
CycleGAN and pix2pix in PyTorch
This is our ongoing PyTorch implementation for both unpaired and paired image-to-image translation.
The code was written by Jun-Yan Zhu and Taesung Park.
Check out the original CycleGAN Torch and pix2pix Torch code if you would like to reproduce the exact same results as in the papers.
CycleGAN: [Project] [Paper] [Torch]

Pix2pix: [Project] [Paper] [Torch]
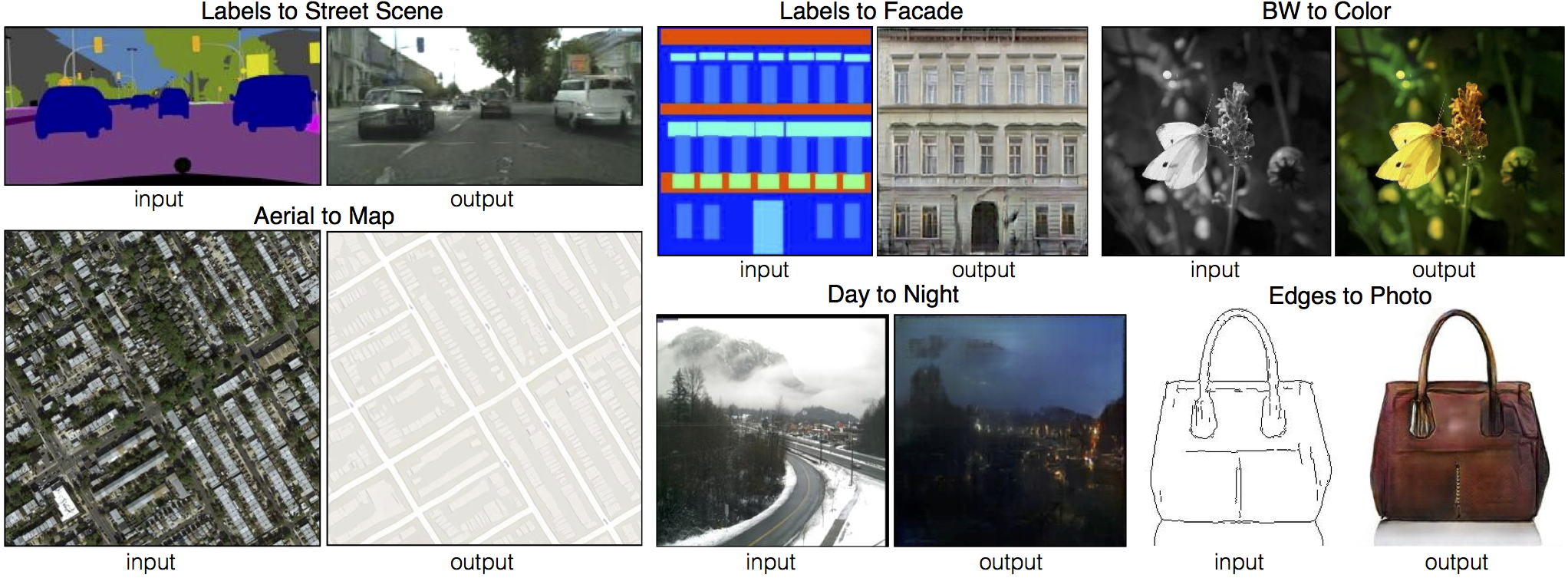
[EdgesCats Demo] [pix2pix-tensorflow]
Written by Christopher Hesse

If you use this code for your research, please cite:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu*, Taesung Park*, Phillip Isola, Alexei A. Efros
In arxiv, 2017. (* equal contributions)
Image-to-Image Translation with Conditional Adversarial Networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
In CVPR 2017.
Prerequisites
- Linux or OSX.
- Python 2 or Python 3.
- CPU or NVIDIA GPU + CUDA CuDNN.
Getting Started
Installation
- Install PyTorch and dependencies from http://pytorch.org/
- Install python libraries visdom and dominate.
pip install visdom
pip install dominate- Clone this repo:
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
cd pytorch-CycleGAN-and-pix2pixCycleGAN train/test
- Download a CycleGAN dataset (e.g. maps):
bash ./datasets/download_cyclegan_dataset.sh maps- Train a model:
#!./scripts/train_cyclegan.sh
python train.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan- To view training results and loss plots, run
python -m visdom.serverand click the URL http://localhost:8097. To see more intermediate results, check out./checkpoints/maps_cyclegan/web/index.html - Test the model:
#!./scripts/test_cyclegan.sh
python test.py --dataroot ./datasets/maps --name maps_cyclegan --model cycle_gan --phase testThe test results will be saved to a html file here: ./results/maps_cyclegan/latest_test/index.html.
pix2pix train/test
- Download a pix2pix dataset (e.g.facades):
bash ./datasets/download_pix2pix_dataset.sh facades- Train a model:
#!./scripts/train_pix2pix.sh
python train.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --which_model_netG unet_256 --which_direction BtoA --lambda_A 100 --align_data --use_dropout --no_lsgan- To view training results and loss plots, run
python -m visdom.serverand click the URL http://localhost:8097. To see more intermediate results, check out./checkpoints/facades_pix2pix/web/index.html - Test the model (
bash ./scripts/test_pix2pix.sh):
#!./scripts/test_pix2pix.sh
python test.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --which_model_netG unet_256 --which_direction BtoA --align_dataThe test results will be saved to a html file here: ./results/facades_pix2pix/latest_val/index.html.
