JavaScript专题之数组去重
mqyqingfeng opened this issue · comments

前言
数组去重方法老生常谈,既然是常谈,我也来谈谈。
双层循环
也许我们首先想到的是使用 indexOf 来循环判断一遍,但在这个方法之前,让我们先看看最原始的方法:
var array = [1, 1, '1', '1'];
function unique(array) {
// res用来存储结果
var res = [];
for (var i = 0, arrayLen = array.length; i < arrayLen; i++) {
for (var j = 0, resLen = res.length; j < resLen; j++ ) {
if (array[i] === res[j]) {
break;
}
}
// 如果array[i]是唯一的,那么执行完循环,j等于resLen
if (j === resLen) {
res.push(array[i])
}
}
return res;
}
console.log(unique(array)); // [1, "1"]在这个方法中,我们使用循环嵌套,最外层循环 array,里面循环 res,如果 array[i] 的值跟 res[j] 的值相等,就跳出循环,如果都不等于,说明元素是唯一的,这时候 j 的值就会等于 res 的长度,根据这个特点进行判断,将值添加进 res。
看起来很简单吧,之所以要讲一讲这个方法,是因为——————兼容性好!
indexOf
我们可以用 indexOf 简化内层的循环:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
for (var i = 0, len = array.length; i < len; i++) {
var current = array[i];
if (res.indexOf(current) === -1) {
res.push(current)
}
}
return res;
}
console.log(unique(array));排序后去重
试想我们先将要去重的数组使用 sort 方法排序后,相同的值就会被排在一起,然后我们就可以只判断当前元素与上一个元素是否相同,相同就说明重复,不相同就添加进 res,让我们写个 demo:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
var sortedArray = array.concat().sort();
var seen;
for (var i = 0, len = sortedArray.length; i < len; i++) {
// 如果是第一个元素或者相邻的元素不相同
if (!i || seen !== sortedArray[i]) {
res.push(sortedArray[i])
}
seen = sortedArray[i];
}
return res;
}
console.log(unique(array));如果我们对一个已经排好序的数组去重,这种方法效率肯定高于使用 indexOf。
unique API
知道了这两种方法后,我们可以去尝试写一个名为 unique 的工具函数,我们根据一个参数 isSorted 判断传入的数组是否是已排序的,如果为 true,我们就判断相邻元素是否相同,如果为 false,我们就使用 indexOf 进行判断
var array1 = [1, 2, '1', 2, 1];
var array2 = [1, 1, '1', 2, 2];
// 第一版
function unique(array, isSorted) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
if (isSorted) {
if (!i || seen !== value) {
res.push(value)
}
seen = value;
}
else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
console.log(unique(array1)); // [1, 2, "1"]
console.log(unique(array2, true)); // [1, "1", 2]优化
尽管 unqique 已经可以试下去重功能,但是为了让这个 API 更加强大,我们来考虑一个需求:
新需求:字母的大小写视为一致,比如'a'和'A',保留一个就可以了!
虽然我们可以先处理数组中的所有数据,比如将所有的字母转成小写,然后再传入unique函数,但是有没有方法可以省掉处理数组的这一遍循环,直接就在去重的循环中做呢?让我们去完成这个需求:
var array3 = [1, 1, 'a', 'A', 2, 2];
// 第二版
// iteratee 英文释义:迭代 重复
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed) {
res.push(value)
}
seen = computed;
}
else if (iteratee) {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}
else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
console.log(unique(array3, false, function(item){
return typeof item == 'string' ? item.toLowerCase() : item
})); // [1, "a", 2]在这一版也是最后一版的实现中,函数传递三个参数:
array:表示要去重的数组,必填
isSorted:表示函数传入的数组是否已排过序,如果为 true,将会采用更快的方法进行去重
iteratee:传入一个函数,可以对每个元素进行重新的计算,然后根据处理的结果进行去重
至此,我们已经仿照着 underscore 的思路写了一个 unique 函数,具体可以查看 Github。
filter
ES5 提供了 filter 方法,我们可以用来简化外层循环:
比如使用 indexOf 的方法:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var res = array.filter(function(item, index, array){
return array.indexOf(item) === index;
})
return res;
}
console.log(unique(array));排序去重的方法:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
return array.concat().sort().filter(function(item, index, array){
return !index || item !== array[index - 1]
})
}
console.log(unique(array));Object 键值对
去重的方法众多,尽管我们已经跟着 underscore 写了一个 unqiue API,但是让我们看看其他的方法拓展下视野:
这种方法是利用一个空的 Object 对象,我们把数组的值存成 Object 的 key 值,比如 Object[value1] = true,在判断另一个值的时候,如果 Object[value2]存在的话,就说明该值是重复的。示例代码如下:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
return obj.hasOwnProperty(item) ? false : (obj[item] = true)
})
}
