linguo

Motivation
This work was done as part of The New York Times R&D(nytlabs) internship in July, 2014.
The result was Editor.
Editor is an experimental text editing interface that explores how collaboration between machine learning systems and journalists could afford fine-grained annotation and tagging of news articles. Our approach applies machine learning techniques interactively, as part of the writing process, rather than retroactively. This approach can offload the burden of work to the computational processes, and can create affordances for journalists to augment, edit and correct those processes with their knowledge.
You can view it in use here:
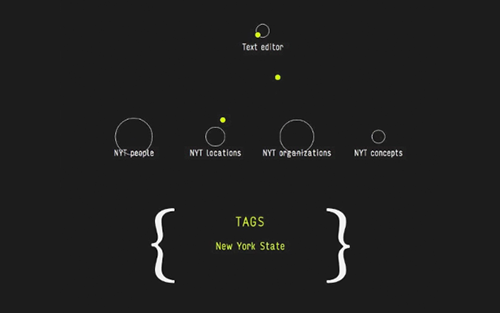
Repository Description
linguo is a set of microservices that provide Natural Language Processing abilities for text editors.
Note: Most of the problems have been well researched since 2014, so there are better libraries available to perform the same task. The libraries like goose and reporter are some of the other libraries.
Editor used following microservices.
-
times_tagger : This folder contains scripts to tag articles with tags from the Times. More information is inside the folder.
-
sentence_segmentation : Scripts in this folder implements a web service to identify sentences from a body of text.
-
keyword_extraction : Scripts in this folder are aimed at extraction of keywords from urls.
-
text_classifier : It is an attempt to classify articles into labels as given in Times taxonomy. Multi-Label Classification is done by using Google's Word2Vec representation of word as 100 dimensional vectors.
As part of another experiment to find the topics of discussion in the lab, I implemented Topic Tracker which performs LDA on the content extracted from different URLs being visited.
-
topic_tracker : It is an attempt to summarize topics that are being read by an individual or a group of people.
-
html_text_extractor : Given an url, it contains massive amount of text but not all text contains core information (about which the page is). This is an attempt to build a classifier on p tags in html to classify if its good or bad.
- usefulScripts : It contains all the scripts which were helpful in preprocessing articles, querying mongoDB or experimenting with LDA.
app.py script combines all the services.