定义正则:**
var re = new RegExp('\\d\\(\\)','gi'); //动态创建reg正则的时候,如果是使用特殊字符串的时候必须要用两根\\ 如 \d 要写成 \\d
var re = /\d\(\)/igm; // 简写方法 推荐使用 性能更好 不能为空 不然以为是注释 ,
javascript中正则表达式支持的正则表达式有三个,g、i、m,分别代表全局匹配、忽略大小写、多行模式。三种属性可以自由组合共存。
正则的常用方法 :
** :在字符串中查找符合正则的内容,若查找到返回true,反之返回false.**
用法:正则.test(字符串)
例子:判断是否是数字
var str = '374829348791';
var re = /\D/; // \D代表非数字
if (re.test(str)) { // 返回true,代表在字符串中找到了非数字。
console.log('不全是数字');
} else {
console.log('全是数字');
}
和match方法一样,搜索符合规则的内容,并返回内容,格式为数组。
用法:正则.exec(字符串);
属性:input(代表要匹配的字符串)
栗子:不是全局匹配的情况:
var testStr = "now test001 test002";
var re = /test(\d+)/; //只匹配一次
var r = "";
var r = re.exec(testStr)
console.log(r);// test001 001 返回匹配结果,以及子项
console.log(r.length); //2 返回内容的长度
console.log(r.input); //now test001 test002 代表每次匹配成功的字符串
console.log(r[0]); //test001
console.log(r[1]); //001 代表每次匹配成功字符串中的第一个子项 (\d+)
console.log(r.index ); // 4 每次匹配成功的字符串中的第一个字符的位置
match() 在字符串中搜索复合规则的内容,搜索成功就返回内容,格式为数组,失败就返回null。 用法: 字符串.match(正则), 量词:+ 至少出现一次 匹配不确定的次数(匹配就是搜索查找的意思) 全局匹配:g——global(正则中默认,只要搜索到复合规则的内容就会结束搜索 )
例子:找出指定格式的所有数字,如下找到 123,54,33,879
var str = 'haj123sdk54hask33dkhalsd879';
var re = /\d+/g;
// 每次匹配至少一个数字 且全局匹配 如果不是全局匹配,当找到数字123,它就会停止了。
// 就只会弹出123.加上全局匹配,就会从开始到结束一直去搜索符合规则的。如果没有加号,匹配的结果就是1,2,3,5,4,3,3,8,7,9并不是我们想要的,
// 有了加号,每次匹配的数字就是至少一个了。
console.log( str.match(re) ); // [123,54,33,879]
在 JavaScript 中,正则表达式常用于两个字符串方法:search() 和 replace()和split()方法
search() 方法使用表达式来搜索匹配,然后返回匹配的位置。
replace() 方法返回模式被替换处修改后的字符串。
split()方法返回模式被截取字符串组成数组。
var str = "Visit W3School!";
var n = str.search("W3School"); //返回位置值
var str = "Visit Microsoft!";
var res = str.replace("Microsoft", "W3School"); // 将Microsoft替换成W3School
var res = str.replace(/microsoft/i, "W3School"); // 使用正则替换
var str="how|old*are you";
var arr=str.split(/\||\*|\s+/);
console.log(arr);
每个RegExp对象都包含5个属性,source、global、ignoreCase、multiline、lastIndex。
是一个只读的字符串,包含正则表达式的文本。
var reg = /JavaScript/;
reg.source; //返回 JavaScript
是一个只读的布尔值,看这个正则表达式是否带有修饰符g。
修饰符g,是全局匹配的意思,检索字符串中所有的匹配。
var str = "JavaScript";
str.match(/JavaScript/); //只能匹配一个JavaScript
var str = "JavaScript JavaScript";
str.match(/JavaScript/g); //能匹配两个JavaScript
var reg = /JavaScript/;
reg.global; //返回 false
var reg = /JavaScript/g;
reg.global; //返回 true
是一个只读的布尔值,看这个正则表达式是否带有修饰符i。
修饰符i,说明模式匹配是不区分大小写的。
var reg = /JavaScript/;
reg.ignoreCase; //返回 false
var reg = /JavaScript/i;
reg.ignoreCase; //返回 true
var reg = /JavaScript/;
reg.test("javascript"); //返回 false
var reg = /JavaScript/i;
reg.test("javascript"); //返回 true
是一个只读的布尔值,看这个正则表达式是否带有修饰符m。
修饰符m,用以在多行模式中执行匹配,需要配合^ 和 $ 使用,使用^ 和 $ 除了匹配整个字符串的开始和结尾之外,还能匹配每行的开始和结尾。
var str="java\nJavaScript";
str.match(/^JavaScript/); //返回null
var str="java\nJavaScript";
str.match(/^JavaScript/m); //匹配到一个JavaScript
var reg=/JavaScript/;
reg.multiline; //返回false