console.log(unique(array)); // [1, 2]我们可以发现,是有问题的,因为 1 和 '1' 是不同的,但是这种方法会判断为同一个值,这是因为对象的键值只能是字符串,所以我们可以使用 typeof item + item 拼成字符串作为 key 值来避免这个问题:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
})
}
console.log(unique(array)); // [1, 2, "1"]然而,即便如此,我们依然无法正确区分出两个对象,比如 {value: 1} 和 {value: 2},因为 typeof item + item 的结果都会是 object[object Object],不过我们可以使用 JSON.stringify 将对象序列化:
var array = [{value: 1}, {value: 1}, {value: 2}];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
console.log(typeof item + JSON.stringify(item))
return obj.hasOwnProperty(typeof item + JSON.stringify(item)) ? false : (obj[typeof item + JSON.stringify(item)] = true)
})
}
console.log(unique(array)); // [{value: 1}, {value: 2}]看似已经万无一失,但考虑到 JSON.stringify 任何一个正则表达式的结果都是 {},所以这个方法并不适用于处理正则表达式去重。(引用勘误 )
console.log(JSON.stringify(/a/)); // {}
console.log(JSON.stringify(/b/)); // {}ES6
随着 ES6 的到来,去重的方法又有了进展,比如我们可以使用 Set 和 Map 数据结构,以 Set 为例,ES6 提供了新的数据结构 Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
是不是感觉就像是为去重而准备的?让我们来写一版:
var array = [1, 2, 1, 1, '1'];
function unique(array) {
return Array.from(new Set(array));
}
console.log(unique(array)); // [1, 2, "1"]甚至可以再简化下:
function unique(array) {
return [...new Set(array)];
}还可以再简化下:
var unique = (a) => [...new Set(a)]此外,如果用 Map 的话:
function unique (arr) {
const seen = new Map()
return arr.filter((a) => !seen.has(a) && seen.set(a, 1))
}JavaScript 的进化
我们可以看到,去重方法从原始的 14 行代码到 ES6 的 1 行代码,其实也说明了 JavaScript 这门语言在不停的进步,相信以后的开发也会越来越高效。
特殊类型比较
去重的方法就到此结束了,然而要去重的元素类型可能是多种多样,除了例子中简单的 1 和 '1' 之外,其实还有 null、undefined、NaN、对象等,那么对于这些元素,之前的这些方法的去重结果又是怎样呢?
在此之前,先让我们先看几个例子:
var str1 = '1';
var str2 = new String('1');
console.log(str1 == str2); // true
console.log(str1 === str2); // false
console.log(null == null); // true
console.log(null === null); // true
console.log(undefined == undefined); // true
console.log(undefined === undefined); // true
console.log(NaN == NaN); // false
console.log(NaN === NaN); // false
console.log(/a/ == /a/); // false
console.log(/a/ === /a/); // false
console.log({} == {}); // false
console.log({} === {}); // false那么,对于这样一个数组
var array = [1, 1, '1', '1', null, null, undefined, undefined, new String('1'), new String('1'), /a/, /a/, NaN, NaN];以上各种方法去重的结果到底是什么样的呢?
我特地整理了一个列表,我们重点关注下对象和 NaN 的去重情况:
| 方法 | 结果 | 说明 |
|---|---|---|
| for循环 | [1, "1", null, undefined, String, String, /a/, /a/, NaN, NaN] | 对象和 NaN 不去重 |
| indexOf | [1, "1", null, undefined, String, String, /a/, /a/, NaN, NaN] | 对象和 NaN 不去重 |
| sort | [/a/, /a/, "1", 1, String, 1, String, NaN, NaN, null, undefined] | 对象和 NaN 不去重 数字 1 也不去重 |
| filter + indexOf | [1, "1", null, undefined, String, String, /a/, /a/] | 对象不去重 NaN 会被忽略掉 |
| filter + sort | [/a/, /a/, "1", 1, String, 1, String, NaN, NaN, null, undefined] | 对象和 NaN 不去重 数字 1 不去重 |
| 优化后的键值对方法 | [1, "1", null, undefined, String, /a/, NaN] | 全部去重 |
| Set | [1, "1", null, undefined, String, String, /a/, /a/, NaN] | 对象不去重 NaN 去重 |
这里再次声明一下,键值对方法不能去重正则表达式。
想了解为什么会出现以上的结果,看两个 demo 便能明白:
// demo1
var arr = [1, 2, NaN];
arr.indexOf(NaN); // -1indexOf 底层还是使用 === 进行判断,因为 NaN === NaN的结果为 false,所以使用 indexOf 查找不到 NaN 元素
// demo2
function unique(array) {
return Array.from(new Set(array));
}
console.log(unique([NaN, NaN])) // [NaN]Set 认为尽管 NaN === NaN 为 false,但是这两个元素是重复的。
写在最后
虽然去重的结果有所不同,但更重要的是让我们知道在合适的场景要选择合适的方法。
专题系列
JavaScript专题系列目录地址:https://github.com/mqyqingfeng/Blog。
JavaScript专题系列预计写二十篇左右,主要研究日常开发中一些功能点的实现,比如防抖、节流、去重、类型判断、拷贝、最值、扁平、柯里、递归、乱序、排序等,特点是研(chao)究(xi) underscore 和 jQuery 的实现方式。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。

