
Learning Joint Spatial-Temporal Transformations for Video Inpainting
Yanhong Zeng, Jianlong Fu, and Hongyang Chao.
In ECCV 2020.
If any part of our paper and repository is helpful to your work, please generously cite with:
@inproceedings{yan2020sttn,
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang,
title = {Learning Joint Spatial-Temporal Transformations for Video Inpainting},
booktitle = {The Proceedings of the European Conference on Computer Vision (ECCV)},
year = {2020}
}
High-quality video inpainting that completes missing regions in video frames is a promising yet challenging task.
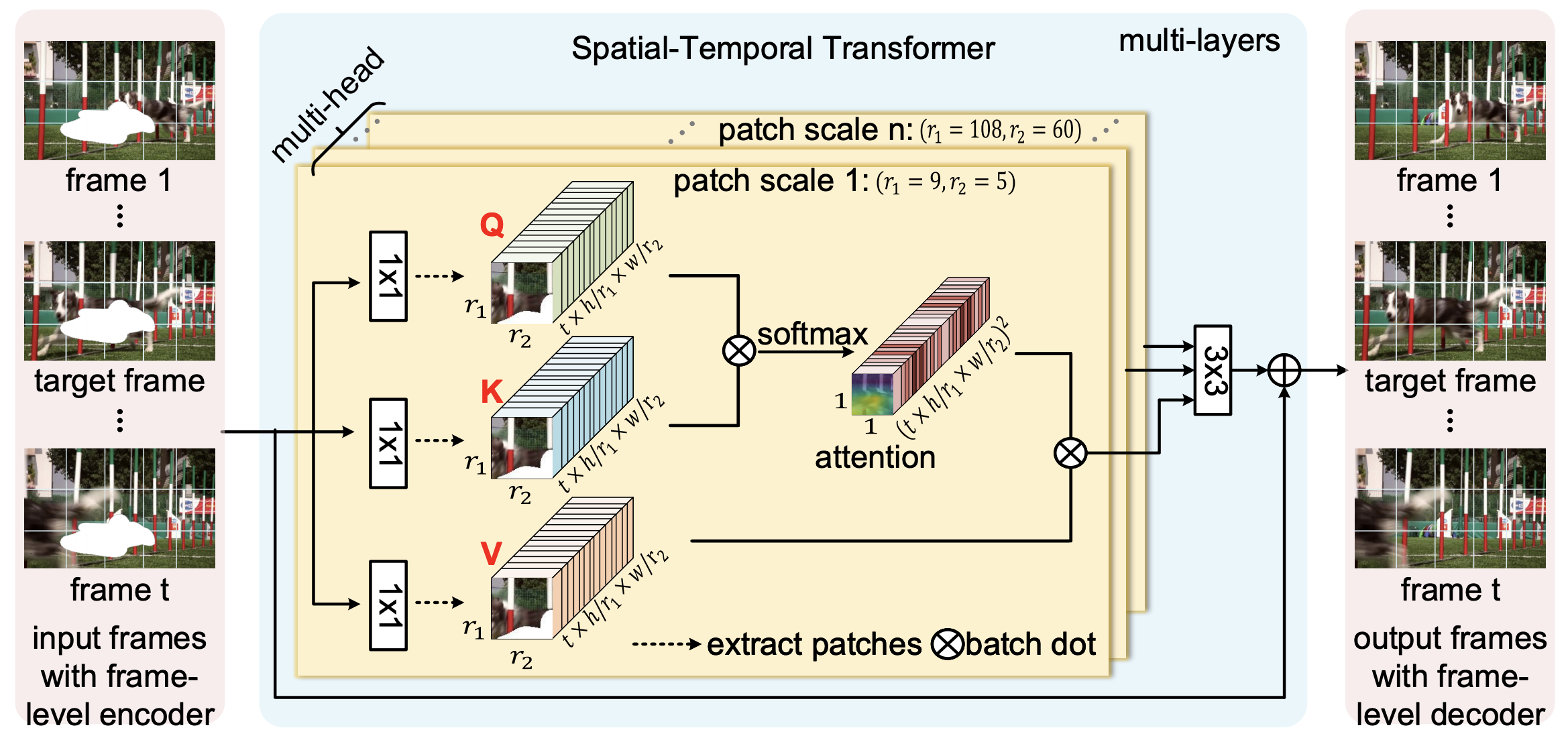
In this paper, we propose to learn a joint Spatial-Temporal Transformer Network (STTN) for video inpainting. Specifically, we simultaneously fill missing regions in all input frames by the proposed multi-scale patch-based attention modules. STTN is optimized by a spatial-temporal adversarial loss.
To show the superiority of the proposed model, we conduct both quantitative and qualitative evaluations by using standard stationary masks and more realistic moving object masks.
Clone this repo.
git clone git@github.com:researchmm/STTN.git
cd STTN/
We build our project based on Pytorch and Python. For the full set of required Python packages, we suggest create a Conda environment from the provided YAML, e.g.
conda env create -f environment.yml
conda activate sttn
The result videos can be generated using pretrained models. For your reference, we provide a model pretrained on Youtube-VOS(Google Drive Folder).
-
Download the pretrained models from the Google Drive Folder, save it in
checkpoints/. -
Complete videos using the pretrained model. For example,
python test.py --video examples/schoolgirls_orig.mp4 --mask examples/schoolgirls --ckpt checkpoints/sttn.pth
The outputs videos are saved at examples/.
We provide dataset split in datasets/.
Preparing Youtube-VOS (2018) Dataset. The dataset can be downloaded from here. In particular, we follow the standard train/validation/test split (3,471/474/508). The dataset should be arranged in the same directory structure as
datasets
|- youtube-vos
|- JPEGImages
|- <video_id>.zip
|- <video_id>.zip
|- test.json
|- train.json
Preparing DAVIS (2018) Dataset. The dataset can be downloaded from here. In particular, there are 90 videos with densely-annotated object masks and 60 videos without annotations. The dataset should be arranged in the same directory structure as
datasets
|- davis
|- JPEGImages
|- cows.zip
|- goat.zip
|- Annoatations
|- cows.zip
|- goat.zip
|- test.json
|- train.json
Once the dataset is ready, new models can be trained with the following commands. For example,
python train.py --config configs/youtube-vos.json --model sttn
Testing is similar to Completing Videos Using Pretrained Model.
python test.py --video examples/schoolgirls_orig.mp4 --mask examples/schoolgirls --ckpt checkpoints/sttn.pth
The outputs videos are saved at examples/.
We provide an example of visualization attention maps in visualization.ipynb.
We provide traning monitoring on losses by running:
tensorboard --logdir release_mode
If you have any questions or suggestions about this paper, feel free to contact me (zengyh7@mail2.sysu.edu.cn).