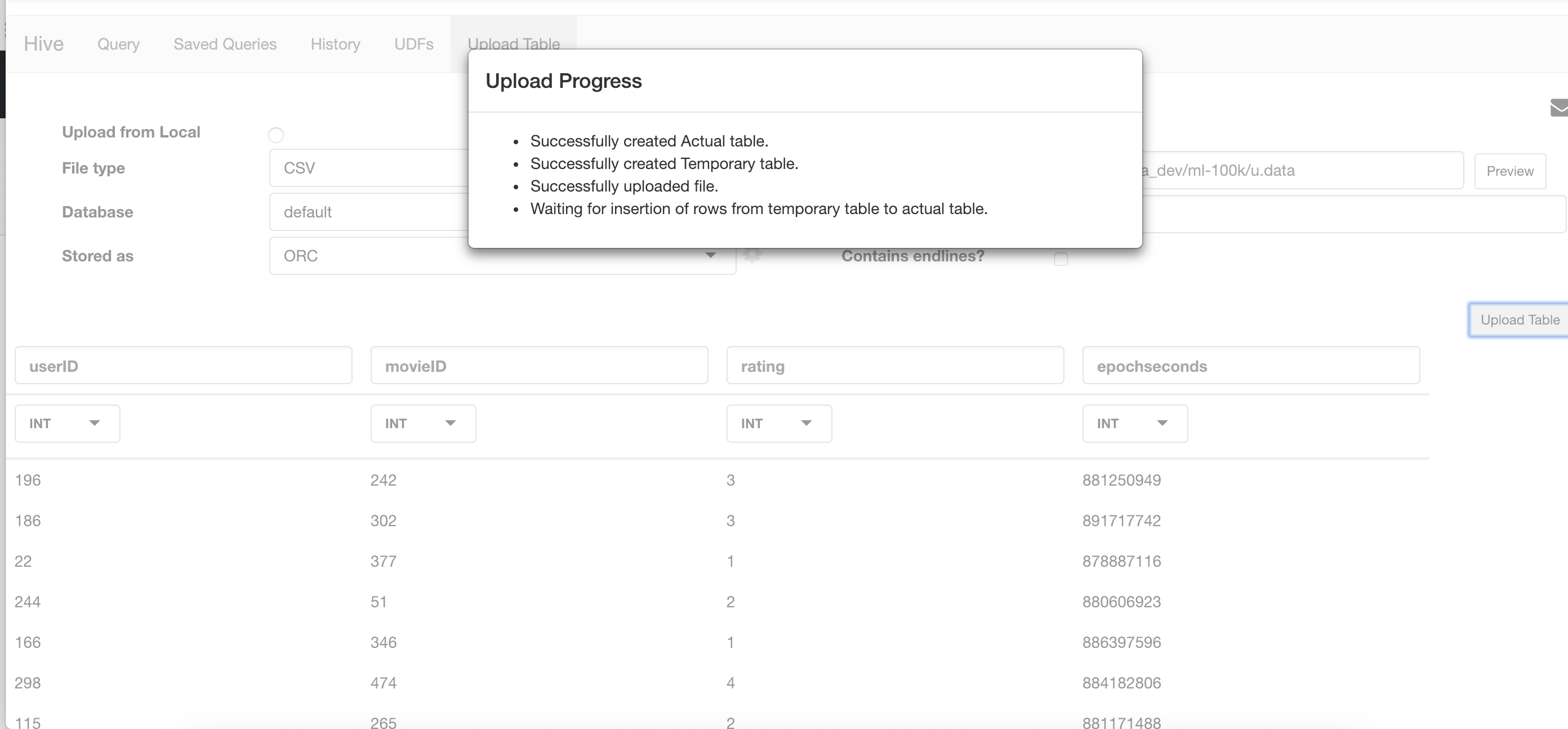
First, we will import both
ml-100ku.dataandu.itemusingHive- You can find
Hiveby clicking the menu icon on the top right corner - After importing the data, we are able to run SQL queries even though the data is saved in a Hadoop cluster (HDFS)
SELECT movie_id, count(movie_id) as ratingCount FROM ratings GROUP BY movie_id ORDER BY ratingCount DESCSELECT name FROM movie_names WHERE movie_id = 50;
- You can find

-
"An open source software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware" - Hortonworks
-
Google published papers about GFS (Google File System) and MapReduce - 2003-2004
-
Yahoo! was building "Nutch", and open source web search engine at the same time
- Doug Cutting and Tom White started putting Hadoop together in 2006
- Hadoop was the name of one of the toys of Doug Cutting child. Yellow stuffed elephant
-
Data is too darm big - terabytes per day
-
Vertical scaling doesn't cut it
- In a database world horizontal-scaling is often based on the partitioning of the data i.e. each node contains only part of the data, in vertical-scaling the data resides on a single node and scaling is done through multi-core i.e. spreading the load between the CPU and RAM resources of that machine.
- With horizontal-scaling it is often easier to scale dynamically by adding more machines into the existing pool - Vertical-scaling is often limited to the capacity of a single machine, scaling beyond that capacity often involves downtime and comes with an upper limit.
- Vertical scaling means more memory and cpu in the existent machines
- Horizontal scaling means more machines
- Vertical scaling issues:
- Disk seek times
- Hardware failures
- Processing times
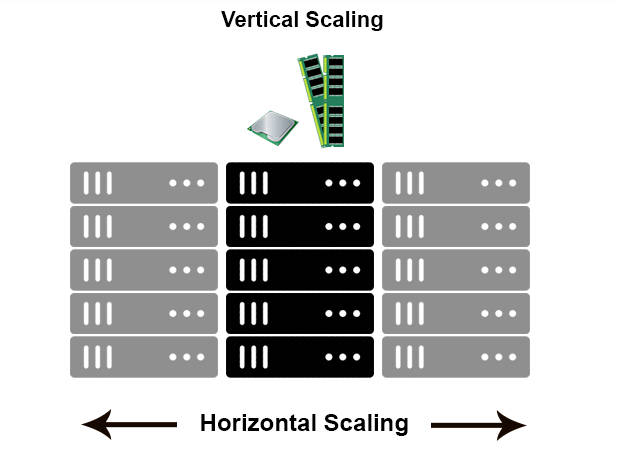
- In a database world horizontal-scaling is often based on the partitioning of the data i.e. each node contains only part of the data, in vertical-scaling the data resides on a single node and scaling is done through multi-core i.e. spreading the load between the CPU and RAM resources of that machine.
-
It is not just for batch processing anymore

- World of Hadoop
- Core Hadoop Ecosystem
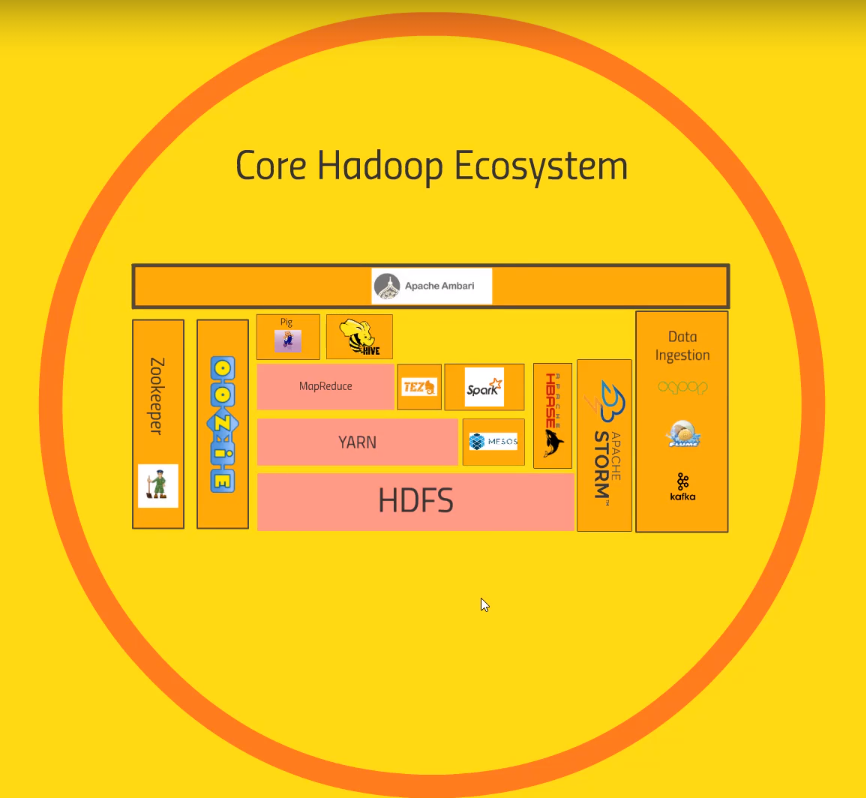
- HDFS: Hadoop Distributed File System
- Makes all the hard drives looks like a single one
- Also, it is responsible for data redundancy (recover)
- YARN: Yet Another Resource Negotiator
- Sits on top of HDFS
- Manages the resources in your computer cluster
- What gets to run when
- Which nodes are available
- Mesos
- An alternative to YARN
- Also a resource negotiator
- Solve the same problem in different ways
- MapReduce
- Sits on top of YARN
- Process you data across an entire cluster
- It consists of Mappers and Reducers
- Mappers: transform your data in parallel
- Reducer: aggregate data together
- Spark
- Sitting at the same level of MapReduce
- Works with YARN or Mesos
- To run queries on your data
- Also handles SQL queries, ML tasks, streaming data
- Write your spark scripts using Java, Scala or Python
- Scala being preferred
- Tez
- Similar to Spark (direct acyclic graph)
- Tez is used in conjunction with Hive to accelerate it
- HBase
- Exposing the data on your cluster to transaction platforms
- NoSQL database (large transaction rates)
- Fast way of exposing those resources to other systems
- Apache Storm
- Process streaming data in real time (log data is an example)
- Sensor data
- Spark streaming solves the same problem, but in a different way
- Update your ML models, or transform data in a database in real time (no batch processing)
- Process streaming data in real time (log data is an example)
- Pig
- Sits on top of MapReduce
- A high level programming API that
- Allows us to write simple scripts that looks a lot like SQL in some cases
- Chain queries together without coding Java or Python
- This script will be transformed in something that runs on top of MapReduce
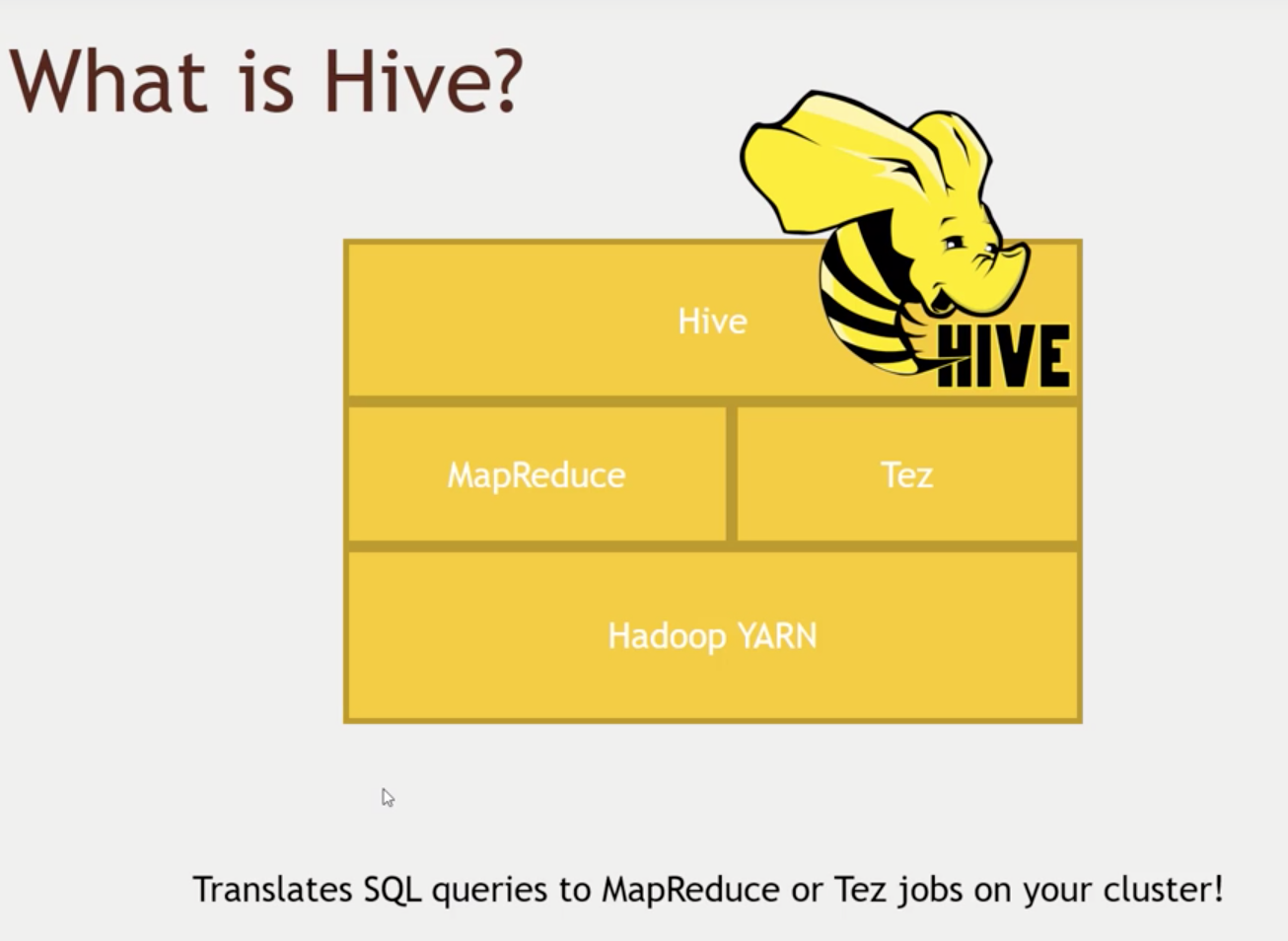
- Hive
- Sits on top of MapReduce
- Makes this HDFS files system looks like a SQL database
- You can connect to it using a shell client or even a driver like ODBC
- Oozie
- A way of scheduling jobs in your cluster
- More complicated operations
- Zookeeper
- Coordinating everything in your cluster
- Which nodes are up, which nodes are down
- Keeping track of who the master node is
- Apache Ambari (used by Hortonworks)
- Sits on top of everything
- Lets us have an overview of everything in your cluster
- How much resources
- What is up and running?
- View of the cluster
- Data Ingestion
- How you get data into your cluster
- Scoop
- A tool that enables anything that communicates using ODBC, JDBC (relational database) to Hadoop
- A connector between Hadoop and your legacy databases
- Flume
- A way of transporting web logs
- Group of web services, get those logs and get those inside the cluster
- Kafka
- Collect data from any source and broadcast that to your hadoop cluster
- External data storage (integrating with Hadoop cluster)
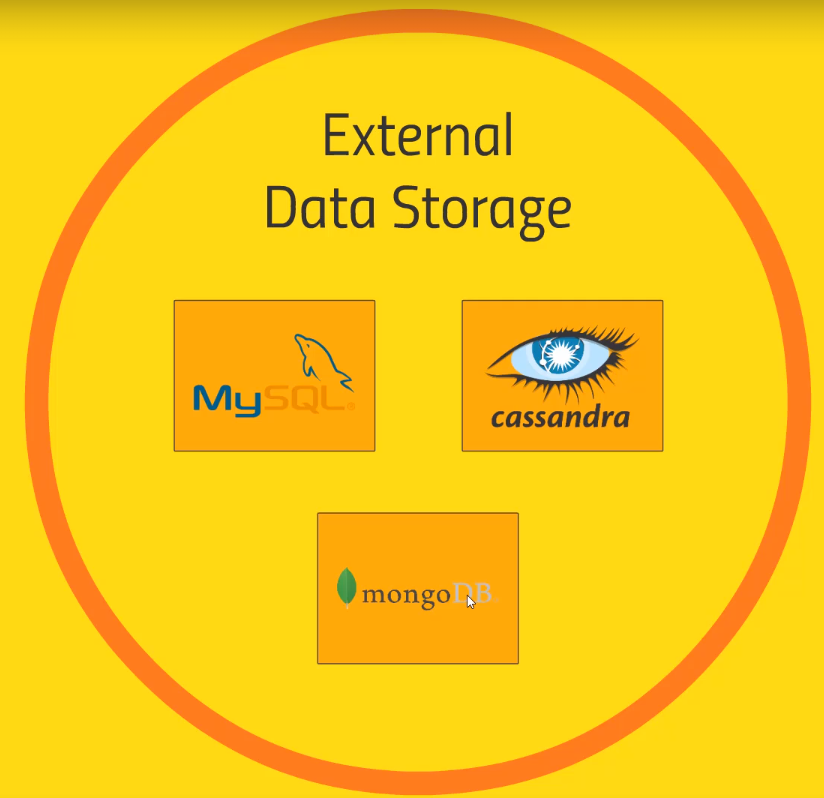
- HBase also fits here
- MySQL
- Import / exports data with Scoop / Spark
- Cassandra (key/value data store)
- MongoDB (key/value data store)
- Query Engines
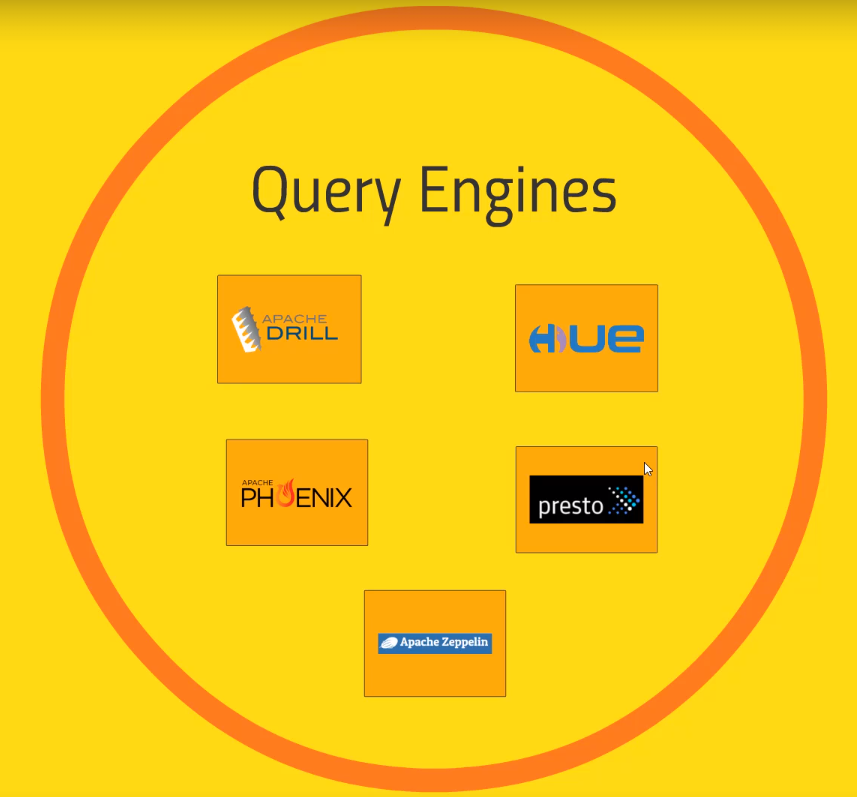
- Hive also fits here
- Apache Drill
- Write SQL queries that works in a wide range of NoSQL dbs (HBase, Cassandra, MongoDB)
- Hue
- Creating queries with Hive and HBase
- Apache Phoenix
- Similar to Drills
- Guarantees ACID
- presto
- Apache Zeppling
- Core Hadoop Ecosystem