var reg=/JavaScript/m;
reg.multiline; //返回true
是一个可读/写的整数,如果匹配模式中带有g修饰符,这个属性存储在整个字符串中下一次检索的开始位置,这个属性会被exec( ) 和 test( ) 方法用到。
exec( )方法是在一个字符串中执行匹配检索,如果它没有找到任何匹配,它就返回null,但如果它找到了一个匹配,它就返回一个数组。
js的正则对象会保存上次查找到的索引值 ,导致的结果就是执行相同的test或exec操作 会出现不同的结果
var reg = /\d/g
var s = '1sss'
var i = reg.test(s)
console.log(i,reg.lastIndex)
var i = reg.test(s)
console.log(i,reg.lastIndex)
要重置的话直接设置索引值就好了
reg.lastIndex = 0
var i = reg.test(s)
console.log(i,reg.lastIndex)
今天在写一个校验ip的正则表达式时,遇到一个问题,表达式匹配本身没有任何问题,但当末尾带上/g时,校验同一个ip,第一次使用test返回的结果是true,但第二次就是false,第三次又是true,仔细一想,记得RegExp对象有一个记录匹配位置的属性,于是上w3school查了一下,果然。
以下为w3school上的内容:
该属性存放一个整数,它声明的是上一次匹配文本之后的第一个字符的位置。
上次匹配的结果是由方法 RegExp.exec() 和 RegExp.test() 找到的,它们都以 lastIndex 属性所指的位置作为下次检索的起始点。这样,就可以通过反复调用这两个方法来遍历一个字符串中的所有匹配文本。
该属性是可读可写的。只要目标字符串的下一次搜索开始,就可以对它进行设置。当方法 exec() 或 test() 再也找不到可以匹配的文本时,它们会自动把 lastIndex 属性重置为 0。
重要事项:不具有标志 g 和不表示全局模式的 RegExp 对象不能使用 lastIndex 属性。
因此,如果正则带有标志g,则必须将lastIndex重置为0后才能再用做校验,否则使用test校验不同的字符串时,RegExp会使用test前一个字符串得出的lastIndex去test后一个字符串,这样代码就坑爹了,必定出错。
思前想后,一般情况下,正则作校验字符串用时,不需要带g
在JavaScript中使用正则表达式时,遇到一个坑:第一次匹配是true,第二次匹配是false。
因为在带全局标识"g"的正则表达式对象中,才有“lastIndex” 属性,该属性用于指定下次匹配的起始位置。
例如:
var pattern1 = new RegExp("1[0-9]{10}", "g"); // 带全局标识
var pattern2 = new RegExp("^1[0-9]{10}$"); // 不带全局标识
带全局标识的正则pattern1 ,在字符串中匹配到子串之后,pattern1.lastIndex的值并没有立刻被重置为0,而是会接着上一次匹配的位置继续向后寻找是否有匹配的值,这就会出现问题:“一个匹配的字符串第一次匹配为true,第二次匹配为false”。
有两种解决方法:
(1)去掉全局标识"g",用[^][$]首尾限定符包裹的字符串定义正则表达式;
(2)有些情况下必须保留全局标识"g",可以在匹配(test)过一次之后,手动将lastIndex的值重置为0,如:
pattern1.lastIndex = 0
例子
//它们都以 lastIndex 属性所指的位置作为下次检索的起始点。这样,就可以通过反复调用这两个方法来遍历一个字符串中的所有匹配文本。
var reg = /\d/g
var s = '1ss1s'
var i = reg.test(s)
console.log(i, reg.lastIndex)
i = reg.test(s)
console.log(i, reg.lastIndex)
// reg.lastIndex = 0
var i = reg.test(s)
console.log(i, reg.lastIndex)
输出
true 1
true 4
false 0
配前面的子表达式零次或一次,0或1,可以使用{0,1}代替
举例:
在平常webpack的rules配置中,用来匹配ts和tsx文件
{
test: /\.tsx?$/
}
能匹配少的就不匹配多的原则
举例:
查找字符串的数字,如果有3个数字连在一起,就直接匹配
const str = 'sd2345s423987sd2342'
str.match(/\d{3,5}?/g)
// 因为增加了"?"符合,导致只要有符合3个连续数字的就返回。
// ["234", "423", "987", "234"]
str.match(/\d{3,5}/g)
// 去掉"?"后,变成了默认模式,就是贪婪匹配
// ["2345", "42398", "2342"]
查找img全标签
const str = '<img class="latex" style="width:2.323ex; height:2.009ex; vertical-align: -0.171ex;" src="https://td.com/1.png" /><span>s</span>'
str.match(/<img.*?\/?>/g)
// ["<img class="latex" style="width:2.323ex; height:2.…l-align: -0.171ex;" src="https://td.com/1.png" />"]
// 下面把第一个"?"去掉,发现结果就是全部匹配了。
str.match(/<img.*\/?>/g)
// ["<img class="latex" style="width:2.323ex; height:2.…1ex;" src="https://td.com/1.png" /><span>s</span>"]
x 只有在 y 前面才匹配,必须写成 /x(?=y)/的形式
举例:
查找字符串%前面的数字
const str = 'The best way to achieve a goal is to devote 100% of your time and energy to it.'
