This repository contains the code used to produce the results in the papers Automated Segmentation of Multiple Sclerosis Lesions using Multi-Dimensional Gated Recurrent Units and Multi-dimensional Gated Recurrent Units for Automated Anatomical Landmark Localization. It was used to reach 1st place in the ISBI 2015 longitudinal lesion segmentation challenge, 2nd place in the white matter hyperintensities challenge of MICCAI 2017 and its previous implementation in CAFFE made 3rd place in the MrBrainS13 Segmentation challenge. We also competed in BraTS 2017, where the information on the exact rank are still unknown. This release is implemented using the tensorflow framework. The CAFFE code is not maintained anymore (there are probably breaking changes in CuDNN, not tested), but a snapshot of it is included in this release in the folder tensorflow_extra_ops as additional operation for tensorflow. Since being published, the code has been improved on quite a bit, especially to facilitate handling training and testing runs. The reported results should still be reproducible though using this implementation.
The file RUN_mdgru.py is used for basically all segmentation tasks. For now, please refer to it's help message by calling python3 RUN_mdgru.py and the documentation in the code.
As the RUN_mdgru.py file contains a overly large number of parameters, a sample train+test, individual train, and individual test run are detailed in the following:
First, the data have to be prepared and have to have a certain format: Each sample should be contained in one folder, with the label and feature (e.g. different Sequences) files consistently named after a certain scheme. Furthermore, all the samples belonging to test, train and validation set should be located in respective folders. The following shows an example, where we have training, testing and validation folders train_data, test_data and val_data respectively, containing each some samples. Each sample consists of two featurefiles (seq1.nii.gz and seq2.nii.gz) and one labelfile (lab.nii.gz), as shown in the following example:
path/to/samplestructure
├── test_data
│ ├── SAMPLE_27535
│ │ ├── lab.nii.gz
│ │ ├── seq1.nii.gz
│ │ └── seq2.nii.gz
│ └── SAMPLE_6971
│ ├── lab.nii.gz
│ ├── seq1.nii.gz
│ └── seq2.nii.gz
├── train_data
│ ├── SAMPLE_11571
│ │ ├── lab.nii.gz
│ │ ├── seq1.nii.gz
│ │ └── seq2.nii.gz
│ ├── SAMPLE_13289
│ │ ├── lab.nii.gz
│ │ ├── seq1.nii.gz
│ │ └── seq2.nii.gz
│ ├── SAMPLE_16158
│ │ ├── lab.nii.gz
│ │ ├── seq1.nii.gz
│ │ └── seq2.nii.gz
│ ├── SAMPLE_18429
│ │ ├── lab.nii.gz
│ │ ├── seq1.nii.gz
│ │ └── seq2.nii.gz
│ ├── SAMPLE_19438
│ │ ├── lab.nii.gz
│ │ ├── seq1.nii.gz
│ │ └── seq2.nii.gz
│ └── SAMPLE_2458
│ ├── lab.nii.gz
│ ├── seq1.nii.gz
│ └── seq2.nii.gz
└── val_data
├── SAMPLE_26639
│ ├── lab.nii.gz
│ ├── seq1.nii.gz
│ └── seq2.nii.gz
└── SAMPLE_27319
├── lab.nii.gz
├── seq1.nii.gz
└── seq2.nii.gz
The Labelfiles need to be consistent with increasing class numbers. Eg. if we model the background, white matter, gray matter and csf for instance, we have 4 classes and hence distribute them to the numbers 0, 1, 2 and 3. Furthermore, the labelfiles should also be encoded as integer files (e.g. nifti uint8), and the feature and label files need to have matching dimensions.