赞

有个小问题,关于排序后去重的下面的代码,var sortedArray = array.concat().sort(); 这个concat()在这里的意义是什么?不是很理解~

@zeroone001 你对数组进行了 array.concat()操作之后,相当于复制出来一份原有的数组,且对复制出来的新数组的操作不会影响到原有数组,但是上面的这个去重的方法是有问题的,对有些数组就无法排序
建议文章中对于用到sort来进行排序的地方都看一下,这些地方的排序的方法是有错误的
@jochenshi 感谢回答哈,全文只有 sort 排序那里使用了排序,sort 排序的结果并不总是正确的,从文章最后的特殊类型排序结果表中,也可以看出,我应该专门注明这个问题的。sort 之所以会出错,还是因为 sort 的原理所致,我会在这个系列的大约第 19 篇中讲讲 V8 的排序源码。之所以写排序去重,是为了引出 underscore 的 unique API,在这个 API 中,如果是处理已排序好的数组,就可以传 true,使用更快的去重方法,而数组是怎么排序的,underscore 并不提供,为了演示排序去重的原理,我才简便的使用了 sort 方法,对数组进行了排序,因为使用了 sort,当涉及到特殊类型时,会出现问题,只能说明使用的场景其实是有限的,也不能说就是错误的,当然真到项目开发中,还是要用类似 underscore、lodash 提供的功能。最后感谢指出哈~ o( ̄▽ ̄)d

第二版是不是逻辑不太清晰,应该修改为
var array3 = [1, 1, 'a', 'A', 2, 2];
// 第二版
// iteratee 英文释义:迭代 重复
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed ) {
res.push(computed )
}
seen = computed ;
}
else if (res.indexOf(computed ) === -1) {
res.push(computed );
}
}
return res;
}
console.log(unique(array3, false, function(item){
return typeof item == 'string' ? item.toLowerCase() : item
})); // [1, "a", 2]
如果指出有错误,还请见谅。
@YeaseonZhang 两个函数实现的效果不一样哈~ 举个例子:
var array = [{value: 1}, {value: 2}, {value: 1}];
console.log(unique(array, false, function(item){
return item.value
}));如果使用文章中的方法,结果会是 [{value: 1}, {value: 2}]
如果使用你的方法,结果会是 [1, 2]
区别在于使用迭代函数处理后的元素,去重后,是返回以前的元素还是计算后的元素。
无所谓对错,看你想设计成什么样子。
@mqyqingfeng 谢谢回复,确实像你给出的那个例子一样。

请教大神一个问题,为什么正则/a/相等和全等都是false呢
@FrontToEnd 因为在 JavaScript 中,正则表达式也是对象。
@mqyqingfeng 谢谢提醒,差点忘了。😯

多维数组如何去重呢?