str.match(/\d+(?=%)/g)
x 只有不在 y 前面才匹 配,必须写成 /x(?!y)/的形
举例:
查找字符串中数字不在%前面的数字
let str = 'I have more than 100 books'
str.match(/\d+(?!%)/g)
// ["100"]
str = 'I have more than 100 books, but only 20% is about software'
str.match(/\d+(?!%)/g)
// 【注意】2也匹配到了,如果需要把20也过滤掉,需要额外加代码
// ["100", "2"]
输出内容,但是不匹配
举例:
输出查找到的内容
let reg1=/(?:js|golang) is good/
let reg2= /(js|golang) is good/
let str1 = reg1.exec('js is good, golang is good')
// js这个词虽然有()进行处理,但是不会被匹配到,而是整体输出`js is good`
// ["js is good", index: 0, input: "js is good, golang is good", groups: undefined]
let str2 = reg2.exec('js is good, golang is good')
// 去掉“?:”之后的结果
// ["js is good", "js", index: 0, input: "js is good, golang is good", groups: undefined]
console.log('str1=', str1)
console.log('str2=', str2)
// [
// 'js is good',
// index: 0,
// input: 'js is good, golang is good',
// groups: undefined
// ]
console.log('js is good, golang is good'.match(str1))
console.log('js is good, golang is good'.match(str2))
// null
"后行断言"正好与"先行断言"相反 , x 只有在 y 后面才匹配 , 必须写成/(
y)x/的 形式
举例:
查找¥后面的数字
let str = `I spent ¥100 RMB to buy this book`
/(?<=¥)\d+/.exec(str)
x 只有不在 y 后面才匹配,必须写成/(?<! y)x/的形式
举例:
查找不是¥后面的数字
let str = `I spent $100 RMB to buy this book`;
/(?<!¥)\d+/.exec(str)
// ["100", index: 9, input: "I spent $100 RMB to buy this book", groups: undefined]
匹配pattern但不获取匹配结果
var str = 'aaabbb'
var reg = /(a+)(?:b+)/
var str1 = str.match(reg)
// ["aaabbb", "aaa", index: 0, input: "aaabbb", groups: undefined]
console.log('str1=', str1)
意思就是匹配内容右侧必须为pattern
var str = "i'm singing and dancing";
var reg = /\b(\w+(?=ing\b))/g
var res = str.match(reg);
console.log(res)// ["sing", "danc"]
就是匹配右侧不是pattern内容
var str = 'nodejs'
var reg = /node(?!js)/
var str1=reg.test(str) // false
console.log('str1=',str1)
匹配这个位置之前为pattern的内容
var str = '111$222'
var reg = /(?<=\$)\d+/
var str1=str.match(reg) // ["222", index: 4, input: "111$222", groups: undefined]
console.log('str1=',str1)
匹配这个位置之前部位pattern的内容
var str = '¥998$888';
var reg = /(?<!\$)\d+/;
console.log(reg.exec(str)) //998
.表示除\n之外的任意字符
+匹配前面的子表达式一次或多次。
(?<=exp)是以exp开头的字符串, 但不包含本身。
(?=exp)就匹配为exp结尾的字符串, 但不包含本身。
注:语句外面的括号不可省略
g匹配全局
- 获取括号的内容,包换括号
var str="123{456}hhh[789]zzz[yyy]bbb(90ba)kkk";
var regex1 = /\((.+?)\)/g; // () 小括号
var regex2 = /\[(.+?)\]/g; // [] 中括号
var regex3 = /\{(.+?)\}/g; // {} 花括号,大括号
// 输出是一个数组
console.log(str.match(regex1)); //['(90ba)']
console.log(str.match(regex2));//['[789]', '[yyy]']
console.log(str.match(regex3));//['{456}']
- 获取括号的内容,不包含括号
也就是将
\(与(?<=\()替换,\)与(?=\))替换,其他括号同理。
var str2="123{456}hhh[789]zzz[yyy]bbb(90ba)kkk";
var regex11 = /(?<=\()(.+?)(?=\))/g; // () 小括号
var regex22 = /(?<=\[)(.+?)(?=\])/g; // [] 中括号
var regex33 = /(?<=\{)(.+?)(?=\})/g; // {} 花括号,大括号
// 输出是一个数组
console.log(str2.match(regex11)); //['90ba']
console.log(str2.match(regex22));//['789', 'yyy']
console.log(str2.match(regex33));//['456']
js正则表达式,匹配括号中的内容(不包含括号)
var str = "12【开始】3{xxxx}456[我的]789123[你的]456(1389090)78【结束】9";
var regex1 = /\((.+?)\)/g; // () 小括号
var regex2 = /\[(.+?)\]/g; // [] 中括号
var regex3 = /\{(.+?)\}/g; // {} 花括号,大括号
var regex4 = /\【(.+?)\】/g; // {} 中文大括号
// 输出是一个数组
console.log(str.match(regex1)); // ["(1389090)"]
console.log(str.match(regex2)); // ["[我的]", "[你的]"]
console.log(str.match(regex3)); // ["{xxxx}"]
console.log(str.match(regex4)); // ["【开始】", "【结束】"]
正则表达式匹配括号中的字符,不包括括号
(?<=\()\S+(?=\))
(?<=exp)是以exp开头的字符串, 但不包含本身.