In the following, we show the case, where we train a model on the above data and also immediately evaluate our model on the last training state (rarely a good idea in general) to explain the individual parameters:
python3 RUN_mdgru.py --datapath path/to/samplestructure --locationtraining train_data \
--locationvalidation val_data --locationtesting test_data \
--optionname defaultsettings --modelname mdgrudef48 -w 64 64 64 -p 5 5 5 \
-f seq1.nii.gz seq2.nii.gz -m lab.nii.gz --iterations 100000 \
--nclasses 4 --ignore_nifti_header --num_threads 4
The above first four parameters tell the script, where our different data lie. Furthermore, it will create a folder experiments in "path/to/samplestructure". Inside this experiments folder, a folder for the current setting is created. The name of this folder can be determined with "--optionname". For each individual train/test/train+test run, a folder with logging data is created using the latest timestamp in seconds inside this settings folder. Any log data for the experiment can then in turn be found inside the cache subfolder. (e.g. /path/to/samplestructure/defaultsettings/1524126169/cache). Inside this cache folder, there will be a log file, logging all relevant information to the current run, all validation files will be saved here as well as the checkpoints and tensorboard data.
Expecially for 2d data, and if a large number of samples is available, the whole image can be processed. There, we set the subvolume (patchsize) parameter to the size of the images, and the padding parameters to 0. This has the effect, that we only sample inside the image, with a padding of 0 and hence just take the full image. As current hardware can rarely support the full volume for volumetric data though, a subvolume needs to be specified. Imagine we are using volumetric data with dimensions 256x256x192. Since this will not fit, we decide to sample patches of 64^3, and hence set the subvolume parameter -w to 64 64 64. Furthermore, we decide that we do want to sample a bit outside of the full volume as well, as interesting data is close to the border. we hence set the -p parameter to 5 5 5, allowing for a random sampling of patches of 5 voxels outside along each axis of the full volume. During testing, patches are sampled from a regular grid to fully cover the full volume (or image). There, the p parameter is used to also specify the amount of overlap of the patches. In our example, we would only specify an overlap of 5 voxels along each dimension.
The following image shows the influence of the w and p parameters when sampling images during the training and testing phase:
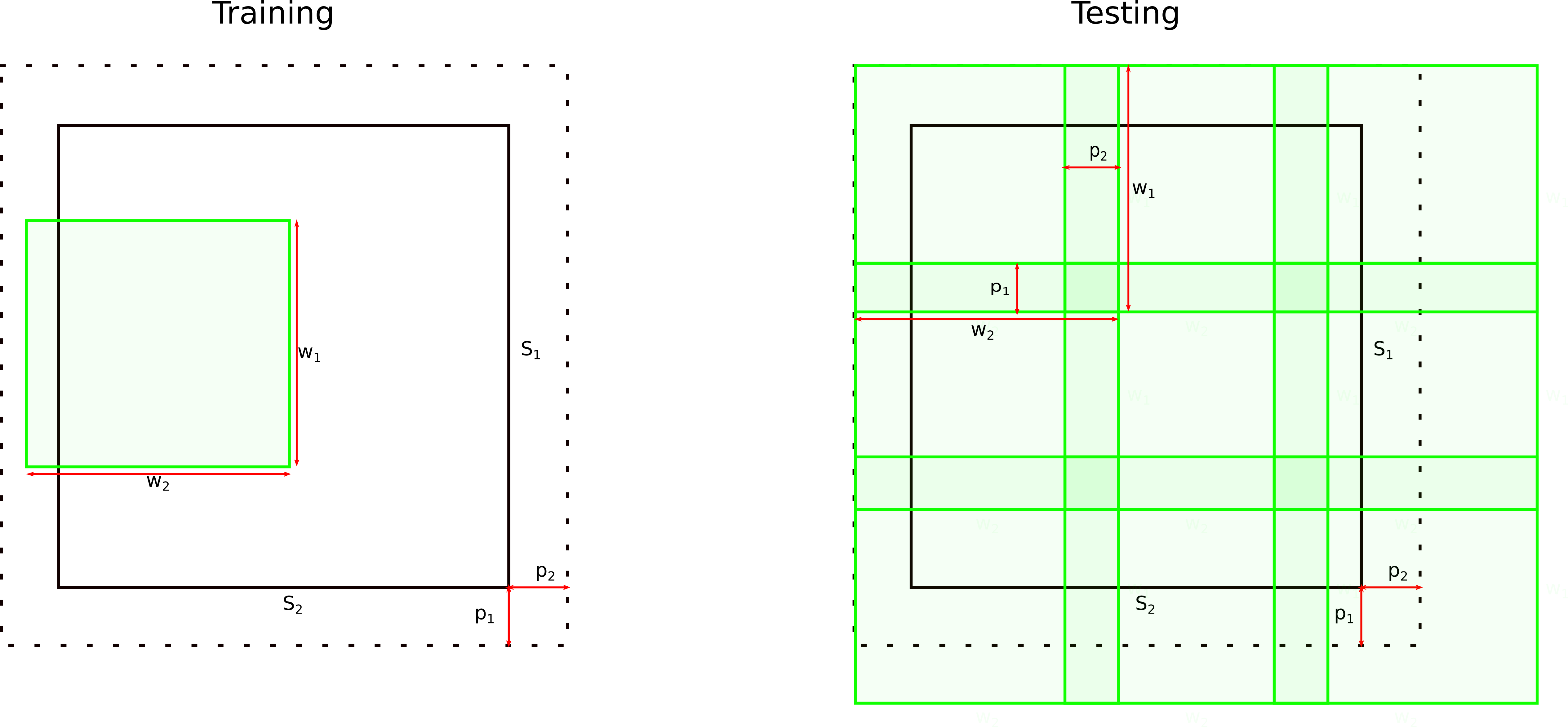