-
Handling large files (broken up across a large cluster)
- Breaking into blocks (128 megabytes blocks)
- Stored across several commodity computers
- They may be even located nearby each other in the network to minimize reads/writes
- The same block will be saved in more than one computer, that way generating redundancy
- If a node goes down, it is ok
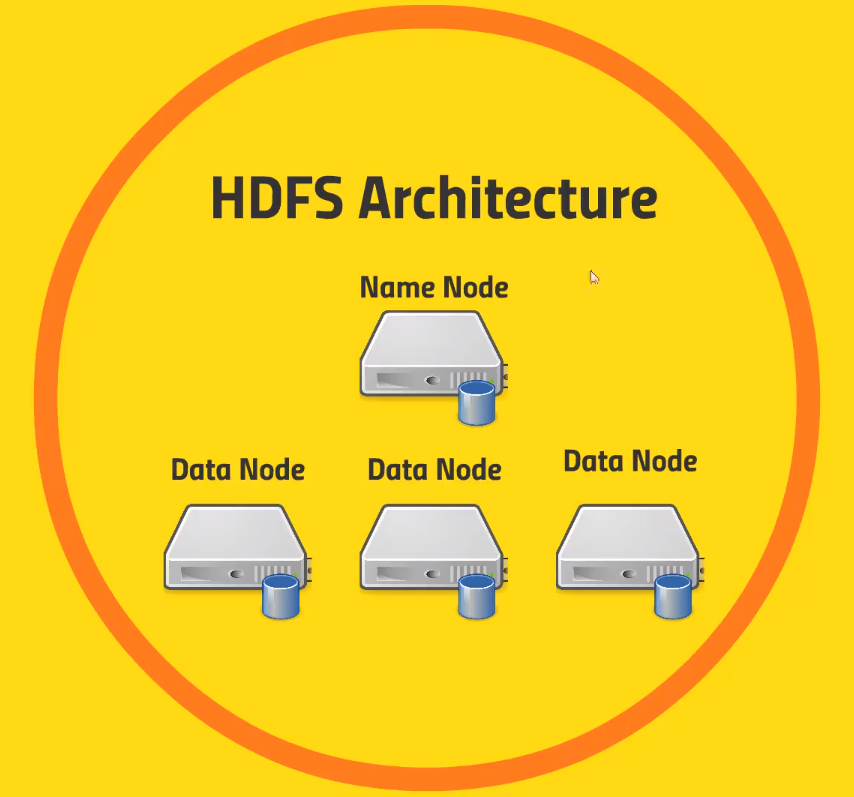
- Name node: This guy tracks where all those blocks live. It maintains a big table with the virtual file name, and it knows its associated blocks (which nodes it is stored in)
- It also maintains an edit log (what is being created, what is being modified, what is being stored) to keep track where the blocks are
- Data node: Store each block of each file
- Name node: This guy tracks where all those blocks live. It maintains a big table with the virtual file name, and it knows its associated blocks (which nodes it is stored in)
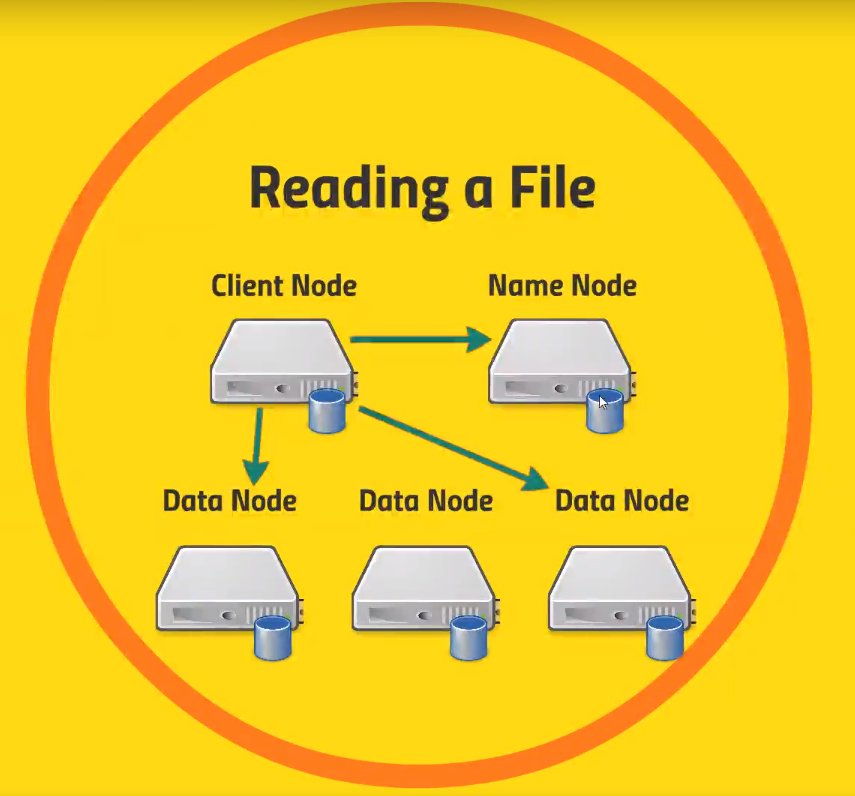
- We have a
Client Noderunning our application - First thing it will do is to talk to the
Name Nodeasking for a specific file- The
Name Nodewill come back with a list of blocks andData Nodeswhere they are located. - It will also optimize this list with the best
Data Nodesbased on your location in the network
- The
- Finally, the client application will reach the
Data Nodesin order to retrieve the blocks
- We have a
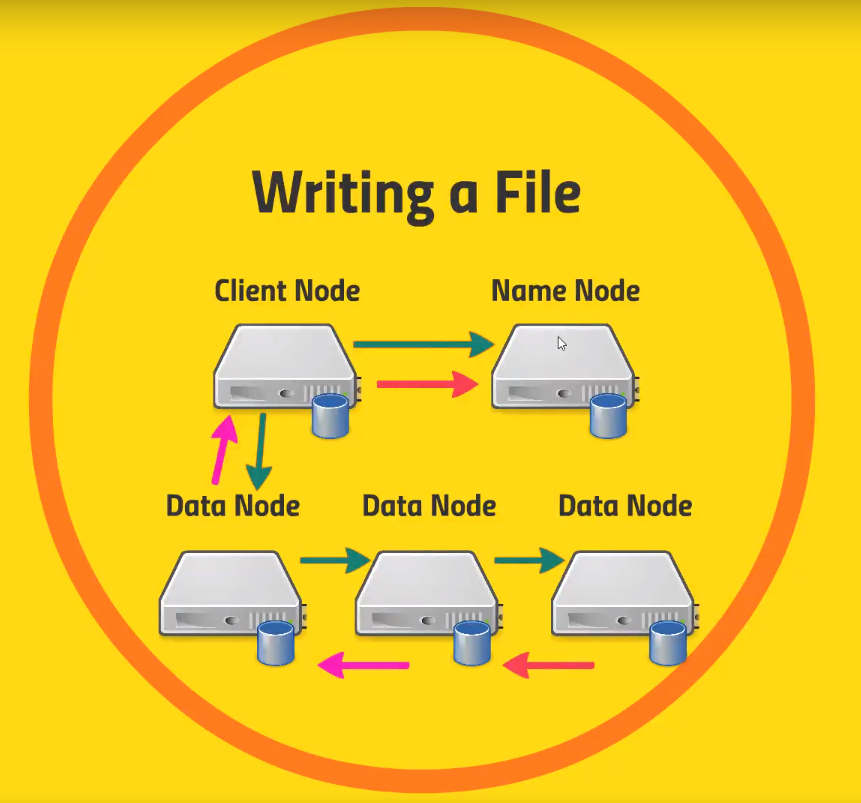
- Whenever you create a file your
Client Nodewill first reach out to theName Nodein order to update his table. - After that, the
Client Nodewill reach to one of theData Nodesin order to write the blocks. On that note, theData Nodewill talk to otherData Nodesand distribute the blocks among them- The
Data Nodestalk to each other in order to store the file
- The
- As soon as the file is saved, the
Data Nodesends a message back to theClient Node, and right after that theClient Nodecommunicates the change to theName Node.
- Whenever you create a file your
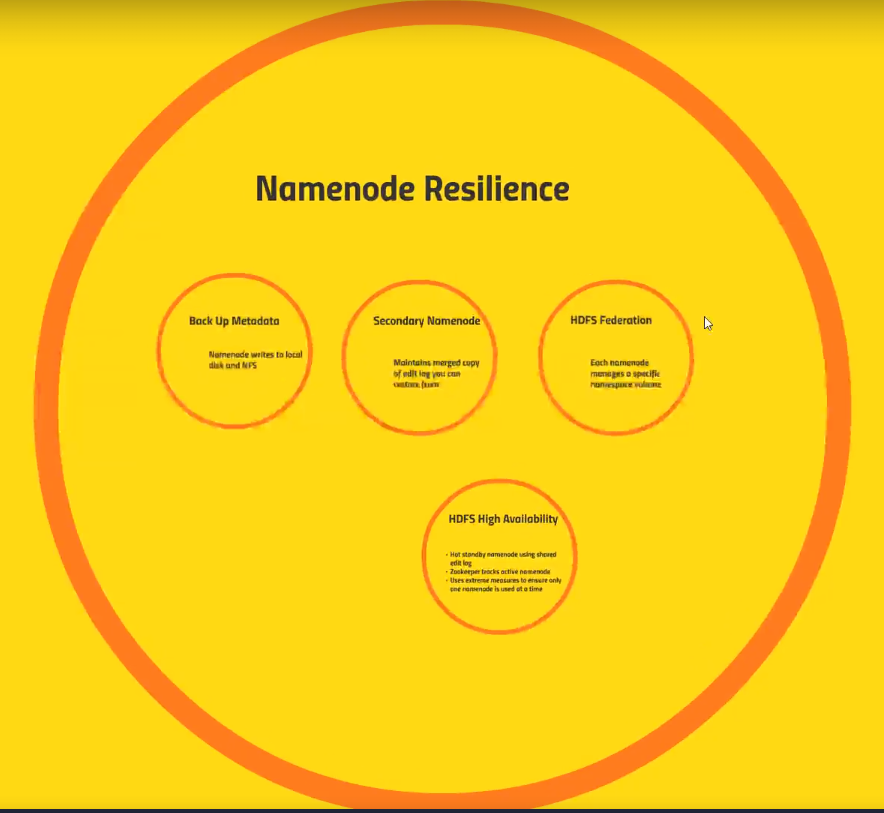
- Back Up Metadata:
Name nodewrites to local disk and NFS- NFS: Network File System
- Secondary Name Node: Maintains merged copy of edit log you can restore from
- HDFS Federation: Each
Name Nodemanages a specific namespace volume- HFS is optimized for large files, and not so much for lots and lots of small files. However, in case you have lots and lots of small files, maybe a
Name Nodewill reach its limit.- So HDFS Federation lets you assign a
Name Nodefor a specific name space volume.
- So HDFS Federation lets you assign a
- This is not a backup technic, but at least in this situation you would not lose all of your data.
- HFS is optimized for large files, and not so much for lots and lots of small files. However, in case you have lots and lots of small files, maybe a
- HDFS High Availability:
- Hot standby
Name Nodeusing shared edit log- No downtime. Your
Name Nodeis actually writing to a share log in some reliable file system that is not HDFS. That way if yourName Nodegoes down, your hotName Nodewill get in charge.
- No downtime. Your
- Zookeeper tracks active
Name Node - Uses extreme measures to ensure only one
Name Nodeis used at a time
- Hot standby
- Back Up Metadata:
- Using HDFS
- UI (Ambari)
- Command-Line Interface
- HTTP / HDFS Proxies
- An example is Ambari/File View
- Java interface
- NFS Gateway
-
To SSH into our Hadoop cluster we will connect to:
maria_dev@127.0.0.1at port2222- This port was mapped by our Hortonworks proxy container
- The password for this account is
maria_dev - We can run
hadoop fs -lsto list the files undermaria_devuser. - To create a directory we will do
hadoop fs -mkdir ml-100k - Lets get some data:
wget http://media.sundog-soft.com/hadoop/ml-100k/u.datahadoop fs -copyFromLocal u.data ml-100k/u.datahadoop fs -rm ml-100k/u.datahadoop fs -rmdir ml-100k
-
Why MapReduce?
- Distributes the processing of data on your cluster
- Divides your data up into partitions that are MAPPED (transformed) and REDUCED (aggregated) by mapper and reducer functions you define
- Resilient to failure - an application master monitors your mappers and reducer on each partition
-
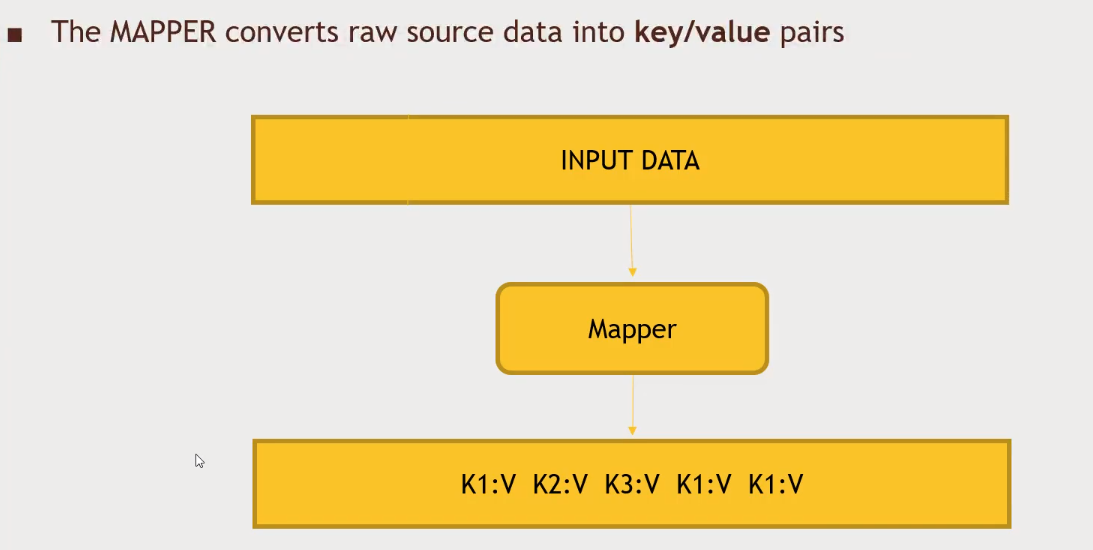
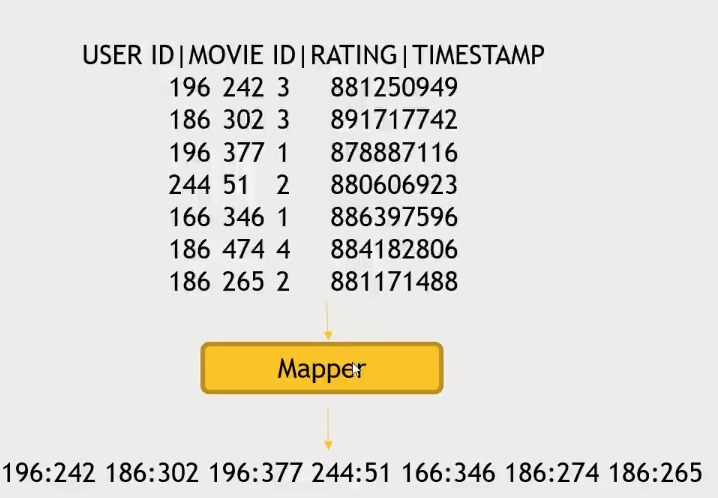
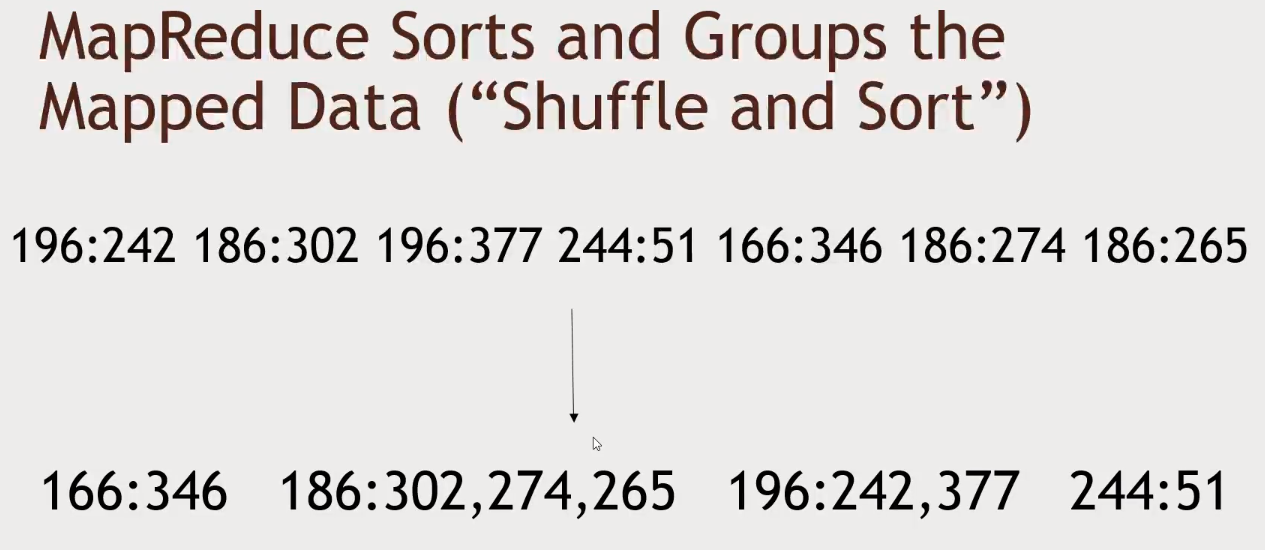
- MapReduce will automatically group key/values and sort keys for you

-
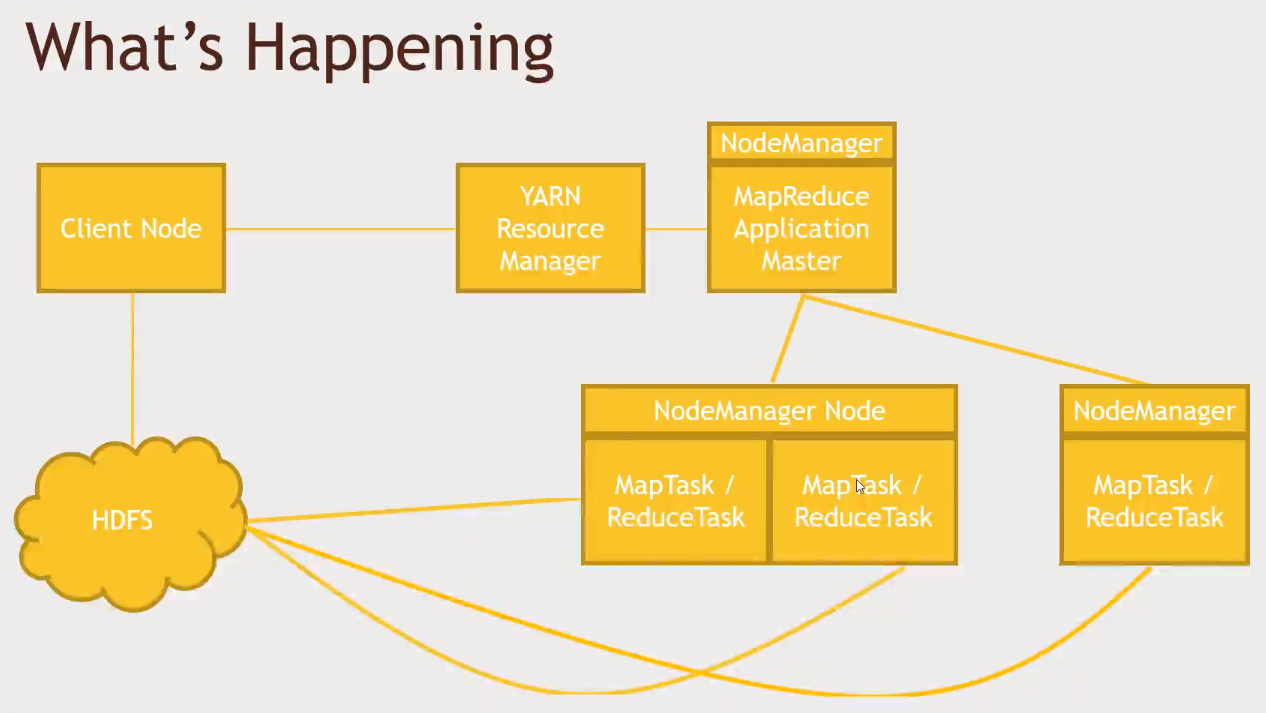
- Client node will communicate with the HDFS in order to kick in any data retrieval needed.
YARNwill be responsible to establish aNodeManagerthat will keep track of its otherNodesprogress. Those otherNodeswill be as close as possible to theHDFSdata (data nodes).- Minimize network traffic
-
MapReduce is natively Java
- STREAMING allows interface to other languages (ie Python)
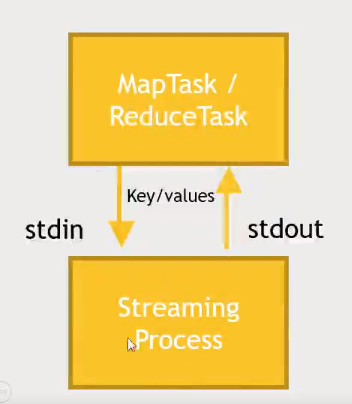
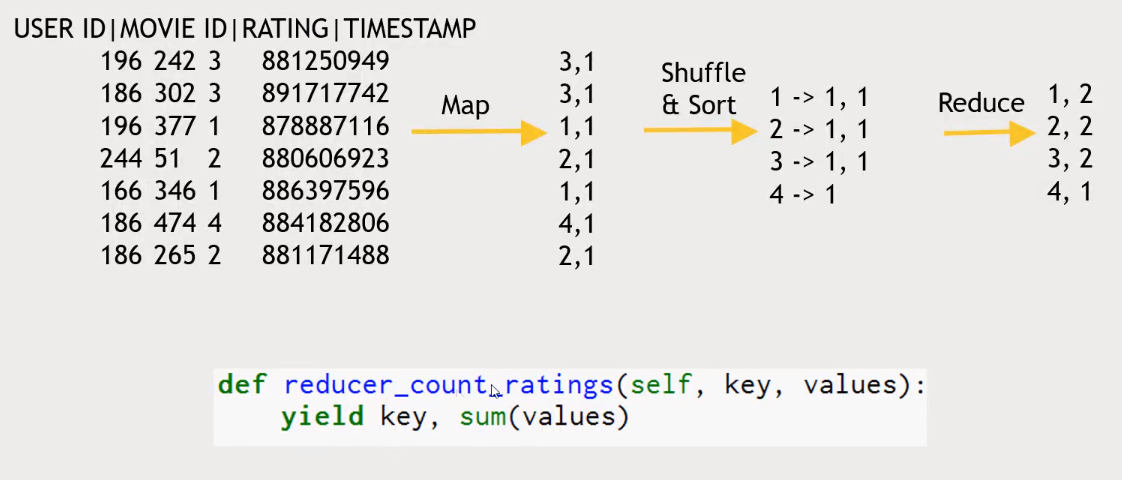
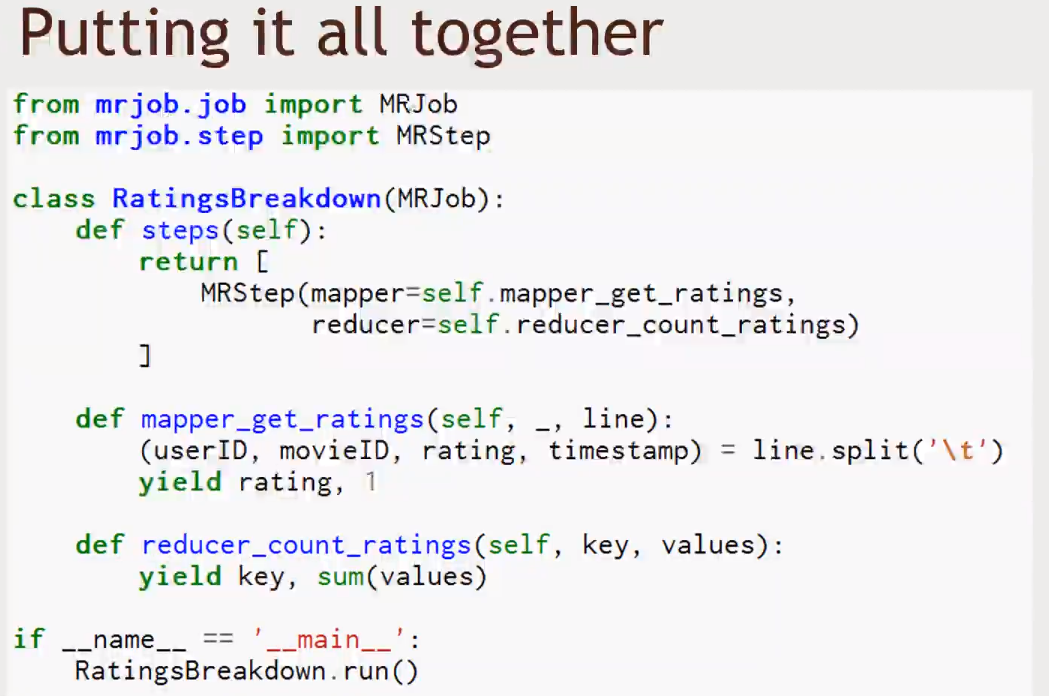
- The
MapReducetask will enable us to communicate with a separate streaming process. That other process we can write in Python, or another programming language. 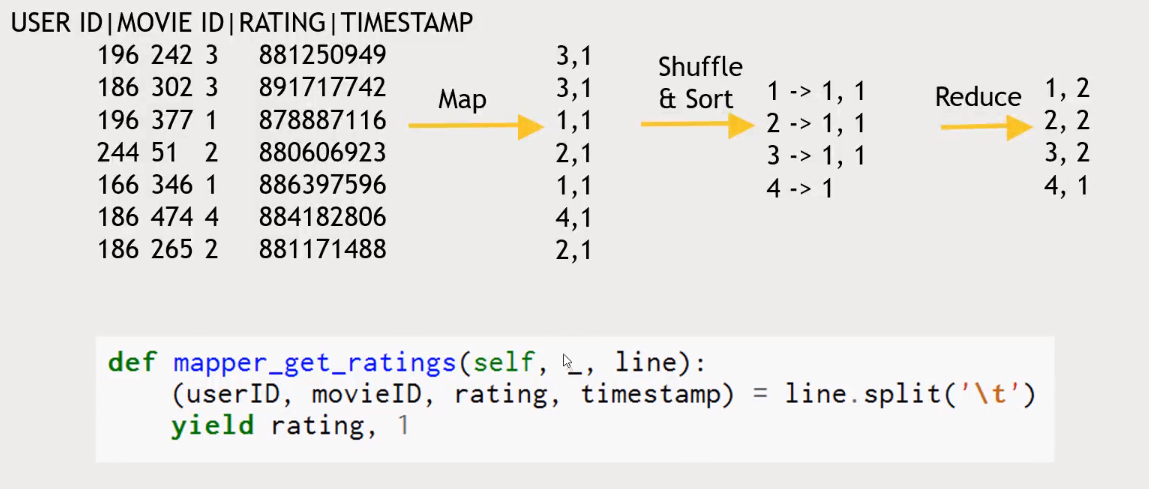

su root- password:
hadoop
- password:
- After that install
pipand all necessary packages 
-
Streaming final output from hdfs:///user/maria_dev/tmp/mrjob/RatingsBreakdown.maria_dev.20190129.095308.285570/output... "1" 6111 "2" 11370 "3" 27145 "4" 34174 "5" 21203 Removing HDFS temp directory hdfs:///user/maria_dev/tmp/mrjob/RatingsBreakdown.maria_dev.20190129.095308.285570... Removing temp directory /tmp/RatingsBreakdown.maria_dev.20190129.095308.285570... 