(?=exp)就匹配为exp结尾的字符串, 但不包含本身.
(?<=() 也就是以括号开头, 但不包含括号.
(?=)) 就是以括号结尾
\S 匹配任何非空白字符。等价于[^\f\n\r\t\v]。
+表示至少有一个字符.
(?<=()\S+(?=)) 就是匹配以 (开头, )结尾的括号里面最少有一个非空白字符的串, 但不包括开头的(和结尾的)
var str = "12【开始】3{xxxx}456[我的]789123[你的]456(1389090)78【结束】9";
var regex1 = /(?<=\()(.+?)(?=\))/g; // () 小括号
var regex2 = /(?<=\[)(.+?)(?=\])/g; // [] 中括号
var regex3 = /(?<=\{)(.+?)(?=\})/g; // {} 花括号,大括号
var regex4 = /((?<=\【)(.+?)(?=\】))/g; // {} 中文大括号
// 输出是一个数组
console.log(str.match(regex1)); // ["1389090"]
console.log(str.match(regex2)); // ["我的", "你的"]
console.log(str.match(regex3)); // ["xxxx"]
console.log(str.match(regex4)); // ["开始", "结束"]
1、移动端项目使用断言时,安卓页面显示无异常,iPhone页面无法加载(空白)。
2、vue的项目中使用断言,打包时异常。
根据正则表达式语法规则,大部分字符仅能够描述自身,这些字符被称为普通字符,如所有的字母、数字等。
元字符就是拥有特动功能的特殊字符,大部分需要加反斜杠进行标识,以便于普通字符进行区别,而少数元字符,需要加反斜杠,以便转译为普通字符使用。JavaScript 正则表达式支持的元字符如表所示。
元字符
描述
.
查找单个字符,除了换行和行结束符
\w
查找单词字符
\W
查找非单词字符
\d
查找数字
\D
查找非数字字符
\s
查找空白字符
\S
查找非空白字符
\b
匹配单词边界
\B
匹配非单词边界
\0
查找 NUL字符
\n
查找换行符
\f
查找换页符
\r
查找回车符
\t
查找制表符
\v
查找垂直制表符
\xxx
查找以八进制数 xxxx 规定的字符
\xdd
查找以十六进制数 dd 规定的字符
\uxxxx
查找以十六进制 xxxx规定的 Unicode 字符
表示字符的方法有多种,除了可以直接使用字符本身外,还可以使用 ASCII 编码或者 Unicode 编码来表示。
下面使用 ASCII 编码定义正则表达式直接量。
var r = /\x61/;var s = "JavaScript";var a = s.match(s);
由于字母 a 的 ASCII 编码为 97,被转换为十六进制数值后为 61,因此如果要匹配字符 a,就应该在前面添加“\x”前缀,以提示它为 ASCII 编码。
除了十六进制外,还可以直接使用八进制数值表示字符。
var r = /\141/;var s = "JavaScript";var a = s.match(r);
使用十六进制需要添加“\x”前缀,主要是为了避免语义混淆,而八进制则不需要添加前缀。
ASCII 编码只能够匹配有限的单字节字符,使用 Unicode 编码可以表示双字节字符。Unicode 编码方式:“\u”前缀加上 4 位十六进制值。
var r = "/\u0061/";var s = "JavaScript";var a = s.match(s);
在 RegExp() 构造函数中使用元字符时,应使用双斜杠。
var r = new RegExp("\\u0061");
RegExp() 构造函数的参数只接受字符串,而不是字符模式。在字符串中,任何字符加反斜杠还表示字符本身,如字符串“\u”就被解释为 u 本身,所以对于“\u0061”字符串来说,在转换为字符模式时,就被解释为“u0061”,而不是“\u0061”,此时反斜杠就失去转义功能。解决方法:在字符 u 前面加双反斜杠。
在正则表达式语法中,放括号表示字符范围。在方括号中可以包含多个字符,表示匹配其中任意一个字符。如果多个字符的编码顺序是连续的,可以仅指定开头和结尾字符,省略中间字符,仅使用连字符
