possible deadlock in dataloader
zym1010 opened this issue · comments

the bug is described at pytorch/examples#148. I just wonder if this is a bug in PyTorch itself, as the example code looks clean to me. Also, I wonder if this is related to #1120.

How much free memory do you have when the loader stops?
@apaszke if I check top, the remaining memory (cached mem also counts as used) is usually 2GB. But if you don't count cached as used, it's always a lot, say 30GB+.
Also I don't understand why it always stops at beginning of validation, but not everywhere else.

Possibly because for validation a separate loader is used that pushes the use of shared memory over the limit.
I just ran the program again. And got stuck.
Output of top:
top - 17:51:18 up 2 days, 21:05, 2 users, load average: 0.49, 3.00, 5.41
Tasks: 357 total, 2 running, 355 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.9 us, 0.1 sy, 0.7 ni, 97.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 65863816 total, 60115084 used, 5748732 free, 1372688 buffers
KiB Swap: 5917692 total, 620 used, 5917072 free. 51154784 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3067 aalreja 20 0 143332 101816 21300 R 46.1 0.2 1631:44 Xvnc
16613 aalreja 30 10 32836 4880 3912 S 16.9 0.0 1:06.92 fiberlamp 3221 aalreja 20 0 8882348 1.017g 110120 S 1.3 1.6 579:06.87 MATLAB
1285 root 20 0 1404848 48252 25580 S 0.3 0.1 6:00.12 dockerd 16597 yimengz+ 20 0 25084 3252 2572 R 0.3 0.0 0:04.56 top
1 root 20 0 33616 4008 2624 S 0.0 0.0 0:01.43 init
Output of free
yimengzh_everyday@yimengzh:~$ free
total used free shared buffers cached
Mem: 65863816 60122060 5741756 9954628 1372688 51154916
-/+ buffers/cache: 7594456 58269360
Swap: 5917692 620 5917072
Output of nvidia-smi
yimengzh_everyday@yimengzh:~$ nvidia-smi
Tue Apr 25 17:52:38 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 375.39 Driver Version: 375.39 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX TIT... Off | 0000:03:00.0 Off | N/A |
| 30% 42C P8 14W / 250W | 3986MiB / 6082MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla K40c Off | 0000:81:00.0 Off | Off |
| 0% 46C P0 57W / 235W | 0MiB / 12205MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 16509 C python 3970MiB |
+-----------------------------------------------------------------------------+
I don't think it's a memory issue.
There are separate limits for shared memory. Can you try ipcs -lm or cat /proc/sys/kernel/shmall and cat /proc/sys/kernel/shmmax? Also, does it deadlock if you use fewer workers (e.g. test with the extreme case of 1 worker)?
yimengzh_everyday@yimengzh:~$ ipcs -lm
------ Shared Memory Limits --------
max number of segments = 4096
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18446744073642442748
min seg size (bytes) = 1
yimengzh_everyday@yimengzh:~$ cat /proc/sys/kernel/shmall
18446744073692774399
yimengzh_everyday@yimengzh:~$ cat /proc/sys/kernel/shmmax
18446744073692774399
how do they look for you?
as for fewer workers, I believe it won't happen that often. (I can try now). But I think in practice I need that many workers.
You have a max of 4096 shared memory segments allowed, maybe that's an issue. You can try increasing that by writing to /proc/sys/kernel/shmmni (maybe try 8192). You may need superuser privileges.
@apaszke well these are default values by both Ubuntu and CentOS 6... Is that really an issue?
@apaszke when running training program, ipcs -a actually shows no shared memory being used. Is that expected?
@apaszke tried running the program (still 22 workers) with following setting on shared mem, and stuck again.
yimengzh_everyday@yimengzh:~$ ipcs -lm
------ Shared Memory Limits --------
max number of segments = 8192
max seg size (kbytes) = 18014398509465599
max total shared memory (kbytes) = 18446744073642442748
min seg size (bytes) = 1
didn't try one worker. first, that would be slow; second, if the problem is really dead locking, then it would definitely disappear.
@zym1010 default settings doesn't have to be created with such workloads in mind, so yes it might have been an issue. ipcs is for System V shared memory which we aren't using, but I wanted to make sure the same limits don't apply to POSIX shared memory.
It wouldn't definitely disappear, because if the problem is really there, then it's likely a deadlock between the worker and main process, and one worker might be enough to trigger this. Anyway, I can't fix the issue until I can reproduce it. What are the parameters you're using to run the example and did you modify the code in any way? Also, what's the value of torch.__version__? Are you running in docker?
@apaszke Thanks. I understand your analysis much better now.
All other results shown to you up to how are performed on a Ubuntu 14.04 machine with 64GB RAM, dual Xeon, and Titan Black (there's also a K40, but I didn't use it).
The command to generate the problem is CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 20 --lr 0.01 --workers 22 --batch-size 256 /mnt/temp_drive_3/cv_datasets/ILSVRC2015/Data/CLS-LOC. I didn't modify code at all.
I installed pytorch through pip, on Python 3.5. pytorch version is 0.1.11_5. Not running in Docker.
BTW, I also tried using 1 worker. But I did it on another machine (128GB RAM, dual Xeon, 4 Pascal Titan X, CentOS 6). I ran it using CUDA_VISIBLE_DEVICES=0 PYTHONUNBUFFERED=1 python main.py -a alexnet --print-freq 1 --lr 0.01 --workers 1 --batch-size 256 /ssd/cv_datasets/ILSVRC2015/Data/CLS-LOC, and the error log is as follows.
Epoch: [0][5003/5005] Time 2.463 (2.955) Data 2.414 (2.903) Loss 5.9677 (6.6311) Prec@1 3.516 (0.545) Prec@5 8.594 (2.262)
Epoch: [0][5004/5005] Time 1.977 (2.955) Data 1.303 (2.903) Loss 5.9529 (6.6310) Prec@1 1.399 (0.545) Prec@5 7.692 (2.262)
^CTraceback (most recent call last):
File "main.py", line 292, in <module>
main()
File "main.py", line 137, in main
prec1 = validate(val_loader, model, criterion)
File "main.py", line 210, in validate
for i, (input, target) in enumerate(val_loader):
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 168, in __next__
idx, batch = self.data_queue.get()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/queue.py", line 164, in get
self.not_empty.wait()
File "/home/yimengzh/miniconda2/envs/pytorch/lib/python3.5/threading.py", line 293, in wait
waiter.acquire()
the top showed the following when stuck with 1 worker.
top - 08:34:33 up 15 days, 20:03, 0 users, load average: 0.37, 0.39, 0.36
Tasks: 894 total, 1 running, 892 sleeping, 0 stopped, 1 zombie
Cpu(s): 7.2%us, 2.8%sy, 0.0%ni, 89.7%id, 0.3%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 132196824k total, 131461528k used, 735296k free, 347448k buffers
Swap: 2047996k total, 22656k used, 2025340k free, 125226796k cached
another thing I found is that, if I modified the training code, so that it won't go through all batches, let say, only train 50 batches
if i >= 50:
break
then the deadlock seems to disappear.
further testing seems to suggest that, this freezing much more frequently happens if I ran the program just after rebooting the computer. After there's some cache in the computer, seems that the frequency of getting this freezing is less.
I tried, but I can't reproduce this bug in any way.