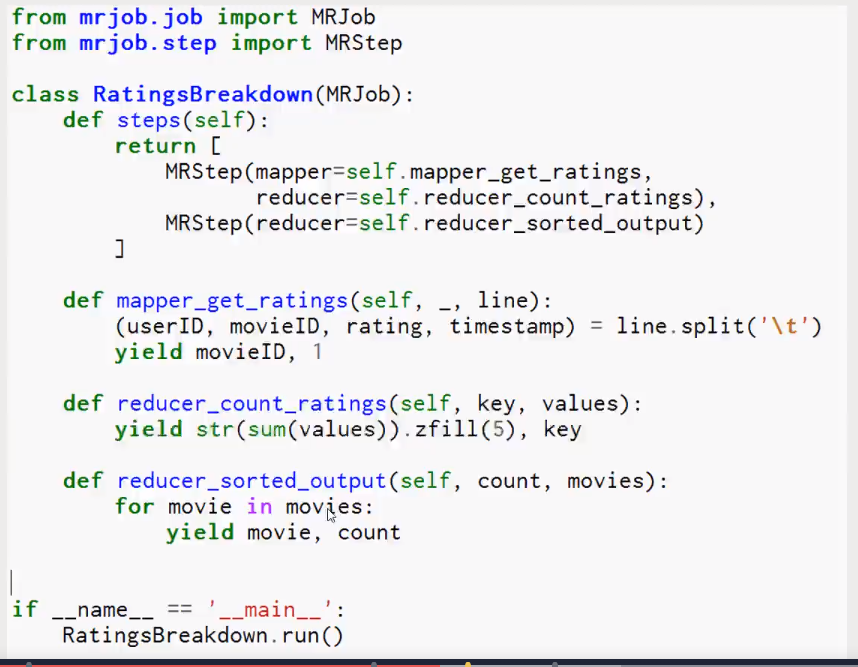
- The


















-
Lets create a user to act as an
admininsideAmbarisu rootambari-admin-password-reset
-
You now can access the
Pig Viewby clicking the top right menu option. -
Scripting language called
Pig Latin- Creates MapReduce jobs without creating Mappers and Reducers
- SQL-like syntax to define your map and reduce steps
-
Sits on top of
MapReduceorTez, it can translate its scripts for both platforms:Tezuses an acyclic graph to find the best path to get your data (10x faster thanMapReduce)MapReducewill run a series of Map->Reduce operations.
-
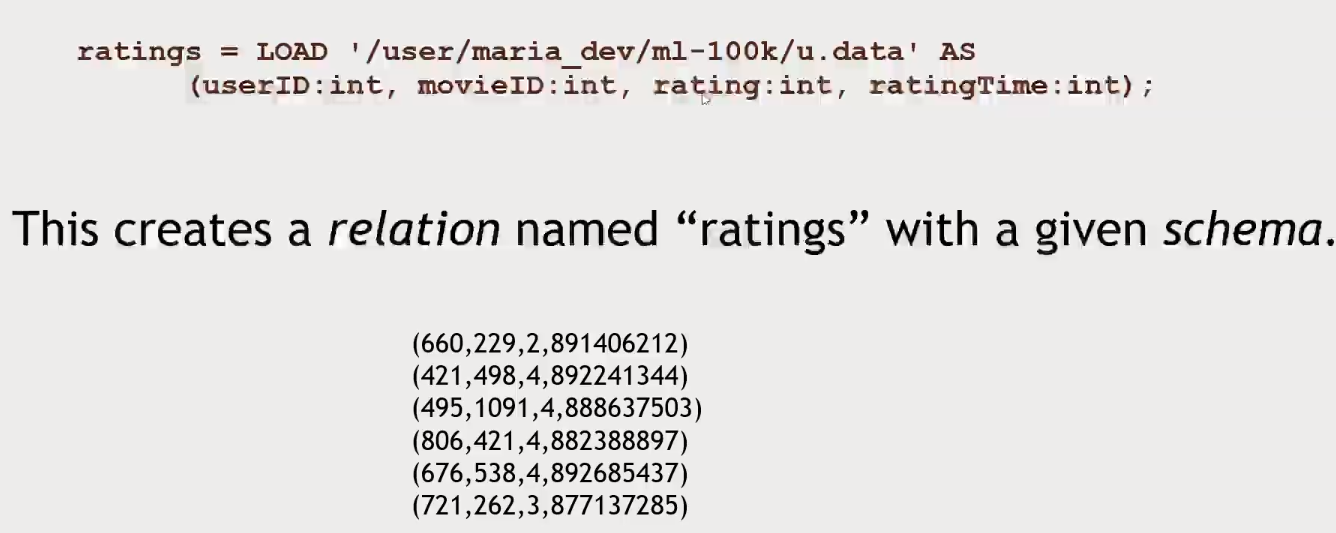
Pigis by default expecting tab limited data
-
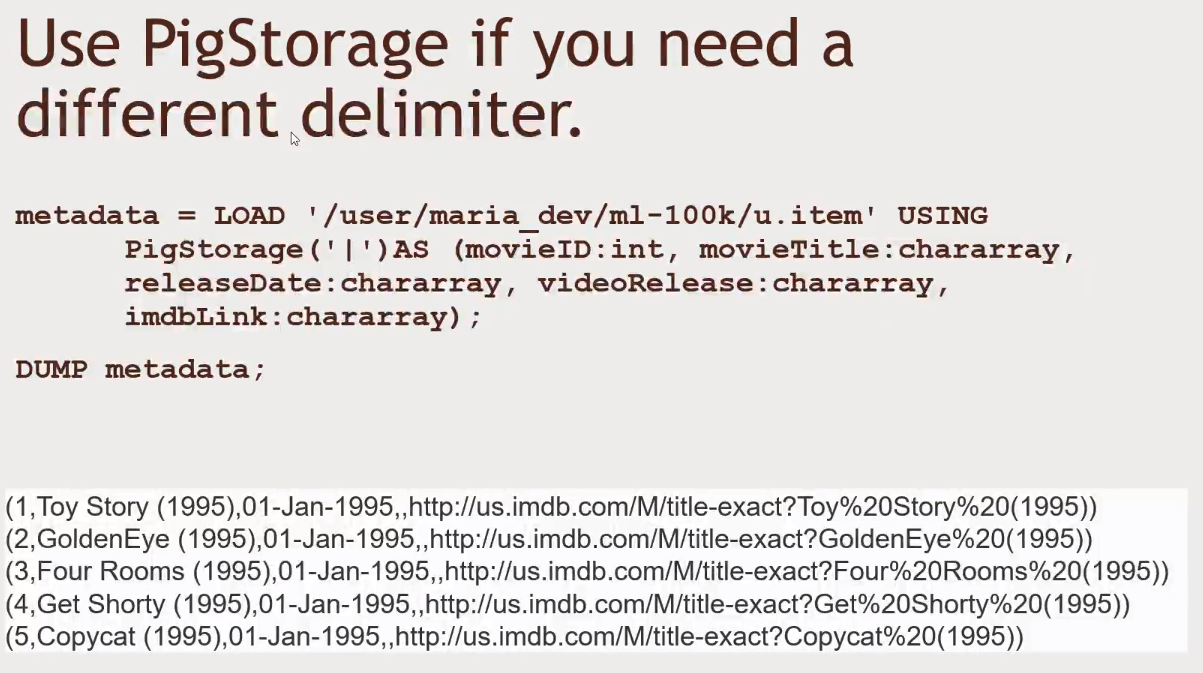
DUMP metadata: We just created a relation calledmetadataand we can print it to the screen by using theDUMPcommand- Good for debugging
-

- Generate a new relation based on a previous relation
-

- Looks like a reduce operation
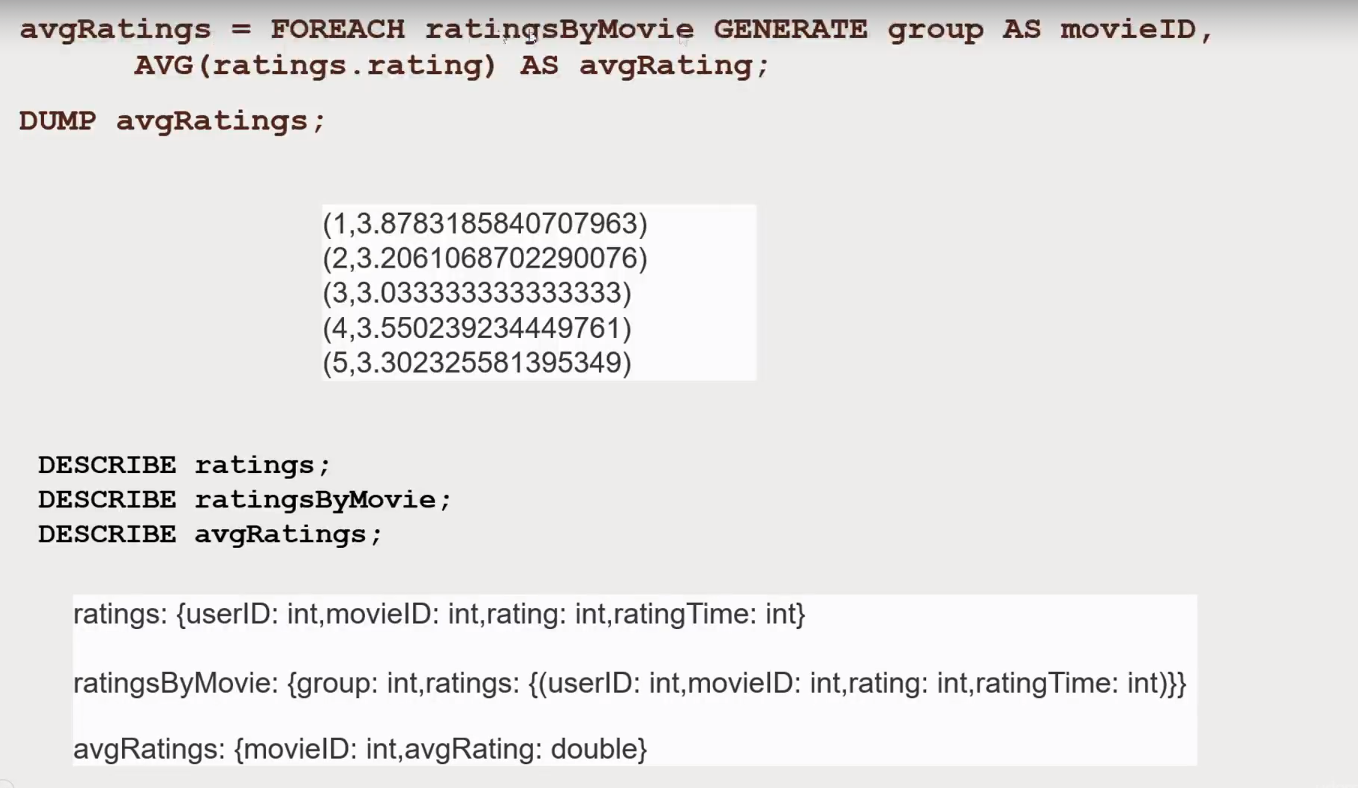
-
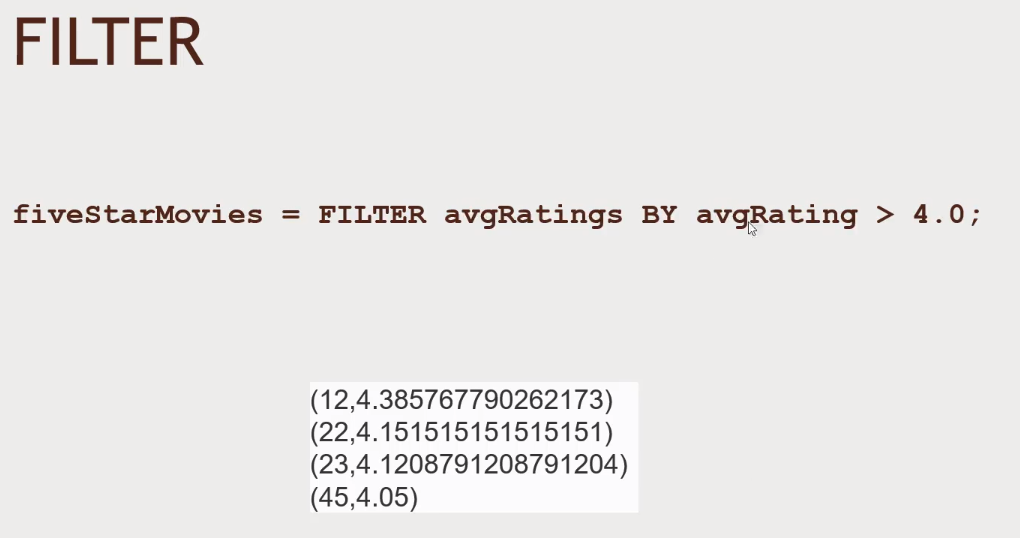
-
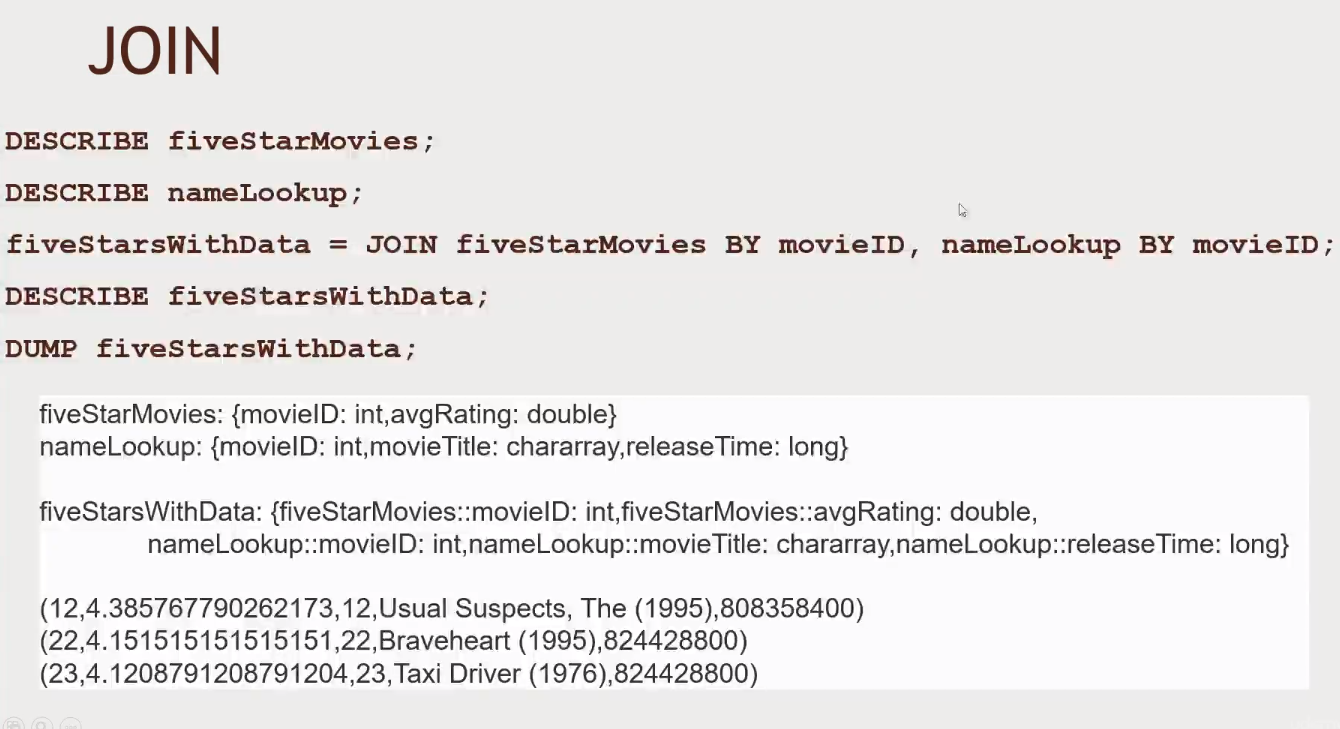
-

-
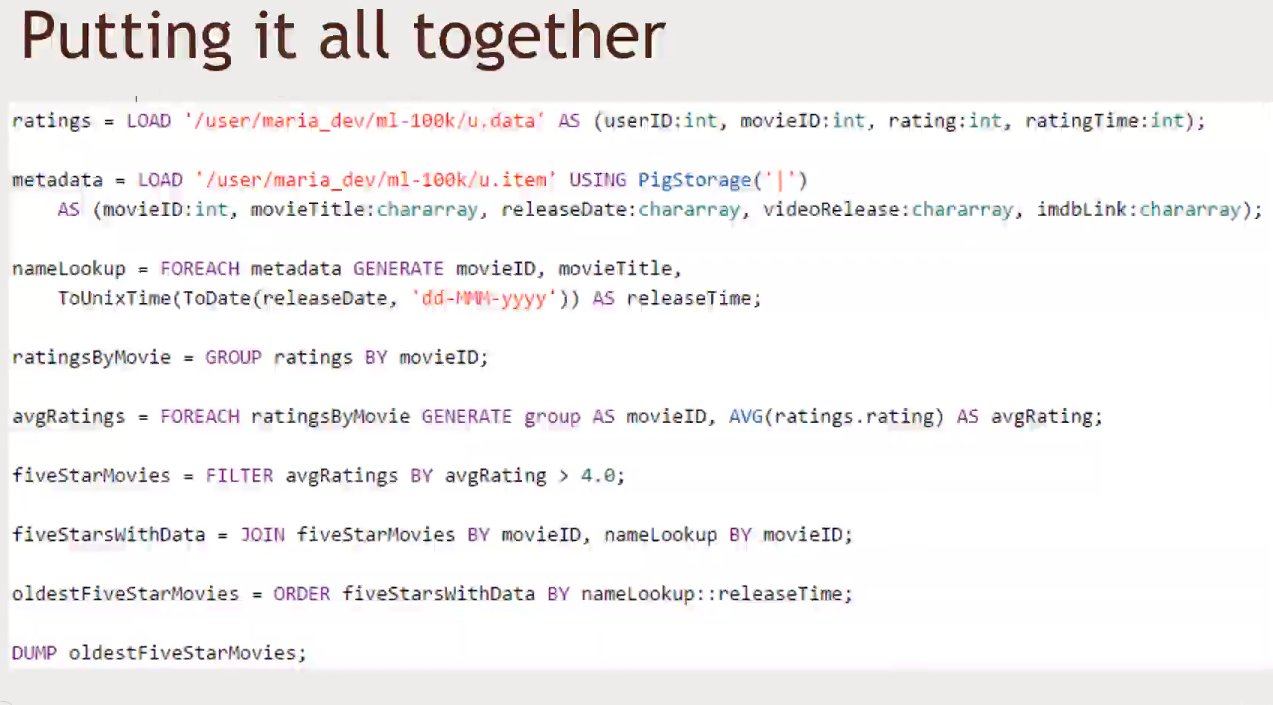
- Open
Ambari, navigate to thePig Viewand create the following script:- Remember to add the
ml-100kto your user folder before running the script -
ratings = LOAD '/user/maria_dev/ml-100k/u.data' AS (userID:int, movieID:int, rating:int, ratingTime:int); metadata = LOAD '/user/maria_dev/ml-100k/u.item' USING PigStorage('|') AS (movieID:int, movieTitle:chararray, releaseDate:chararray, videoRelease:chararray, imdbLink:chararray); nameLookup = FOREACH metadata GENERATE movieID, movieTitle, ToUnixTime(ToDate(releaseDate,'dd-MMM-yyyy')) as releaseTime; ratingsByMovie = GROUP ratings by movieID; avgRatings = FOREACH ratingsByMovie GENERATE group AS movieID, AVG(ratings.rating) AS avgRating; fiveStarMovies = FILTER avgRatings by avgRating > 4.0; fiveStarsWithData = JOIN fiveStarMovies by movieID, nameLookup by movieID; oldestFiveStarMovies = ORDER fiveStarsWithData BY nameLookup::releaseTime; DUMP oldestFiveStarMovies; - You can also run it using
Tezby checking theExecute on Tezcheck box on the top right corner
- Remember to add the
- Open
-
More about the Pig-latin language
-

STORE: to store the results in HDFSMAPREDUCE: lets you call actual Mappers and Reducers fromPigSTREAM: you can use stdin and stout to another process
-

DESCRIBE: Shows details of a relation (name and types)EXPLAIN: Very much like a SQL explain plan (shows the steps to get and merge the data together)ILLUSTRATE: Similar toEXPLAIN, it will show what is happening to the data in every single step
-

- User-defined functions in Java
REGISTER: I have a jar file that contains my user defined functionDEFINE: Assigns names to the registered functionsIMPORT: Import macros (pig code you have done before). Similar to C macros
-

-













-
A fast and general engine for large-scale data processing
- Compared to
Pig, this has a rich ecosystem that enables you to work with:- Machine Learning
- Data Mining
- Graph Analysis
- Streaming Data
- Compared to
-
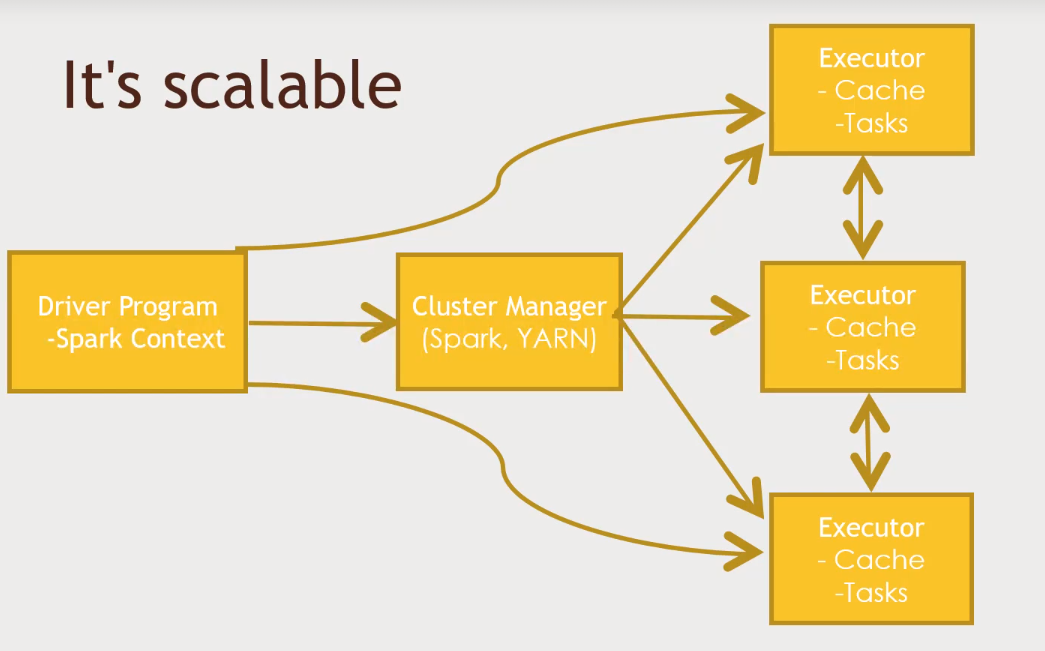
Driver Program: Script that controls what is going to happen in your jobSparkcan run on hadoop, but it can also run with other platforms. It can also useMesos- Whatever Cluster Manager you choose, it will distribute the job across nodes
- Process data in parallel
Sparktries to retain as much as it can in RAM (Cache)- "Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk"
- DAG Engine (directed acyclic graph) optimizes workflows
-
Code in Python, Java or Scala
- Build around one main concept: Resilient Distributed DataSet (RDD)
- RDD is an object that represents a DataSet, and there are various functions you can call in that RDD object to transform it, or reduce it / analyze it.
- Takes an RDD as input data, and transform it
- Spark 2.0: They have built on top of RDDs to build something called DataSets
- Build around one main concept: Resilient Distributed DataSet (RDD)
-