~
表示。如果在方括号内添加脱字符
^
前缀,还可以表示范围之外的字符。例如:
- [abc]:查找方括号内任意一个字符。
- [^abc]:查找不在方括号内的字符。
- [0-9]:查找从 0 至 9 范围内的数字,即查找数字。
- [a-z]:查找从小写 a 到小写 z 范围内的字符,即查找小写字母。
- [A-Z]:查找从大写 A 到大写 Z 范围内的字符,即查找大写字母。
- [A-z]:查找从大写 A 到小写 z 范围内的字符,即所有大小写的字母。
字符范围遵循字符编码的顺序进行匹配。如果将要匹配的字符恰好在字符编码表中特定区域内,就可以使用这种方式表示。
如果匹配任意 ASCII 字符:
var r = /[\u0000-\u00ff]/g;
如果匹配任意双字节的汉字:
var r = /[^\u0000-\u00ff]/g;
如果匹配任意大小写字母和数字:
var r = /[a-zA-Z0-9]/g;
使用 Unicode 编码设计,匹配数字:
var r = /[\u0030-\u0039]/g;
使用下面字符模式可以匹配任意大写字母:
var r = /[\u0041-\u004A]/g;
使用下面字符模式可以匹配任意小写字母:
var r = /[\u0061-\u007A]/g;
在字符范围内可以混用各种字符模式。
var s = "abcdez"; //字符串直接量var r = /[abce-z]/g; //字符a、b、c,以及从e~z之间的任意字符var a = s.match(r); //返回数组["a","b","c","e","z"]
在中括号内不要有空格,否则会误解为还要匹配空格。
var r = /[0-9]/g;
字符范围可以组合使用,以便设计更灵活的匹配模式。
var s = "abc4 abd6 abe3 abf1 abg7"; //字符串直接量
var r = /ab[c-g][1-7]/g; //前两个字符为ab,第三个字符为从c到g,第四个字符为1~7的任意数字
var a = s.match(r); //返回数组["abc4","abd6","abe3","abf1","abg7"]
使用反义字符范围可以匹配很多无法直接描述的字符,达到以少应多的目的。
var r = /[^0123456789]/g;
在这个正则表达式中,将会匹配除了数字以外任意的字符。反义字符类比简单字符类的功能更强大和实用。
选择匹配类似于 JavaScript 的逻辑与运算,使用竖线
|
描述,表示在两个子模式的匹配结果中任选一个。例如:
- 匹配任意数字或字母
var r = /\w+|\d+/;
- 可以定义多重选择模式。设计方法:在多个子模式之间加入选择操作符。
var r = /(abc)|(efg)|(123)|(456)/;
为了避免歧义,应该为选择操作的多个子模式加上小括号。
设计对提交的表单字符串进行敏感词过滤。先设计一个敏感词列表,然后使用竖线把它们连接在一起,定义选择匹配模式,最后使用字符串的 replace() 方法把所有敏感字符替换为可以显示的编码格式。代码如下:
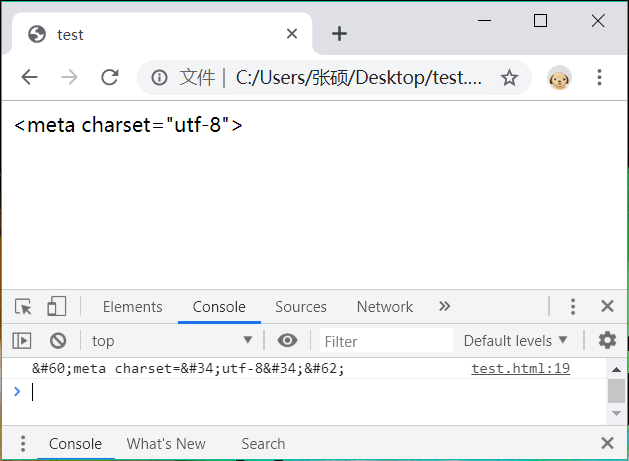
var s = '<meta charset="utf-8">'; //待过滤的表单提交信息
var r = /\'|\"|\<|\>/gi; //过滤敏感字符的正则表达式
function f () { //替换函数
////把敏感字符替换为对应的网页显示的编码格式
return "&#" + arguments[0].charCodeAt(0) + ";";
}
var a = s.replace(r, f); //执行过滤替换 document.write(a);
//在网页中显示正常的字符信息
console.log(a);
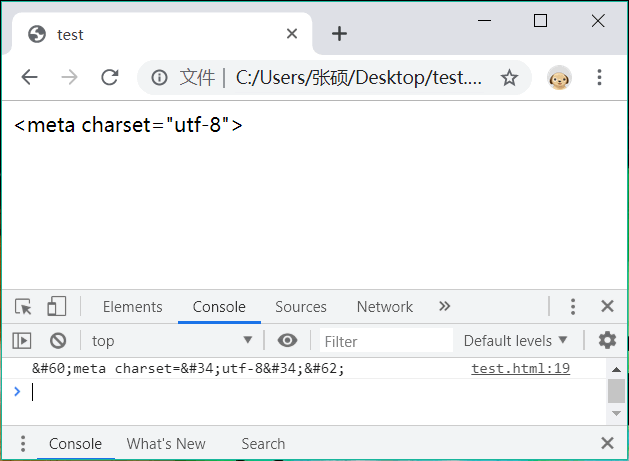
显示结果如下:
在正则表达式语法中,定义了一组重复类量词,如表所示。它们定义了重复匹配字符的确数或约数。
量词
描述
n+
匹配任何包含至少一个 n 的字符串
n*
匹配任何包含零个或多个 n 的字符串
n?