I met a similar issue: the data loader stops when I finish an epoch and will start a new epoch.
Setting num_workers = 0 works. But the program slows down.
@apaszke have you tried first rebooting the computer and then running the programs? For me, this guarantees the freezing. I just tried 0.12 version, and it's still the same.
One thing I'd like to point out is that I installed the pytorch using pip, as I have a OpenBLAS-linked numpy installed and the MKL from @soumith 's anaconda cloud wouldn't play with it well.
So essentially pytorch is using MKL and numpy is using OpenBLAS. This may not be ideal, but I think this should have nothing to do with the issue here.
I looked into it, but I could never reproduce it. MKL/OpenBLAS should be unrelated to this problem. It's probably some problem with a system configuration
@apaszke thanks. I just tried the python from anaconda official repo and MKL based pytorch. Still the same problem.
tried running the code in Docker. Still stuck.

We have the same problem, running the pytorch/examples imagenet training example (resnet18, 4 workers) inside an nvidia-docker using 1 GPU out of 4. I'll try to gather a gdb backtrace, if I manage to get to the process.
At least OpenBLAS is known to have a deadlock issue in matrix multiplication, which occurs relatively rarely: OpenMathLib/OpenBLAS#937. This bug was present at least in OpenBLAS packaged in numpy 1.12.0.
@jsainio I also tried pure MKL based PyTorch (numpy is linked with MKL as well), and same problem.
Also, this problem is solved (at least for me), if I turn of pin_memory for dataloader.
It looks as if two of the workers die out.
During normal operation:
root@b06f896d5c1d:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 33.2 4.7 91492324 3098288 ? Ssl 10:51 1:10 python -m runne
user+ 58 76.8 2.3 91079060 1547512 ? Rl 10:54 1:03 python -m runne
user+ 59 76.0 2.2 91006896 1484536 ? Rl 10:54 1:02 python -m runne
user+ 60 76.4 2.3 91099448 1559992 ? Rl 10:54 1:02 python -m runne
user+ 61 79.4 2.2 91008344 1465292 ? Rl 10:54 1:05 python -m runne
after locking up:
root@b06f896d5c1d:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 24.8 4.4 91509728 2919744 ? Ssl 14:25 13:01 python -m runne
user+ 58 51.7 0.0 0 0 ? Z 14:27 26:20 [python] <defun
user+ 59 52.1 0.0 0 0 ? Z 14:27 26:34 [python] <defun
user+ 60 52.0 2.4 91147008 1604628 ? Sl 14:27 26:31 python -m runne
user+ 61 52.0 2.3 91128424 1532088 ? Sl 14:27 26:29 python -m runne
For one still remaining workers, the beginning of the gdb stacktrace looks like:
root@b06f896d5c1d:~/mnt# gdb --pid 60
GNU gdb (GDB) 8.0
Attaching to process 60
[New LWP 65]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
(gdb) bt
#0 0x00007f36f52af827 in do_futex_wait.constprop ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#1 0x00007f36f52af8d4 in __new_sem_wait_slow.constprop.0 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#2 0x00007f36f52af97a in sem_wait@@GLIBC_2.2.5 ()
from /lib/x86_64-linux-gnu/libpthread.so.0
#3 0x00007f36f157efb1 in semlock_acquire (self=0x7f3656296458,
args=<optimized out>, kwds=<optimized out>)
at /home/ilan/minonda/conda-bld/work/Python-3.5.2/Modules/_multiprocessing/semaphore.c:307
#4 0x00007f36f5579621 in PyCFunction_Call (func=
<built-in method __enter__ of _multiprocessing.SemLock object at remote 0x7f3656296458>, args=(), kwds=<optimized out>) at Objects/methodobject.c:98
#5 0x00007f36f5600bd5 in call_function (oparg=<optimized out>,
pp_stack=0x7f36c7ffbdb8) at Python/ceval.c:4705
#6 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#7 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=1, kws=0x0, kwcount=0, defs=0x0, defcount=0, kwdefs=0x0,
closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#8 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#9 0x00007f36f5557542 in function_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/funcobject.c:627
#10 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36561c7d08>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#11 0x00007f36f554077c in method_call (
func=<function at remote 0x7f36561c7d08>,
arg=(<Lock(release=<built-in method release of _multiprocessing.SemLock object at remote 0x7f3656296458>, acquire=<built-in method acquire of _multiprocessing.SemLock object at remote 0x7f3656296458>, _semlock=<_multiprocessing.SemLock at remote 0x7f3656296458>) at remote 0x7f3656296438>,), kw=0x0)
at Objects/classobject.c:330
#12 0x00007f36f5524236 in PyObject_Call (
func=<method at remote 0x7f36556f9248>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#13 0x00007f36f55277d9 in PyObject_CallFunctionObjArgs (
callable=<method at remote 0x7f36556f9248>) at Objects/abstract.c:2445
#14 0x00007f36f55fc3a9 in PyEval_EvalFrameEx (f=<optimized out>,
throwflag=<optimized out>) at Python/ceval.c:3107
#15 0x00007f36f5601166 in fast_function (nk=<optimized out>, na=1,
n=<optimized out>, pp_stack=0x7f36c7ffc418,
func=<function at remote 0x7f36561c78c8>) at Python/ceval.c:4803
#16 call_function (oparg=<optimized out>, pp_stack=0x7f36c7ffc418)
at Python/ceval.c:4730
#17 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3236
#18 0x00007f36f5601b49 in _PyEval_EvalCodeWithName (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=4, kws=0x7f36f5b85060, kwcount=0, defs=0x0, defcount=0,
kwdefs=0x0, closure=0x0, name=0x0, qualname=0x0) at Python/ceval.c:4018
#19 0x00007f36f5601cd8 in PyEval_EvalCodeEx (_co=<optimized out>,
globals=<optimized out>, locals=<optimized out>, args=<optimized out>,
argcount=<optimized out>, kws=<optimized out>, kwcount=0, defs=0x0,
defcount=0, kwdefs=0x0, closure=0x0) at Python/ceval.c:4039
#20 0x00007f36f5557661 in function_call (
func=<function at remote 0x7f36e14170d0>,
arg=(<ImageFolder(class_to_idx={'n04153751': 783, 'n02051845': 144, 'n03461385': 582, 'n04350905': 834, 'n02105056': 224, 'n02112137': 260, 'n03938244': 721, 'n01739381': 59, 'n01797886': 82, 'n04286575': 818, 'n02113978': 268, 'n03998194': 741, 'n15075141': 999, 'n03594945': 609, 'n04099969': 765, 'n02002724': 128, 'n03131574': 520, 'n07697537': 934, 'n04380533': 846, 'n02114712': 271, 'n01631663': 27, 'n04259630': 808, 'n04326547': 825, 'n02480855': 366, 'n02099429': 206, 'n03590841': 607, 'n02497673': 383, 'n09332890': 975, 'n02643566': 396, 'n03658185': 623, 'n04090263': 764, 'n03404251': 568, 'n03627232': 616, 'n01534433': 13, 'n04476259': 868, 'n03495258': 594, 'n04579145': 901, 'n04266014': 812, 'n01665541': 34, 'n09472597': 980, 'n02095570': 189, 'n02089867': 166, 'n02009229': 131, 'n02094433': 187, 'n04154565': 784, 'n02107312': 237, 'n04372370': 844, 'n02489166': 376, 'n03482405': 588, 'n04040759': 753, 'n01774750': 76, 'n01614925': 22, 'n01855032': 98, 'n03903868': 708, 'n02422699': 352, 'n01560419': 1...(truncated), kw={}) at Objects/funcobject.c:627
#21 0x00007f36f5524236 in PyObject_Call (
func=<function at remote 0x7f36e14170d0>, arg=<optimized out>,
kw=<optimized out>) at Objects/abstract.c:2165
#22 0x00007f36f55fe234 in ext_do_call (nk=1444355432, na=0,
flags=<optimized out>, pp_stack=0x7f36c7ffc768,
func=<function at remote 0x7f36e14170d0>) at Python/ceval.c:5034
#23 PyEval_EvalFrameEx (f=<optimized out>, throwflag=<optimized out>)
at Python/ceval.c:3275
--snip--