@suihaohao 递归
@suihaohao 也可以先扁平再去重,关于扁平化: JavaScript专题之数组扁平化
扁平之后再去重那就不是多维数组了吧,但是我想要的是去重之后仍然是多维数组呢?
@suihaohao 如果是这样的话,遍历的时候判断元素是否是数组,然后递归使用 unique 函数,类似于这样:
var array = [1, 2, 1, [1, 1, 2], [3, 3, 4]];
function unique(array) {
var res = [];
for (var i = 0, len = array.length; i < len; i++) {
var current = array[i];
if (Array.isArray(array[i])) {
res.push(unique(array[i]))
}
else if (res.indexOf(current) === -1) {
res.push(current)
}
}
return res;
}
console.log(unique(array)); // [1, 2, [1, 2], [3, 4]]@mqyqingfeng 但是如果是 var array = [1, 2, 1, [1, 1, 2], [3, 3, 4],[1, 1, 2]]这样的数组,我想要的结果是
res= [1, 2, [1, 2], [3, 4]];这个方法就不行了;
@suihaohao 其实你想要的并不是多维数组的去重,而是对象的去重,这需要再利用一个判断两个对象是否相等的函数,JavaScript专题之如何判断两个对象相等
@suihaohao 如果是要这个结果的话,你可以先利用键值对去重的方法处理成 [1, 2, [1,1, 2], [3, 3, 4]],再利用刚才的多维数组去重的方法,处理成 [1, 2, [1, 2], [3, 4]]
@mqyqingfeng 灰常感谢!!!
@mqyqingfeng 大神辛苦了

Object键值对方法中的键应改成typeof item + JSON.stringify(item)
不然的话{},跟{name:'mosen'}会当成一样的因为如果是typeof item + item的话键都是object[object Object]
@huangmxsysu 感谢指出,确实有这个问题~

最后一版感觉有点问题
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed) {
res.push(value)
}
seen = computed;
}
else if (iteratee) {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}
else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
修改前
var arr = ['A','a',1].sort();
unique(arr,true,function(item){
return typeof item == 'string' ? item.toLowerCase() : item
});
// [ 1, 'A', 'a' ]
如果不做修改的话,一个排序过的数组,传不传入 iteratee 方法,对运行结果没啥影响啊。
@mqyqingfeng 没有···· 你运行的是不是修改过的代码哈······
这是文章中最后一版的代码:
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
// 我觉得这里有点问题
// 如果不做修改的话,一个排序过的数组,传不传入 iteratee 方法,对运行结果没啥影响啊。
if (isSorted) {
if (!i || seen !== value) {
res.push(value)
}
seen = value;
}
else if (iteratee) {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}
else if (res.indexOf(value) === -1) {
res.push(value);
}
}
return res;
}
如果按照上面的代码,来处理一个简单排序过的数组的时候,会有点小问题:
var arr = ['A','a',1].sort();//按数字字母排序 => [1, "A", "a"]
console.log(unique(arr,true,function(item){
return typeof item == 'string' ? item.toLowerCase() : item
}));
// 运行结果 [1, "A", "a"]

else if (iteratee) {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}为什么这一段的时候,里面的判断要用seen呢?直接用res不好吗?

@xu824332362
seen中存放的是迭代器处理后的值(比如迭代器中将数组元素都转成小写),res存放的是数组中的原始数据,computed是迭代器处理后的值和seen中的值进行比较。如果直接用res的话,比如原先数组中的大写元素会全部变成小写,会不会不太好...
@sarazhang123 感谢回答,正是如此~ @xu824332362 之所以使用 seen 是为了根据迭代后的值去重,而不改变原数组

es6的去重方法使用越来越多


观君文章,干货颇多,赞

好棒哦,思路清晰考虑全面 😀

@mqyqingfeng 这种数组如何去重?
let arr = [{name: 'li',age: 12}, {name: 'li', age: 12}]@2015-lizaiyang 这篇文章涉及到的去重方法本质都是用 === 判断的,而对于两个对象而言, === 的结果为 false,所以我们还需要借助一个函数来判断两个对象是否相同,这个可以参考 JavaScript专题之如何判断两个对象相等。
具体的写法有很多种,可以选择本篇中的任何一种方法,然后将其 === 的部分修改成使用 eq 函数,当然也可以不使用 eq 函数,使用 JSON.stringify 来简单处理:
// 使用 JSON.stringfiy 处理
var arr = [{ name: 'li', age: 12 }, { name: 'li', age: 12 }]
function unique(array) {
var res = array.filter(function(item, index, array) {
return array.findIndex((element) => {
return JSON.stringify(item) === JSON.stringify(element)
}) === index;
})
return res;
}
console.log(unique(arr)); // eq 函数可以从 《JavaScript专题之如何判断两个对象相等》 这篇文章中找到
var arr = [{ name: 'li', age: 12 }, { name: 'li', age: 12 }]
function unique(array) {
var res = array.filter(function(item, index, array) {
return array.findIndex((element) => {
return eq(element, item)
}) === index;
})
return res;
}
console.log(unique(arr));
sort()在这里应该只是为了把相同的元素逼在一起。所以sort()里不用传一个function再去排序吧。
@magentaqin function 是可选参数,可以不用传入,不过 sorted 为 true,并且还要传一个 function 进行排序,这样的需求还真的很少