匹配任何包含零个或一个 n 的字符串
n{x}
匹配包含 x 个 n 的序列的字符串
n{x,y}
匹配包含最少 x 个、最多 y 个 n 的序列的字符串
n{x,}
匹配包含至少 x 个 n 的序列的字符串
下面结合示例进行演示说明,先设计一个字符串:
var s = "ggle gogle google gooogle goooogle gooooogle goooooogle gooooooogle goooooooogle";
- 如果仅匹配单词 ggle 和 gogle,可以设计:
var r = /go?gle/g;
var a = s.match(r);
量词
?
表示前面字符或子表达式为可有可无,等效于:
var r = /go{0,1}gle/g;
var a = s.match(r);
- 如果匹配第 4 个单词 gooogle,可以设计:
var r = /go{3}gle/g;
var a = s.match(r);
等效于:
var r = /gooogle/g;
var a = s.match(r);
- 如果匹配第 4 个到第 6 个之间的单词,可以设计:
var r = /go{3,5}gle/g;
var a = s.match(r);
- 如果匹配所有单词,可以设计:
var r = /go*gle/g;
var a = s.match(r);
量词
*
表示前面字符或表达式可以不出现,或者重复出现任意多次。等效于:
var r = /go(0,)gle/g;
var a = s.match(r);
- 如果匹配包含字符“o”的所有词,可以设计:
var r = /go+gle/g;
var a = s.match(r);
量词
+
表示前面字符或子表达式至少出现 1 次,最多重复次数不限。等效于:
var r = /go{1,}gle/g;
var a = s.match(r);
重复类量词总是出现在它们所作用的字符或子表达式后面。如果想作用于多个字符,需要使用小括号把它们包裹在一起形成一个子表达式。
重复类量词都具有贪婪性,在条件允许的前提下,会匹配尽可能多的字符。
- ?、{n} 和 {n,m} 重复类具有弱贪婪性,表现为贪婪的有限性。
- *、+ 和 {n,} 重复类具有强贪婪性,表现为贪婪的无限性。
越是排在左侧的重复类量词匹配优先级越高。下面示例显示当多个重复类量词同时满足条件时,会在保证右侧重复类量词最低匹配次数基础上,使最左侧的重复类量词尽可能占有所有字符。
var s = "<html><head><title></title></head><body></body></html>";
var r = /(<.*>)(<.*>)/
var a = s.match(r);//左侧表达式匹配"<html><head><title></title></head><body></body></html>"
console.log(a[1])
console.log(a[2]); //右侧表达式匹配“</html>”
与贪婪匹配相反,惰性匹配将遵循另一种算法:在满足条件的前提下,尽可能少的匹配字符。定义惰性匹配的方法:在重复类量词后面添加问号?限制词。贪婪匹配体现了最大化匹配原则,惰性匹配则体现最小化匹配原则。
下面示例演示了如何定义匹配模式。
var s = "<html><head><title></title></head><body></body></html>";
var r = /<.*?>/
var a = s.match(r); //返回单个元素数组["<html>"]
在上面示例中,对于正则表达式 /<.*?>/ 来说,它可以返回匹配字符串 "<>",但是为了能够确保匹配条件成立,在执行中还是匹配了带有 4 个字符的字符串“html”。惰性取值不能够以违反模式限定的条件而返回,除非没有找到符合条件的字符串,否则必须满足它。
针对 6 种重复类惰性匹配的简单描述如下:
- {n,m}?:尽量匹配 n 次,但是为了满足限定条件也可能最多重复 m 次。
- {n}?:尽量匹配 n 次。
- {n,}?:尽量匹配 n 次,但是为了满足限定条件也可能匹配任意次。
- ??:尽量匹配,但是为了满足限定条件也可能最多匹配 1 次,相当于 {0,1}?。
- +?:尽量匹配 1 次,但是为了满足限定条件也可能匹配任意次,相当于 {1,}?。
- *? :尽量不匹配,但是为了满足限定条件也可能匹配任意次,相当于 {0,}?。
边界就是确定匹配模式的位置,如字符串的头部或尾部,具体说明如表所示。
量词
说明
^
匹配开头,在多行检测中,会匹配一行的开头
$
匹配结尾,在多行检测中,会匹配一行的结尾
下面代码演示如何使用边界量词。先定义字符串:
var s = "how are you "
- 匹配最后一个单词
var r = /\w+$/;
var a = s.match(r); //返回数组["you"]
- 匹配第一个单词
var r = /^\w+/;