- Spark Streaming: Imagine you have a group of web servers producing logs, you could ingest that data and analyze it in real time
- Spark SQL: A SQL interface to Spark (really optimized)
- MLLib: A library of Machine Learning and Data Mining tools that you can run in a data set that is in Spark
- GraphX: Social graphs and other features
-


val nums = sc.parallelize(List[1,2,3,4])is generating an RDD called nums
-
RDD
- Resilient
- Distributed
- Dataset
- This is an object that knows how to manage it self on a cluster
-
The SparkContext
- You driver program will create a SparkContext
- It is responsible for making RDD's resilient and distributed!
- Creates RDD's
- The Spark shell creates a "sc" object for you
-

-

map: every input row of your RDD maps to an output row (1 to 1)flatmap: will let you discard some input lines, or output more than one line for an entry (0..any to 0..any)filter: Remove something from an RDDdistinct: Distinct unique values in an RDDsample: Random sample- Similar to Pig, but more powerful
-
Map example
-
rdd = sc.parallelize([1,2,3,4]) squaredRDD = rdd.map(lambda x: x*x)
- This yields 1, 4, 9, 16
-
-

collect: Take all of the results of an RDD and suck them down to the Driver Script. Reduced it to something that can fit in memorycount: How many rows in RDDcountByValue: How many times a value occurs in your RDDtake: Take the top 10 resultstop: Top few rows of an RDDreduce: Define a function to reduce the data
-
Lazy evaluation: Nothing actually happens in your driver program until an action is called
-
Lets start with an example with the lower level RDD interface: Spark 1
- Lower average rating movies
- This script bellow is an example of a
Driver Script -
from pyspark import SparkConf, SparkContext # This function just creates a Python "dictionary" we can later # use to convert movie ID's to movie names while printing out # the final results. def loadMovieNames(): movieNames = {} with open("ml-100k/u.item") as f: for line in f: fields = line.split('|') movieNames[int(fields[0])] = fields[1] return movieNames # Take each line of u.data and convert it to (movieID, (rating, 1.0)) # This way we can then add up all the ratings for each movie, and # the total number of ratings for each movie (which lets us compute the average) def parseInput(line): fields = line.split() return (int(fields[1]), (float(fields[2]), 1.0)) if __name__ == "__main__": # The main script - create our SparkContext conf = SparkConf().setAppName("WorstMovies") sc = SparkContext(conf = conf) # Load up our movie ID -> movie name lookup table (local memory since it is small) movieNames = loadMovieNames() # Load up the raw u.data file (actual RDD) lines = sc.textFile("hdfs:///user/maria_dev/ml-100k/u.data") # Convert to (movieID, (rating, 1.0)) movieRatings = lines.map(parseInput) # Reduce to (movieID, (sumOfRatings, totalRatings)) ratingTotalsAndCount = movieRatings.reduceByKey(lambda movie1, movie2: ( mov ie1[0] + movie2[0], movie1[1] + movie2[1] ) ) # Map to (rating, averageRating) averageRatings = ratingTotalsAndCount.mapValues(lambda totalAndCount : total AndCount[0] / totalAndCount[1]) # Sort by average rating sortedMovies = averageRatings.sortBy(lambda x: x[1]) # Take the top 10 results results = sortedMovies.take(10) # Print them out: for result in results: print(movieNames[result[0]], result[1])
spark-submit LowestRatedMovieSpark.py-
SPARK_MAJOR_VERSION is set to 2, using Spark2 ('3 Ninjas: High Noon At Mega Mountain (1998)', 1.0) ('Beyond Bedlam (1993)', 1.0) ('Power 98 (1995)', 1.0) ('Bloody Child, The (1996)', 1.0) ('Amityville: Dollhouse (1996)', 1.0) ('Babyfever (1994)', 1.0) ('Homage (1995)', 1.0) ('Somebody to Love (1994)', 1.0) ('Crude Oasis, The (1995)', 1.0) ('Every Other Weekend (1990)', 1.0)
-
-
Lets know cover Spark 2.0
-
Spark 2.0 is going for a more structured data approach
-
Extends RDD to a "DataFrame" object
-
DataFrames:- Contain Row objects
- Contains structured data
- Can run SQL queries
- Has a schema (leading to a more efficient storage)
- Read and write to JSON, Hive, parquet
- Communicates with JDBC/ODBC, Tableau
- Contain Row objects
-

-

- Remember,
Data Framesare build on top ofRDDs. So you can extract the underline RDD from it
- Remember,
-

-

-

-
RDD is the base/low level structure used in Spark to map/distribute data among a Spark cluster.
-
Dataset And Dataframe is a new abstraction API that allows the developer to work on a higher level that is more of tabular approach to your data, Dataset and Dataframe are backed by RDD.
-
The difference between dataset and dataframe is Dataset is strongly typed meaning you need to define the structure and type of fields during development.
-
Great post about RDDs, DataFrames and Datasets: https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
- Starting in Spark 2.0, Dataset takes on two distinct APIs characteristics: a strongly-typed API and an untyped API, as shown in the table below. Conceptually, consider DataFrame as an alias for a collection of generic objects Dataset[Row], where a Row is a generic untyped JVM object. Dataset, by contrast, is a collection of strongly-typed JVM objects, dictated by a case class you define in Scala or a class in Java.
-
-
Lets create a Spark 2 script:
-
from pyspark.sql import SparkSession from pyspark.sql import Row from pyspark.sql import functions def loadMovieNames(): movieNames = {} with open("ml-100k/u.item") as f: for line in f: fields = line.split('|') movieNames[int(fields[0])] = fields[1] return movieNames def parseInput(line): fields = line.split() return Row(movieID = int(fields[1]), rating = float(fields[2])) if __name__ == "__main__": # Create a SparkSession (the config bit is only for Windows!) spark = SparkSession.builder.appName("PopularMovies").getOrCreate() # Load up our movie ID -> name dictionary movieNames = loadMovieNames() # Get the raw data lines = spark.sparkContext.textFile("hdfs:///user/maria_dev/ml-100k/u.data") # Convert it to a RDD of Row objects with (movieID, rating) movies = lines.map(parseInput) # Convert that to a DataFrame movieDataset = spark.createDataFrame(movies) # Compute average rating for each movieID averageRatings = movieDataset.groupBy("movieID").avg("rating") # Compute count of ratings for each movieID counts = movieDataset.groupBy("movieID").count() # Join the two together (We now have movieID, avg(rating), and count columns) averagesAndCounts = counts.join(averageRatings, "movieID") # Filter movies rated 10 or fewer times popularAveragesAndCounts = averagesAndCounts.filter("count > 10") # Pull the top 10 results topTen = popularAveragesAndCounts.orderBy("avg(rating)").take(10) # Print them out, converting movie ID's to names as we go. for movie in topTen: print (movieNames[movie[0]], movie[1], movie[2]) # Stop the session spark.stop()
export SPARK_MAJOR_VERSION=2spark-submit LowestRatedMovieDataFrame.py-
SPARK_MAJOR_VERSION is set to 2, using Spark2 ('Amityville: A New Generation (1993)', 5, 1.0) ('Hostile Intentions (1994)', 1, 1.0) ('Lotto Land (1995)', 1, 1.0) ('Power 98 (1995)', 1, 1.0) ('Falling in Love Again (1980)', 2, 1.0) ('Careful (1992)', 1, 1.0) ('Low Life, The (1994)', 1, 1.0) ('Amityville: Dollhouse (1996)', 3, 1.0) ('Further Gesture, A (1996)', 1, 1.0) ('Touki Bouki (Journey of the Hyena) (1973)', 1, 1.0)
-
-
On the next example lets do a movie recommendation script using
Spark 2.0and theMLLib-
from pyspark.sql import SparkSession from pyspark.ml.recommendation import ALS from pyspark.sql import Row from pyspark.sql.functions import lit # Load up movie ID -> movie name dictionary def loadMovieNames(): movieNames = {} with open("ml-100k/u.item") as f: for line in f: fields = line.split('|') movieNames[int(fields[0])] = fields[1].decode('ascii', 'ignore') return movieNames # Convert u.data lines into (userID, movieID, rating) rows def parseInput(line): fields = line.value.split() return Row(userID = int(fields[0]), movieID = int(fields[1]), rating = float(fields[2])) if __name__ == "__main__": # Create a SparkSession (the config bit is only for Windows!) spark = SparkSession.builder.appName("MovieRecs").getOrCreate() # Load up our movie ID -> name dictionary movieNames = loadMovieNames() # Get the raw data lines = spark.read.text("hdfs:///user/maria_dev/ml-100k/u.data").rdd # Convert it to a RDD of Row objects with (userID, movieID, rating) ratingsRDD = lines.map(parseInput) # Convert to a DataFrame and cache it ratings = spark.createDataFrame(ratingsRDD).cache() # Create an ALS collaborative filtering model from the complete data set als = ALS(maxIter=5, regParam=0.01, userCol="userID", itemCol="movieID", ratingCol="rating") model = als.fit(ratings) # Print out ratings from user 0: print("\nRatings for user ID 0:") userRatings = ratings.filter("userID = 0") for rating in userRatings.collect(): print movieNames[rating['movieID']], rating['rating'] print("\nTop 20 recommendations:") # Find movies rated more than 100 times ratingCounts = ratings.groupBy("movieID").count().filter("count > 100") # Construct a "test" dataframe for user 0 with every movie rated more than 100 times popularMovies = ratingCounts.select("movieID").withColumn('userID', lit(0)) # Run our model on that list of popular movies for user ID 0 recommendations = model.transform(popularMovies) # Get the top 20 movies with the highest predicted rating for this user topRecommendations = recommendations.sort(recommendations.prediction.desc()).take(20) for recommendation in topRecommendations: print (movieNames[recommendation['movieID']], recommendation['prediction']) spark.stop()
-












-
-

-

- It is meant for data analysis (analytics), not to be used for real time transactional db.
- OLTP: Online Transaction Process
- Hive is for OLAP (Online Analytical Processing)
- Under the hood it is just Mappers and Reducers
-

- Similar syntax as MySQL
-
- We can import files from HDFS or our local machine
- After that, we can create views just like
-
CREATE VIEW IF NOT EXISTS topMovieIDs as SELECT movieID, count(movieID) as ratingCount FROM ratings GROUP BY movieID ORDER BY ratingCount DESC;
- This will get stored in HDFS as a "table"
-
SELECT n.title, ratingCount FROM topMovieIDs t JOIN name n ON t.movieID = n.movieID;
DROP VIEW topMovieIDs
-
-
SQL databases generally work with a
Schema on Writeapproach. That means that we establish our table layout before inserting any data into the database. On the other hand, Hive works with aSchema on Readlayout, where the data is not stored in aSchemafashion, but whenever we read it then we convert it to aSchema- Data is saved without actual structure
-

- Without using Hive view in Ambari, those would be the steps needed to create the "table".
-

-

-

- In a nutshell, Hive is this SQL abstraction that makes our HDFS looks like a database. However, it is just a series of metafiles and actual files being crossed together. For this reason, this is NOT suitable for transaction systems (OLTP)
-
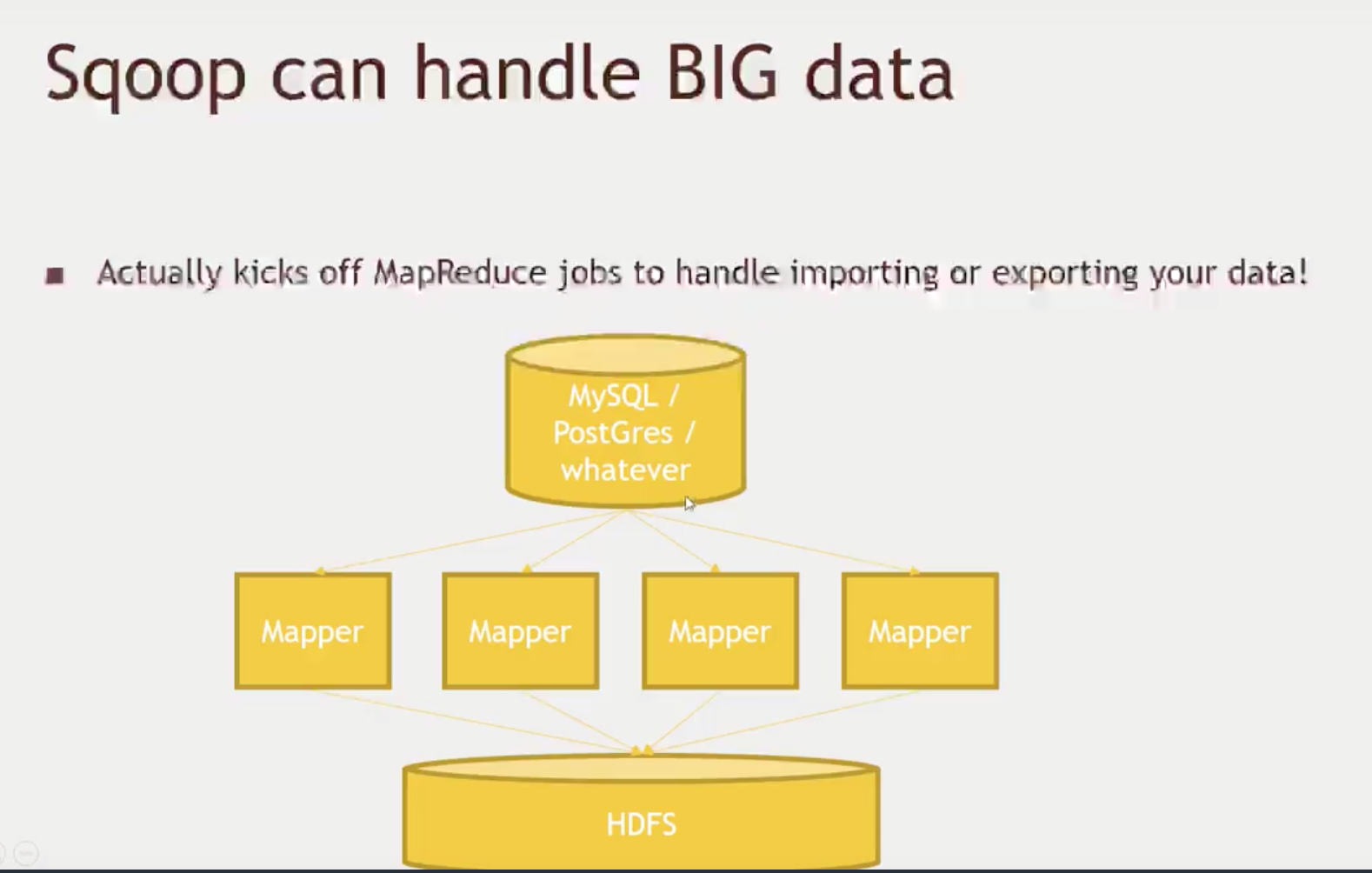
How to integrate an actual MySQL database to your Hadoop cluster.
- We will use Scoop to get MySQL data
-
-