@mqyqingfeng 第二版中优化后排序感觉还是有点问题。
var result = unique(arr3.concat().sort(), true)
按你文中是用 var array3 = [1, 1, 'a', 'A', 2, 2]; // [1,2, 'A', 'a']
如果你用 var arr3 = [1, '1', 1, '1'] // [1, '1', 1, '1']
这种就没效果了。还是我用错了~
@zjp6049 哈哈,就是会有这样的问题哈,因为 underscore 认为这个数组是否是排序过后的,是靠开发者决定的,也就是会要求开发者在将第二个参数设置为 true 的时候,要传一个经过排序的数组,这个排序还不仅仅是指通过 sort 函数排序,而是指通过排序,相同的元素是相邻的,underscore 内部也不会进行校验,所以确实会有这个问题,你看最后的表格中 sort 函数的结果,其实也有这个问题。
@mqyqingfeng 那还是直接用JSON.stringify稳一点,但就是数组很长的情况下可能会慢一丢丢
function unique(array) {
var obj = {}
return array.filter(function(value, index, arr) {
var typeofVal = typeof value + JSON.stringify(value)
return obj.hasOwnProperty(typeofVal) ? false : (obj[typeofVal] = true)
})
}因为这个方法好像有点万能
@shenzekun 抱歉哈,我之前没有看到,现在才看到,已经修改了,感谢指出~ o( ̄▽ ̄)d
@ranchoopenwrt 啊? 没有明白?是第二版吗?

@mqyqingfeng ranchoopenwrt 大概指的是第二版
调用时 iteratee只有一个参数
unique(array3, false, function(item){
return typeof item == 'string' ? item.toLowerCase() : item
})定义时 iteratee传了3个参数
var computed = iteratee ? iteratee(value, i, array) : value;小白,同问
@ranchoopenwrt @lvzirui 原来是这个,确实在例子中只用了一个参数,之所以定义传多个参数,其实是为了方便调用时可以使用这些参数,你去看这个定义的参数,其实跟 ES5 中的 map、reduce、forEach
、every 等函数一样,第一个参数是迭代时的参数的值,第二个参数是迭代时的序号,第三个参数就是原数组元素。你可以打印这些参数看一看:
unique(array3, false, function(item, index, arr){
console.log(index)
console.log(arr)
return typeof item == 'string' ? item.toLowerCase() : item
})
很多地方类似啊大兄弟. 跟大漠写的.[JavaScript学习笔记:数组去重]https://www.w3cplus.com/javascript/remove-duplicates-from-javascript-array.html)
@1657413883 数组去重的方法老生常谈了,有相似也是很正常的啦,不过我并没有看过这篇文章~

filter去重的那个版本
var array = [1,2,4,5,"3","4","3",3,2,1,4,5,6];
function unique(array) {
return array.concat().sort().filter(function(item, index, array){
return !index || item !== array[index - 1]
})
}
console.log(unique(array));最后输出结果是[1, 2, "3", 3, "3", "4", 4, 5, 6] 还有两个“3” 好像有点问题呀
@bamboooooo 确实有这个问题哈~ 你看文章末尾的表格里,filter + sort 的结果也有同样的问题,所以使用这种方法的时候要注意了。之所以要讲这个方法,是为了引出 underscore 对于已排序数组的处理方式,所以对于这种在一次循环中只比较前后数组元素是否相同的方式只适合于已经排好序的数组,而让这个数组处于排好序的状态是由开发者来实现的~

数组去重这样的需求,在前端这块,是否需要考虑时间复杂度这样的性能问题?前几周一次面试的时候,面试官让我在对数组去重的性能进行优化,然后想了半天也只写出来了Object键值对的性能,找不到其他既能判断引用类型,性能又稳定在n^2之内的方式?
@Tan90Qian 我也只能想到 Object 键值对这种方式……

JSON.stringify(1) 和 JSON.stringify('1') 返回值不同,并且都可以作为Object键值。typeof可以省略吧?

sort 函数本身的时间复杂度 ......
而且 JSON.stringify({value:1}) === JSON.stringify({value:1})

作者可否研究一下各方法的时间复杂度,找出最优解O(n)

Set 认为尽管 NaN === NaN 为 false,但是这两个元素是重复的。
我看《深入理解ES6》说 Set 集合中检测两个值是否一致,引擎内部使用的是 Object.is()方法,然后 Object.is(NaN, NaN) // true,所以,原文中“Set 认为尽管 NaN === NaN 为 false”这前半句是不是有误

NaN 和 null 用 JSON.stringify 区别不开。
JSON.stringify(NaN); // null
JSON.stringify(null); // null
typeof NaN; // number
typeof null; // object
像这种东西我反手就是一个赞,写的很棒。

这绝对是数组去重最全的攻略了!