I had similar error log, with the main process stuck on: self.data_queue.get()
For me the problem was that I used opencv as image loader. And the cv2.imread function was hanging indefinitely without error on a particular image of imagenet ("n01630670/n01630670_1010.jpeg")
If you said it's working for you with num_workers = 0 it's not that. But I thought it might help some people with similar error trace.
I'm running a test with num_workers = 0 currently, no hangs yet. I'm running the example code from https://github.com/pytorch/examples/blob/master/imagenet/main.py. pytorch/vision ImageFolder seems to use PIL or pytorch/accimage internally to load the images, so there's no OpenCV involved.
With num_workers = 4, I can occasionally get the first epoch train and validate fully, and it locks up in the middle of the second epoch. So, it is unlikely a problem in the dataset/loading function.
It looks something like a race condition in ImageLoader which might be triggered relatively rarely by a certain hardware/software combination.
@zym1010 thanks for the pointer, I'll try setting pin_memory = False too for the DataLoader.
Interesting. On my setup, setting pin_memory = False and num_workers = 4 the imagenet example hangs almost immediately and three of the workers end up as zombie processes:
root@034c4212d022:~/mnt# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
user+ 1 6.7 2.8 92167056 1876612 ? Ssl 13:50 0:36 python -m runner
user+ 38 1.9 0.0 0 0 ? Z 13:51 0:08 [python] <defunct>
user+ 39 4.3 2.3 91069804 1550736 ? Sl 13:51 0:19 python -m runner
user+ 40 2.0 0.0 0 0 ? Z 13:51 0:09 [python] <defunct>
user+ 41 4.1 0.0 0 0 ? Z 13:51 0:18 [python] <defunct>
In my setup, the dataset lies on a networked disk that is read over NFS. With pin_memory = False and num_workers = 4 I can get the system fail fairly fast.
=> creating model 'resnet18'
- training epoch 0
Epoch: [0][0/5005] Time 10.713 (10.713) Data 4.619 (4.619) Loss 6.9555 (6.9555) Prec@1 0.000 (0.000) Prec@5 0.000 (0.000)
Traceback (most recent call last):
--snip--
imagenet_pytorch.main.main([data_dir, "--transient_dir", context.transient_dir])
File "/home/user/mnt/imagenet_pytorch/main.py", line 140, in main
train(train_loader, model, criterion, optimizer, epoch, args)
File "/home/user/mnt/imagenet_pytorch/main.py", line 168, in train
for i, (input, target) in enumerate(train_loader):
File "/home/user/anaconda/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 206, in __next__
idx, batch = self.data_queue.get()
File "/home/user/anaconda/lib/python3.5/multiprocessing/queues.py", line 345, in get
return ForkingPickler.loads(res)
File "/home/user/anaconda/lib/python3.5/site-packages/torch/multiprocessing/reductions.py", line 70, in rebuild_storage_fd
fd = df.detach()
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/home/user/anaconda/lib/python3.5/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/user/anaconda/lib/python3.5/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError
:
[Errno 104] Connection reset by peer
@zym1010 do you happen to have a networked disk or a traditional spinning disk as well which might be slower in latency/etc.?
I'm using a local SSD on the compute node of cluster.The code is on a NFS drive, but the data is on the local SSD, for maximal loading speed. Never tried loading data on NFS drives.
@zym1010 Thanks for the info. I'm running this too on a compute node of a cluster.
Actually, I'm running the num_workers = 0 experiment on the same node at the same time while trying the num_workers = 4 variations. It might be that the first experiment is generating enough load so that possible race conditions manifest themselves faster in the latter.
@apaszke When you tried to reproduce this previously, did you happen to try running two instances side-by-side or with some significant other load on the system?
@jsainio Thanks for investigating this! That's weird, workers should only exit together, and once the main process is done reading the data. Can you try to inspect why do they exit prematurely? Maybe check the kernel log (dmesg)?
No, I haven't tried that, but it seemed to appear even when that wasn't the case IIRC
@apaszke Ok, good to know that the workers should not have exited.
I've tried but I don't know a good way to check why they exit. dmesg does not show anything relevant. (I'm running in a Ubuntu 16.04-derived Docker, using Anaconda packages)
One way would be to add a number of prints inside the worker loop. I have no idea why do they silently exit. It's probably not an exception, because it would have been printed to stderr, so they either break out of the loop, or get killed by the OS (perhaps by a signal?)
@jsainio, just to make sure, are you running docker with --ipc=host (you don't mention this)? Can you check the size of your shared memory segment (df -h | grep shm)?
@ngimel I'm using --shm-size=1024m. df -h | grep shm reports accordingly:
root@db92462e8c19:~/mnt# df -h | grep shm
shm 1.0G 883M 142M 87% /dev/shm
That usage seems rather high tough. This is on a docker with two zombie workers.
Can you try increasing shm size? I just checked and on the server where I tried to reproduce the problems it was 16GB. You either change the docker flag or run
mount -o remount,size=8G /dev/shm
I just tried decreasing the size to 512MB, but I got a clear error instead of a deadlock. Still can't reproduce 😕
With docker we tend to get deadlocks when shm is not enough, rather than clear error messages, don't know why. But it is usually cured by increasing shm (and I did get deadlocks with 1G).
Ok, it seems that with 10 workers an error is raised, but when I use 4 workers I get a deadlock at 58% of /dev/shm usage! I finally reproduced it

That's great that you can reproduce a form of this problem. I posted a script that triggers a hang in #1579, and you replied that it didn't hang on your system. I had actually only tested it on my MacBook. I just tried on Linux, and it didn't hang. So if you only tried on Linux, it might also be worth trying on a Mac.
Ok, so after investigating the problem it seems to be a weird issue. Even when I limit /dev/shm to be only 128MB large, Linux is happy to let us create 147MB files there, mmap them fully in memory, but will send a deadly SIGBUS to the worker once it actually tries to access the pages... I can't think of any mechanism that would allow us to check validity of the pages except for iterating over them, and touching each one, with a SIGBUS handler registered...
A workaround for now is to expand /dev/shm with the mount command as I shown above. Try with 16GB (ofc if you have enough RAM).
It's hard to find any mentions of this, but here's one.

