openvino/workbench 2022.1 grays out gpu option on 8th generation intel core i7
dnoliver opened this issue · comments

NOTE: 11th gen Core works fine
We only see this issue with the 'ssdlite_mobilenet_v2' model, but not with caffenet
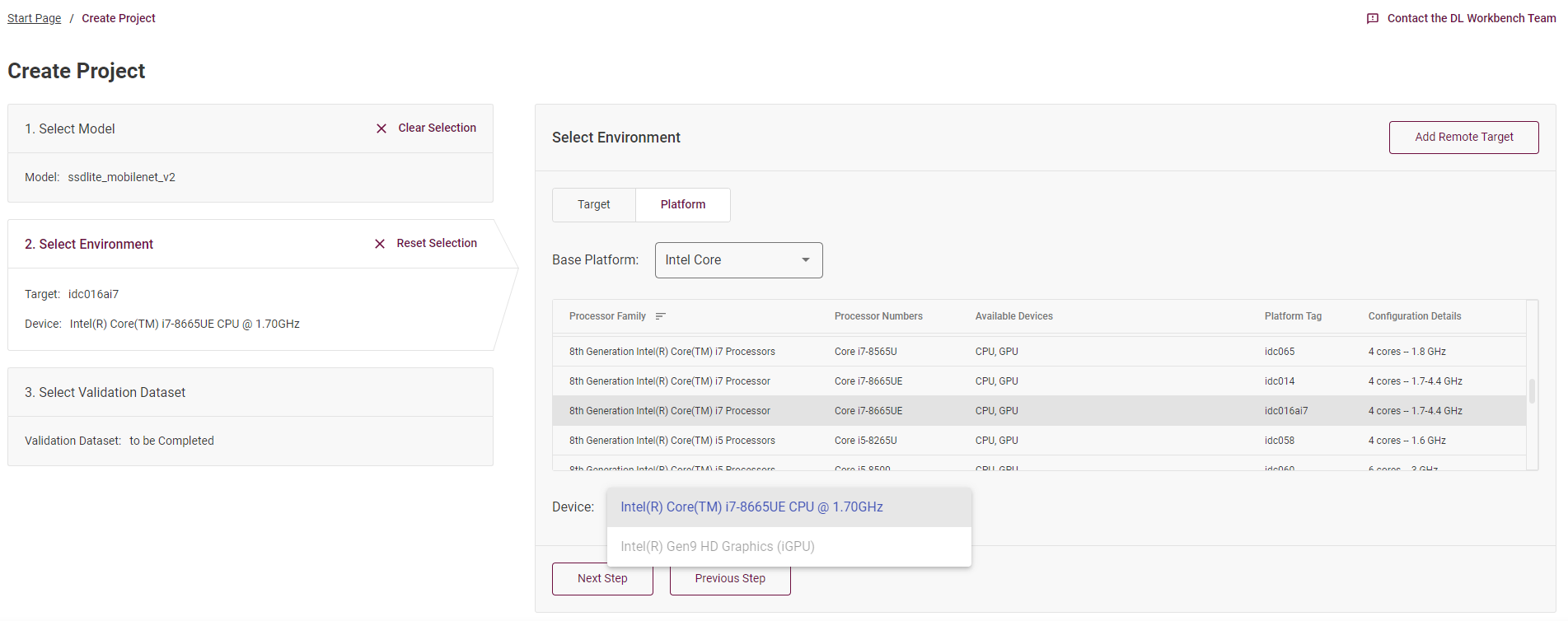
Is this behavior expected?

Hello @dnoliver! Thank you for using the tool.
Can you explain what exactly ssdlite_mobilenet_v2 Do you use? Does it contains I8 operations?
Hi!
Sorry, I had so many Github notifications that I am missing important stuff.
This was reported to us by a user. I am not sure which is the purpose of that model.
This was originally reported by @whitneyfoster, maybe she will have additional information and follow up with you on this issue.