-

-

-

- Note: Hive actually uses MySQL in order to work














-
NoSQL
- Your high-transaction queries are probably pretty simple once de-normalized
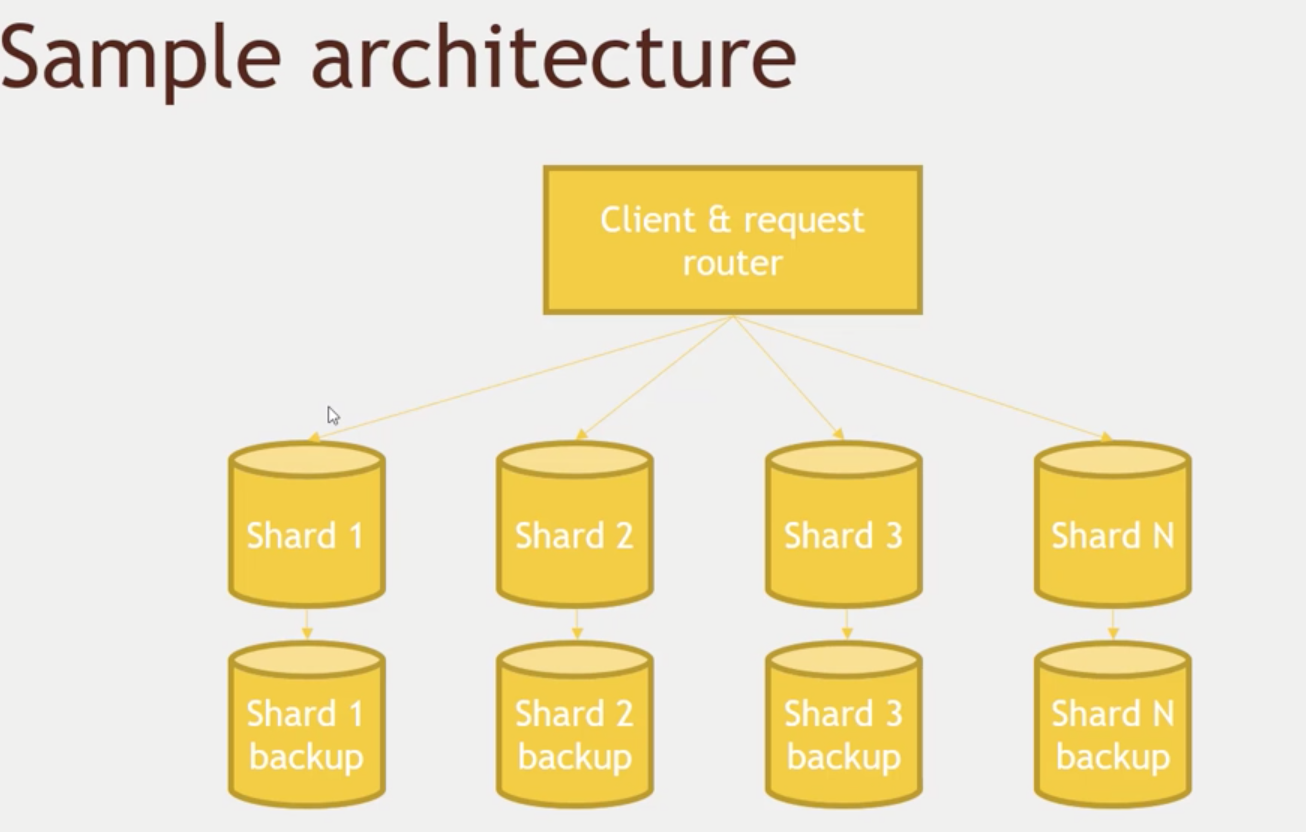
- Each shard takes care of a subset of keys
- For analytical queries we will still use SQL databases, they do a pretty good job at that. However, noSQL will help us scaling for online transactions (to server webapps, etc)
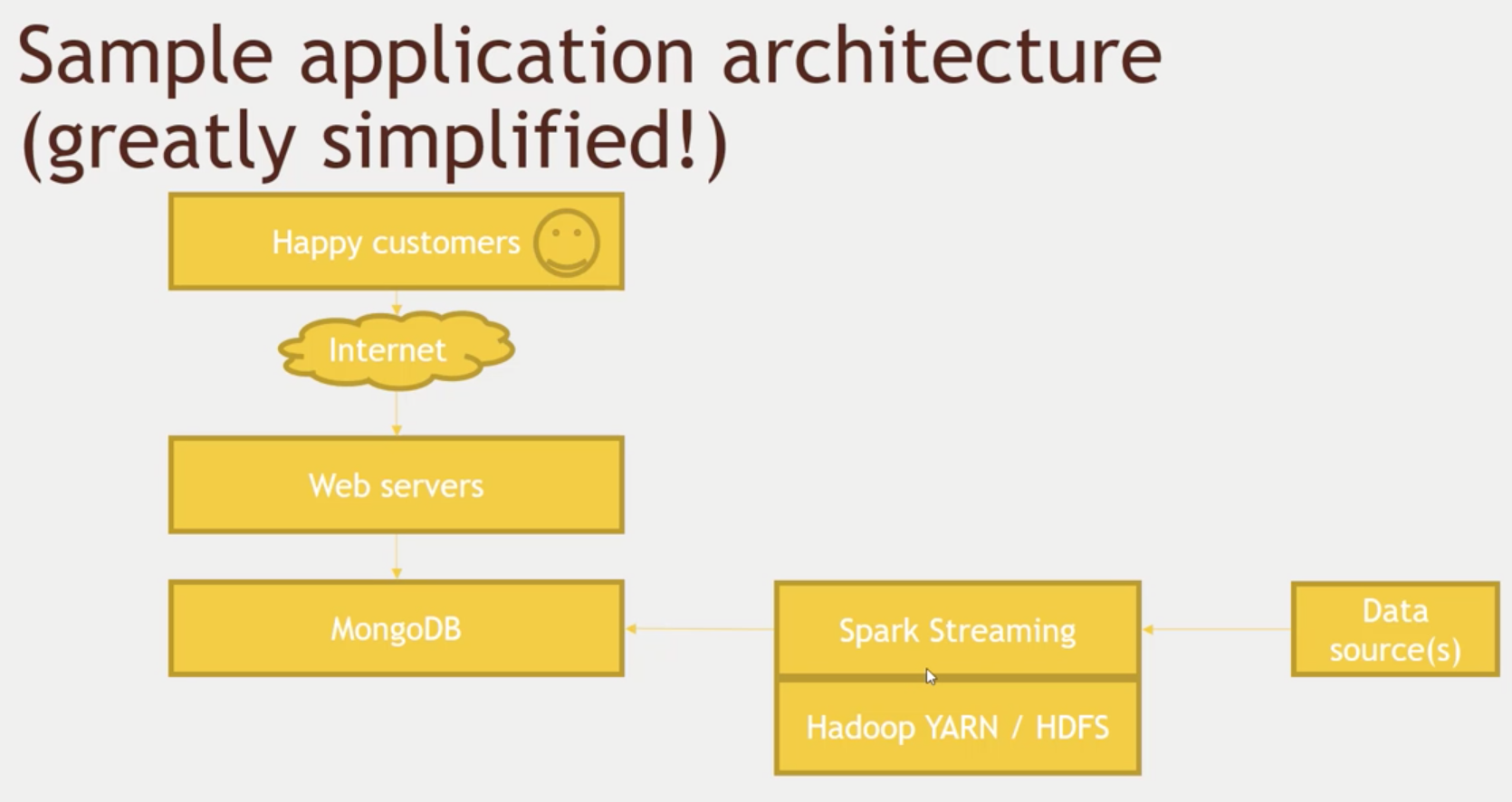
- You may have a data source (web apps) feeding the system with data.
- We will stream that data using Spark, generate some analysis on it and store that data in HDFS, but also send the processed data to MongoDB or some other NoSQL solution in order to answer questions quickly.
-
HBase
-
Build on top of HDFS
-
No query language, but it has an API (for CRUD)
-
Build on top of Big Table ideas from Google
-
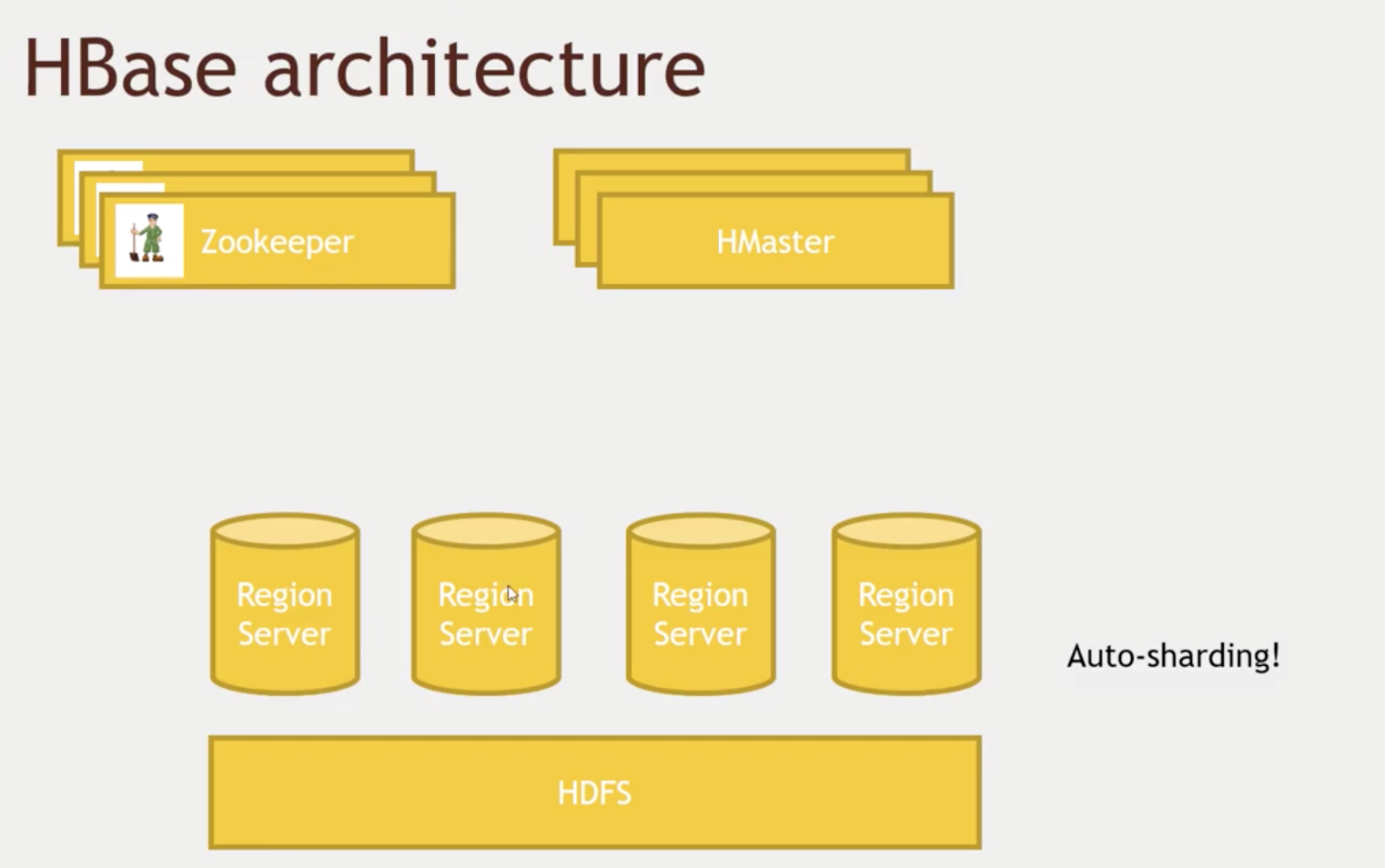
- Each server will take care of a range of keys (this is not a geographical filter)
- Just like sharding or partitioning
- The sharding (balancing the keys process) is done automatically
- It does that by doing Write Ahead Commit logs and other strategies
- HBase will copy those individual rows inside each "Region" in a bigger file inside HDFS.
- HMaster will keep track of your data schema, where things are stores, and how is it partitioned.
- Mastermind of HBase
- Zookeeper will keep track of HMasters so the cluster is always up and running properly even if some Node goes down.
- Each server will take care of a range of keys (this is not a geographical filter)
-
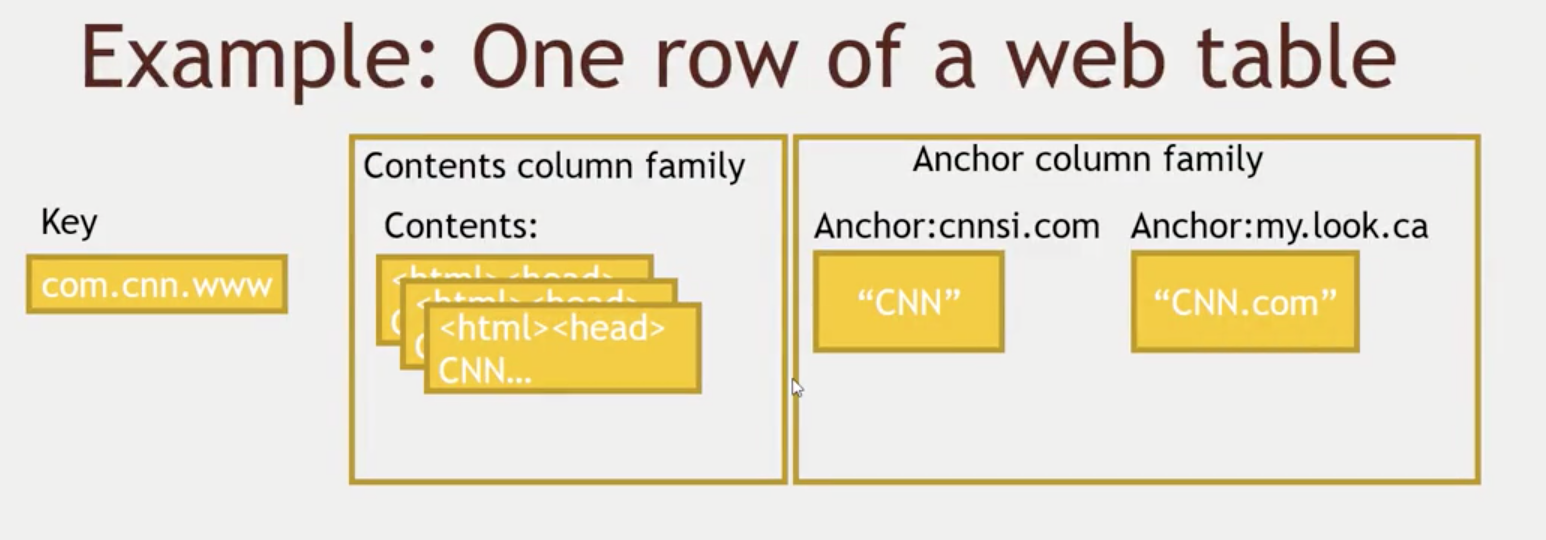
Data Model
- Fast access to any given ROW
- A ROW is referenced by a unique KEY
- Each ROW has some small number of COLUMN FAMILIES
- A COLUMN FAMILY may contain arbitrary COLUMNS
- You can have a very large number of COLUMNS in a COLUMN FAMILY
- It is like having a list of values inside a ROW
- Each CELL can have many VERSIONS with timestamps
- Sparse data is A-OK - missing column in a row consumes no storage at all.
-
-
-
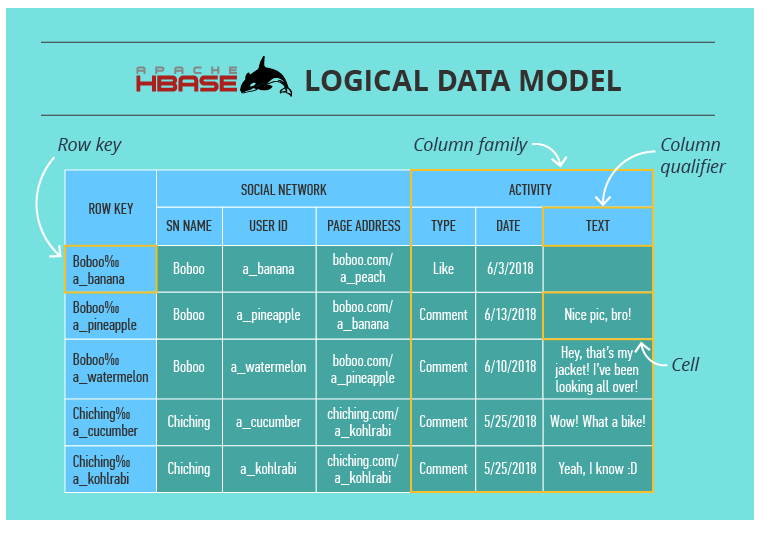
Here we have a table that consists of cells organized by row keys and column families. Sometimes, a column family (CF) has a number of column qualifiers to help better organize data within a CF.
-
A cell contains a value and a timestamp. And a column is a collection of cells under a common column qualifier and a common CF.
-
Within a table, data is partitioned by 1-column row key in lexicographical order (is a generalization of the way words are alphabetically ordered based on the alphabetical order of their component letters.), where topically related data is stored close together to maximize performance. The design of the row key is crucial and has to be thoroughly thought through in the algorithm written by the developer to ensure efficient data lookups.
-
-

-
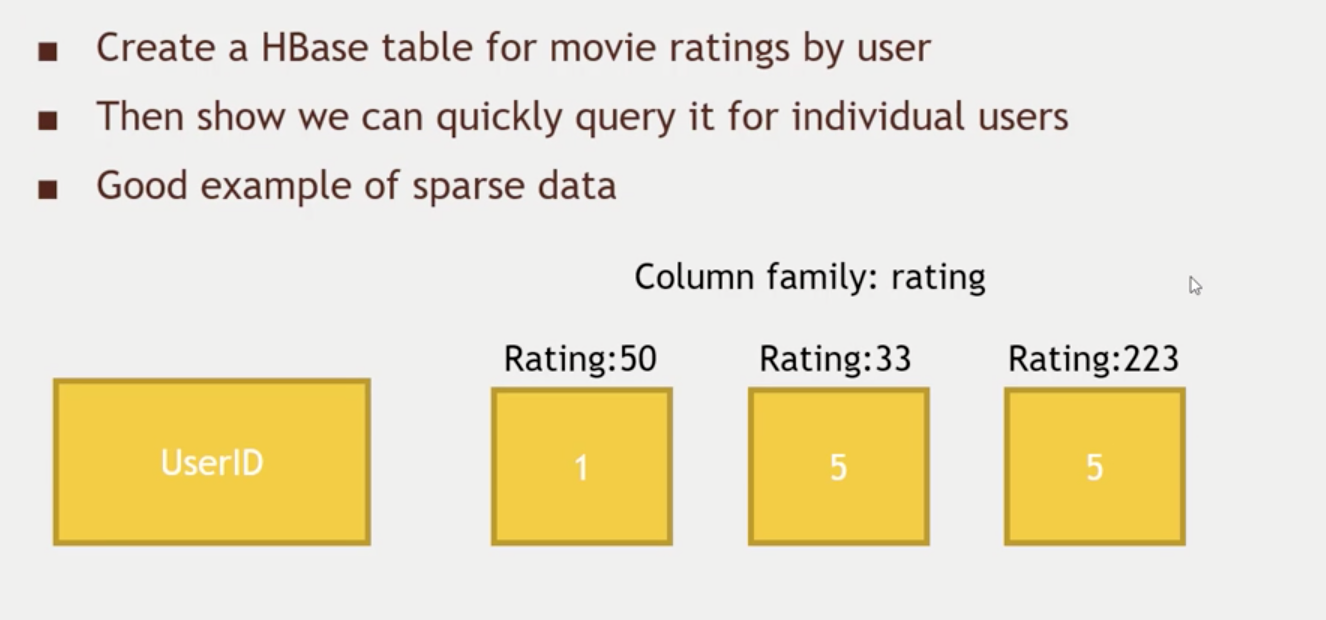
- For a specific UserID we will have a COLUMN FAMILY (list) of ratings.
{ movieId: rating }
- For a specific UserID we will have a COLUMN FAMILY (list) of ratings.
-
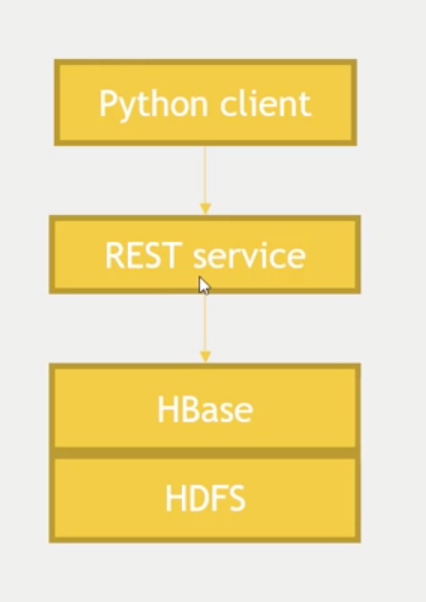
- Remember that HBase Regions are near to the appropriate Data Nodes they need to communicate to. They are always minimizing network calls.
- Region server may be running on the same server as a Data Node. This is data locality
- Remember that HBase Regions are near to the appropriate Data Nodes they need to communicate to. They are always minimizing network calls.
-
-
Script inside
HadoopMaterials/HBaseExamples.py-
# Remember to start HBase inside Ambari # you also need to ssh into the machine and start the server as root # su root # /usr/hdp/current/hbase-master/bin/hbase-daemon.sh start rest -p <port> --infoport <infoport> # hbase rest start -p <port> --infoport <infoport> # Remember to open port 8000 from starbase import Connection c = Connection("127.0.0.1", "8000") ratings = c.table('ratings') # Creates a COLUMN FAMILY if (ratings.exists()): print("Dropping existing ratings table\n") ratings.drop() ratings.create('rating') print("Parsing the ml-100k ratings data...\n") ratingFile = open("./ml-100k/u.data", "r") batch = ratings.batch() print(batch) for line in ratingFile: (userID, movieID, rating, timestamp) = line.split() batch.update(userID, {'rating': {movieID: rating}}) ratingFile.close() print ("Committing ratings data to HBase via REST service\n") batch.commit(finalize=True) print ("Get back ratings for some users...\n") print ("Ratings for user ID 1:\n") print (ratings.fetch("1")) print ("Ratings for user ID 33:\n") print (ratings.fetch("33")) ratings.drop()
-
-
Region server maintains the inmemory copy of the table updates in memcache. In-memory copy is flushed to the disc periodically. Updates to HBase table is stored in HLog files which stores redo records. In case of region recovery, these logs are applied to the last commited HFile and reconstruct the in-memory image of the table. After reconstructing the in-memory copy is flushed to the disc so that the disc copy is latest.
-
Integrating Pig with HBase
-
In the previous example we read an entire file and created a
HBasetable usingREST. However, if we had a bigger file that would not be possible. -
In order to work with big files, we need to first upload the data to
HDFS, and then usePigin order to create ourHBasetable. -
The first step to work with
Pigis to create ourHBasetable ahead of time. -

- This way
Pigwill control many Mappers and Reducers in order to create theHBasetable - Another tool to import data to
HBaseis calledimport tsv(script)
- This way
-
Lets create our table:
hbase shelllist: All the tables on this HBase instancecreate 'users','userinfo': Create a table calleduserswith a single COLUMN FAMILYuserinfowget http://media.sundog-soft.com/hadoop/hbase.pig: DownloadPigscript-
users = LOAD '/user/maria_dev/ml-100k/u.user' USING PigStorage('|') AS (userID:int, age:int, gender:chararray, occupation:chararray, zip:int); STORE users INTO 'hbase://users' USING org.apache.pig.backend.hadoop.hbase.HBaseStorage ( 'userinfo:age,userinfo:gender,userinfo:occupation,userinfo:zip');- The first columen
userIDis automatically used as the key pig hbase.pig- Kicking off a Map/Reduce job
scan 'users'
disable 'users'drop 'users'
- The first columen
-
-
Cassandra
- Has no Master node. It is engineered for availability (no single point of failure)

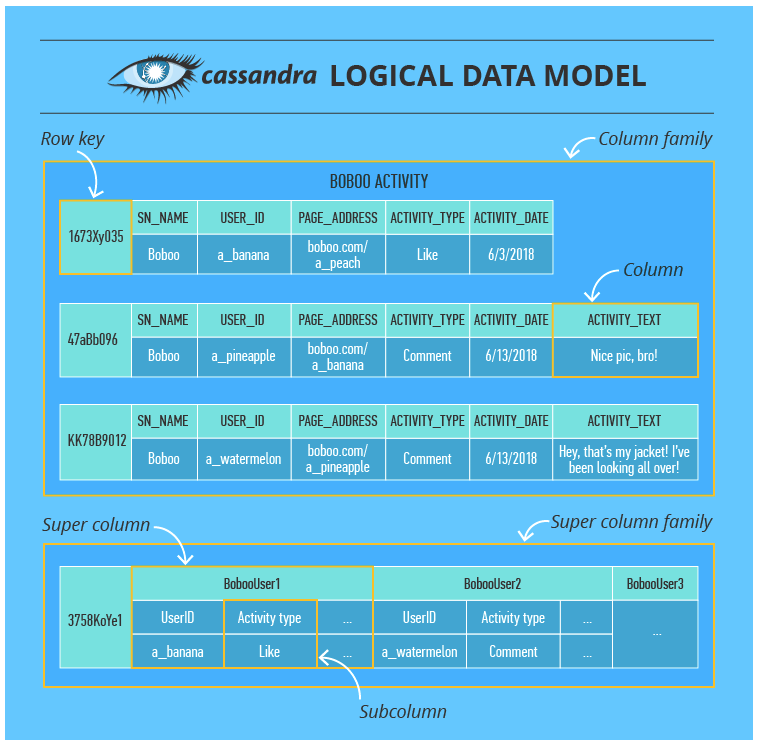
- Here we have a column family that consists of columns organized by row keys. A column contains a name/key, a value and a timestamp. In addition to a usual column, Cassandra also has super columns containing two or more subcolumns. Such units are grouped into super column families (although these are rarely used).
- In the cluster, data is partitioned by a multi-column primary key that gets a hash value and is sent to the node whose token is numerically bigger than the hash value. Besides that, the data is also written to an additional number of nodes that depends on the replication factor set by Cassandra practitioners. The choice of additional nodes may depend on their physical location in the cluster.

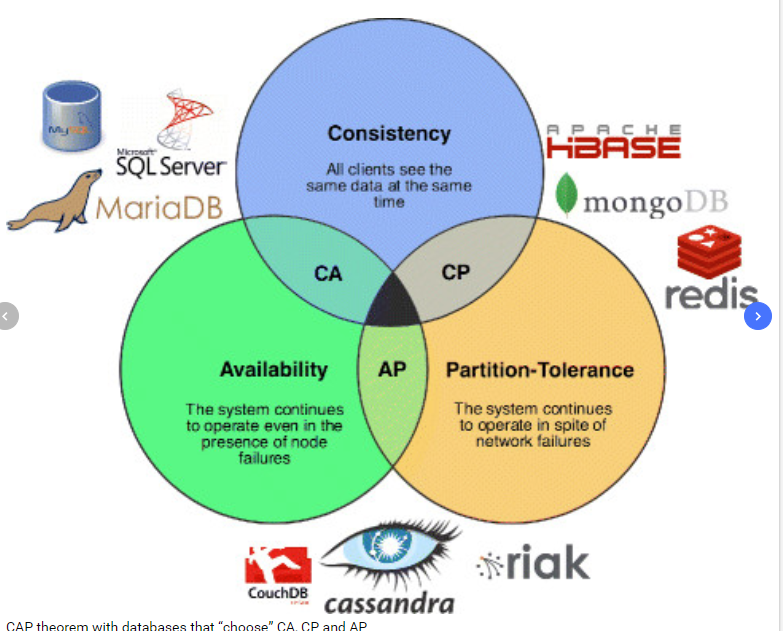
- CAP: Consistency, Availability and Partition Tolerance
- https://towardsdatascience.com/cap-theorem-and-distributed-database-management-systems-5c2be977950e
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non-error) response – without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
- A network partition refers to network decomposition into relatively independent subnets for their separate optimization as well as network split due to the failure of network devices. In both cases the partition-tolerant behavior of subnets is expected. This means that even after the network is partitioned into multiple sub-systems, it still works correctly.
- ACID
- Atomicity: An atomic transaction is an indivisible and irreducible series of database operations such that either all occur, or nothing occurs.
- Consistency: must change affected data only in allowed ways. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
- Isolation: determines how transaction integrity is visible to other users and systems. For example, when a user is creating a Purchase Order and has created the header, but not the Purchase Order lines, is the header available for other systems/users (carrying out concurrent operations, such as a report on Purchase Orders) to see? A lower isolation level increases the ability of many users to access the same data at the same time, but increases the number of concurrency effects (such as dirty reads or lost updates) users might encounter. Conversely, a higher isolation level reduces the types of concurrency effects that users may encounter, but requires more system resources and increases the chances that one transaction will block another.
- Durability: property which guarantees that transactions that have committed will survive permanently.
- CAP: Consistency, Availability and Partition Tolerance
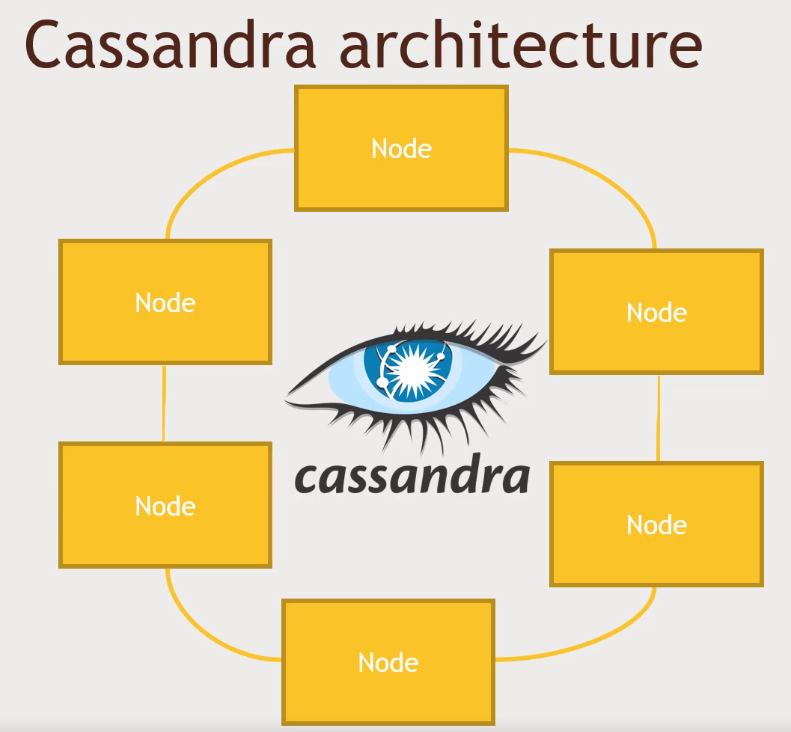
- Ring architecure
- We don't have a master Node keeping track of the other Nodes
- "Gossip" protocol
- Every node is communicating with each other every second
- Exact same software, exact same function
- Making sure has a backup copy
- Consistency can be stabilished based on the number of nodes that contains the same copy of the data


- S3 – Non-urgent batch jobs. S3 fits very specific use cases when data locality isn’t critical.
- Cassandra – Perfect for streaming data analysis and an overkill for batch jobs.
- HDFS – Great fit for batch jobs without compromising on data locality.