The remaining options given above are the --modelname, which is a optional, userspecified name for the model we are creating in the tensorflow graph. -f and -m specify feature and mask files to be used. --nclasses specifies how many classes are in the label files (e.g. 4 for background, white matter, grey matter and csf). --iterations specifies the maximum number of iterations to train. If we cancel the training process at any time, the current state is saved in a checkpoint called interrupt. Finally, --ignore_nifti_header is required due to a bug in the nifti reorientation code and num_threads is a parameter which defines how many threads should be used to load data concurrently. This can initially be set to a low value such as 4. If during training, in the log file or stdout on the console, values larger than 0.1 seconds are used for "io", it might be advisable to increase this value, as valuable time is wasted on waiting for the data loading routine.
Usually, we want to use the validation set to determine, which state of the network works best for our data and then evaluate our testset on that data. We can do this by using the following command:
python3 RUN_mdgru.py --datapath path/to/samplestructure --locationtraining train_data \
--locationvalidation val_data \
--optionname onlytrainrun --modelname mdgrudef48 -w 64 64 64 -p 5 5 5 \
-f seq1.nii.gz seq2.nii.gz -m lab.nii.gz --iterations 100000 \
--nclasses 4 --ignore_nifti_header --num_threads 4 --onlytrain
In this setup, we can omit the '--locationtesting' and append '--onlytrain' in its place, to specify, that we want to stop the procedure after the training process.
Furthermore, it is in most cases advisable to use a certain amount of data augmentation, since rarely enough labelled training data is available. For this, the following set of parameters can be optionally added for the training procedure:
--rotate ANGLE --scale scale1 scale2... --deformation gridspacing1 gridspacing2... --deformSigma samplingstdev1 samplingstdev2...
The first parameter is a scalar in radians which allows for random rotation around a random vector for 3d data, and around the center point for 2d data between [-ANGLE,+ANGLE] degrees. The parameter is sampled uniformly. The scaling parameter allows for random scaling between [1/scale,scale], where we sample form an exponential distribution and each axis has its own scaling parameter. The last two parameters have to be used together and specify a random deformation grid which is applied to the subvolumes. The first parameters specify the grid spacing, and the second set of parameters the standard deviation of a zero mean Gaussian which is used at each grid point to sample a random vector. This low resolution grid is then interpolated quadratically and used to deform the sampling of the subvolumes or patches.