Thanks for your time about this issue, it has been driving me nuts for a long time! If I understand correctly I need to expand /dev/shm to be 16G instead of 8G. It makes sens but when when in try df -h, I can see that all my ram is actually allocated as such : (I have 16G)
tmpfs 7,8G 393M 7,4G 5% /dev/shm
tmpfs 5,0M 4,0K 5,0M 1% /run/lock
tmpfs 7,8G 0 7,8G 0% /sys/fs/cgroup
tmpfs 1,6G 60K 1,6G 1% /run/user/1001
This is the output of df -h during a deadlock. As far as I understand, If I have a SWAP partition of 16G, I can mount tmpfs up to 32G, so it shouldn't be a problem to expand /dev/shm, right ?
More importantly, I am puzzled about the cgroup partition and its purpose since it takes nearly a half of my RAM. Apparently it's designed to manage efficiently multi-processor tasks, but I'm really not familiar with what it does and why we need it, would it change something to allocate all of physical RAM to shm (because we set its size to 16G) and put it in SWAP (although i believe both will be partly in the RAM and SWAP simultaneously)
@apaszke Thanks! Great that you found the underlying cause. I was occasionally getting both various "ConnectionReset" errors and deadlocks with docker --shm-size=1024m depending what other load there was one the machine. Testing now with --shm-size=16384m and 4 workers.
@jsainio ConnectionReset might have been caused by the same thing. The processes started exchanging some data, but once shm ran out of space a SIGBUS was sent to the worker and killed it.
@ClementPinard as far as I understand you can make it as large as you want, except that it will likely freeze your machine once you run out of RAM (because even kernel can't free this memory). You probably don't need to bother about /sys/fs/cgroup. tmpfs partitions allocate memory lazily, so as long as the usage stays at 0B, it doesn't cost you anything (including limits). I don't think using swap is a good idea, as it will make the data loading muuuuch slower, so you can try increasing the shm size to say 12GB, and limiting the number of workers (as I said, don't use all your RAM for shm!). Here's a nice writeup on tmpfs from the kernel documentation.
I don't know why the deadlock happen even when /dev/shm usage is very small (happens at 20kB on my machine). Perhaps the kernel is overly optimistic, but doesn't wait until you fill it all, and kills the process once it starts using anything from this region.
Testing now with 12G and half the workers I had, and it failed :(
It was working like a charm in lua torch version (same speed, same number of workers) , which makes me wonder if the problem is only /dev/shmrelated and not closer to python multiprocessing...
The odd thing about it (as you mentionned) is that /dev/shmis never close to be full. During first training epoch, it never went above 500Mo. And It also never locks during first epoch, and if I shut down testing trainloader never fails across all the epochs. The deadlock seems to only appear when beginning test epoch. I should keep track of /dev/shm when going from train to test, maybe there is a peak usage during dataloaders changing.
@ClementPinard even with higher shared memory, and without Docker, it can still fail.
If torch version == Lua Torch, then it still might be related to /dev/shm. Lua Torch can use threads (there's no GIL), so it doesn't need to go through shared mem (they all share a single address space).

I had the same issue where the dataloader crashes after complaining that it could not allocate memory at the beginning of a new training or validation epoch. The solutions above did not work for me (i) my /dev/shm is 32GB and it was never used more than 2.5GB, and (ii) setting pin_memory=False did not work.
This is perhaps something to do with garbage collection? My code looks roughly like the following. I need an infinite iterator and hence I do a try / except around the next() below :-)
def train():
train_iter = train_loader.__iter__()
for i in xrange(max_batches):
try:
x, y = next(train_iter)
except StopIteration:
train_iter = train_loader.__iter__()
...
del train_iter
train_loader is a DataLoader object. Without the explicit del train_iter line at the end of the function, the process always crashes after 2-3 epochs (/dev/shm still shows 2.5 GB). Hope this helps!
I am using 4 workers (version 0.1.12_2 with CUDA 8.0 on Ubuntu 16.04).

I also met the deadlock, especially when the work_number is large. Is there any possible solution for this problem? My /dev/shm size is 32GB, with cuda 7.5, pytorch 0.1.12 and python 2.7.13. The following is related info after death. It seems related to memory. @apaszke

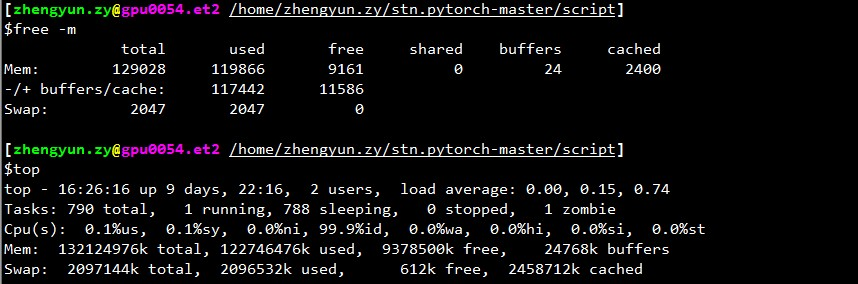
@zhengyunqq try pin_memory=False if you set it to True. Otherwise, I'm not aware of any solution.