优化的版本中:
// 这里判断应该排除iteratee存在的情况
if (isSorted && !iteratee) {
if (!i || seen !== computed) {
res.push(value);
}
seen = computed;
}比如:
var array = ["A", "B", "a", "b"];
unique(array, true, function(item){
return typeof item == 'string' ? item.toLowerCase() : item
}))作者优化的那个版本会输出:["A", "B", "a", "b"],是有问题的呢,并没有满足保留大小写一个的需求!

优化后的键值对方法 去重会有问题 正则表达式 只会保留一个
typeof /a/ 和 typeof /b/ 都是'object'
JSON.stringify(/a/) 和 JSON.stringify(/b/) 都是 ‘{}’

//去重复,不区分大小写
let arrstr = ['a', 'a', 'B', 'a', 'c', 'd', 'e', 'A', 'b'];
if (arrstr != null && arrstr.length > 0) {
let newarrs = arrstr.reduce((init, currentValue, currentIndex, arr) => {
let isexists = init.some((item) => {
return item.toLowerCase() == currentValue.toLowerCase();
})
if (!isexists) {
init.push(currentValue)
}
return init;
}, [])
console.log(newarrs) // ["a", "B", "c", "d", "e"]
}
else {
alert("数组中无元素")
}
var scores = [
{subject: '数学', score: 99},
{subject: '语文', score: 95},
{subject: '物理', score: 80},
{subject: '语文', score: 95},
{subject: '物理', score: 81},
{subject: '英文', score: 80}
];
//只要subject一样就算同一个
//注意这里判断数组为空情况
if (scores != null && scores.length > 0) {
let newarrs = scores.reduce((init, current) => {
// console.log(init)
// console.log(current)
let _subject = current.subject;
// console.log(_subject)
if (init.length == 0) {
init.push(current)
}
else {
let isexists = init.some((item) => {
//只要subject一样就算同一个
return item.subject == _subject
});
if (!isexists) {
init.push(current)
}
}
return init;
}, [])
//只要subject一样就算同一个
console.log(newarrs)
//结果:
// {subject: "数学", score: 99}
// {subject: "语文", score: 95}
// {subject: "物理", score: 80}
// {subject: "英文", score: 80}
}
else {
alert("数组中无元素")
}

有个小问题,关于排序后去重的下面的代码,
var sortedArray = array.concat().sort();这个concat()在这里的意义是什么?不是很理解~
不更改原数组,返回一个新数组进行操作

楼主如果数组如果包含了数组,情况就只有第一个满足,比如
arr =[1,2,4,5,5,5,5,1,'1',[1,2],[1,2],0,null,undefined,NaN,NaN]

优秀

用JSON.stringify区分Object绝对是错误的,同一个对象写法里,字面量属性顺序不同JSON.stringify的结果也不同,你还要考虑对象里还有对象的情况,判断对象属性值相等本身就没这么简单

优化小节中,unqique 的拼写错了

function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed) {
res.push(value)
}
seen = computed;
}
else {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}
}
return res;
}
@YeaseonZhang 两个函数实现的效果不一样哈~ 举个例子:
var array = [{value: 1}, {value: 2}, {value: 1}]; console.log(unique(array, false, function(item){ return item.value }));如果使用文章中的方法,结果会是 [{value: 1}, {value: 2}]
如果使用你的方法,结果会是 [1, 2]区别在于使用迭代函数处理后的元素,去重后,是返回以前的元素还是计算后的元素。
无所谓对错,看你想设计成什么样子。
是不是可以改成这种
function unique(array, isSorted, iteratee) {
var res = [];
var seen = [];
for (var i = 0, len = array.length; i < len; i++) {
var value = array[i];
var computed = iteratee ? iteratee(value, i, array) : value;
if (isSorted) {
if (!i || seen !== computed) {
res.push(value)
}
seen = computed;
}
else {
if (seen.indexOf(computed) === -1) {
seen.push(computed);
res.push(value);
}
}
}
return res;
}


copy过去使用为什么出错呢?js小学生求指教

学习了学习了

有个小问题,关于排序后去重的下面的代码,
var sortedArray = array.concat().sort();这个concat()在这里的意义是什么?不是很理解~
为了不影响原数组


博主您好,sort 是可以过滤数字 1 的,不知道你为什么会说不能过滤了?