-
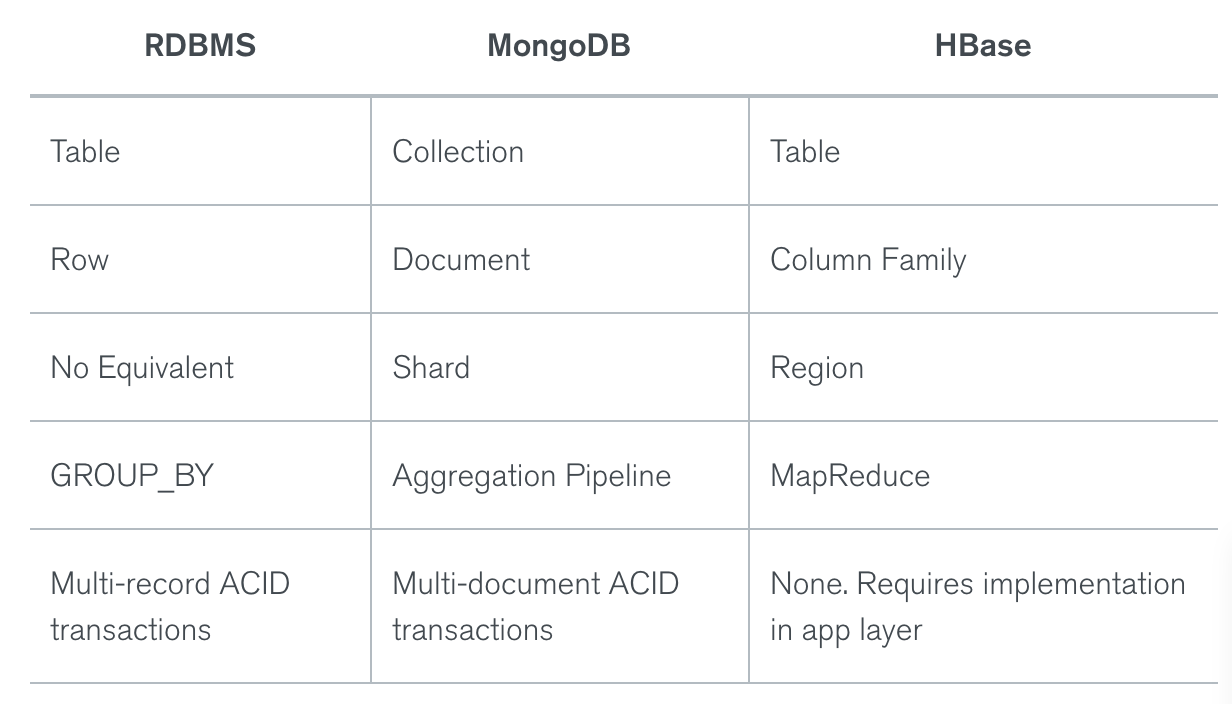
HBase vs. Cassandra (data model comparison)
-
The terms are almost the same, but their meanings are different. Starting with a column: Cassandra’s column is more like a cell in HBase. A column family in Cassandra is more like an HBase table. And the column qualifier in HBase reminds of a super column in Cassandra, but the latter contains at least 2 subcolumns, while the former – only one.
-
Besides, Cassandra allows for a primary key to contain multiple columns and HBase, unlike Cassandra, has only 1-column row key and lays the burden of row key design on the developer. Also, Cassandra’s primary key consist of a partition key and clustering columns, where the partition key also can contain multiple columns.
-
Despite these ‘conflicts,’ the meaning of both data models is pretty much the same. They have no joins, which is why they group topically related data together. They both can have no value in a certain cell/column, which takes up no storage space. They both need to have column families specified while schema design and can’t change them afterwards, while allowing for columns’ or column qualifiers’ flexibility at any time. But, most importantly, they both are good for storing big data.
-
But the main difference between applying Cassandra and HBase in real projects is this. Cassandra is good for ‘always-on’ web or mobile apps and projects with complex and/or real-time analytics. But if there’s no rush for analysis results (for instance, doing data lake experiments or creating machine learning models), HBase may be a good choice. Especially if you’ve already invested in Hadoop infrastructure and skill set.
-
-
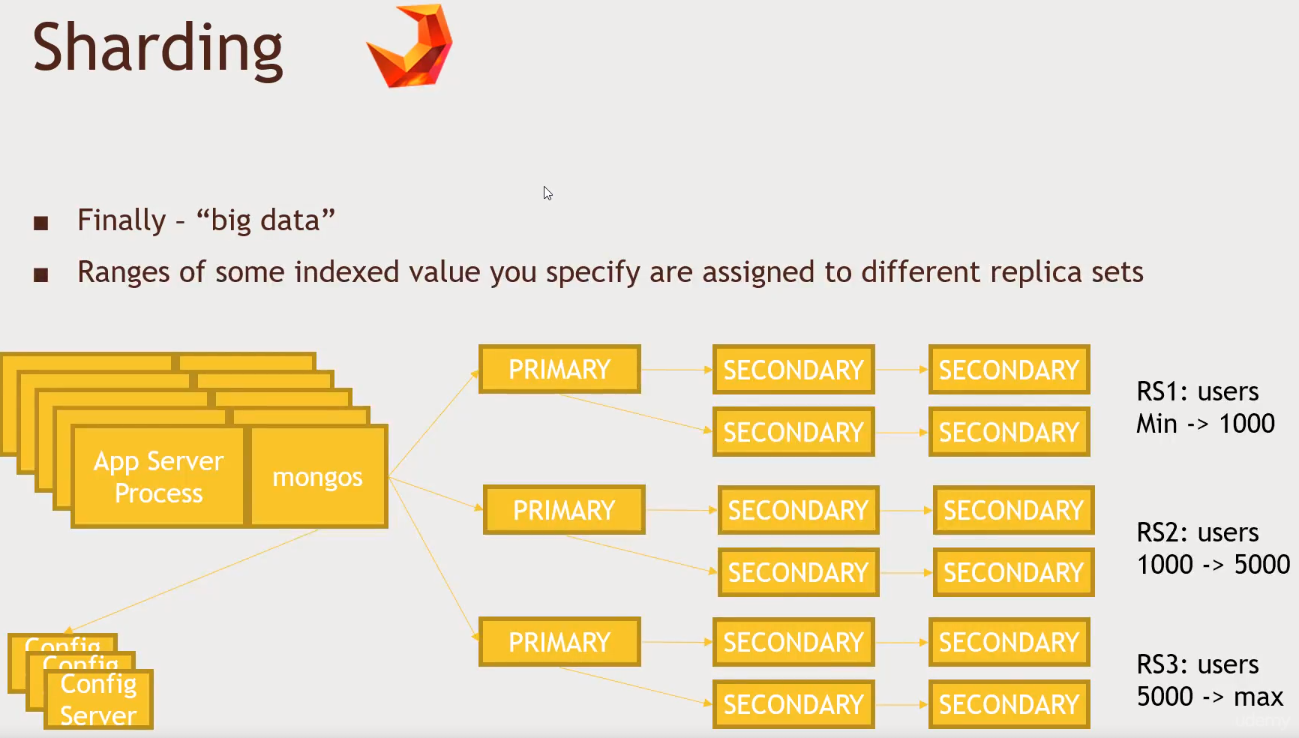
MongoDB
- Has a single master
- It is looking for Consistency and Partition Tolerance



- Elections are made if the PRIMARY is down
- A secundary may take over, but it will collect change logs and will apply those back at the PRIMARY whenever it is back up

- At least 3 servers in order to elect a PRIMARY
- You can set an ARBITER node in place of SECONDARY node to tell who should take over in case the PRIMARY fails


-



























-
Apache Drill
- Can issue queries on MongoDB, or files sitting on HDFS, S3 or Google Cloud Storage / Azure, Hive and HBase
- SQL Queries
-
Apache Phoenix
- SQL queries on HBase
-
Presto is similar to Drill
- It was made from Facebook
- Can talk to Cassandra, and Drill cannot
- Drill can talk to MongoDB, but Presto cannot
-
Apache Drill
- SQL for noSQL
- Based on Google's Dremel (early 2000s)
- It is actual SQL (based on the SQL 2003 standards)
- With Hive you need to use HiveSQL, but here we can use real SQL
- Has support for ODBC / JDBC drivers

- You could join data from your MongoDB instance and your hive instance, HBase.. and even some random JSON file sitting somewhere
- SQL for you entire ecosystem
Apache Drilldoes not come packed with HDP- Run steps:
wget http://archieve.apache.org/dist/drill/drill-1.12.0/apache-drill-1.12.tar.gztar -xvf apache-drill-1.12.tar.gzbin/drillbit.sh start -Ddrill.exec.port=8765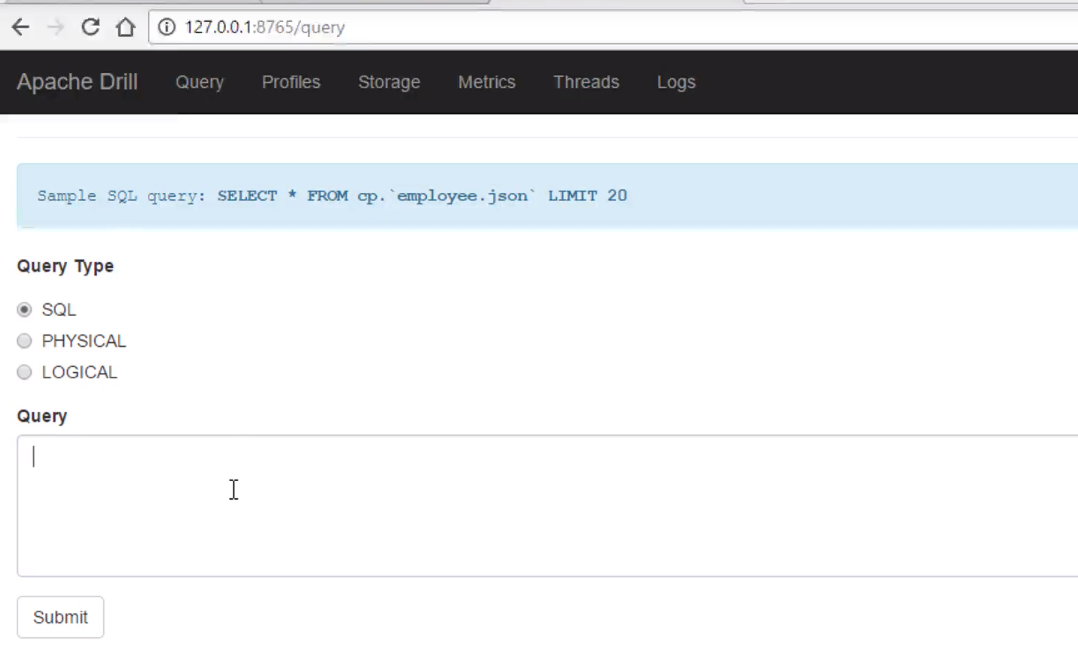
-
bin/drillbit.sh stop
-
Apache Phoenix
- A SQL driver for HBase that supports transactions
- Fast, low-latency - OLTP support
- Originally developed by Salesforce, the open-sourced
- Exposes a JDBC connector for HBase
- Supports secondary indices and user-defined functions
- Integrates with MapReduce, Spark, Hive, Pig and Flume

- Phoenix does not support all of SQL, but it is close
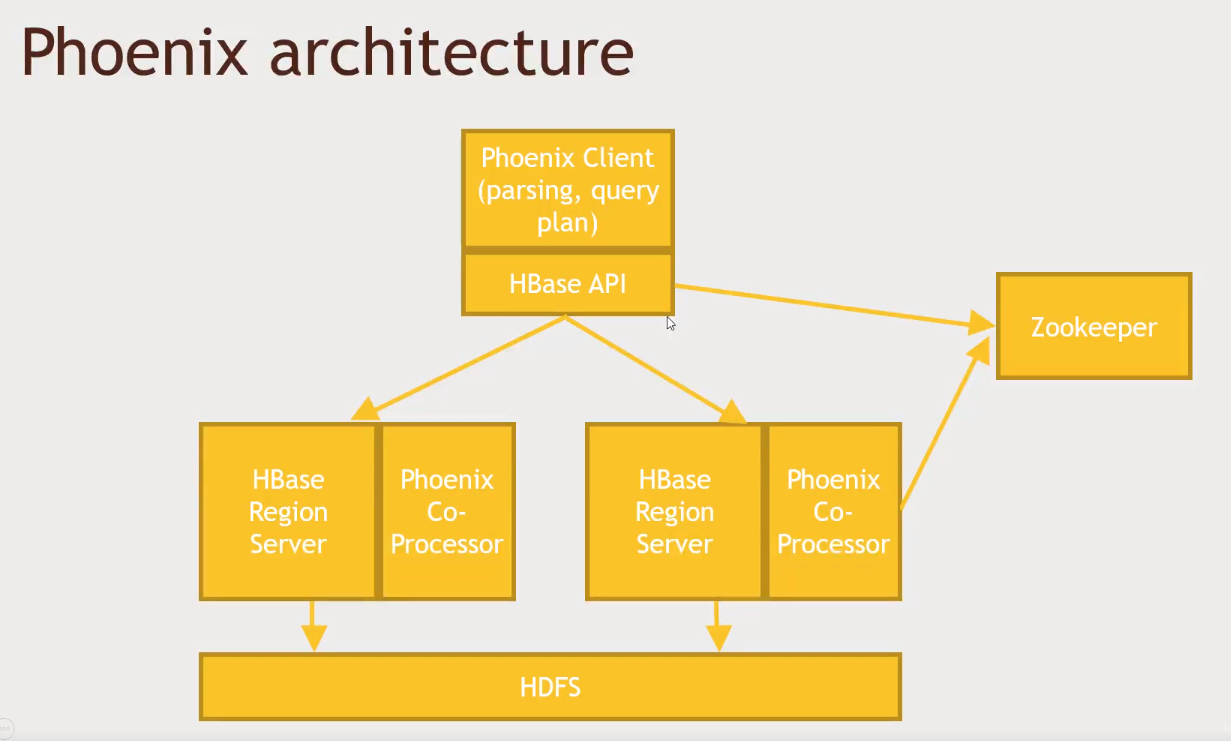

- Run steps:
yum install phoenixcd /usr/hdp/current/phoenix-clientpython sqlline.py!tableslist all tables in HBase
!tablesUPSERT INTO US_POPULATION VALUES ('NY', 'New York', 8143197)create or update rowSELECT * FROM US_POPULATION;DROP TABLE US_POPULATION;!quit
-
Presto
- Distributing queries across different data stores

- Great for OLAP - analytical queries, data warehousing

- Run steps:
wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.216/presto-server-0.216.tar.gztar -xvf presto-server-0.216.tar.gzcd presto-server-0.216wget http://media.sundog-soft.com/hadoop/presto-hdp-config.tgztar -xvf presto-hdp-config.tgz- Inside
etcwe have the config files
- Inside
cd binwget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.216/presto-cli-0.216-executable.jarmv presto-cli-0.216-executable.jar prestochmod +x prestocd ..bin/launcher startAccess 127.0.0.1:8090bin/presto --server 127.0.0.1:8090 --catalog hiveConnecting to Hiveshow tables from defaultselect * from default.ratings limit 10select * from default.ratings where rating = 5 limit 10bin/launcher stop









-
YARN (Yet Another Resource Negotiator)

- MapReduce, Spark and Tez are build on top of YARN
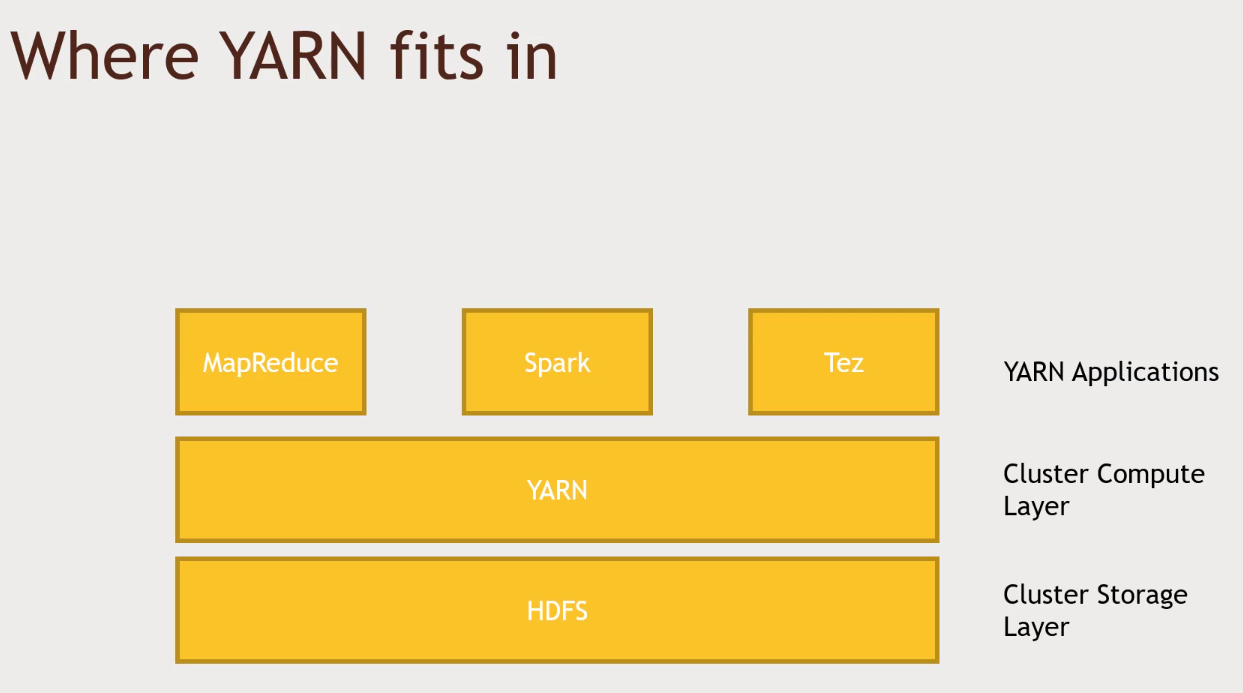
- YARN is about splitting the entire computation all over your cluster. On the other hand, HDFS is about splitting the storage between computers.
- YARN tries to maintain data locality (run the process in the same place as your block of data)
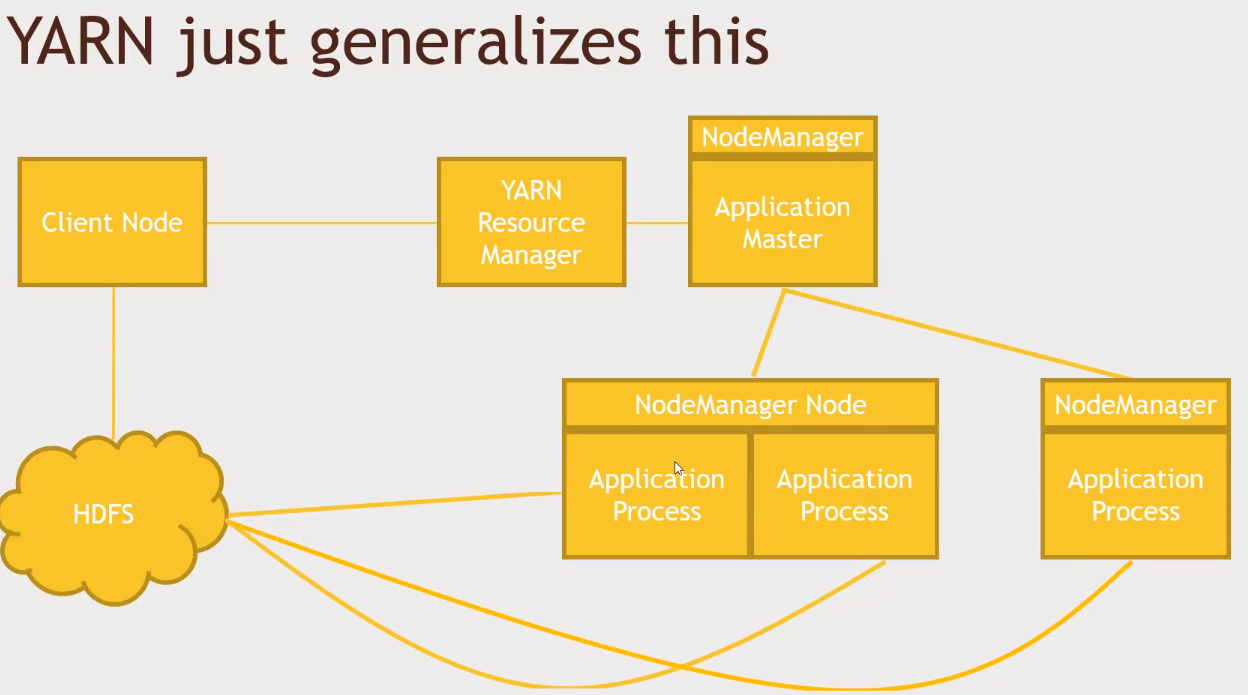
NodeManagertalks to YARN in order to get more resources. Other nodes will run the Application Process (MapReduce for example)YARNwill assign aNodeManager, thisNodeManagerwill request otherNodesin order to process the task. This framework provided byYARNalso guarantees that the process will be in a machine that contains the data.YARNcan be used by MapReduce, Taz and Spark.- CPU cycle + data locality

-
Tez (Yet Another Resource Negotiator)