I have also met the deadlock when num_workers is large.

For me, the problem was that if a worker thread dies for whatever reason, then index_queue.put hangs forever. One reason of working threads dying is unpickler failing during initialization. In that case, until this Python bugfix in master in May 2017, the worker thread would die and cause the endless hang. In my case, the hang was happening in batch pre-fetching priming stage.
Maybe a replacement of SimpleQueue used in DataLoaderIter by Queue which allows for a timeout with a graceful exception message.
UPD: I was mistaken, this bugfix patches Queue, not SimpleQueue. It's still true that SimpleQueue will lock if no worker threads are online. An easy way to check that is replacing these lines with self.workers = [].

i have the same problem, and i can't change shm(without permission), maybe it's better to use Queue or something else?

I have a similar problem.
This code will freeze and never print anything. If I set num_workers=0 it will work though
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
model.cuda()
for i, batch in enumerate(dataloader):
print(i)
If I put model.cuda() behind the loop, everything will run fine.
dataloader = DataLoader(transformed_dataset, batch_size=2, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i)
model.cuda()
Does anyone have a solution for that problem?

I have run into similar issues as well while training ImageNet. It will hang at the 1st iteration of evaluation consistently on certain servers with certain architecture (and not on other servers with the same architecture or the same server with different architecture), but always the 1st iter during eval on validation. When I was using Torch, we found nccl can cause deadlock like this, is there way to turn it off?

I'm facing the same issue,randomly getting stuck at the start of 1st epoch.All the workarounds mentioned above don't work for me.When Ctrl-C is pressed, it prints these:
Traceback (most recent call last):
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 44, in _worker_loop
data_queue.put((idx, samples))
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/queues.py", line 354, in put
self._writer.send_bytes(obj)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 398, in _send_bytes
self._send(buf)
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
KeyboardInterrupt
Traceback (most recent call last):
File "scripts/train_model.py", line 640, in <module>
main(args)
File "scripts/train_model.py", line 193, in main
train_loop(args, train_loader, val_loader)
File "scripts/train_model.py", line 341, in train_loop
ee_optimizer.step()
File "/home/zhangheng_li/applications/anaconda3/lib/python3.6/site-packages/torch/optim/adam.py", line 74, in step
p.data.addcdiv_(-step_size, exp_avg, denom)
KeyboardInterrupt

I had a similar problem of having a deadlock with a single worker inside docker and I can confirm that it was the shared memory issue in my case. By default docker only seems to allocate 64MB of shared memory, however I needed 440MB for 1 worker, which probably caused the behavior described by @apaszke.

I am being troubled by the same problem, yet I'am under a different environment from most others in this thread, so maybe my inputs can help locating the underlying cause. My pytorch is installed using the excellent conda package built by peterjc123 under Windows10.
I am running some cnn on the cifar10 dataset. For the dataloaders, num_workers is set to 1. Although having num_workers > 0 is known to cause BrokenPipeError and advised against in #494, what I am experiencing is not BrokenPipeError but some memory allocation error. The error always occurred at around 50 epochs, right after the validation of the last epoch and before the start of training for the next epoch. 90% of the time it's precisely 50 epochs, other times it will be off by 1 or 2 epochs. Other than that everything else is pretty consistent. Setting num_workers=0 will eliminate this problem.

@paulguerrero is right. I solved this problem by increasing the shared memory from 64M to 2G. Maybe it's useful to docker users.

@berzjackson That's a known bug in the conda package. Fixed in the latest CI builds.

We have ~600 people that started a new course that uses Pytorch on Monday. A lot of folks on our forum are reporting this problem. Some on AWS P2, some on their own systems (mainly GTX 1070, some Titan X).
When they interrupt training the end of the stack trace shows:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv_bytes(self, maxsize)
405
406 def _recv_bytes(self, maxsize=None):
--> 407 buf = self._recv(4)
408 size, = struct.unpack("!i", buf.getvalue())
409 if maxsize is not None and size > maxsize:
~/anaconda2/envs/fastai/lib/python3.6/multiprocessing/connection.py in _recv(self, size, read)
377 remaining = size
378 while remaining > 0:
--> 379 chunk = read(handle, remaining)
380 n = len(chunk)
381 if n == 0:
We have num_workers=4, pin_memory=False. I've asked them to check their shared memory settings - but is there anything I can do (or we could do in Pytorch) to make this problem go away? (Other than reducing num_workers, since that would slow things down quite a bit.)

I'm in the class @jph00 (thanks Jeremy! :) ) referred to. I tried using "num_workers=0" as well. Still get the same error where resnet34 loads very slowly. The fitting is also very slow. But weird thing: this only happens once in the lifetime of a notebook session.
In other words, once the data is loaded, and the fitting is run once, I can move around and keep repeating the steps... even with 4 num_workers, and everything seems to work fast as expected in a GPU.
I'm on PyTorch 0.2.0_4, Python 3.6.2, Torchvision 0.1.9, Ubuntu 16.04 LTS. Doing "df -h" on my terminal says that I've 16GBs on /dev/shm, although the utilization was very low.
Here's a screenshot of where the loading fails (note I've used num_workers=0 for the data)
(sorry about the small letters. I had to zoom out to capture everything...)

@apiltamang I'm not sure that's the same issue - it doesn't sound like the same symptoms at all. Best for us to diagnose that on the fast.ai forum, not here.

looking into this ASAP!