More example scripts can be found at scripts directory.
Training/test Details
- See
options/train_options.pyandoptions/base_options.pyfor training flags; seeoptions/test_options.pyandoptions/base_options.pyfor test flags. - CPU/GPU (default
--gpu_ids 0): Set--gpu_ids -1to use CPU mode; set--gpu_ids 0,1,2for multi-GPU mode. You need a large batch size (e.g.--batchSize 32) to benefit from multiple gpus. - During training, the current results can be viewed using two methods. First, if you set
--display_id> 0, the results and loss plot will be shown on a local graphics web server launched by visdom. To do this, you should have visdom installed and a server running by the commandpython -m visdom.server. The default server URL ishttp://localhost:8097.display_idcorresponds to the window ID that is displayed on thevisdomserver. Thevisdomdisplay functionality is turned on by default. To avoid the extra overhead of communicating withvisdomset--display_id 0. Second, the intermediate results are saved to[opt.checkpoints_dir]/[opt.name]/web/as an HTML file. To avoid this, set--no_html.
CycleGAN Datasets
Download the CycleGAN datasets using the following script. Some of the datasets are collected by other researchers. Please cite their papers if you use the data.
bash ./datasets/download_cyclegan_dataset.sh dataset_namefacades: 400 images from the CMP Facades dataset. [Citation]cityscapes: 2975 images from the Cityscapes training set. [Citation]maps: 1096 training images scraped from Google Maps.horse2zebra: 939 horse images and 1177 zebra images downloaded from ImageNet using keywordswild horseandzebraapple2orange: 996 apple images and 1020 orange images downloaded from ImageNet using keywordsappleandnavel orange.summer2winter_yosemite: 1273 summer Yosemite images and 854 winter Yosemite images were downloaded using Flickr API. See more details in our paper.monet2photo,vangogh2photo,ukiyoe2photo,cezanne2photo: The art images were downloaded from Wikiart. The real photos are downloaded from Flickr using the combination of the tags landscape and landscapephotography. The training set size of each class is Monet:1074, Cezanne:584, Van Gogh:401, Ukiyo-e:1433, Photographs:6853.iphone2dslr_flower: both classes of images were downlaoded from Flickr. The training set size of each class is iPhone:1813, DSLR:3316. See more details in our paper.
To train a model on your own datasets, you need to create a data folder with two subdirectories trainA and trainB that contain images from domain A and B. You can test your model on your training set by setting phase='train' in test.lua. You can also create subdirectories testA and testB if you have test data.
You should not expect our method to work on just any random combination of input and output datasets (e.g. cats<->keyboards). From our experiments, we find it works better if two datasets share similar visual content. For example, landscape painting<->landscape photographs works much better than portrait painting <-> landscape photographs. zebras<->horses achieves compelling results while cats<->dogs completely fails.
pix2pix datasets
Download the pix2pix datasets using the following script. Some of the datasets are collected by other researchers. Please cite their papers if you use the data.
bash ./datasets/download_pix2pix_dataset.sh dataset_namefacades: 400 images from CMP Facades dataset. [Citation]cityscapes: 2975 images from the Cityscapes training set. [Citation]maps: 1096 training images scraped from Google Mapsedges2shoes: 50k training images from UT Zappos50K dataset. Edges are computed by HED edge detector + post-processing. [Citation]edges2handbags: 137K Amazon Handbag images from iGAN project. Edges are computed by HED edge detector + post-processing. [Citation]
We provide a python script to generate pix2pix training data in the form of pairs of images {A,B}, where A and B are two different depictions of the same underlying scene. For example, these might be pairs {label map, photo} or {bw image, color image}. Then we can learn to translate A to B or B to A:
Create folder /path/to/data with subfolders A and B. A and B should each have their own subfolders train, val, test, etc. In /path/to/data/A/train, put training images in style A. In /path/to/data/B/train, put the corresponding images in style B. Repeat same for other data splits (val, test, etc).
Corresponding images in a pair {A,B} must be the same size and have the same filename, e.g., /path/to/data/A/train/1.jpg is considered to correspond to /path/to/data/B/train/1.jpg.
Once the data is formatted this way, call:
python datasets/combine_A_and_B.py --fold_A /path/to/data/A --fold_B /path/to/data/B --fold_AB /path/to/dataThis will combine each pair of images (A,B) into a single image file, ready for training.
TODO
- add reflection and other padding layers.
- add more preprocessing options.
Related Projects:
CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
pix2pix: Image-to-image translation with conditional adversarial nets
iGAN: Interactive Image Generation via Generative Adversarial Networks
Cat Paper Collection
If you love cats, and love reading cool graphics, vision, and learning papers, please check out the Cat Paper Collection:
[Github] [Webpage]
Acknowledgments
Code is inspired by pytorch-DCGAN.