@artyomtugaryov This is the ssdlit_mobilenet_v2 model that is in from the OMZ and available to download and convert within DL Workbench: https://docs.openvino.ai/latest/omz_models_model_ssdlite_mobilenet_v2.html
Looks like the model contains precisions that are not supported by the GPU, for example int8.
Why can I select GPU on TGL systems then? Also I thought that while GPU was not optimized for int8, you can still run int8 on GPU.
I am also able to run the model locally on my Intel(R) Core(TM) i5-7300U GPU.
C:\Users\wfoster\Downloads>benchmark_app -m C:\Users\wfoster\Downloads\public\ssdlite_mobilenet_v2\FP32\ssdlite_mobilenet_v2.xml -d GPU
[Step 1/11] Parsing and validating input arguments
[ WARNING ] -nstreams default value is determined automatically for a device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 2/11] Loading OpenVINO
[ WARNING ] PerformanceMode was not explicitly specified in command line. Device GPU performance hint will be set to THROUGHPUT.
[ INFO ] OpenVINO:
API version............. 2022.1.0-7019-cdb9bec7210-releases/2022/1
[ INFO ] Device info
GPU
Intel GPU plugin........ version 2022.1
Build................... 2022.1.0-7019-cdb9bec7210-releases/2022/1
[Step 3/11] Setting device configuration
[ WARNING ] -nstreams default value is determined automatically for GPU device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 4/11] Reading network files
[ INFO ] Read model took 95.83 ms
[Step 5/11] Resizing network to match image sizes and given batch
[ INFO ] Network batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model input 'image_tensor' precision u8, dimensions ([N,H,W,C]): 1 300 300 3
[ INFO ] Model output 'detection_boxes' precision f32, dimensions ([...]): 1 1 100 7
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 14100.89 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] DEVICE: GPU
[ INFO ] AVAILABLE_DEVICES , ['0']
[ INFO ] RANGE_FOR_ASYNC_INFER_REQUESTS , (1, 2, 1)
[ INFO ] RANGE_FOR_STREAMS , (1, 2)
[ INFO ] OPTIMAL_BATCH_SIZE , 1
[ INFO ] MAX_BATCH_SIZE , 1
[ INFO ] FULL_DEVICE_NAME , Intel(R) HD Graphics 620 (iGPU)
[ INFO ] OPTIMIZATION_CAPABILITIES , ['FP32', 'BIN', 'FP16']
[ INFO ] GPU_UARCH_VERSION , 9.0.0
[ INFO ] GPU_EXECUTION_UNITS_COUNT , 24
[ INFO ] PERF_COUNT , False
[ INFO ] GPU_ENABLE_LOOP_UNROLLING , True
[ INFO ] CACHE_DIR ,
[ INFO ] COMPILATION_NUM_THREADS , 4
[ INFO ] NUM_STREAMS , 1
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS , 0
[ INFO ] DEVICE_ID , 0
[Step 9/11] Creating infer requests and preparing input data
[ INFO ] Create 2 infer requests took 4.00 ms
[ WARNING ] No input files were given for input 'image_tensor'!. This input will be filled with random values!
[ INFO ] Fill input 'image_tensor' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 2 inference requests using 1 streams for GPU, inference only: True, limits: 60000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 28.61 ms
[Step 11/11] Dumping statistics report
Count: 3338 iterations
Duration: 60064.57 ms
Latency:
Median: 35.03 ms
AVG: 35.91 ms
MIN: 25.57 ms
MAX: 164.72 ms
Throughput: 55.57 FPS
C:\Users\wfoster\Downloads>benchmark_app -m C:\Users\wfoster\Downloads\public\ssdlite_mobilenet_v2\FP16\ssdlite_mobilenet_v2.xml -d GPU
[Step 1/11] Parsing and validating input arguments
[ WARNING ] -nstreams default value is determined automatically for a device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 2/11] Loading OpenVINO
[ WARNING ] PerformanceMode was not explicitly specified in command line. Device GPU performance hint will be set to THROUGHPUT.
[ INFO ] OpenVINO:
API version............. 2022.1.0-7019-cdb9bec7210-releases/2022/1
[ INFO ] Device info
GPU
Intel GPU plugin........ version 2022.1
Build................... 2022.1.0-7019-cdb9bec7210-releases/2022/1
[Step 3/11] Setting device configuration
[ WARNING ] -nstreams default value is determined automatically for GPU device. Although the automatic selection usually provides a reasonable performance, but it still may be non-optimal for some cases, for more information look at README.
[Step 4/11] Reading network files
[ INFO ] Read model took 68.75 ms
[Step 5/11] Resizing network to match image sizes and given batch
[ INFO ] Network batch size: 1
[Step 6/11] Configuring input of the model
[ INFO ] Model input 'image_tensor' precision u8, dimensions ([N,H,W,C]): 1 300 300 3
[ INFO ] Model output 'detection_boxes' precision f32, dimensions ([...]): 1 1 100 7
[Step 7/11] Loading the model to the device
[ INFO ] Compile model took 17612.33 ms
[Step 8/11] Querying optimal runtime parameters
[ INFO ] DEVICE: GPU
[ INFO ] AVAILABLE_DEVICES , ['0']
[ INFO ] RANGE_FOR_ASYNC_INFER_REQUESTS , (1, 2, 1)
[ INFO ] RANGE_FOR_STREAMS , (1, 2)
[ INFO ] OPTIMAL_BATCH_SIZE , 1
[ INFO ] MAX_BATCH_SIZE , 1
[ INFO ] FULL_DEVICE_NAME , Intel(R) HD Graphics 620 (iGPU)
[ INFO ] OPTIMIZATION_CAPABILITIES , ['FP32', 'BIN', 'FP16']
[ INFO ] GPU_UARCH_VERSION , 9.0.0
[ INFO ] GPU_EXECUTION_UNITS_COUNT , 24
[ INFO ] PERF_COUNT , False
[ INFO ] GPU_ENABLE_LOOP_UNROLLING , True
[ INFO ] CACHE_DIR ,
[ INFO ] COMPILATION_NUM_THREADS , 4
[ INFO ] NUM_STREAMS , 1
[ INFO ] PERFORMANCE_HINT_NUM_REQUESTS , 0
[ INFO ] DEVICE_ID , 0
[Step 9/11] Creating infer requests and preparing input data
[ INFO ] Create 2 infer requests took 2.00 ms
[ WARNING ] No input files were given for input 'image_tensor'!. This input will be filled with random values!
[ INFO ] Fill input 'image_tensor' with random values
[Step 10/11] Measuring performance (Start inference asynchronously, 2 inference requests using 1 streams for GPU, inference only: True, limits: 60000 ms duration)
[ INFO ] Benchmarking in inference only mode (inputs filling are not included in measurement loop).
[ INFO ] First inference took 13.62 ms
[Step 11/11] Dumping statistics report
Count: 5074 iterations
Duration: 60041.18 ms
Latency:
Median: 22.59 ms
AVG: 23.59 ms
MIN: 9.77 ms
MAX: 158.04 ms
Throughput: 84.51 FPS