@ssnl one of the students has confirmed they've increased shared memory, and still have the problem. I've asked some others to confirm too.
@jph00 Thanks! I successfully reproduced the hang due to low shared memory. If the issue lies in elsewhere I'll have to dig deeper! Do you mind share the script with me?
Sure - here's the notebook we're using: https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb . The students have noticed that the problem only occurs when they run all the cells in the order they're in the notebook. Hopefully the notebook is self-explanatory, but let me know if you have any trouble running it - it includes a link to download the necessary data.
Based on the shared memory issue you could replicate, is there any kind of workaround I could add to our library or notebook that would avoid it?
@jph00 Diving into the code right now. I'll try to spot ways to reduce shared memory usage. It doesn't seem that the script should use large amount of shm, so there is hope!
I'll also send out a PR to show a nice error message upon hitting shm limit rather than just letting it hang.
OK I've replicated the problem on a fresh AWS P2 instance using their CUDA 9 AMI with latest Pytorch conda install. If you provide your public key, I can give you access to try it out directly. My email is the first letter of my first name at fast.ai
@jph00 Just sent you an email :) thanks!
@jph00 And FYI, the script took 400MB shared memory on my box. So it'd be great for students who had this issue to check they have enough free shm.
OK so I've figured out the basic issue, which is that opencv and Pytorch multiprocessing don't play well together, sometimes. No problems on our box at university, but lots of problems on AWS (on the new deep learning CUDA 9 AMI with P2 instance). Adding locking around all cv2 calls doesn't fix it, and adding cv2.setNumThreads(0) doesn't fix. This seems to fix it:
from multiprocessing import set_start_method
set_start_method('spawn')
However that impacts performance by about 15%. The recommendation in the opencv github issue is to use https://github.com/tomMoral/loky . I've used that module before and found it rock-solid. Not urgent, since we've got a solution that works well enough for now - but might be worth considering using Loky for Dataloader?
Perhaps more importantly, it would be nice if at least there was some kind of timeout in pytorch's queue so that these infinite hangs would get caught.
FYI, I just tried a different fix, since 'spawn' was making some parts 2-3x slower - which is that I added a few random sleeps in sections that iterate through the dataloader quickly. That also fixed the problem - although perhaps not ideal!
Thanks for digging into this! Glad to know that you've found two workarounds. Indeed it would be good to add timeouts on indexing into datasets. We will discuss and get back to you on that route tomorrow.
cc @soumith is loky something we want to investigate?
For people who come to this thread for above discussion, the opencv issue is discussed in greater depth at opencv/opencv#5150
OK I seem to have a proper fix for this now - I've rewritten Dataloader to user ProcessPoolExecutor.map() and moved the creation of the tensor into the parent process. The result is faster than I was seeing with the original Dataloader, and it's been stable on all the computers I've tried it on. The code is also a lot simpler.
If anyone is interested in using it, you can get it from https://github.com/fastai/fastai/blob/master/fastai/dataloader.py .
The API is the same as the standard version, except that your Dataset must not return a Pytorch tensor - it should return numpy arrays or python lists. I haven't made any attempt to make it work on older Pythons, so I wouldn't be surprised if there's some issues there.
(The reason I've gone down this path is that I found when doing a lot of image processing/augmentation on recent GPUs that I couldn't complete the processing fast enough to keep the GPU busy, if I did the preprocessing using Pytorch CPU operations; however using opencv was much faster, and I was able to fully utilize the GPU as a result.)
Oh if it's an opencv issue then there's not a lot we can do about it. It's true that forking is dangerous when you have thread pools. I don't think we want to add a runtime dependency (currently we have none), especially that it won't handle PyTorch tensors nicely. It would be better to just figure out what's causing the deadlocks and @ssnl is on it.
@jph00 have you tried Pillow-SIMD? It should work with torchvision out of the box and I have heard many good things about it.
Yes I know pillow-SIMD well. It only speeds up resize, blur, and RGB conversion.
I don't agree there's not a lot you can do here. It's not exactly an opencv issue (they don't claim to support this type of python multiprocessing more generally, let alone pytorch's special-cased multi-processing module) and not exactly a Pytorch issue either. But the fact that Pytorch silently waits for ever without giving any kind of error is (IMO) something you can fix, and more generally a lot of smart folks have been working hard over the last few years to create improved multiprocessing approaches which avoid problems just like this one. You could borrow from the approaches they use without bringing in an external dependency.
Olivier Grisel, who is one of the folks behind Loky, has a great slide deck summarizing the state of multiprocessing in Python: http://ogrisel.github.io/decks/2017_euroscipy_parallelism/
I don't mind either way, since I've now written a new Dataloader that doesn't have the problem. But I do, FWIW, suspect that interactions between pytorch's multiprocessing and other systems will be an issue for other folks too in the future.