var a = s.match(r); //返回数组["how"]
- 匹配每一个单词
var r = /\w+/g;
var a = s.match(r); //返回数组["how","are","you"]
声明表示条件的意思。声明词量包括正向声明和反向声明两种模式。
指定匹配模式后面的字符必须被匹配,但又不返回这些字符。语法格式如下:
匹配模式 (?= 匹配条件)
声明包含在小括号内,它不是分组,因此作为子表达式。
下面代码定义一个正前向生命的匹配模式。
var s = "one : 1; two : 2";
var r = /\w*(?==)/; //使用正前向声明,指定执行匹配必须满足的条件
var a = s.match(r); //返回数组["two"]
在上面示例中,通过
?==
锚定条件,指定只有在 \w* 所能够匹配的字符后面跟随一个等号字符,才能够执行 \w* 匹配。所以,最后匹配的字符串“two”,而不是字符串“one”。
与正向声明匹配相反,指定接下来的字符都不必被匹配。语法格式如下:
匹配模式(?! 匹配条件)
下面代码定义一个反前向生命的匹配模式。
var s = "one : 1; two : 2";
var r = /\w*(?!=)/; //使用正前向声明,指定执行匹配不必满足的条件
var a = s.match(r); //返回数组["one"]
在上面示例中,通过
?!=
锚定条件,指定只有在“\w*”所能够匹配的字符后面不跟随一个等号字符,才能够执行 \w*匹配。所以,最后匹配的是字符串“one”,而不是字符串“two”。
使用小括号可以对字符模式进行任意分组,在小括号内的字符串表示子表达式,也称为子模式。子表达式具有独立的匹配功能,保存独立的匹配结果;同时,小括号后的量词将会作用于整个子表达式。
通过分组可以在一个完整的字符模式中定义一个或多个子模式。当正则表达式成功地匹配目标字符串后,也可以从目标字符串中抽出与子模式相匹配的子内容。
在下面代码中,不仅能匹配出每个变量声明,同时还抽出每个变量及其值。
var s = "ab=21, bc=45, cd=43";
var r = /(\w+)=(\d*)/g;
while (a = r.exec(s)) {
console.log(a); //返回类似["ab=21","bc=45","cd=43"]三个数组
}
在字符模式中,后面的字符可以引用前面的子表达式。实现方法如下:
+ 数字
数字指定了子表达式在字符模式中的顺序。如“\1”引用的是第 1 个子表达式,“\2”引用的是第 2 个子表达式。
在下面代码中,通过引用前面子表达式匹配的文本,实现成组匹配字符串。
var s = "<h1>title<h1><p>text<p>";
var r = /(<\/?\w+>)\1/g;
var a = s.match(r); //返回数组["<h1>title<h1>","<p>text<p>"]
由于子表达式可以相互嵌套,它们的顺序将根据左括号的顺序来确定。例如,下面示例定义匹配模式包含多个子表达式。
var s = "abc";
var r = /(a(b(c)))/;
var a = s.match(r); //返回数组["abc","abc","bc","c"]
在这个模式中,共产生了 3 个反向引用,第一个是“(a(b(c)))”,第二个是“(b(c))”,第三个是“(C)”。它们引用的匹配文本分别是字符串“abc”、“bc”和“c”。
对子表达式的引用,是指引用前面子表达式所匹配的文本,而不是子表达式的匹配模式。如果要引用前面子表达式的匹配模式,则必须使用下面方式,只有这样才能够达到匹配目的。
var s = "<h1>title</h1><p>text</p>";
var r = /((<\/?\w+>).*(<\/?\w+>))/g;
var a = s.match(r); //返回数组["<h1>title</h1>","<p>text</p>"]
反向引用在开发中主要有以下几种常规用法。
在正则表达式对象的 test() 方法中,以及字符串对象的 match() 和 search() 等方法中使用。在这些方法中,反向引用的值可以从 RegExp() 构造函数中获得。
var s = "abcdefghijklmn";
var r = /(\w)(\w)(\w)/;
r.test(s);
console.log(RegExp.$1); //返回第1个子表达式匹配的字符a
console.log(RegExp.$2); //返回第2个子表达式匹配的字符b
console.log(RegExp.$3); //返回第3个子表达式匹配的字符c
通过上面示例可以看到,正则表达式执行匹配检测后,所有子表达式匹配的文本都被分组存储在 RegExp() 构造函数的属性内,通过前缀符号
$
与正则表达式中子表达式的编号来引用这些临时属性。其中属性 $1 标识符指向第 1 个值引用,属性 $2 标识符指向第 2 个值引用。