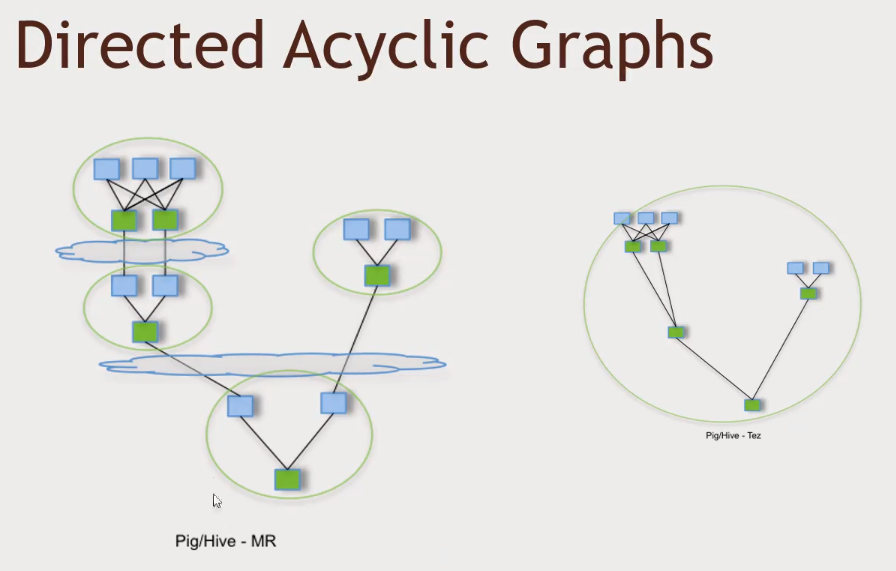
- Skipping steps and not going to the HDFS cloud as often makes the magic.
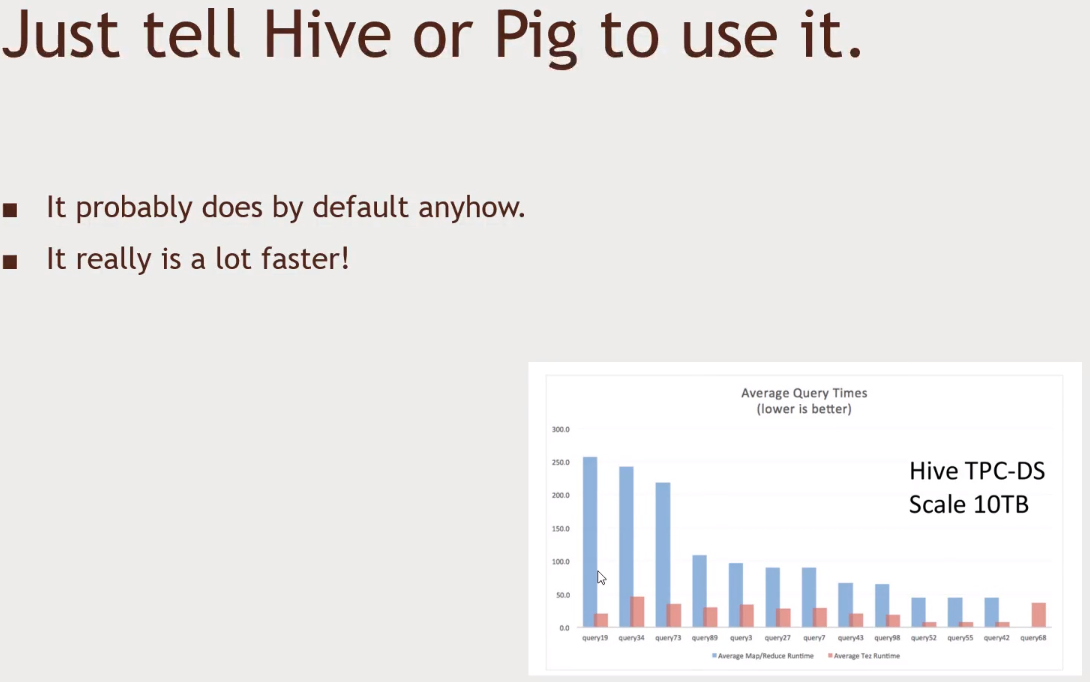
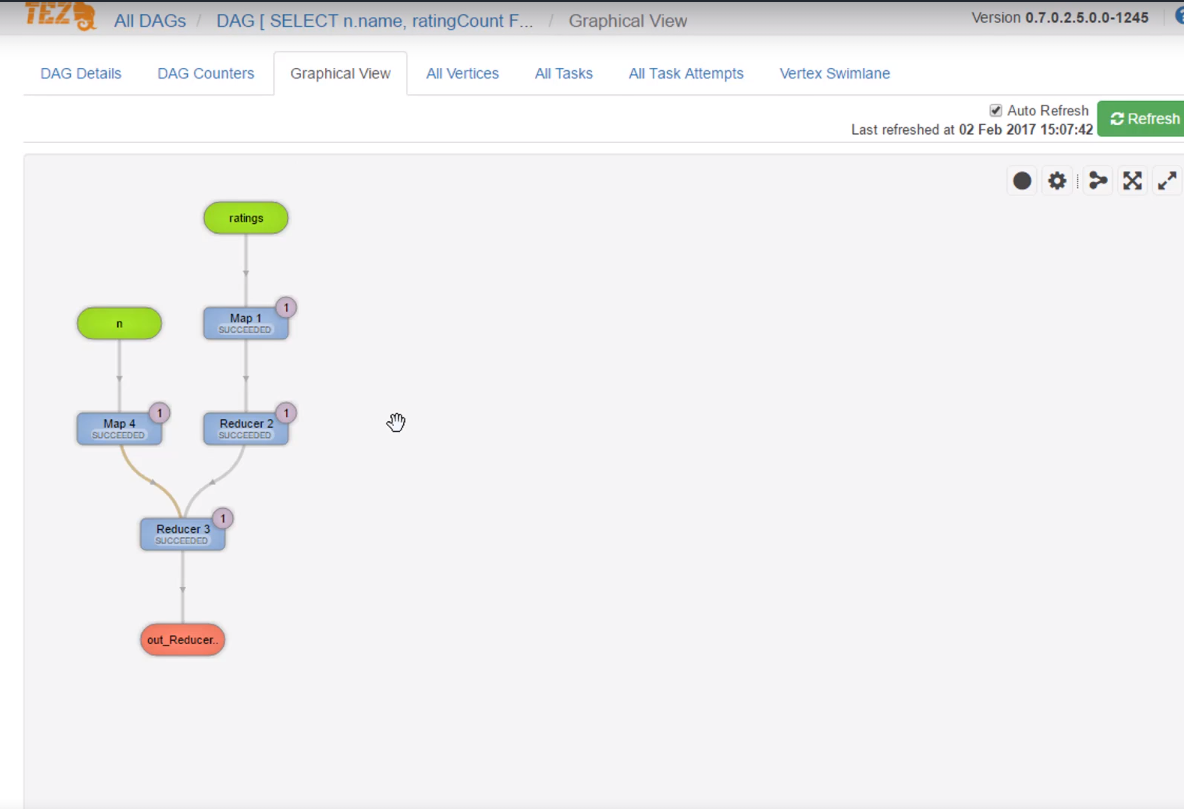
- Compared to pure MapReduce, Tez is 3x faster.
-
Mesos
- Yes, yet another resource negotiator

- Distribute tasks to a computer cluster
- It is more generic than
YARN - Developed by Twitter
- Not strict to Hadoop tasks
- It could spawn web servers and other resources

- Spark was developed to run on top of
Mesos
- Spark was developed to run on top of


-
ZooKeeper





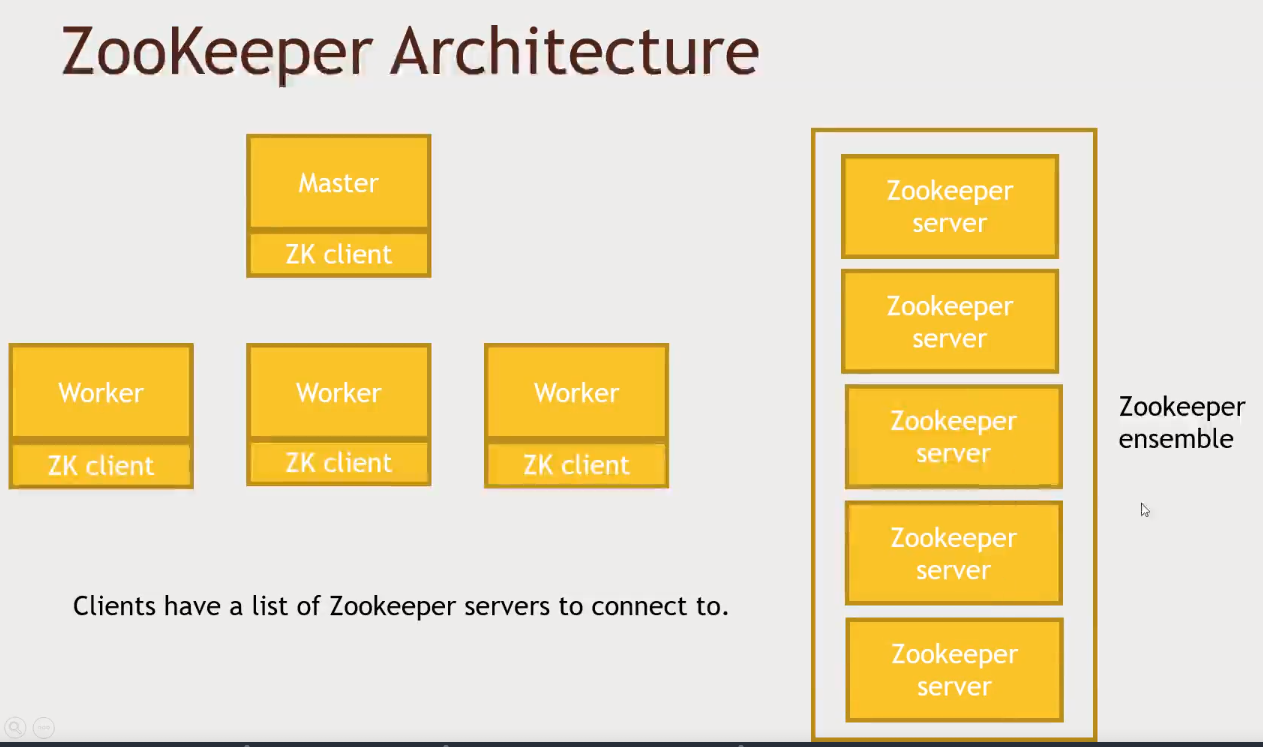
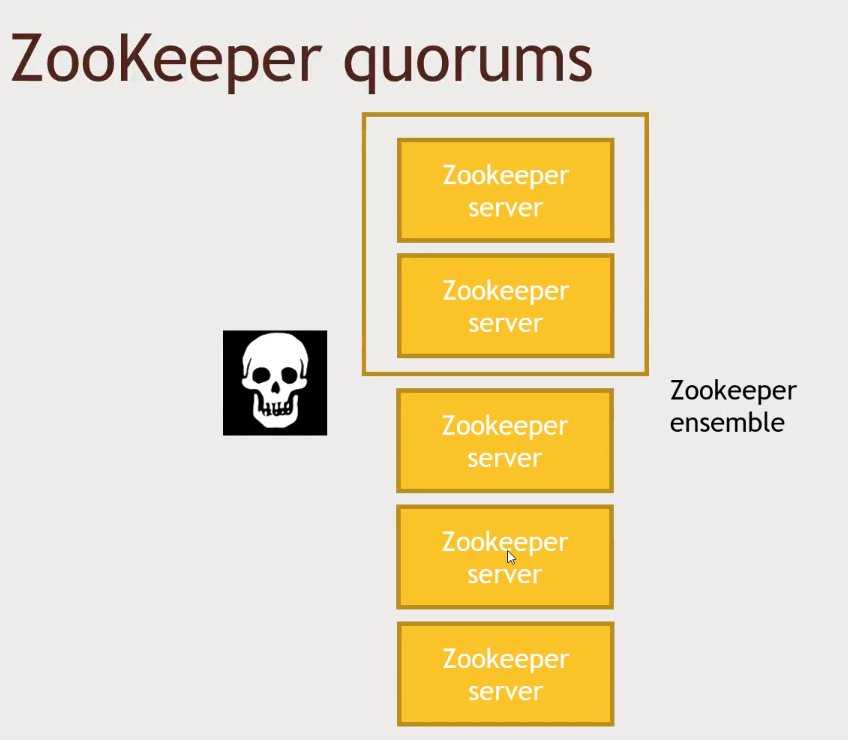
- Various nodes must agree before sharing information to a service (at least 3). That is the way consistency is kept
- Zookeeper has an ephemeral storage by default, that means that if a master client from an application (lets say HBase) goes down, his
znode/filewon't show anymore inside Zookeeper.- That way, a client node will be notified about it and then elect him-self to be the master, and Zookeeper will make sure that only one client node will be able to write to the "HBase master"
znodefile.
- That way, a client node will be notified about it and then elect him-self to be the master, and Zookeeper will make sure that only one client node will be able to write to the "HBase master"

-
OOZIE
- Orchestrating your Hadoop jobs

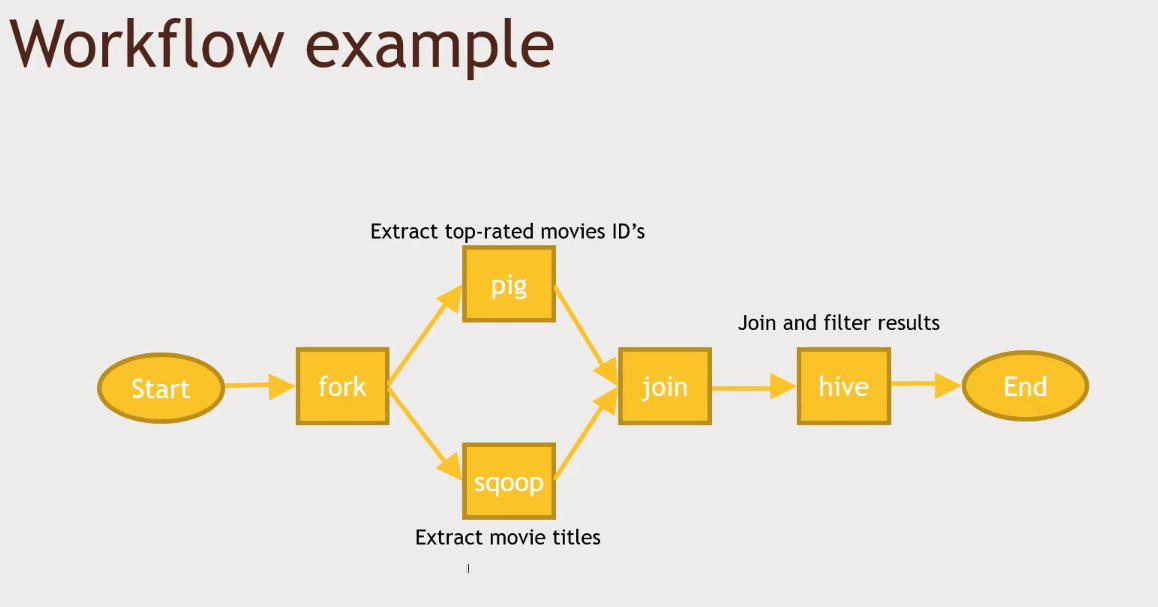
- Works with the idea of nodes (a node will do some task)
- fork node, task nodes and join node, etc..

- No fancy editor



- Used to kick off a job within a time frame
- A bundle is a collection of coordinators
- By grouping them in a bundle, you could suspend them all if there were a problem with log collection
-
Apache Zeppelin
- A notebook interface to yout Big Data
- Similar to iPython notebook and Jupiter Notebook
- Lets you interactively run scripts / code against your data
- Can interleave with nicely formatted notes
- Can share notebooks with others on your cluster


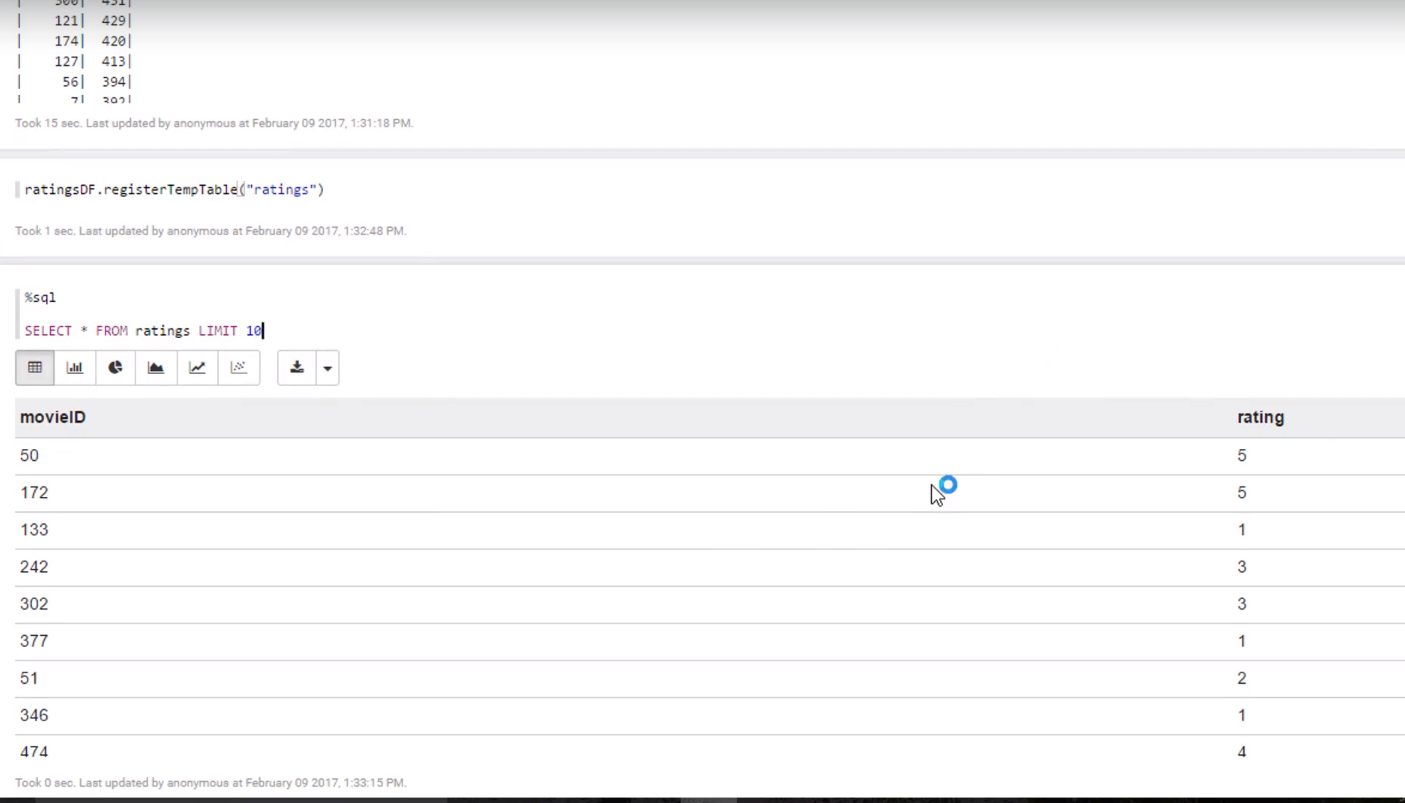
- SparkSQL in action
-
Hue
- Clouderas Ambari

- Hortonworks is an 100% open source solution, cloudera injects some products of its own
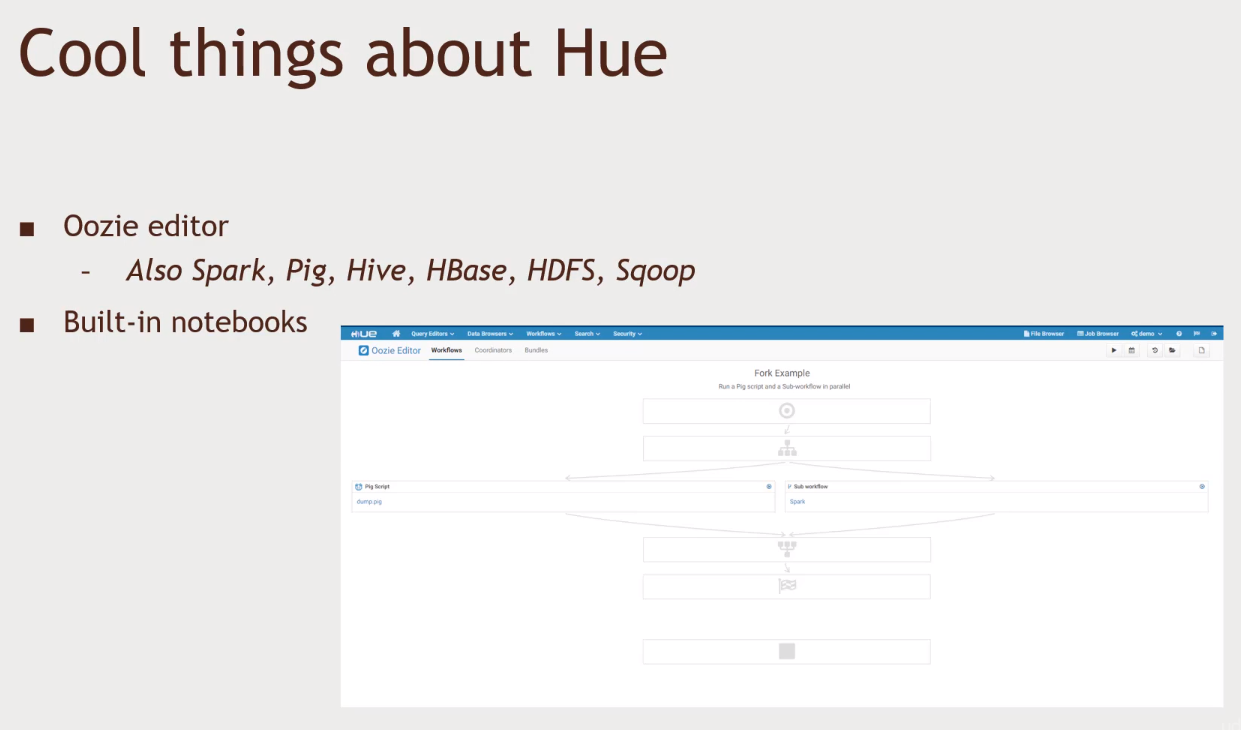
- Has a nice ozzie editor
-
Legacy technologies
- Ganglia
- Distributed monitoring system
- It is dead (2008)
- Chukwa
- Collecting and analyzing logs
- People use Flume or Kafka now a days
- It is dead (2010)
- Collecting and analyzing logs
- Ganglia
