博主您好,sort 是可以过滤数字 1 的,不知道你为什么会说不能过滤了?
我本来是在控制台运行的,跟你有一样的问题,后来我发现在node环境下1就没有去重,比较后发现是sort()排序出现的问题,我猜测正如前几个问题的评论一样,sort 排序的结果并不总是正确的,在node排序的结果是,
[ /a/, /a/, '1', '1', 1, [String: '1'], 1, [String: '1'], NaN, NaN, null, null, undefined, undefined ]
两个数字1并不相邻导致1没有去重。

const uniqueWithSet = (arr) => Array.from(new Set(arr.map(item => JSON.stringify(item))), item => JSON.parse(item))这样写会不会更好呢。

第三个排序去重 !i 那个判断应该是多余的吧

楼主在优化大小写版本的时候,是这样写的
新需求:字母的大小写视为一致,比如'a'和'A',保留一个就可以了!
这里是只保留大写或者小写中的一个就好了。所以针对var arr = ["A", "B", "a", "b"] 返回 ["A", "B"] 没有毛病呀

| 方法 | 结果 | 说明 |
|---|---|---|
| sort | [/a/, /a/, "1", 1, String, 1, String, NaN, NaN, null, undefined] | 对象和 NaN 不去重 数字 1 也不去重 |
| filter + sort | [/a/, /a/, "1", 1, String, 1, String, NaN, NaN, null, undefined] | 对象和 NaN 不去重 数字 1 也不去重 |
请问这个,数字1为什么不去重,我用排序后去重的方法试了一下,1是会去重的呀?

楼主,第二个indexOf方法可以换成ES6的includes方法,这样就可以去掉重复的NaN,就是带来了兼容性问题。
function unique(array){ var res = []; for(var i = 0, len = array.length; i < len; i++){ var current = array[i]; if(!res.includes(current)){ res.push(current); } } return res; }
function unique(array){
var res = [];
for(var i = 0, len = array.length; i < len; i++){
var current = array[i];
if(!res.includes(current)){
res.push(current);
}
}
return res;
}

/**
* map加for循环 O(n)
*/
const map = {}
let array = []
for (let i = 0; i < arr.length; i++) {
if (map[arr[i]]) {
return
}
array.push(arr[i])
map[arr[i]] = true
}
图片

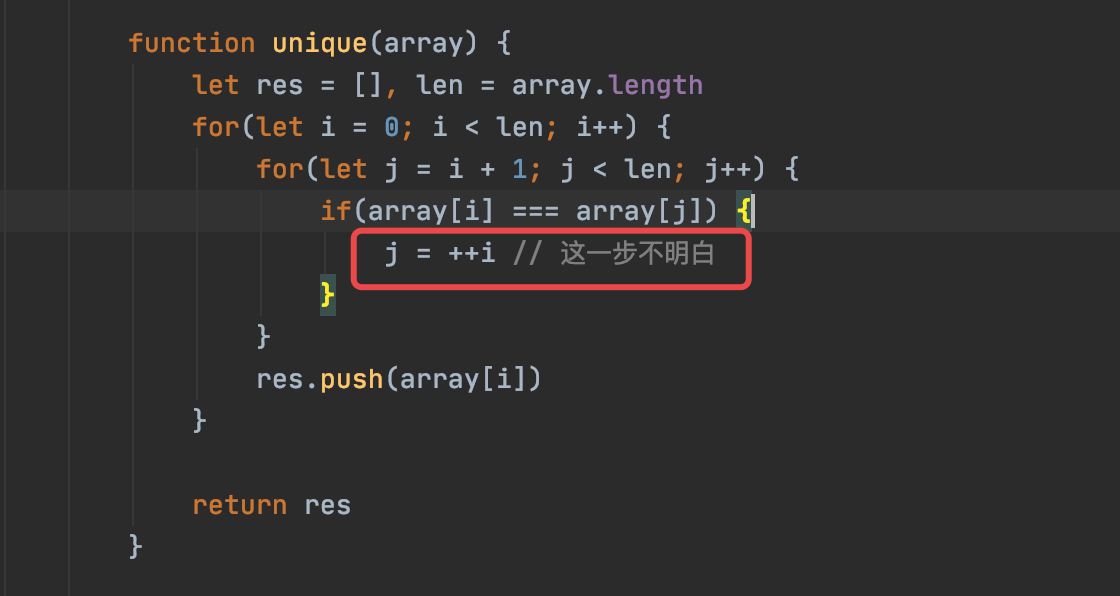
各位大佬,帮忙解释下这步

发现后面有重复的,就不管前面的这个了,继续往后走,只插入最右边的

isSortd其作用是在没有iteratee的情况先把,iteratee返回的值,不一定认识排序好的
function unique(arr, isSortd, iteratee) {
var res = []
var seen = []
for (var i = 0, l = arr.length; i < l; i++) {
var value = arr[i]
// 通过iteratee计算得到的值,不一定任然是排序好的
if (isSortd && !iteratee) {
if (value !== seen) {
res.push(value)
seen = value
}
} else {
var computed = iteratee ? iteratee(value, i, arr) : value
if (seen.indexOf(value) === -1) {
res.push(value)
seen.push(computed)
}
}
}
}