python3 RUN_mdgru.py --datapath path/to/samplestructure --locationtraining train_data \
--locationtesting test_data\
--optionname defaultsettings --modelname mdgrudef48 -w 64 64 64 -p 5 5 5 \
-f seq1.nii.gz seq2.nii.gz -m lab.nii.gz \
--nclasses 4 --ignore_nifti_header --onlytest --ckpt path/to/samplestructure/experiments/onlytrainrun/1524126169/cache/temp-22500 --notestingmask
Usually, after conducting a training run, it is the best idea to simply copy the training parameters, remove the "onlytest", add the locationtesting and the checkpointfile with "--ckpt". Some other parameters can also be left out as shown above, since they do not have an impact on the testing process. The training process before, when completed, creates at the specified saving interval checkpoint files, which are named temp-$i, where $i is the iteration number, if no epochs are specified or temp-epoch$epoch-$i otherwise. On the file system, the files also have appendices like ".data-00000-of-00001" or ".meta" or ".index", but these can be ignored and should not be specified when specifying a checkpoint. After the whole training procedure, a final checkpoint is created, which saves the final state of the network. If the training process is interrupted, a "interrupt-$i" checkpoint is created, where $i is again the iteration number. All of these three types of checkpoints can be used to evaluate the model. During testing, the optionname also defines the name of the probability maps that are saved in the test_data sample folders as results. If multiple checkpoints are used for evaluation, either none, one or the same number of optionnames can be provided. Finally, --notestingmask has to be used, if for the testing samples, no mask files are available. Otherwise, it will not find testing samples, as it uses the mask file as a requirement for each folder to be accepted as valid sample. If there are labelmaps for the test samples, this flag can be omitted, leading to an automatic evaluation using predefined metrics during the evaluation.
The code for the landmark localization task is also included in this release except for an appropriate RUN-file. Since it would need some code updates due to recent changes in the code, it has not been included. If you're anyhow interested in the localization code, please get in touch, and I could provide you with the (now outdated) RUN-files we used and information on what needs to be updated to make it work again.
Requirements (on ubuntu) can be installed using the following lines of code. On other systems, use the corresponding packages. Make sure to use tensorflow v 1.8.
sudo apt-get install cmake python3-pip curl git python3-dicom
sudo pip3 install --upgrade pip
# either with a gpu, and cuda + cudnn installed:
sudo pip3 install "tensorflow-gpu>=1.8"
# or
sudo pip3 install "tensorflow>=1.8"
sudo pip3 install nibabel numpy scipy matplotlib pynrrd scikit-image scikit-learn
sudo pip3 install git+https://github.com/spezold/mvloader.git
Reference implementation for - and based on - Caffe version:
@inproceedings{andermatt2016multi,
title={Multi-dimensional gated recurrent units for the segmentation of biomedical 3D-data},
author={Andermatt, Simon and Pezold, Simon and Cattin, Philippe},
booktitle={International Workshop on Large-Scale Annotation of Biomedical Data and Expert Label Synthesis},
pages={142--151},
year={2016},
organization={Springer}
}
Code used for:
@inproceedings{andermatt2017a,
title = {{{Automated Segmentation of Multiple Sclerosis Lesions}} using {{Multi-Dimensional Gated Recurrent Units}}},
timestamp = {2017-08-09T07:27:10Z},
journal = {Lecture Notes in Computer Science},
author = {Andermatt, Simon and Pezold, Simon and Cattin, Philippe},
year = {2017},
booktitle={International Workshop on Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries},
note = {{{[accepted]}}},
organization={Springer}
}
@article{andermatt2017b,
title={Multi-dimensional Gated Recurrent Units for Automated Anatomical Landmark Localization},
author={Andermatt, Simon and Pezold, Simon and Amann, Michael and Cattin, Philippe C},
journal={arXiv preprint arXiv:1708.02766},
year={2017}
}
@article{andermatt2017wmh,
title={Multi-dimensional Gated Recurrent Units for the Segmentation of White Matter Hyperintensites},
author={Andermatt, Simon and Pezold, Simon and Cattin, Philippe}
}
@inproceedings{andermatt2017brats,
title = {Multi-dimensional Gated Recurrent Units for
Brain Tumor Segmentation},
author = {Simon Andermatt and Simon Pezold and Philippe C. Cattin},
year = 2017,
booktitle = {2017 International {{MICCAI}} BraTS Challenge}
}
When using this code, please cite at least andermatt2016multi, since it is the foundation of this work. Furthermore, feel free to cite the publication matching your use-case from above. E.g. if you're using the code for pathology segmentation, it would be adequate to cite andermatt2017a as well.
We thank the Medical Image Analysis Center for funding this work.