-
What is streaming?
-
Kafka
- Publish/Subscribe Messaging with Kafka

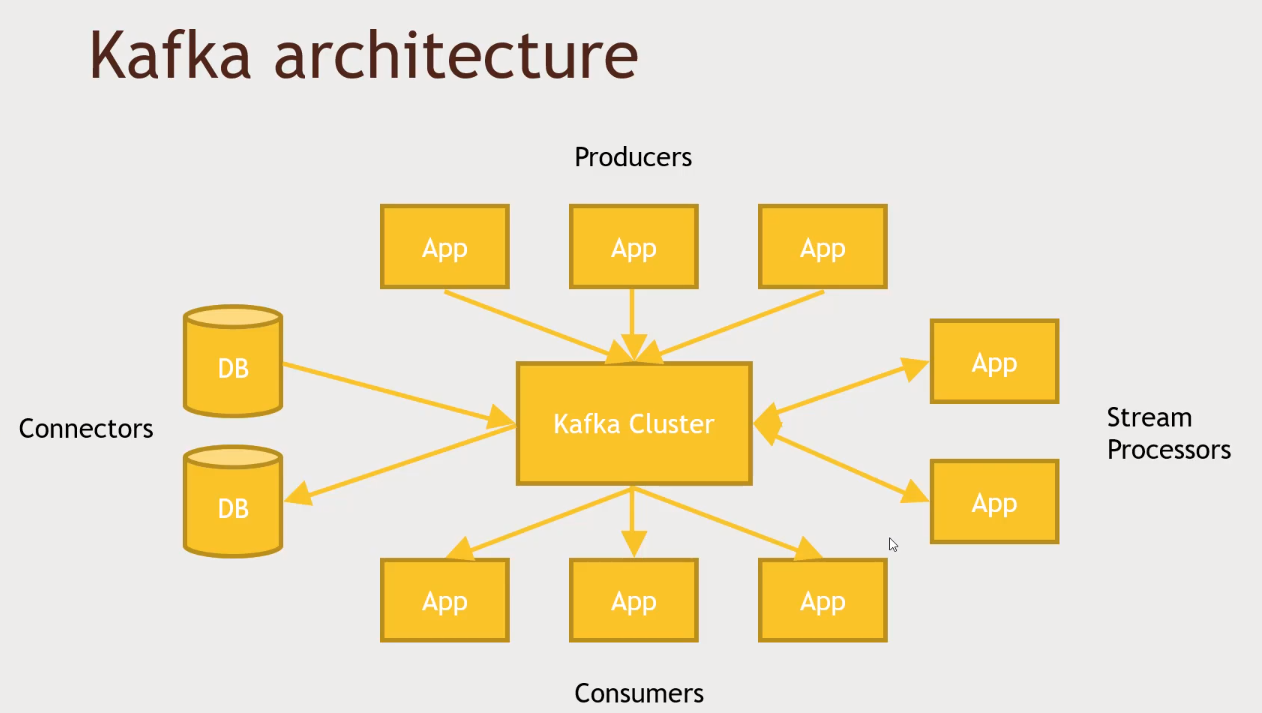
- Stream processors example: It will watch for a kafka topic, get log data and extract what you really want from it, and republish that to a new topic in Kafka
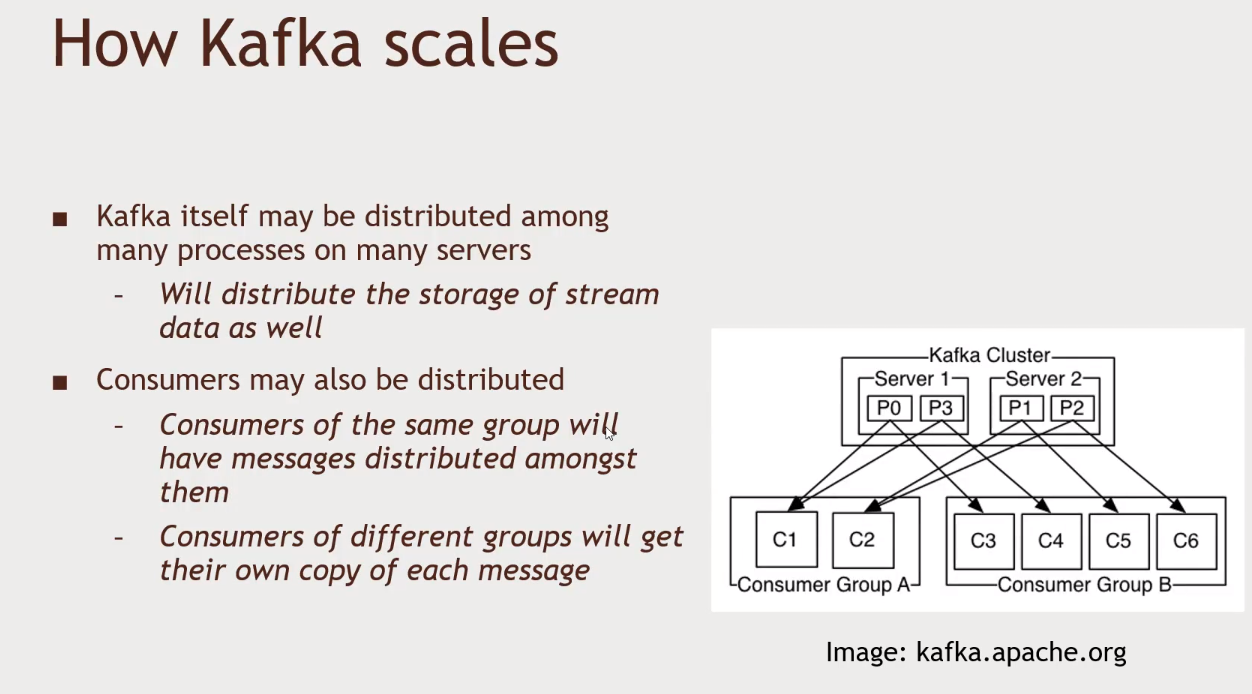
-
Flume
- Another way to stream data into your cluser
- Build with Hadoop in mind
- Originally made to handle log aggreagation
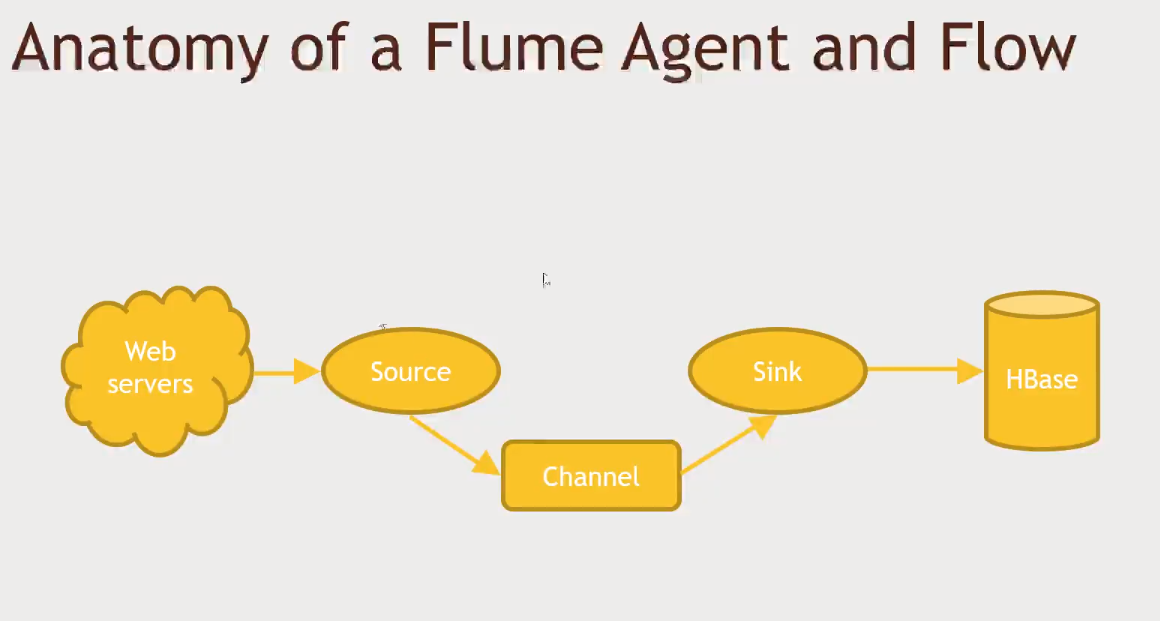

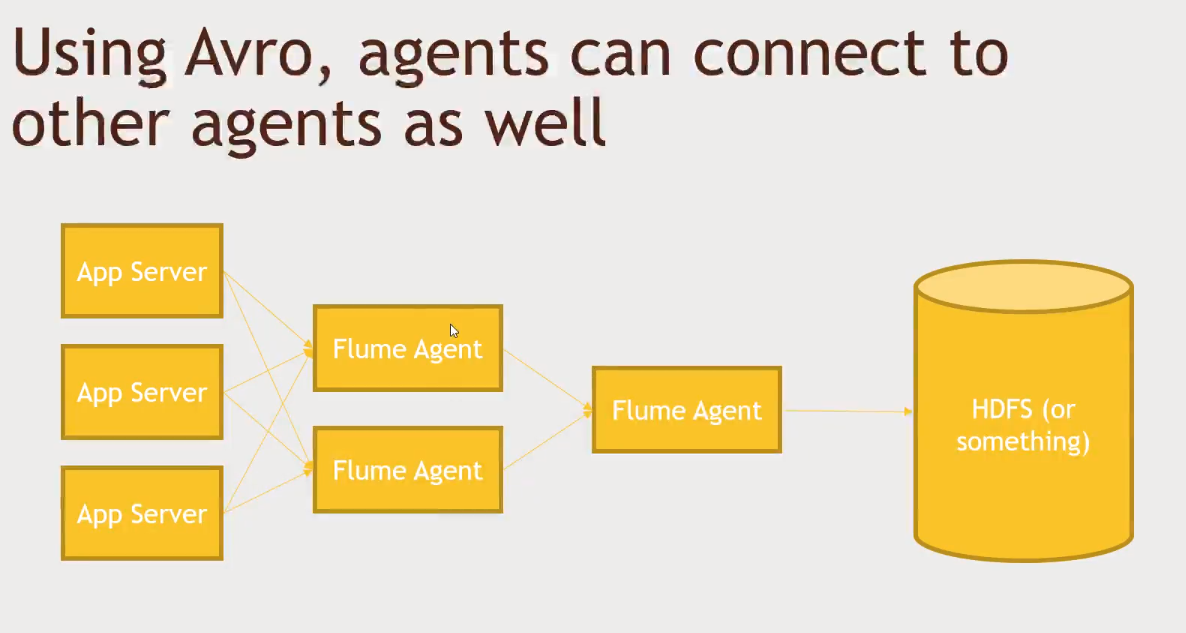
- An agente may watch for changes on a file log in a web server (source)
- Flume will delete the message as soon as it is processed by the channel (kafka wont do that)
- The channel will pipe information from the source to the sink (memory or file)












-
"Big data" never stops!
-
Analyze data streams in real time, instead of in huge batch jobs daily
-
Analyzing streams of web log data to react to user behavior
-
Analyze streams of real-time sensor data for "Internet of Things" stuff
-
Spark Stream
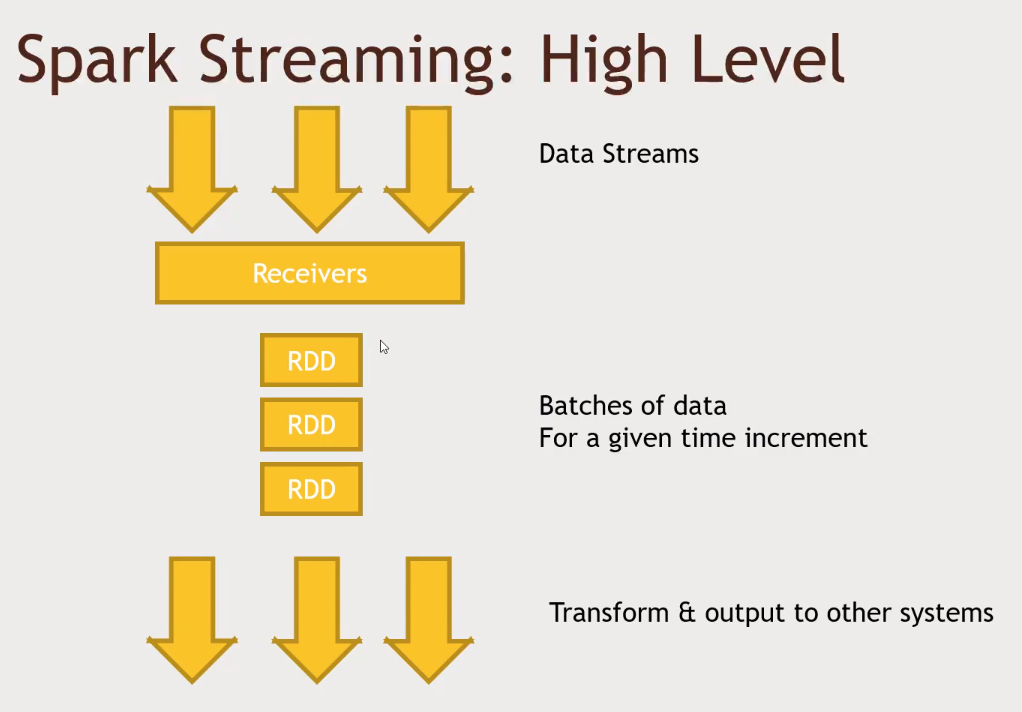
- Will receive that from Kafka and other sources.
Receiverswill create RDD based on some discretize time frame of data (2s of data for example)- Micro batches
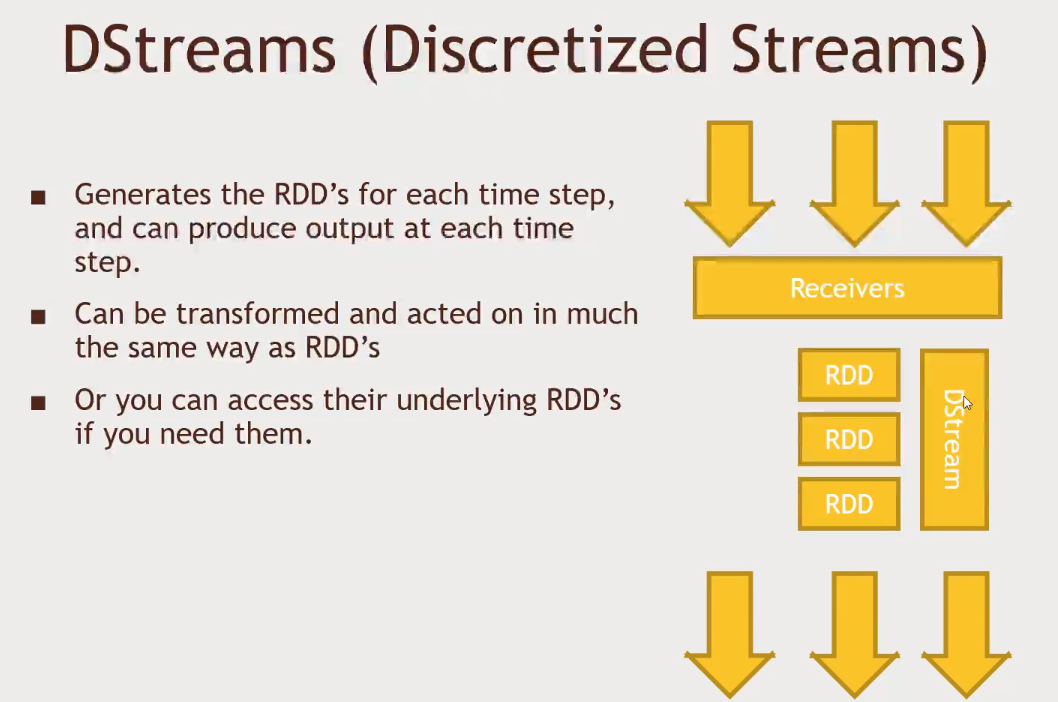





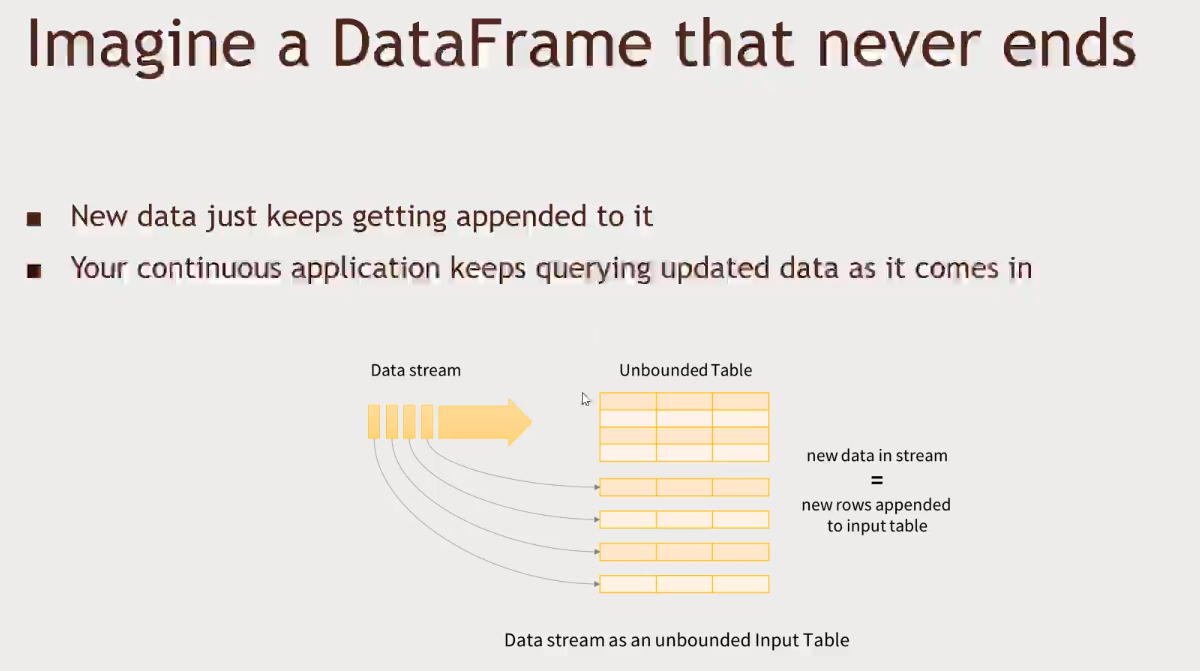

-
Apache Storm
- Another framwework for processing continuos streams of data on a cluster
- Can run on top of YARN
- Works on individual events, not micro-batches (like Spark Streaming does)
- If you need sub-second latency, Storm is for you
- More real time, no batch intervals
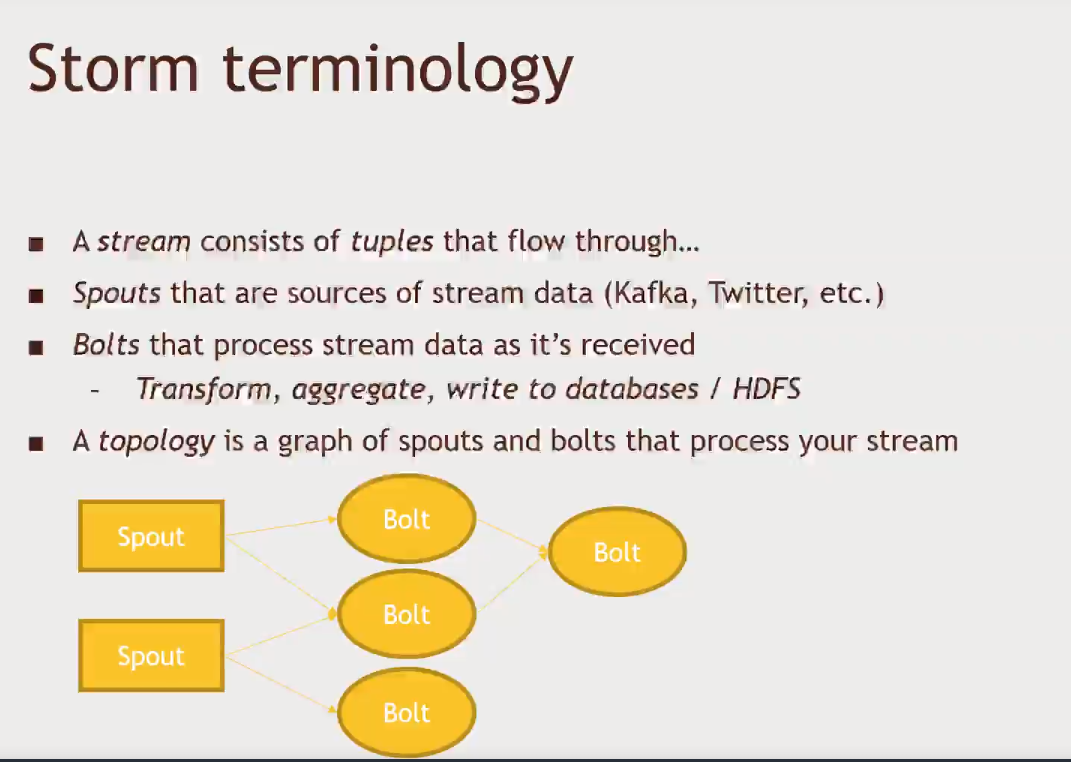

- Another framwework for processing continuos streams of data on a cluster
-
Flink


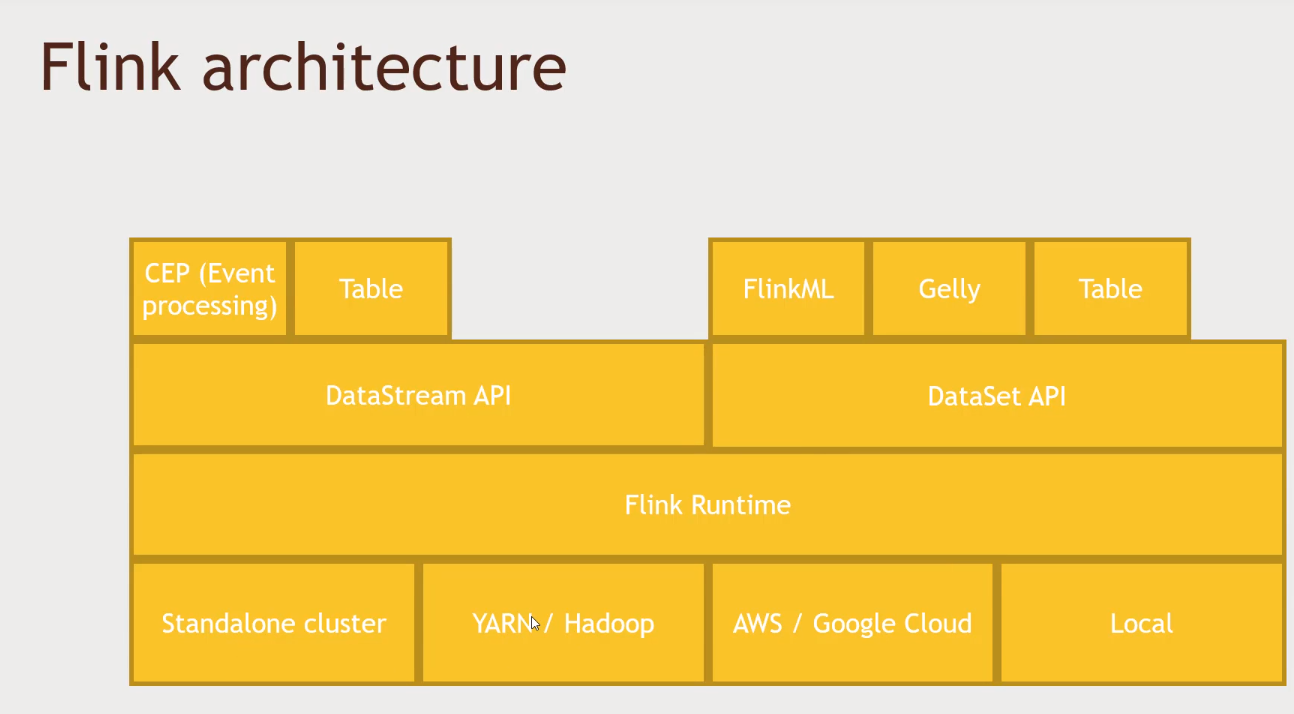
- Can work with stream and batch data














-
ImpalaClouderas alternative to Hive -
Accumulois HBase with better security- Cell-based access control
-
Redisa distributed in-memory data store (like memcache) -
Igniteis an option toRedis- Close to a real database (ACID, SQL support, but all in-memory)
-
Elasticsearchdistributed document search and analytics engine -
Kinesis- AWS version of Kafka
- DynamoDB is like Cassandra
- Elastic MapReduce (EMR)