var array = [/a/, /a/, /b/, "1", 1, String, 1, String, NaN, NaN, null, undefined];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
console.log(typeof item + JSON.stringify(item))
return obj.hasOwnProperty(typeof item + JSON.stringify(item)) ? false : (obj[typeof item + JSON.stringify(item)] = true)
})
}
console.log(unique(array)) // [/a/, "1", 1, ƒ, NaN, null, undefined]/b/ 会被过滤掉
按照这个方法键值是重复的
/a/ => object{} /b/ => object{}
这里是不是需要特判一下正则的情况
item = item instanceof RegExp ? item.toString() : item
各位大佬,帮忙解释下这步
function quChong(arr) {
for (let i = 0; i < arr.length; i++) {
for (let j = i+1; j < arr.length; j++) {
if(arr[i] === arr[j]) {
arr.splice(j, 1);
j--;
}
}
}
return arr;
}
这样写你会不会更理解一点

var array = [{value: NaN}, {value: null}, {value: 2}];
function unique(array) {
var obj = {};
return array.filter(function(item, index, array){
console.log(typeof item + JSON.stringify(item))
return obj.hasOwnProperty(typeof item + JSON.stringify(item)) ? false : (obj[typeof item + JSON.stringify(item)] = true)
})
}
console.log(unique(array)); // [{value: NaN}, {value: 2}]
// 这个输出也有点问题,JSON.stringify({value: NaN}) ---> "{\"value\":null}"总感觉数组中比较对象不是太合适,除非是对象的引用,如果需要比较应该是遍历对象进行比较合适。

不好意思不知道是否跟其他小伙伴问题重复了。
大佬,关于第二版涉及排序后返回的好像有点问题。比如说我给的array是这样的:
var array = [1,2,5,3,5,'2','1',1,'2','1'];
最后的unique(array)的结果是:[1, "1", 1, "1", 2, "2", 3, 5]
不好意思不知道是否跟其他小伙伴问题重复了。
大佬,关于第二版涉及排序后返回的好像有点问题。比如说我给的array是这样的:
var array = [1,2,5,3,5,'2','1',1,'2','1'];
最后的unique(array)的结果是:[1, "1", 1, "1", 2, "2", 3, 5]
不好意思说错,不是第二版。是这个代码:
var array = [1, 1, '1'];
function unique(array) {
var res = [];
var sortedArray = array.concat().sort();
var seen;
for (var i = 0, len = sortedArray.length; i < len; i++) {
// 如果是第一个元素或者相邻的元素不相同
if (!i || seen !== sortedArray[i]) {
res.push(sortedArray[i])
}
seen = sortedArray[i];
}
return res;
}
console.log(unique(array));

第一个 排序后去重
是不是没有办法解决这种情况
[1, 2, '1', 2, 1]
得倒的结果是 [1, "1", 1, 2]
改成这样可以 但是 跟作者之前 seen 这个变量就没啥关系了。。 ummm
function unique(array) {
var res = [];
var sortedArray = array.concat().sort();
var seen;
for (var i = 0, len = sortedArray.length; i < len; i++) {
const element = sortedArray[i];
if (!res.includes(element)) {
res.push(element);
}
}
return res;
}
[2, '2', 2].sort() 排序后还是 [2, '2', 2],在排序去重的方法中不行

var arrObj = [1,1,2,3, null, null, undefined, undefined, NaN, NaN, {name: 1}, {name: 2}, {name: 1}, '5', '5', '6', /a/, /a/, /c/];
这个怎么去重吖😂😂😂 写懵了

ES 6 的reduce去重也蛮好用的,友情补充下
/**
* deDuplicateTool 数组去重
* @param array 数组
* @returns 去重后的数组
*/
const deDuplicateTool: deDuplicateType = (array) =>
array.reduce((reviousValue, currentValue) => {
if (!reviousValue.includes(currentValue)) {
return reviousValue.concat(currentValue);
} else {
return reviousValue;
}
}, []);