可以直接在定义的字符模式中包含反向引用。这可以通过使用特殊转义序列(如 \1、\2 等)来实现。
var s = "abcbcacba";
var r = /(\w)(\w)(\w)\2\3\1\3\2\1/;
var b = r.test(s); //验证正则表达式是否匹配该字符串
console.log(b); //返回true
在上面示例的正则表达式中,“\1”表示对第 1 个反向引用 (\w) 所匹配的字符 a 进行引用,“\2”表示对第 2 个反向引用 (\w) 所匹配的字符串 b 进行引用,“\3”表示对第 3 个反向引用 (\w) 所匹配的字符 c 进行引用。
可以在字符串对象的 replace() 方法中使用。通过使用特殊字符序列$1、$2、$3 等来实现。例如,在下面的示例中将颠倒相邻字母和数字的位置。
var s = "aa11bb22c3d4e5f6";
var r = /(\w+?)(\d+)/g;
var b = s.replace(r, "$2$1");
console.log(b); //返回字符串“aa11bb22c3 d4e5f6”
在上面例子中,正则表达式包括两个分组,第 1 个分组匹配任意连续的字母,第 2 个分组匹配任意连续的数字。在 replace() 方法的第 2 个参数中,$1 表示对正则表达式中第 1 个子表达式匹配文本的引用,而 $2 表示对正则表达式中第 2 个子表达式匹配文本的引用,通过颠倒 $1 和 $2 标识符的位置,即可实现字符串的颠倒来替换原字符串。
反向引用会占用一定的系统资源,在较长的正则表达式中,反向引用会降低匹配速度。如果分组仅仅是为了方便操作,可以禁止反向引用。
实现方法:在左括号的后面加上一个问号和冒号。
var s1 = "abc";
var r = /(?:\w*?)|(?:\d*?)/;
var a = r.test(si);
非引用型分组必须使用子表达式,但是又不希望存储无用的匹配信息,或者希望提高匹配速度来说,是非常重用的方法。
1. 简单排除
[^a]* 排除a
[^abc]* 排除a,b,c
\D 排除数字
\S 排除空格
[^\u4E00-\u9FA5] 排除汉字
2. 排除某个单词
/^((?!hello).)+$/ 排除 hello
((?!天空).)* 排除 天空
\b(?!cat\b)\w+ 排除 cat
3. 排除的写法结构
^(?!排除判断).key(?!排除判断).$
4. 排除多个
^(?!.*(?:取消|撤销|删除)).*小微
(?!.*(?:abc|123)) 排除abc或者123
^(?!.(?:取消|撤销|删除)).小微(?!.(?:企业|贷款|快贷|商户|公司)).$
例子:
1. 匹配不包含"天空",包含"花儿"的句子
import re
string = '太阳天空照,花儿对我笑'
result = re.findall(r'^(?:(?!天空).)*?花儿.*$', string)
print(result)
# []
string = '太阳空中照,花儿对我笑'
result = re.findall(r'^(?:(?!天空).)*?花儿.*$', string)
print(result)
# ['太阳空中照,花儿对我笑']
2. 匹配今天的天气,而不是明天的
import re
s1 = 'how is the weather today'
s2 = 'how is the weather tomorrow'
regex = r'(^.*weather(?:(?!tomorrow).)*$)'
result1 = re.findall(regex, s1)
result2 = re.findall(regex, s2)
print('result1: ', result1)
print('result2: ', result2)
# result1: ['how is the weather today']
# result2: []
3. 匹配&和;之间不含有test的字符
str = "hello &test1;test&qout;";
正则表达式:/&((?!test).)+;/g
匹配结果: 和 &qout;
4. 匹配不含有![]() 标签的
标签的
标签
str = "<div id='1'><img class='xx'></div><div id='1'><input type=''text"></div>";
正则表达式: /<div[^>]>((?!<img[^>]>).)+/g
匹配结果:
<input type=''text">
5. 不包含robots的句子
^(?!.*?robots).*$
6. 不以2009-07-08开头的条目
^(?!2009-07-08).*?$
出处:https://blog.csdn.net/xuyangxinlei/article/details/81359366
https://www.cnblogs.com/zongfa/p/14818734.html