For what it's worth, I had this issue on Python 2.7 on ubuntu 14.04. My data loader read from a sqlite database and worked perfectly with num_workers=0, sometimes seemed OK with num_workers=1, and very quickly deadlocked for any higher value. Stack traces showed the process hung in recv_bytes.
Things that didn't work:
- Passing
--shm-size 8Gor--ipc=hostwhen launching docker - Running
echo 16834 | sudo tee /proc/sys/kernel/shmmnito increase the number of shared memory segments (the default was 4096 on my machine) - Setting
pin_memory=Trueorpin_memory=False, neither one helped
The thing that reliably fixed my issue was porting my code to Python 3. Launching the same version of Torch inside a Python 3.6 instance (from Anaconda) completely fixed my issue and now data loading doesn't hang anymore.
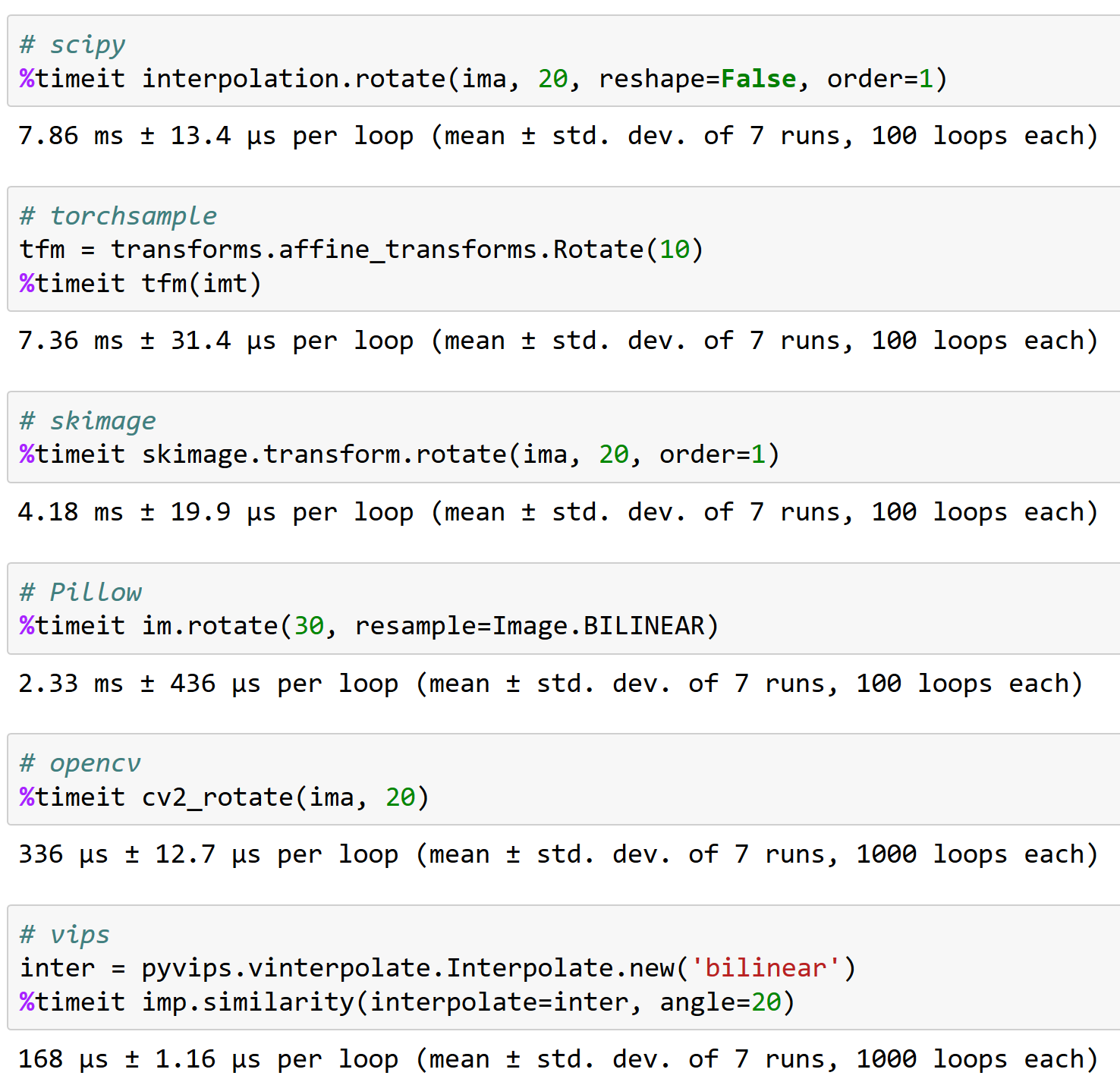
@apaszke here's why working well with opencv is important, FYI (and why torchsample isn't a great option - it can handle rotation of <200 images/sec!):

Did anyone find a solution to this problem?

@Iqbalu Try the script above: https://github.com/fastai/fastai/blob/master/fastai/dataloader.py
It solved my issue but it doesn't support num_workers=0.
@elbaro actually I tried it and in my case it was not using multiple workers at all. Did you change anything there?
@Iqbalu fast.ai data loader never spawns worker processes. It only uses threads, so they might not show up in some tools
It's likely data loader uses packages that don't give up the GIL
@apaszke any idea why the usage of shared-memory keeps increasing after some epochs. In my case, it starts with 400MB and then every ~20th epoch increases by 400MB. Thanks!
@Iqbalu not really. That shouldn't be happening


I have been troubled by this problem recently. cv2.setNumThreads(0) doesn't work for me. I even change all cv2 code to use scikit-image instead, but the problem still exists. Besides, I have 16G for /dev/shm. I only have this problem when using multiple gpus. Every thing works fine on single gpu. Do anyone has any new thoughts on the solution?

Same Error. I have this problem when using single gpu.

For me disabling opencv threads solved the problem:
cv2.setNumThreads(0)

hit it too with pytorch 0.3, cuda 8.0, ubuntu 16.04
no opencv used.